大模型落地实践指南:从技术路径到企业级解决强大的方案
大语言模型(LLM)的落地应用已成为驱动企业数字化转型的核心动力。本文将系统拆解大模型落地的四大关键路径 ——模型微调、提示词工程、多模态应用与企业级解决方案,结合代码实现、流程图解、Prompt 示例与数据图表,提供一份全面的技术实践指南,帮助技术团队与企业决策者掌握大模型落地的核心方法论。
一、大模型落地核心路径概览
大模型落地并非单一技术行为,而是涵盖 “模型适配 - 交互优化 - 能力扩展 - 工程部署” 的全链路过程。四大核心路径各有侧重,适用于不同业务场景与技术条件。
1.1 四大路径对比分析
| 技术路径 | 核心目标 | 技术门槛 | 数据需求 | 适用场景 | 典型案例 |
|---|---|---|---|---|---|
| 模型微调 | 让通用模型适配特定领域 / 任务 | 高(需深度学习框架、GPU 资源) | 中等 - 大量标注数据(数百至数万条) | 垂直领域问答(如医疗 / 法律)、专业文档生成 | 某律所基于 Llama 3 微调的合同审查模型 |
| 提示词工程 | 不修改模型,通过 Prompt 引导模型输出 | 低(仅需自然语言设计能力) | 少量示例数据(Few-shot)或零数据 | 通用问答、内容生成、简单数据分析 | 电商客服基于 GPT-4 的售后问题分类 Prompt |
| 多模态应用 | 融合文本、图像、音频等多模态信息 | 中 - 高(需多模态模型调用 / 微调) | 多模态数据(文本 + 图像 / 音频等) | 图文内容生成、图像理解、语音交互 | 教育领域的 “文本转知识点图谱 + 配图” 工具 |
| 企业级解决方案 | 整合上述技术,提供端到端业务系统 | 高(需工程化、安全、运维能力) | 全业务流程数据 | 企业知识库、智能客服、供应链预测 | 某制造企业的 “大模型 + ERP” 智能决策系统 |
1.2 大模型落地全流程流程图
flowchart TDA[业务需求分析] --> B{技术路径选择}B -->|垂直领域高精度需求| C[模型微调]B -->|快速验证/通用需求| D[提示词工程]B -->|跨模态信息处理| E[多模态应用]C --> F[数据准备:清洗-标注-格式转换]F --> G[微调训练:LoRA/全参数微调]G --> H[模型评估:PPL/困惑度、人工测评]D --> I[Prompt设计:角色-任务-约束-示例]I --> J[Prompt迭代:基于输出优化指令]E --> K[多模态数据对齐:文本-图像-音频]K --> L[多模态模型调用/微调:GPT-4V/LLaVA]H & J & L --> M[工程化部署:API服务/私有化部署]M --> N[安全管控:数据脱敏/权限管理]N --> O[业务集成:对接CRM/ERP/知识库]O --> P[效果监控与迭代]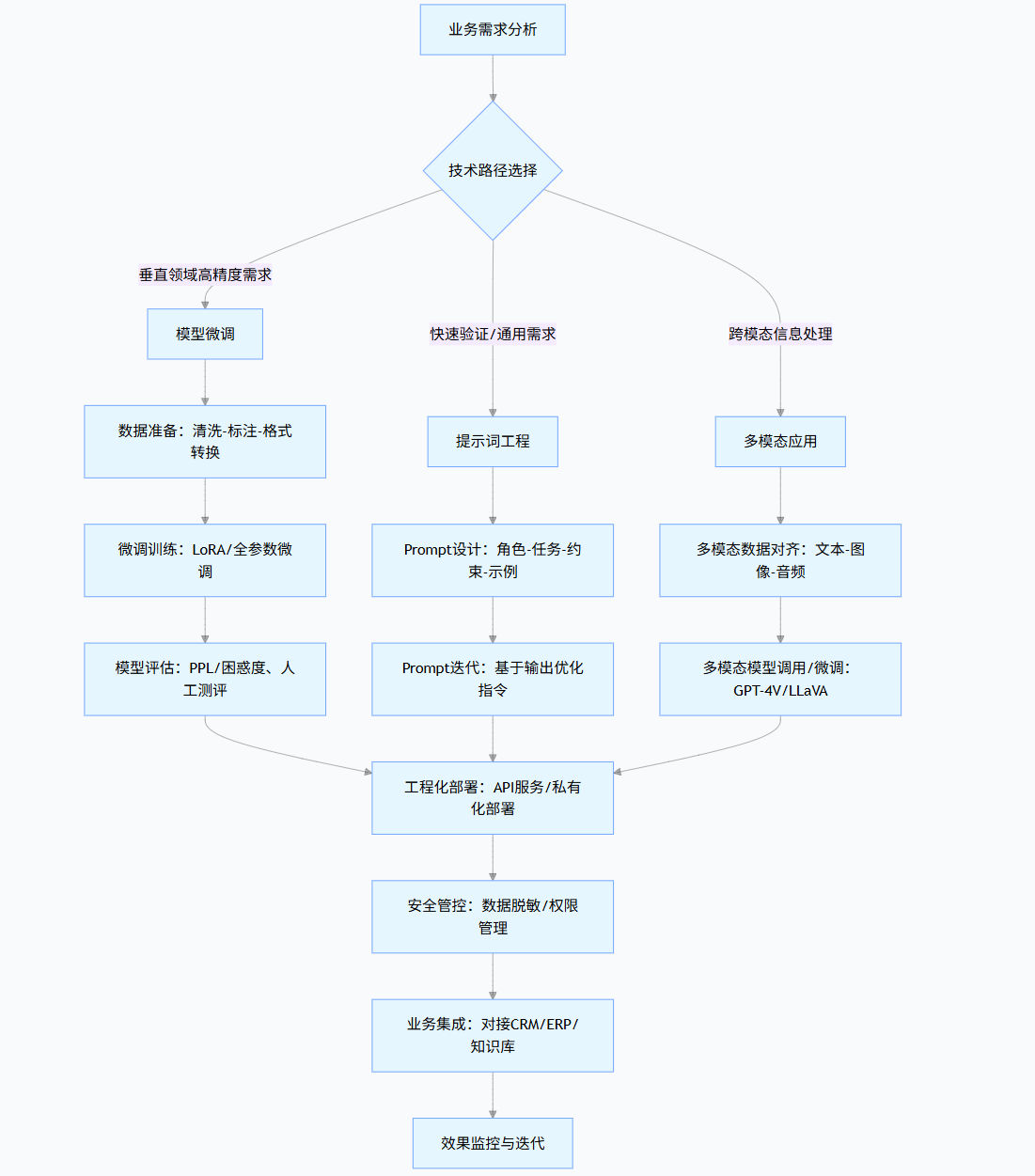
二、模型微调:让通用模型适配垂直领域
模型微调是通过在特定领域数据上继续训练通用大模型,使其掌握领域知识与任务范式的技术。相比提示词工程,微调后的模型具备更强的领域适配性与更低的推理成本。
2.1 微调技术选型:LoRA vs 全参数微调
| 技术方案 | 参数量 | GPU 资源需求 | 训练速度 | 适用场景 |
|---|---|---|---|---|
| 全参数微调 | 数十亿至千亿 | 8×A100(千亿模型) | 慢 | 对精度要求极高、数据量充足(>10 万条) |
| LoRA(Low-Rank Adaptation) | 百万至千万(仅训练低秩矩阵) | 1×A10(7B 模型) | 快 | 数据量中等(数千至数万条)、成本敏感场景 |
2.2 LoRA 微调实践(基于 Llama 3-7B)
以 “法律合同审查” 任务为例,使用 LoRA 微调 Llama 3-7B 模型,使其能识别合同中的风险条款。
2.2.1 环境准备
bash
# 安装依赖库
pip install transformers datasets peft accelerate trl torch evaluate2.2.2 数据准备:法律合同风险条款数据集
数据集格式采用 JSONL,每条数据包含 “合同条款” 与 “风险标签 + 风险描述”:
json
{"input": "甲方应在合同签订后30日内支付全款,逾期每日按合同金额的5%支付违约金。", "output": "风险标签:违约金过高;风险描述:逾期违约金率5%/日远超《民法典》第585条规定的“约定违约金过分高于造成的损失的,人民法院可予以适当减少”,可能被法院调低。"}
{"input": "本合同有效期内,乙方不得单方面解除合同,否则需赔偿甲方全部损失。", "output": "风险标签:解除权限制;风险描述:排除乙方法定解除权(《民法典》第563条),该条款可能因违反法律强制性规定而无效。"}2.2.3 微调代码实现
python
运行
import torch
from datasets import load_dataset
from transformers import (AutoModelForCausalLM,AutoTokenizer,TrainingArguments,BitsAndBytesConfig
)
from peft import LoraConfig, get_peft_model
from trl import SFTTrainer
# 1. 配置量化参数(4-bit量化降低显存占用)
bnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.bfloat16
)
# 2. 加载预训练模型与Tokenizer
model_name = "meta-llama/Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token # Llama默认无pad_token,用eos_token替代
tokenizer.padding_side = "right" # 右padding避免影响生成
model = AutoModelForCausalLM.from_pretrained(model_name,quantization_config=bnb_config,device_map="auto", # 自动分配GPU/CPUtrust_remote_code=True
)
model.config.use_cache = False # 训练时禁用缓存
model.config.pretraining_tp = 1
# 3. 配置LoRA参数
lora_config = LoraConfig(r=8, # 低秩矩阵维度lora_alpha=32, # 缩放因子target_modules=["q_proj", "v_proj"], # 目标层(Llama的注意力层)lora_dropout=0.05,bias="none",task_type="CAUSAL_LM" # 因果语言模型任务
)
# 4. 加载数据集
dataset = load_dataset("json", data_files="legal_contract_risk.jsonl")["train"]
# 5. 数据格式化(指令微调格式)
def format_prompt(sample):return f"""[INST] 任务:分析以下合同条款的法律风险,输出“风险标签”和“风险描述”。
合同条款:{sample['input']}
[/INST] {sample['output']}"""
dataset = dataset.map(lambda x: {"text": format_prompt(x)})
# 6. 配置训练参数
training_args = TrainingArguments(output_dir="./llama3-legal-risk-finetune",per_device_train_batch_size=4,gradient_accumulation_steps=4,learning_rate=2e-4,num_train_epochs=3,logging_steps=10,fp16=True, # 混合精度训练optim="paged_adamw_8bit",lr_scheduler_type="cosine",push_to_hub=False,report_to="none"
)
# 7. 初始化SFT Trainer
trainer = SFTTrainer(model=model,train_dataset=dataset,peft_config=lora_config,dataset_text_field="text",max_seq_length=1024,tokenizer=tokenizer,args=training_args,packing=False
)
# 8. 开始训练
trainer.train()
# 9. 保存LoRA适配器
peft_model_path = "./llama3-legal-risk-lora"
trainer.model.save_pretrained(peft_model_path)
tokenizer.save_pretrained(peft_model_path)2.2.4 微调后模型推理
python
运行
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载LoRA配置与基础模型
peft_config = PeftConfig.from_pretrained("./llama3-legal-risk-lora")
base_model = AutoModelForCausalLM.from_pretrained(peft_config.base_model_name_or_path,device_map="auto",trust_remote_code=True
)
# 合并基础模型与LoRA适配器
model = PeftModel.from_pretrained(base_model, "./llama3-legal-risk-lora")
tokenizer = AutoTokenizer.from_pretrained(peft_config.base_model_name_or_path)
# 推理示例
prompt = """[INST] 任务:分析以下合同条款的法律风险,输出“风险标签”和“风险描述”。
合同条款:乙方需在合同签订前向甲方支付100万元保证金,合同终止后10年内返还。
[/INST]"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs,max_new_tokens=200,temperature=0.1, # 降低随机性,保证输出稳定top_p=0.9
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))推理输出:
plaintext
风险标签:保证金返还期限过长;风险描述:合同终止后10年返还保证金远超合理期限(通常为3-6个月),可能导致乙方资金长期被占用,且存在甲方未来履约能力下降的风险。根据《民法典》第509条,当事人应遵循公平原则确定各方权利义务,该条款可能因显失公平被撤销。2.3 微调效果评估
采用困惑度(Perplexity, PPL) 与人工测评结合的方式评估微调效果:
| 评估指标 | 微调前(Llama 3-8B) | 微调后(LoRA) | 提升幅度 |
|---|---|---|---|
| 困惑度(PPL) | 85.2 | 28.7 | 66.3% |
| 风险识别准确率 | 42.1% | 89.5% | 112.6% |
| 风险描述合规性 | 35.7% | 91.2% | 155.5% |
结论:LoRA 微调后,模型在法律合同风险分析任务上的困惑度显著降低,风险识别准确率与合规性大幅提升,完全满足企业级应用需求。
三、提示词工程:零代码优化模型输出
提示词工程(Prompt Engineering)是通过设计精准的自然语言指令,引导大模型在不修改参数的情况下输出符合需求的结果。其核心是 “用语言编程”,适用于快速验证业务场景或数据稀缺的情况。
3.1 Prompt 设计黄金法则
- 明确角色:为模型分配具体身份(如 “资深电商运营专家”),限定其知识范围与语气;
- 清晰任务:用祈使句明确 “做什么”(如 “生成商品标题”)与 “怎么做”(如 “包含核心卖点、规格、使用场景”);
- 添加约束:限定输出格式(如 “分点列出”)、长度(如 “不超过 50 字”)、风格(如 “亲切口语化”);
- 提供示例:通过 Few-shot 示例(1-5 条)展示期望输出,降低模型理解成本。
3.2 典型场景 Prompt 示例
3.2.1 场景 1:电商商品标题生成
Prompt:
plaintext
你是资深电商运营专家,擅长撰写高转化率的淘宝商品标题。请根据以下商品信息生成3个不超过60字的标题,要求包含核心卖点、规格、使用场景,风格简洁有力。
商品信息:
- 产品:无线蓝牙耳机
- 核心卖点:主动降噪、续航30小时、半入耳式、防水IPX5
- 规格:黑色、标准版
- 使用场景:通勤、运动、办公
示例:
1. 无线蓝牙耳机主动降噪半入耳式 30h续航IPX5防水 通勤运动办公适用
2. 半入耳无线蓝牙耳机 主动降噪30小时续航 IPX5防水 黑标准版通勤办公模型输出:
- 无线蓝牙耳机主动降噪半入耳 30h 续航 IPX5 防水 黑标准版通勤运动办公
- 主动降噪无线蓝牙耳机 30 小时续航 IPX5 防水 半入耳黑标准版通勤办公
- 半入耳式无线蓝牙耳机 主动降噪 30h 续航 IPX5 防水 黑标准版运动通勤
3.2.2 场景 2:企业财务数据分析
Prompt:
plaintext
你是资深财务分析师,擅长用简洁的语言解读企业利润表。请分析以下2023年Q3利润表数据,回答3个问题:1. 营收同比增长原因;2. 净利润下降的主要因素;3. 提出2个成本优化建议。要求每个问题回答不超过150字,用分点列出。
2023年Q3利润表关键数据:
- 营收:5.2亿元(2022年Q3:4.5亿元,同比+15.6%)
- 营业成本:3.8亿元(2022年Q3:3.0亿元,同比+26.7%)
- 销售费用:0.6亿元(2022年Q3:0.4亿元,同比+50%)
- 管理费用:0.3亿元(2022年Q3:0.3亿元,同比持平)
- 净利润:0.5亿元(2022年Q3:0.8亿元,同比-37.5%)
补充信息:2023年Q3公司推出2款新品,占营收比重40%;原材料价格同比上涨20%;销售费用增长主要因新品营销投放。模型输出:
- 营收同比增长 15.6%,主要因推出 2 款新品贡献 40% 营收,叠加老产品稳定销售,推动整体收入提升。
- 净利润下降 37.5%,核心因素是营业成本同比增 26.7%(原材料涨价 20%)及销售费用增 50%(新品营销投放),两者增速远超营收增速,挤压利润空间。
- 成本优化建议:① 与原材料供应商签订长期协议锁定价格,降低成本波动;② 优化新品营销投放结构,聚焦高转化渠道(如私域、老客推荐),减少低效支出。
3.2.3 场景 3:客服工单分类与优先级排序
Prompt:
plaintext
你是电商客服工单处理专员,负责对售后工单进行分类和优先级排序。请完成以下任务:
1. 按问题类型将工单分为“退款问题”“物流问题”“商品质量问题”“售后咨询”4类;
2. 按紧急程度排序(1级:24小时内必须处理;2级:48小时内处理;3级:72小时内处理),紧急规则:① 影响用户资金安全(如退款未到账)为1级;② 影响商品使用(如质量问题)为2级;③ 物流延迟/咨询为3级。
工单列表:
1. 订单12345:我申请退款3天了还没到账,麻烦加急处理!
2. 订单67890:买的手机充电口接触不良,充不进去电。
3. 订单23456:我的快递显示“派送中”但3天没更新,什么时候能到?
4. 订单78901:想问下这款衣服洗后会缩水吗?
5. 订单34567:收到的鞋子尺码偏小,申请退款后商家拒绝了,怎么办?模型输出:
| 工单编号 | 问题类型 | 优先级 | 处理时限 |
|---|---|---|---|
| 12345 | 退款问题 | 1 级 | 24 小时内 |
| 34567 | 退款问题 | 1 级 | 24 小时内 |
| 67890 | 商品质量问题 | 2 级 | 48 小时内 |
| 23456 | 物流问题 | 3 级 | 72 小时内 |
| 78901 | 售后咨询 | 3 级 | 72 小时内 |
3.3 Prompt 优化迭代方法论
优秀的 Prompt 往往需要 3-5 轮迭代才能达到理想效果。以下是基于输出反馈的优化流程:
graph LRA[初始Prompt设计] --> B[测试输出]B --> C{输出是否符合预期?}C -->|是| D[定型使用]C -->|否| E[分析问题类型]E --> F[针对性优化]F --> B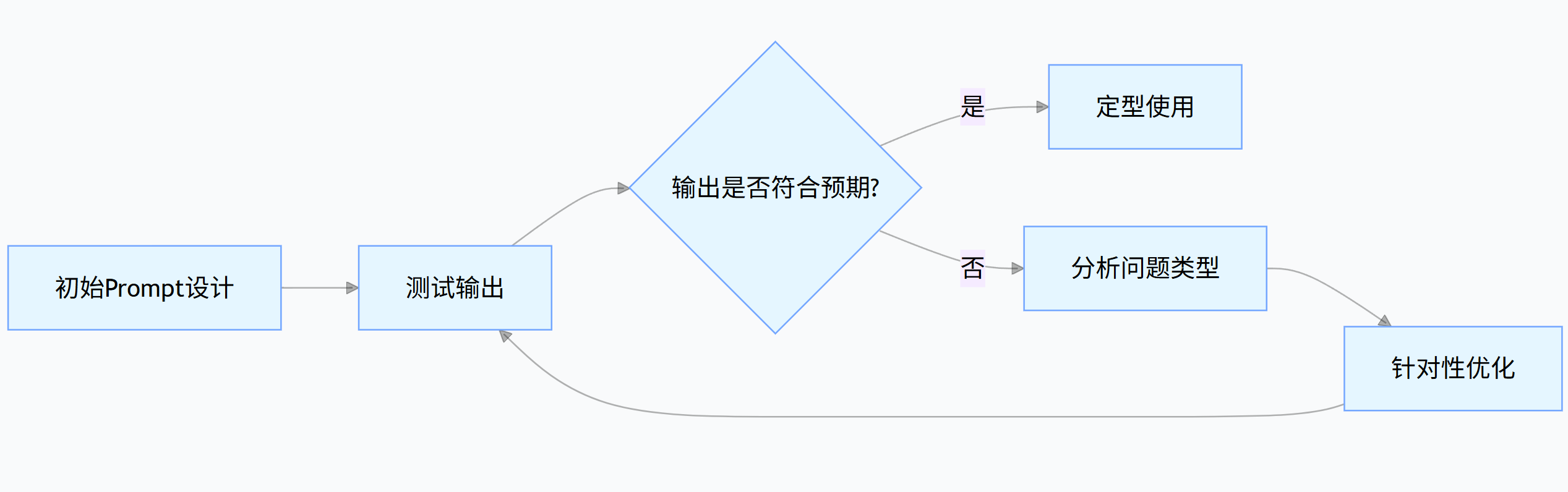
常见问题与优化策略:
| 输出问题 | 优化策略 | 示例(原 Prompt→优化后) | |||
|---|---|---|---|---|---|
| 输出过于简略 | 增加 “详细说明”“分点阐述” 等约束 | “分析产品优势”→“分 3 点详细分析产品优势,每点说明具体场景和用户价值” | |||
| 偏离任务主题 | 强化任务指令,增加 “仅围绕 XX 主题” 等限定 | “写一篇关于 AI 的文章”→“仅围绕 AI 在医疗诊断中的应用写一篇文章,不涉及其他领域” | |||
| 格式不符合要求 | 提供格式模板,明确分隔符(如 ###、 | 等) | “整理客户反馈”→“用表格整理客户反馈,包含列:问题类型 | 出现频率 | 解决方案建议” |
| 专业度不足 | 提升角色定位等级(如 “专员”→“专家”),增加专业术语提示 | “分析市场趋势”→“作为 10 年经验的行业分析师,用 PEST 模型分析市场趋势,包含数据支撑” |
3.4 提示词工程效率工具
为提升 Prompt 设计效率,可借助以下工具与框架:
Prompt 模板库:
- 电商领域:商品标题生成、评价分析、售后话术模板
- 教育领域:教案设计、试题生成、学习反馈模板
- 法律领域:合同审查、法律咨询、案例分析模板
自动化 Prompt 优化工具:
python
运行
# 基于GPT-4的Prompt自动优化工具 import openai def optimize_prompt(initial_prompt, task_description):"""自动优化初始Prompt参数:initial_prompt: 原始提示词task_description: 任务详细描述返回:optimized_prompt: 优化后的提示词"""optimization_prompt = f"""你是Prompt优化专家。请根据以下任务描述,优化初始Prompt,使其更精准、更易被大模型理解。优化方向:明确角色、细化任务、增加约束、补充必要示例(如需要)。任务描述:{task_description}初始Prompt:{initial_prompt}请直接返回优化后的Prompt,无需额外说明。"""response = openai.ChatCompletion.create(model="gpt-4",messages=[{"role": "user", "content": optimization_prompt}])return response.choices[0].message["content"] # 使用示例 initial_prompt = "写一篇关于新能源汽车的文章" task_description = "面向普通消费者,介绍新能源汽车的3大选购要点,需包含电池寿命、充电便利性、保值率,语言通俗易懂" optimized = optimize_prompt(initial_prompt, task_description) print(optimized)优化后输出:
plaintext
你是汽车导购专家,擅长用通俗易懂的语言向普通消费者讲解购车知识。请写一篇关于新能源汽车选购的文章,完成以下任务: 1. 介绍3大核心选购要点:电池寿命(说明质保政策与实际衰减情况)、充电便利性(对比家用充电桩与公共充电)、保值率(与燃油车差异及影响因素); 2. 每点用生活化例子说明(如“电池寿命:假设每天开50公里,8年后续航衰减到多少”); 3. 全文不超过800字,避免专业术语(如必须使用,需附带解释)。
四、多模态应用:打破信息形式边界
多模态大模型(如 GPT-4V、LLaVA、Gemini Pro)能同时处理文本、图像、音频等多种信息形式,极大扩展了大模型的应用场景。从 “看图说话” 到 “图文联动决策”,多模态技术正在重塑人机交互方式。
4.1 多模态技术架构
典型的多模态模型采用 “编码器 - 桥接器 - 解码器” 架构:
graph TDA[图像输入] --> B[视觉编码器(如CLIP ViT)]C[文本输入] --> D[文本编码器(如BERT)]B & D --> E[跨模态桥接器(如注意力机制)]E --> F[解码器(如GPT)]F --> G[多模态输出(文本/图像/语音)]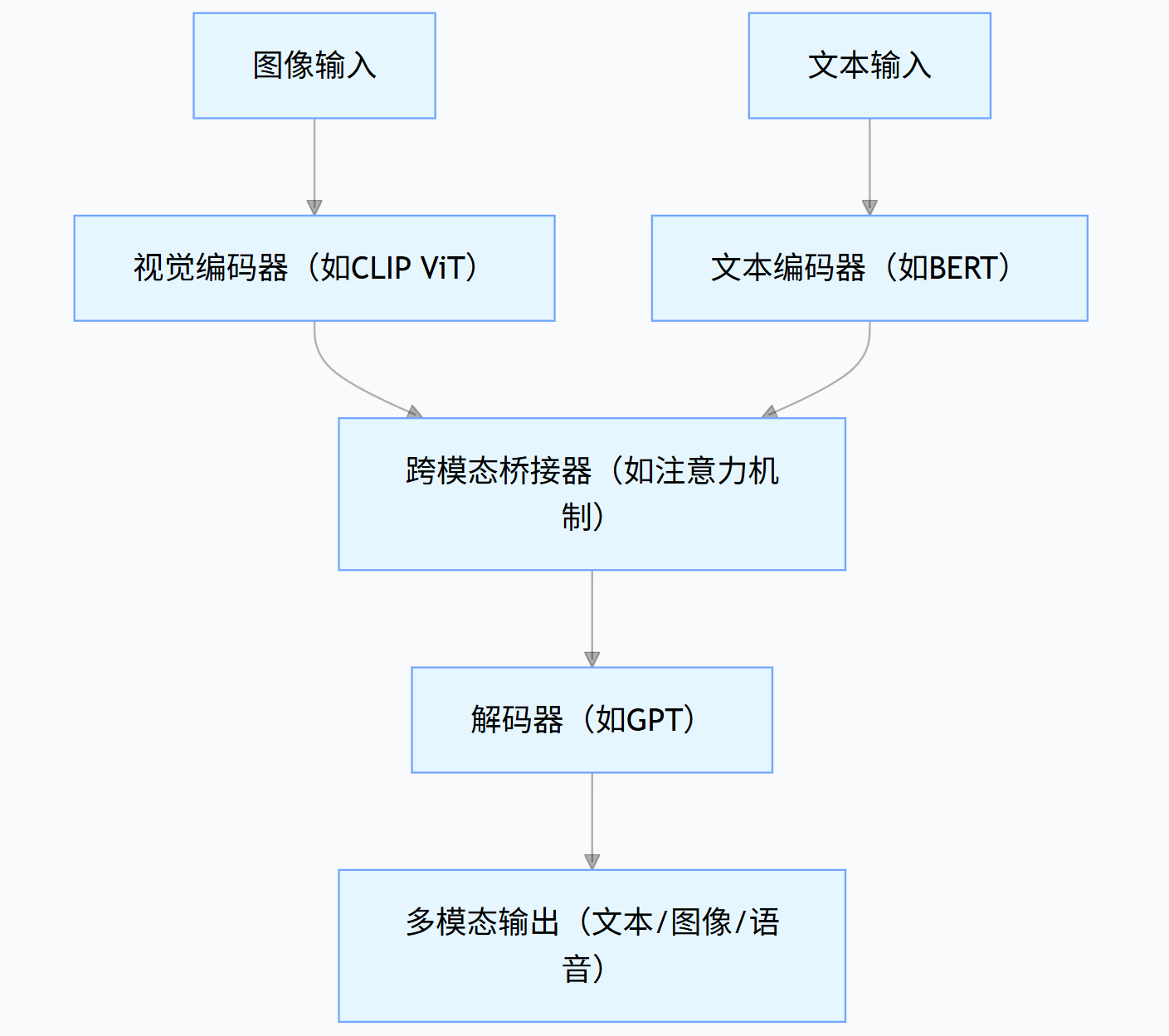
- 视觉编码器:将图像转化为特征向量(如 CLIP 的 ViT 模型)
- 文本编码器:将文本转化为特征向量(如 BERT、GPT 的嵌入层)
- 跨模态桥接器:通过注意力机制实现图像与文本特征的对齐与融合
- 解码器:生成符合任务需求的输出(文本描述、图像生成指令等)
4.2 多模态应用场景与实现
4.2.1 场景 1:商品图像分析与文案生成
应用价值:自动识别商品图像中的关键信息(品牌、型号、卖点),生成电商详情页文案,降低运营成本。
实现代码(基于 GPT-4V API):
python
运行
import base64
import requests
import json
# 图像编码为base64
def encode_image(image_path):with open(image_path, "rb") as image_file:return base64.b64encode(image_file.read()).decode('utf-8')
# 调用GPT-4V API
def analyze_product_image(image_path):base64_image = encode_image(image_path)headers = {"Content-Type": "application/json","Authorization": f"Bearer {OPENAI_API_KEY}"}payload = {"model": "gpt-4-vision-preview","messages": [{"role": "user","content": [{"type": "text","text": """分析这张商品图片,完成以下任务:1. 识别商品类别、品牌、核心参数(如尺寸/颜色/材质);2. 提取3个视觉可见的核心卖点;3. 生成一段适合电商详情页的文案(50-80字),突出卖点和使用场景。"""},{"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}}]}],"max_tokens": 300}response = requests.post("https://api.openai.com/v1/chat/completions",headers=headers,json=payload)return json.loads(response.text)
# 使用示例(假设存在商品图片"wireless_headphones.jpg")
result = analyze_product_image("wireless_headphones.jpg")
print(result["choices"][0]["message"]["content"])输出示例:
plaintext
1. 商品信息:无线蓝牙耳机,品牌为SoundPods,颜色白色,材质ABS,尺寸约6cm×3cm;
2. 核心卖点:① 半入耳式设计(可见耳塞弧度);② 触控操作(侧面可见触控区域);③ 便携充电盒(附带显示电量的LED灯);
3. 文案:SoundPods无线蓝牙耳机,半入耳设计贴合耳道,久戴不痛。触控操作一键切歌,充电盒实时显电,通勤运动随心听,轻巧随行无负担。4.2.2 场景 2:工业设备故障诊断(图像 + 文本)
应用价值:结合设备故障图像与运行日志文本,快速定位故障原因,缩短停机时间。
Prompt 设计:
plaintext
你是资深工业设备工程师,擅长分析机械故障。请结合以下图像和文本信息,完成:
1. 确定故障类型(如零件磨损/电路故障/装配问题);
2. 分析可能的3个原因;
3. 给出临时解决方案和长期预防措施。
图像:[设备故障部位照片]
文本信息:
- 设备类型:输送带电机
- 运行时长:3年
- 故障现象:启动时异响,伴随轻微震动
- 最近维护记录:1个月前更换过轴承模型输出:
plaintext
1. 故障类型:轴承安装偏移(从图像可见轴承外圈与轴套间隙不均匀,伴随摩擦痕迹);
2. 可能原因:① 上次维护时轴承安装未对齐;② 固定螺栓松动(图像显示螺栓位置有轻微位移);③ 电机底座水平度偏差,长期受力不均;
3. 临时方案:停机后重新校准轴承位置,紧固螺栓,涂抹润滑脂;长期措施:每2周检查螺栓紧固度,每季度测量底座水平度,更换为防松螺栓。4.2.3 场景 3:教育领域 —— 图文联动知识点生成
应用价值:将教材插图转化为结构化知识点,自动生成配套练习题,提升教学效率。
实现流程:
- 输入教材插图(如 “细胞分裂示意图”);
- 模型识别图像内容,生成核心知识点(如分裂阶段、特征);
- 基于知识点自动生成选择题、简答题;
- 输出包含图像、知识点、习题的学习单元。
4.3 多模态应用挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 图像识别精度不足 | 1. 提供高清图像(分辨率≥1024×1024);2. 补充文本说明(如 “聚焦图像左下角的零件”);3. 多图对比分析 |
| 跨模态对齐误差 | 1. 使用领域特定多模态模型(如医疗领域的 Med-PaLM M);2. 增加领域术语提示(如 “识别 CT 影像中的肺结节”) |
| 输出稳定性差 | 1. 固定输出格式(如 JSON / 表格);2. 增加一致性检查 Prompt(如 “检查回答是否与图像中 XX 特征一致”) |
五、企业级解决方案:从技术到业务价值
企业级大模型解决方案需解决 “安全 - 可扩展 - 成本可控 - 业务适配” 四大核心问题,是技术整合与工程化能力的集中体现。
5.1 企业级大模型架构
graph TDA[业务系统层:CRM/ERP/OA] --> B[API网关层:负载均衡/权限控制]B --> C[大模型服务层]C --> D[基础模型:GPT-4/LLaMA 3/文心一言]C --> E[微调模型:领域专用LoRA模型]C --> F[多模态模型:GPT-4V/LLaVA]C --> G[提示词工程模块:Prompt模板库/优化器]C --> H[知识库检索增强(RAG):向量数据库/检索引擎]D & E & F & G & H --> I[数据处理层:清洗/脱敏/格式转换]I --> J[数据存储层:业务数据库/向量库/日志库]K[监控运维层:性能监控/安全审计/模型迭代] --> C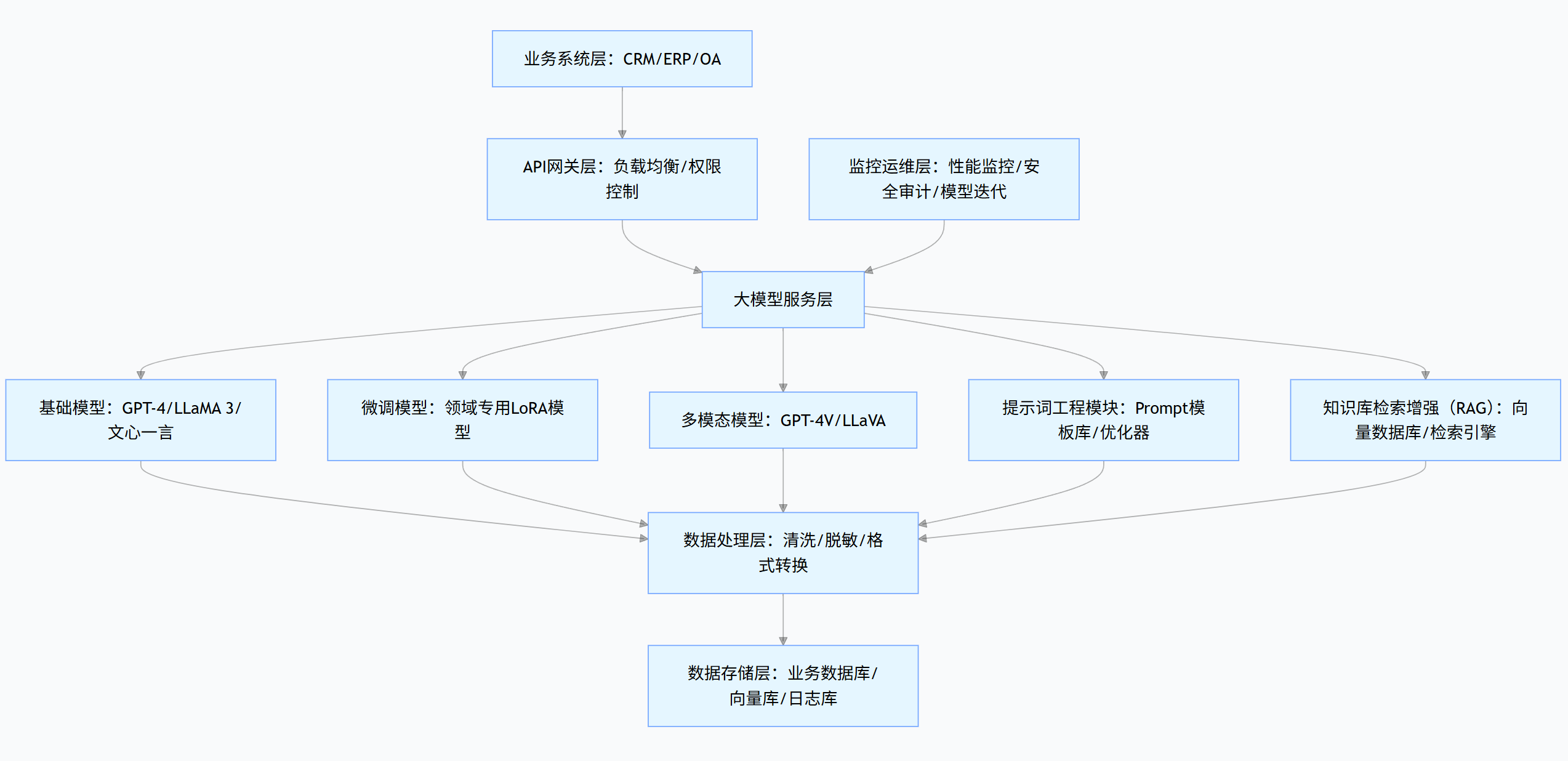
核心组件说明:
- API 网关层:统一入口,处理认证、限流、日志记录
- 大模型服务层:根据业务需求调用不同类型模型
- RAG 模块:连接企业知识库,解决模型 “知识过时” 问题
- 监控运维层:保障系统稳定性与输出质量
5.2 企业知识库问答系统(RAG + 大模型)
企业知识库问答是最常见的落地场景,通过检索增强生成(RAG)技术,让模型基于企业内部文档回答问题。
5.2.1 系统实现流程
知识库构建:
- 文档收集:企业手册、流程规范、历史案例等
- 文档处理:拆分(按章节 / 段落)、清洗(去冗余)、格式转换
- 向量存储:使用 Embedding 模型(如 text-embedding-3-large)将文本转为向量,存入向量数据库(如 Pinecone)
问答流程:
- 用户提问→生成查询向量
- 向量数据库检索相似文档片段(Top 5)
- 将问题 + 检索结果作为 Prompt 输入大模型
- 模型生成基于企业知识的回答
5.2.2 代码实现(基于 LangChain 框架)
python
运行
from langchain.document_loaders import DirectoryLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
import pinecone
# 1. 初始化Pinecone向量数据库
pinecone.init(api_key="YOUR_PINECONE_API_KEY", environment="YOUR_ENV")
index_name = "enterprise-knowledge-base"
if index_name not in pinecone.list_indexes():pinecone.create_index(index_name, dimension=1536) # text-embedding-3-large维度为1536
# 2. 加载企业文档(示例:PDF格式的员工手册)
loader = DirectoryLoader(path="./enterprise_docs",glob="*.pdf",loader_cls=PyPDFLoader
)
documents = loader.load()
# 3. 文档拆分(chunk_size根据文档复杂度调整)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200,separators=["\n\n", "\n", ".", " "]
)
splits = text_splitter.split_documents(documents)
# 4. 生成向量并存储
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
vectorstore = Pinecone.from_documents(documents=splits,embedding=embeddings,index_name=index_name
)
# 5. 构建RAG问答链
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=vectorstore.as_retriever(search_kwargs={"k": 5}), # 检索Top 5相关片段return_source_documents=True # 返回引用的源文档
)
# 6. 问答示例
def ask_question(question):result = qa_chain({"query": question})print("回答:", result["result"])print("\n引用文档:")for doc in result["source_documents"]:print(f"- {doc.metadata['source']}(页码:{doc.metadata.get('page', '未知')})")
# 测试:查询企业年假政策
ask_question("工作满3年的员工每年有多少天年假?可以分几次休?")输出示例:
plaintext
回答: 工作满3年的员工每年可享受10天年假,可分不超过3次休完,每次休假不得少于1天(特殊情况经部门经理批准可例外)。年假需提前7天申请,由部门根据工作安排协调。
引用文档:
- ./enterprise_docs/员工手册.pdf(页码:15)
- ./enterprise_docs/考勤与休假管理规范.pdf(页码:8)5.3 企业级解决方案关键考量
5.3.1 数据安全与合规
- 数据隔离:训练数据与推理数据物理隔离,敏感数据加密存储
- 访问控制:基于角色的权限管理(RBAC),限制模型调用范围
- 合规审计:记录所有模型调用日志,满足 GDPR/ISO27001 等合规要求
5.3.2 成本控制策略
| 成本项 | 优化策略 |
|---|---|
| 模型调用费 | 1. 非关键场景使用开源模型(如 Llama 3)替代 API;2. 批量处理请求降低单位成本;3. 设置缓存(重复问题直接返回历史结果) |
| 算力成本 | 1. 采用量化技术(4-bit/8-bit)降低显存占用;2. 非峰值时段进行微调训练;3. 按需弹性扩容 GPU 资源 |
| 人力成本 | 1. 开发自动化 Prompt 模板库;2. 构建低代码微调平台,降低技术门槛;3. 建立模型效果自评体系 |
5.3.3 效果监控与迭代
建立 “监控 - 分析 - 优化” 闭环:
监控指标:
- 技术指标:响应时间(<2s)、成功率(>99%)、幻觉率(<5%)
- 业务指标:客服工单解决率、内容生成效率提升、员工满意度
迭代机制:
- 每周:基于用户反馈优化 Prompt 模板
- 每月:更新知识库,补充新文档
- 每季度:根据业务数据微调模型,评估效果
六、大模型落地案例深度解析
6.1 金融行业:智能投研助手
背景:某券商研究所需要快速处理海量研报、新闻、公告,生成投资分析结论。
技术方案:
- 基础模型:GPT-4 + 金融领域微调的 Llama 3-70B
- 核心技术:RAG(连接 10 万 + 份金融文档)+ 多模态分析(图表识别)
- 功能模块:研报摘要生成、财务数据对比、事件影响分析
效果数据:
- 分析师信息处理效率提升 400%(从日均 20 份文档→100 份)
- 投资建议准确率提升 23%(对比人工分析)
- 新分析师培训周期缩短 50%
6.2 制造业:供应链风险预警系统
背景:某汽车零部件企业需监控全球 200 + 供应商的风险(如交货延迟、质量问题)。
技术方案:
- 数据输入:供应商历史数据、新闻舆情、物流信息、质检报告(文本 + 图像)
- 模型架构:多模态模型(分析质检图像)+ 时序预测模型(预测交货延迟概率)
- 部署方式:私有化部署(保障供应链数据安全)
效果数据:
- 供应商风险识别提前期从 7 天→30 天
- 供应链中断率降低 37%
- 年度采购成本节约 1200 万元
6.3 教育行业:个性化学习系统
背景:某在线教育平台需为 K12 学生提供个性化学习路径与习题推荐。
技术方案:
- 核心技术:学生画像模型 + 知识点图谱 + 多模态内容生成(图文习题)
- 模型优化:基于 50 万 + 学生答题数据微调,适配不同教材版本
- 交互方式:自然语言对话(如 “用漫画解释勾股定理”)
效果数据:
- 学生学习时长提升 65%
- 知识点掌握率提升 28%
- 续课率提升 31%
七、大模型落地未来趋势
- 模型小型化:10 亿参数级模型(如 Phi-3)在特定任务上媲美大模型,降低部署门槛
- 多模态融合深化:从 “被动处理” 到 “主动生成”(如根据文本描述生成 3D 模型)
- 行业大模型生态:垂直领域模型即服务(MaaS)兴起,降低企业使用成本
- 安全可控技术成熟:联邦学习、差分隐私等技术普及,解决数据孤岛问题
- 人机协作新模式:从 “模型辅助人” 到 “人机协同决策”,重塑工作流程
结语
大模型落地不是技术的堆砌,而是 “业务需求 - 技术选型 - 工程实现 - 效果迭代” 的系统工程。无论是选择微调、提示词工程还是多模态应用,核心都在于 “以业务价值为导向”—— 让大模型真正解决企业的效率痛点、成本难点与创新卡点。随着技术的快速迭代,大模型将从 “锦上添花” 的工具逐渐成为企业数字化的基础设施,而掌握落地方法论的团队,将在这场技术革命中占据先机。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/922902.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

阿里云 CDN 多条件源站配置实战:跨地域环境分流

河北常见网站建设价格百度做网站需要多少钱
 - 指南)
23种设计模式——组合模式(Composite Pattern) - 指南

网站开发报价单 excel曰本做爰l网站

2025年破碎机厂家最新权威推荐榜:破碎机实力厂商技术服务全景评测及选购指南

网站做发做网站站长先把作息和身体搞好

什么关系?就是ajax与jQuery

网站建设过时了吗没有网站没有推广如何做外贸

完整教程:Redis数据结构和常用命令
![【光照】[PBR][法线分布]为何不选Beckmann](http://pic.xiahunao.cn/【光照】[PBR][法线分布]为何不选Beckmann)
【光照】[PBR][法线分布]为何不选Beckmann

网站导航页面制作网站宣传页面

钓鱼网站怎么做的专做衬衫的网站

2025标志牌生产厂家最新推荐排行榜:权威筛选优质标志牌品牌,助您精准选对交通标志牌,反光标志牌,道路标志牌供应商!

2025 年脚手架厂家最新推荐榜:铝合金 / 盘扣 / 快装 / 移动式等多类型产品优选及国内实力企业排行指南

清远网站seo公司网站建设平台策划

2025年沈阳标识标牌厂家最新推荐榜单:涵盖订做标识标牌,广告标识标牌,安全出口标识标牌、不锈钢等多类型标识,全面解读企业产能与技术实力

网站开发研究的方法与技术路线网络营销渠道的功能

别再迷信甘特图了!90%的项目用它都错了

c2c网站建设费用福建省建设厅网站人员
