背景
家里放置了一个 32G+1T 的 R7-8745H 主机,部署一些数据库等服务以便日常开发,后续需求越来越多,需要用到可观察性组件,所以研究一些在中小公司中实现性价比高、简单易用、吞吐量大的部署方案。
本问主要部署环境是 Docker,不涉及 Kubernetes 部署,但是涉及的组件可以根据实际需求放在 Kubernetes 中进行分布式扩展,以及收集集群信息。
如需了解集群部署原理等相关知识,可参考笔者以前的文章:
Kubernetes 集群日志 和 EFK 架构日志方案: https://www.cnblogs.com/whuanle/p/15893923.html
Kubernetes 集群和应用监控方案的设计与实践 :https://www.cnblogs.com/whuanle/p/15890343.html
方案说明
可观测性的实现方案有很多,例如 Grafana 全家桶、Elastic 商业全家桶,商业收费或开源也有一些一体化平台例如 GreptimeDB,为了在部署过程研究各种中间件服务的特点和部署流程,我们不采用这种一体化平台,使用各种开源组件实现部署。
主要目标是实现小企业低成本建设,我们考虑在最小内存实现满足 10 天以上的日志、链路追踪、监控等数据存储和查询。
主要思路是分开 日志(Logs)、链路追踪(Traces)、指标(Metrics)三方面研究。
让我们了解一下日志记录的三个关键组件。
Logging Agent: 日志代理,在服务器节点上运行,采集系统日志、服务日志、Docker 容器日志、Kubernetes 服务日志等,它将日志不断地集中到日志后端。
Logging Backend: 一个集中的系统,能够存储、搜索和分析日志数据。
Log Visualization: 以仪表板的形式可视化日志数据的工具。
首先是 Logging Agent,社区最常用的是 Logstash 组件,用于采集、过滤、二次处理日志,然后推送到存储后端。
要先评估每天产生的日志数量,量小且没有太多分析需求时,使用 Filebeat 收集日志、打标签、推送到 ElasticSearch、Clickhouse 等即可。
如果要应对集群、每天产生的日志数量大、有峰值瓶颈,可以在每个节点部署 Filebeat 收集日志,推送到 Kafka 集群,然后使用 Logstash 逐步消费 Kafka 日志推送到 ElasticSearch。这种方式好处时可以进行流量削峰,可以很容易水平伸缩应对高吞吐量,满足有额外日志处理的需求,方便进行二次处理。
Logging Backend 是存储日志的后端,ElasticSearch、Clickhouse 都是常用的日志存储数据库,两者都支持分布式部署,Clickhouse 的成本更低一些,不过使用曲线复杂一些,所以后续主要使用 ElasticSearch 做存储后端。

链路追踪和指标,可以使用 OpenTelemetry Collector 做统一接入层,然后使用 Collector 转发到不同的方案中。好处是应用只需要有一个统一的推送地址,应用只需要使用 OpenTelemetry SDK 统一接入就行,而运维可以使用 Collector 绑定不同的后端存储服务。
OpenTelemetry Collector 本身不存储数据,它是实现了 OpenTelemetry 协议的统一接入层,然后转发到对应的后端存储服务,需要搭配对应的 Logs、Traces、Metrics 使用。
比如 Traces 可以使用 Jaeger 或 Skywalking + ElasticSearch,Metrics 可以使用 Prometheus + Grafana,而应用服务并不需要关注具体的实现,统一将数据推送到 OpenTelemetry Collector 服务即可,具体怎么处理,由运维配置 Collector 转发到具体的存储后端。
当然,OpenTelemetry Collector 也支持应用推送日志,不过一般是采集器在宿主机采集。
当然,很多可观察性组件本身就已经兼容了 OpenTelemetry 协议,不需要 OpenTelemetry Collector 也可以直接接收数据,这点后面再讲解。
采用的大概方案就是这样,接下来将讲解具体实现细节。
日志方案
存储后端 ElasticSearch + Kibana
日志存储和索引最常用的就是 ElasticSearch + Kibana 了,虽然说 ElasticSearch 占用资源大一些,但是相对来说维护还是比较简单的,资料也多,需要扩展成集群也相对容易一些,配置日志清理规则等,都容易处理,所以日志存储服务首选还是 ElasticSearch。
本章将 ElasticSearch 部署为单节点模式,本文的 ElasticSearch、Kibana 不创建网络也不创建存储卷,直接以节点的形式暴露端口,并且映射本地目录持久化存储。
创建 /data/elasticsearch/data、/data/elasticsearch/config 用于存储 ElasticSearch 的配置文件和数据,目录权限设置 755。
先启动一个 ElasticSearch:
docker run -itd --name elasticsearch -m 2GB \
--restart=always \
--publish 9200:9200 \
--env discovery.type=single-node \
--env xpack.security.authc.api_key.enabled=true \
-v /data/elasticsearch/data:/usr/share/elasticsearch/data \
docker.elastic.co/elasticsearch/elasticsearch:9.1.3
```(http://nps.local.whuanle.cn:36006/images> 部署 ElasticSearch 最好设置限制内存,否则吃掉非常多的主机资源。<br />如果需要将 ElasticSearch 的配置文件也放出来,可以先复制到 config 目录:```bash
docker cp elasticsearch:/usr/share/elasticsearch/config ./
然后删除容器重新创建:
docker rm -f elasticsearch
docker run -itd --name elasticsearch -m 2GB \
--restart=always \
--publish 9200:9200 \
--env discovery.type=single-node \
--env xpack.security.authc.api_key.enabled=true \
-v /data/elasticsearch/config:/usr/share/elasticsearch/config \
-v /data/elasticsearch/data:/usr/share/elasticsearch/data \
docker.elastic.co/elasticsearch/elasticsearch:9.1.3
接着进入容器,初始化 elastic、kibana_system、logstash_system 三个账号的密码。
docker exec -it elasticsearch bash
进入容器后打开 bin 目录。

分别执行 ./elasticsearch-reset-password -u elastic、./elasticsearch-reset-password -u kibana_system、 ./elasticsearch-reset-password -u logstash_system ,复制输出的密码。
或者执行 ./elasticsearch-setup-passwords interactive,按照提示选择要重置密码的账号。

建议使用随机密码,如果密码太简单,Kibana 连接时会提示
Error: [config validation of [elasticsearch].password]: expected value of type [string] but got [number]。
测试 ElasticSearch 是否部署成功:
curl -u elastic http://localhost:9200/

或者在浏览器打开地址后输入 elastic 的账号密码,能够进入说明部署正常。


接下来开始部署 Kibana,因为 Kibana 是无状态的,因此只需要注册相关环境变量,不需要映射目录。
docker run --name kibana --restart=always \
-itd --publish 5601:5601 \
--env ELASTICSEARCH_HOSTS="http://192.168.50.199:9200" \
--env ELASTICSEARCH_USERNAME=kibana_system \
--env ELASTICSEARCH_PASSWORD='密码' \
docker.elastic.co/kibana/kibana:9.1.3
ELASTICSEARCH_HOSTS是 ElasticSearch 容器所在的节点 IP 和端口。ELASTICSEARCH_USERNAME、ELASTICSEARCH_PASSWORD是账号密码,账号固定使用kibana_system。
至此,ElasticSearch、Kibana 部署完成。

日志收集方案
开源社区中有很多方案,社区中常用的有 logstash 、Flunetd/Fluentbit、Filebeat 等工具,例如大名鼎鼎的 ELK 中的 L 是 logstash ,LogsStash 功能强劲但是占用资源大,在集群里面收集日志或节点里面收集日志可能会消耗过多的资源。
所以笔者主要使用 Filebeat 收集日志,读者可以根据需求确认使用哪种具体的收集方式。
Filebeat 是 Elastic 家的产品之一,其文档介绍:https://elastic.ac.cn/docs/reference/beats/filebeat/how-filebeat-works
例如只需要收集日志转发,Filebeat 足够轻量,支持 Docker 部署,也支持 Kubernetes 部署,无需安装插件即可支持输出到 Kafka、ElasticSearch。
不需要按照额外插件即可支持多种接口,这是非常重要的,一开始笔者尝试过 Fluentd,奈何部署需要另外安装插件,Docker 启动需要另外制作带插件的包,部署过于麻烦,所以笔者放弃了 Fluentd。
笔者采用的方案是 filebeat + kafka + logstash 。如果你的服务器数量少,每天产生的日志量不大,直接使用 Filebeat 推送到 ElasticSearch 即可。
如果集群日志量比较大,则每个节点使用使用 Filebeat 推送到 Kafka,然后 Logstash 从 Kafka 消费处理后推送到 ElasticSearch。
因为短时间集群日志的量可能比较大,ElasticSearch 万一顶不住那么大的直接炸了就不好了,使用 Kafka 可以以集群的方式部署,对流量进行削峰。
Logstash 可以单节点部署,因为 Logstash 的吞吐量很大,即使多个 Filebeat 同时推送到 Kafka,Logstash 也可以应对,并且 Kafka 有持久化能力,即使单节点 Logstash 消费慢一些,后续也可以通过部署多个 Logstash 解决问题。
多个 Logstash 并不需要分布式通讯协调,因为他们使用相同的 Consumer 订阅 Kafka 主题即可,Kafka 会均衡将消息分配给每个实例,所以扩展起来也很简单。
Filebeat 的配置挺简单的,如果直接使用 Filebeat 推送到 ElasticSearch,只需要这样配置即可:
这里只做演示,不实际使用。
filebeat.config:modules:path: ${path.config}/modules.d/*.ymlreload.enabled: falsefilebeat.autodiscover:providers:- type: dockerhints.enabled: trueprocessors:
- add_cloud_metadata: ~output.elasticsearch:hosts: '${ELASTICSEARCH_HOSTS:elasticsearch:9200}'username: '${ELASTICSEARCH_USERNAME:}'password: '${ELASTICSEARCH_PASSWORD:}'
配置内容参考:raw.githubusercontent.com/elastic/beats/9.0/deploy/docker/filebeat.docker.yml
部署 Kafka
笔者内网的日志量不大,所以只需要部署单机即可。
创建目录:
mkdir -p /data/kafka/broker/logs
mkdir -p /data/kafka/broker/data
chmod -R 777 /data/kafka
在 /data/kafka 目录下创建 docker-compose.yml 文件:
services:kafka:image: apache/kafka-nativeports:- "9092:9092"- "9093:9093"volumes:- /data/kafka/broker/logs:/opt/kafka/logs # 持久化日志和数据- /data/kafka/broker/data:/opt/kafka/dataenvironment:# Configure listeners for both docker and host communicationKAFKA_LISTENERS: CONTROLLER://:9091,HOST://0.0.0.0:9092,DOCKER://0.0.0.0:9093KAFKA_ADVERTISED_LISTENERS: HOST://192.168.50.199:9092,DOCKER://kafka:9093KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,DOCKER:PLAINTEXT,HOST:PLAINTEXT# Settings required for KRaft modeKAFKA_NODE_ID: 1KAFKA_PROCESS_ROLES: broker,controllerKAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLERKAFKA_CONTROLLER_QUORUM_VOTERS: 1@localhost:9091# Listener to use for broker-to-broker communicationKAFKA_INTER_BROKER_LISTENER_NAME: DOCKER# Required for a single node clusterKAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1kafka-ui:image: kafbat/kafka-ui:mainports:- 8080:8080environment:DYNAMIC_CONFIG_ENABLED: "true"KAFKA_CLUSTERS_0_NAME: localKAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9093depends_on:- kafka
生产环境建议按需部署 Kafka 集群,请勿使用单机 Kafka。
如果不需要 ui,可以删除
kafka-ui服务。
打开 kafka-ui 端口,然后填写 Kafka 地址。
注,笔者实际使用的是 38080 端口,管理 Kafka 要使用 9093 端口而不是 9092 端口。

部署 Filebeat
Filebeat 支持采集多行消息、AWS S3 、Azure Blob Storage、容器、 Kafka 等各种日志源支持采集和集中处理日志,详细介绍参考:https://www.elastic.co/cn/beats/filebeat
Filebeat 支持裸机、Docker 部署和集群部署,考虑到维护方法,这里使用 Docker 部署收集宿主机的日志,这里讲解 Kubernetes 的部署。
docker pull docker.elastic.co/beats/filebeat:9.1.3
创建 /data/filebeat/filebeat.docker.yml 文件和 /data/filebeat/data 目录。
filebeat.docker.yml 文件内容如下:
#######################
# Filebeat 主配置
#######################
filebeat.inputs:# Docker日志输入(添加多行处理)- type: filestreamid: docker-logspaths:- /var/lib/docker/containers/*/*.logparsers:- container: # 使用 container 解析器处理 Docker JSON 日志format: dockerstream: all# 新增多行配置(关键修改)multiline:type: patternpattern: '^[[:space:]]' # 匹配以空格/制表符开头的行negate: falsematch: aftertimeout: 5sfields:log_source: dockerlog_topic: docker-logs# Nginx日志输入(保持不变)- type: filestreamid: nginx-logspaths:- /var/log/nginx/*.logmultiline:pattern: '^\[[0-9]{4}-[0-9]{2}-[0-9]{2}'negate: truematch: afterfields:log_topic: nginx-logsprocessors:- add_host_metadata:when.not.contains.tags: forwarded- add_cloud_metadata: ~- add_docker_metadata: ~- drop_fields:fields: ["log.offset", "input.type", "host.uptime"]- drop_event.when:or:- contains.container.name: "logstash"- contains.container.name: "filebeat"#######################
# 输出配置
#######################
output.kafka:# initial brokers for reading cluster metadatahosts: ["192.168.50.199:9092"]# message topic selection + partitioningtopic: '%{[fields.log_topic]}'partition.round_robin:reachable_only: falserequired_acks: 1compression: gzipmax_message_bytes: 1000000
部署时如发现运行异常,可以开启输出调试信息功能。
logging.level: debug # 开启调试日志
这里使用 Filebeat 收集两类日志,一个是 Docker 容器的日志,要使用 drop_event.when 排除 logstash、filebeat 容器的日志;另一个是收集 nginx 的日志,如果不需要收集 nginx 日志,可以去掉 nginx-logs,这里只做演示使用。
读者可以调整配置收集 /var/log 、/var/lib/docker/containers/ 等目录下的日志。
日志收集没有这么简单,因为不同程序输出的日志有各种各样的,而默认 Docker 是按照每行输出一个 json 记录,会导致完整的日志被拆散,需要想办法重新组合,这一点在部署 Logstash 消费日志时再说。
配置里面根据 docker 和 nginx 分开推送到 kafka,产生两个 topic, topic: '%{[fields.log_topic]}' 是 区配所有 topic,跟每个 inputs 的字段变量有关,可以自行修改。
如果使用不是 Docker 或者使用 containerd 等启动,容器日志的目录可能是 /var/log/containers/*.log,读者自行调整。
启动 filebeat,将宿主机的日志文件映射到 filebeat 容器中:
docker run -d \--name=filebeat \--user=root \--volume="/data/filebeat/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \--volume="/data/filebeat/data:/usr/share/filebeat/data:rw" \--volume="/var/lib/docker/containers:/var/lib/docker/containers" \--mount type=bind,source=/var/log,target=/var/log \docker.elastic.co/beats/filebeat:9.1.3 filebeat -e --strict.perms=false
--strict.perms=false:避免因文件权限问题导致启动失败。
打开 kafbat UI,查看是否有 topic 。

日志收集处理方式
消费的日志非常依赖收集时的日志格式和各类元数据,好的收集方式可以大大简化消费日志的复杂配置,所以这里先讲解收集阶段如何正确处理日志文件。
基本需求: 增加或去除无用字段, 处理不同格式的日志:json、单行、多行、异常堆栈,对日志处理时,还要给其附加所在的环境、节点名称、容器/服务名称等信息。。
第一类,Json 日志格式日志,这是微服务下推荐使用的的日志格式,后端服务使用日志框架生成 json 格式的日志输出,每行一个 json,多行文本被压缩到字段里面,json 日志可以附带上下文信息和元数据,日志收集和分析都很方便。

C# 程序参考笔者的教程:https://maomi.whuanle.cn/3.2.serilog.html#serilog-日志格式模板
推送到 ElasticSearch 时,可以利用 Json 字段生成 ElasticSearch 的字段,这样搜索、筛选都是很方便,例如日志框架固定 "@tr" 服务输出链路追踪 id,那么可以通过其 id 查找一次请求中关联的所有日志。
{"log.level":"warn","@timestamp":"2025-09-19T03:39:29.165Z","log.logger":"input.scanner","log.origin":{"function":"github.com/elastic/beats/v7/filebeat/input/filestream.(*fileScanner).GetFiles","file.name":"filestream/fswatch.go","file.line":421},"message":"1 file is too small to be ingested, files need to be at least 1024 in size for ingestion to start. To change this behaviour set 'prospector.scanner.fingerprint.length' and 'prospector.scanner.fingerprint.offset'. Enable debug logging to see all file names.","service.name":"filebeat","filestream_id":"docker-logs","ecs.version":"1.6.0"}
单行日志没有特定格式,所有内容压缩在一行,这样难以携带上下文信息、阅读困难。

单行日志处理其实挺简单,但是如果程序抛出堆栈或需要多行格式输出属性时,会导致一个日志被分开成多个行,导致日志质量低下、信息被打散。

Docker 是将每行日志生成一个 json 输出的,例如:
[2025-09-19 03:22:55,782] INFO KafkaConfig values: add.partitions.to.txn.retry.backoff.max.ms = 100add.partitions.to.txn.retry.backoff.ms = 20
Docker 对日志的处理方式非常简单,它完全不关心日志内容的格式或结构,包括多行日志,Docker 只会捕获容器的标准输出(stdout)和标准错误(stderr)流,将这个流中的每一行以换行符 \n为分隔,然后以 json 格式输出到容器日志文件。
最后生成三行日志:
{"log":"[2025-09-19 03:22:55,782] INFO KafkaConfig values: \n","stream":"stdout","time":"2025-09-19T03:22:55.782123456Z"}
{"log":"\tadd.partitions.to.txn.retry.backoff.max.ms = 100\n","stream":"stdout","time":"2025-09-19T03:22:55.782234567Z"}
{"log":"\tadd.partitions.to.txn.retry.backoff.ms = 20\n","stream":"stdout","time":"2025-09-19T03:22:55.782345678Z"}
所以日志收集消费都要考虑各种各样的日志格式问题。
为了保证日志收集和消费的高效,Filebeat 收集日志只在乎单行还是多行,只负责将日志提前出完整的一部分。
所以在 filebeat.docker.yml 文件有这一部分配置:
multiline:type: patternpattern: '^[[:space:]]' # 识别缩进行(如堆栈跟踪)negate: false # 直接匹配patternmatch: after # 合并到前一行之后timeout: 5s # 多行组等待时间
而对应其他更加特殊的格式,需要读者自行查找解析方法。
虽然 Filebeat 也支持 Json 解析和各种各样的验证规则,但是为了性能和速度起见,只按单行多行处理就推送到 Kafka。
过程:
Docker Containers↓ (stdout/stderr)
/var/lib/docker/containers/*.log↓
Filebeat (多行合并 + Docker元数据)↓ (Kafka Producer)
Kafka Topic: raw-docker-logs↓ (Kafka Consumer)
Logstash (JSON检测 + 字段处理)↓
Elasticsearch Index: docker-{容器名称}-*
日志消费
目的是从 Kafka 消费日志,清洗日志后推送到 ElasticSearch。
由于笔者的需求不多,因此只需要消费日志后打标签推送到 ElasticSearch。
在 /data/logstash 目录创建 logstash.conf 文件,内容如下:
# logstash.conf
input {kafka {bootstrap_servers => "192.168.50.199:9092"topics => ["docker-logs"]codec => "json" # 解析Filebeat输出的JSON格式}
}filter {# 提取Docker容器元数据ruby {code => 'if container_id = event.get("[container][id]")event.set("container_name", event.get("[container][name]") || container_id[0..11])end'}# 智能JSON检测(关键)if [message] =~ /^{.*}$/ {json {source => "message"target => "json_content"remove_field => ["message"]}}# 公共字段清理mutate {remove_field => ["agent", "ecs", "input", "log", "host"]}
}output {elasticsearch {hosts => ["http://192.168.50.199:9200"]index => "docker-%{[container][name]}-%{+YYYY.MM.dd}"user => "ES账号"password => "ES密码"ssl_enabled => false}# 调试用(可选)stdout {codec => rubydebug}
}
注意,这里推送到 ElasticSearch 的日志索引都带有
docker-前缀,可以自行改掉。如果需要启用 ElasticSearch SSL:
ssl_enabled => true ssl_certificate_verification => true cacert => "/path/to/ca.crt"
启动 logstash 服务。
docker pull docker.elastic.co/logstash/logstash:9.1.4
# 国内网络 docker pull logstash:9.1.4
docker run --name logstash -itd --restart=always \
-v /data/logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
docker.elastic.co/logstash/logstash:9.1.4# 国内网络使用以下命令
docker run --name logstash -itd --restart=always \
-v /data/logstash/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
logstash:9.1.4
查看 logstash 的日志,正在消费 Kafka:

logstash 消费能力非常强,启动后短时间就消费了仅 3000w 条日志。

查看 ElasticSearch 输出了对应的容器索引日志。
这里带上了
docker-前缀,如不需要,可以修改logstash.conf的index => "docker-%{[container][name]}-%{+YYYY.MM.dd}"。

如果要在界面按照服务名称搜索和查看日志,需要进入 Discover,添加新的视图。

例如,要查看查看 astrbot 容器的日志,因为日志是按天生成的,所以需要查看 docker-astrbot-* 的所有相关日志,之后即可查看 astrbot 的所有日期的日志。


监控方案
Metrics 毫无疑问固定搭配 Prometheus + Grafana,本文涉及到的组件有 Prometheus、Grafana、pushgateway、node exporter、mysql exporter 等。
Prometheus 只需要固定采集 pushgateway 即可,各类数据源可以自己推送到 pushgateway,省去大量配置 Prometheus 的麻烦。
下面直接开始讲解部署过程。
拉取镜像:
docker pull prom/pushgateway
docker pull prom/prometheus
创建两个目录:
/data/prometheus/config
/data/prometheus/data
先部署 pushgateway。
docker run -d -restart=always --name pushgateway -p 9091:9091 prom/pushgateway
在 /data/prometheus/config 目录新建 prometheus.yml 文件。
global:scrape_interval: 15sevaluation_interval: 15sscrape_timeout: 10sscrape_configs:# 监控Prometheus自身- job_name: 'prometheus'static_configs:- targets: ['localhost:9090']# Pushgateway监控 (核心配置)- job_name: 'pushgateway'honor_labels: true # 关键配置:保留推送的原始标签static_configs:- targets: ['192.168.50.199:9091'] # 替换为 pushgateway 实际IP和端口labels:env: 'prod'component: 'batch_jobs' # 按实际用途标记
部署 Promethes:
docker run -itd --restart=always -p 9090:9090 \
-v /data/prometheus/config/prometheus.yml:/prometheus/prometheus.yml \
-v /data/prometheus/data:/prometheus \
prom/prometheus
部署完成后,打开 Prometheus 地址,查看是否开源正常访问数据源。

部署 node_exporter
目的是监控机器的 CPU、内容、网络等。
在 Github 上下载最新版本 node_exporter: https://github.com/prometheus/node_exporter/releases/tag/v1.9.1
tar -zvxf node_exporter-1.9.1.linux-amd64.tar.gz
mv node_exporter-1.9.1.linux-amd64/node_exporter /usr/local/bin/
制作系统启动项:
cd /etc/systemd/system
nano node_exporter.service
node_exporter.service 内容如下:
[Unit]
Description=Node Exporter
Documentation=https://prometheus.io/docs/guides/node-exporter/
Wants=network-online.target
After=network-online.target[Service]
User=nobody
Group=nogroup
Type=simple
# 启动Node Exporter,默认监听9100端口
ExecStart=/usr/local/bin/node_exporter \--collector.systemd \--collector.processes \--collector.filesystem.ignored-mount-points="^/(sys|proc|dev|host|etc)($$|/)"[Install]
WantedBy=multi-user.target
配置开机自启动:
sudo systemctl daemon-reload
sudo systemctl start node_exporter
sudo systemctl enable node_exporter
sudo systemctl status node_exporter
修改 prometheus.yml 文件,加上:
- job_name: mininodestatic_configs:- targets: ['192.168.50.199:9100']
重启 Prometheus 容器。
部署 Grafana
创建 /data/grafana/storage 目录。
mkdir /data/grafana/storage
docker run -d -p 3000:3000 --name=grafana \--volume /data/grafana/storage:/var/lib/grafana \grafana/grafana:12.1.1
浏览器打开 3000 端口,默认账号密码都是 admin,第一次进入会提示修改密码。
需要在 Grafana 上配置数据源连接到 Prometheus。

点击右上角的 Add new data source,选择 Prometheus。
由于内网部署没有设置密码,因此只需要填写 Connection 地址即可。

可视化配置
前面已经部署了 nodeexporter,用于监控服务器资源,一般我们关注:
CPU 使用率
负载平均值
内存使用率
磁盘 I/O
磁盘使用率
网络接收量
网络传输量
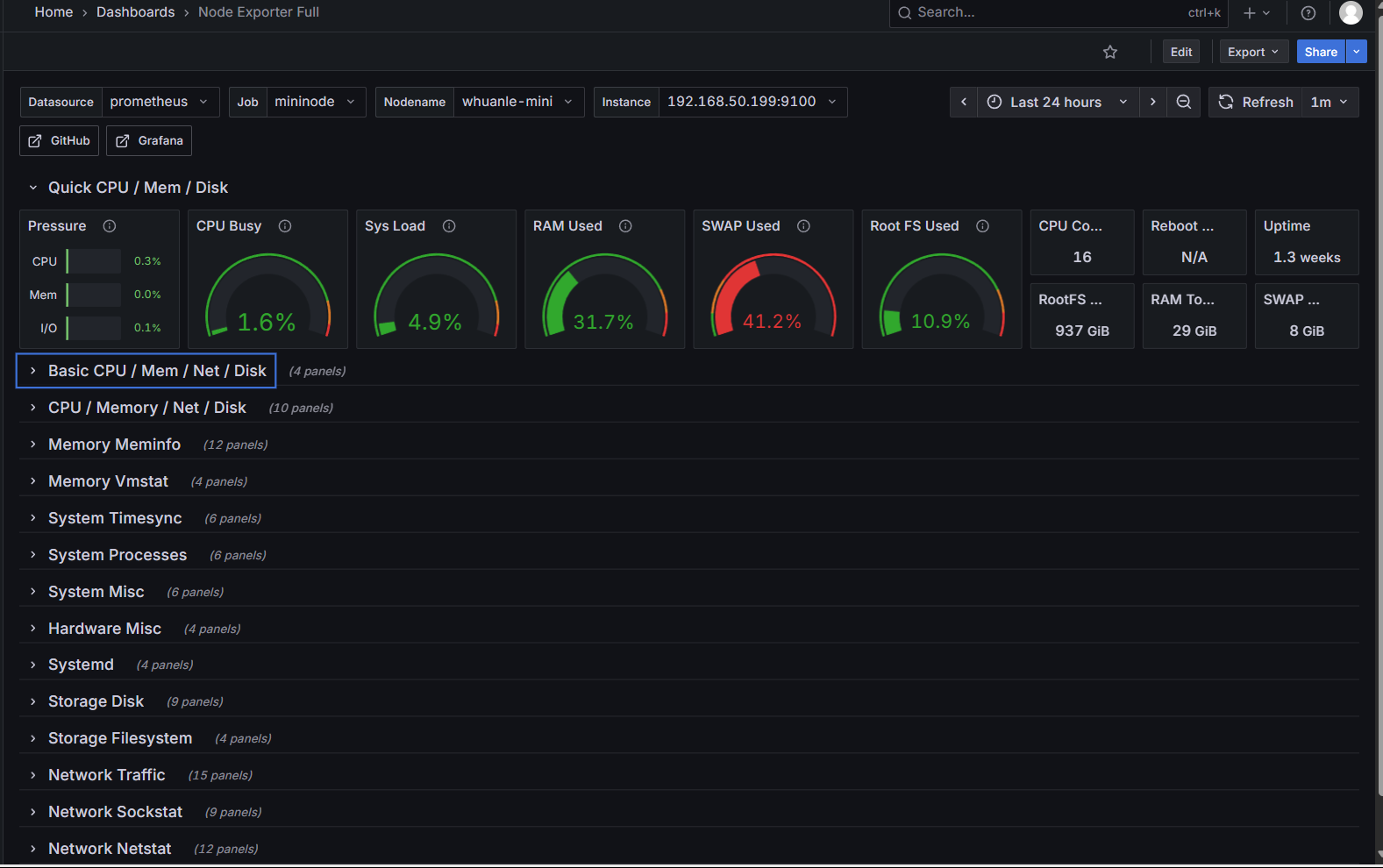
接入 Prometheus 数据源后,不同的数据源需要选择合适的面板显示数据,例如这个 node_exporter 模板:
https://grafana.com/grafana/dashboards/1860-node-exporter-full/
在模板介绍页面,复制 ID 或下载 JSON:

回到 Grafana 导入面板。


导入成功后,可以看到节点的各项数据。
mysql exporter
用于观测 Mysql 数据库的各种性能指标。
在 mysql 创建 exporter 用户:
CREATE USER 'exporter'@'%' IDENTIFIED BY '你的密码' WITH MAX_USER_CONNECTIONS 3;# 授权
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'%';
FLUSH PRIVILEGES;
如果经过授权后 mysql-exporter 不能正常工作,参考:
-- 对于 MySQL 8.0.22 及以上版本
GRANT PROCESS, REPLICATION CLIENT, REPLICATION SLAVE MONITOR, SELECT ON *.* TO 'exporter'@'%';-- 对于 MySQL 8.0.22 以下版本
GRANT PROCESS, REPLICATION CLIENT, REPLICATION SLAVE ADMIN, SELECT ON *.* TO 'exporter'@'%';FLUSH PRIVILEGES;
如果是 MariaDB :
# MariaDB 10.5 及以上版本
-- 授予 SLAVE MONITOR 权限(仅用于监控从库状态,权限更精细)
GRANT SLAVE MONITOR ON *.* TO 'exporter'@'%';# MariaDB 10.4 及以下版本
GRANT SUPER ON *.* TO 'exporter'@'%';FLUSH PRIVILEGES;
在 /data/exporter/mysql 创建 my.cnf 文件。
[client]
host=192.168.50.199
port=3306
user=exporter
password=你的密码
启动 docker:
docker pull prom/mysqld-exporterdocker run -itd --restart=always -p 9104:9104 \
--name mysqld-exporter \
--volume=/data/exporter/mysql/my.cnf:/etc/mysql/my.cnf:ro prom/mysqld-exporter \
--config.my-cnf=/etc/mysql/my.cnf
然后修改 prometheus.yml,增加内容:
- job_name: mysqlstatic_configs:- targets: ['192.168.50.199:9104']
最后我们使用官方的面板 https://grafana.com/grafana/dashboards/14057-mysql/

mysql exporter 主要记录了:
Uptime
Current QPS
InnoDB Buffer Pool
MySQL Connections
MySQL Client Thread Activity
MySQL Questions
MySQL Thread Cache
MySQL Temporary Objects
MySQL Select Types
MySQL Sorts
MySQL Slow Queries
MySQL Aborted Connections
MySQL Table Locks
MySQL Network Traffic
MySQL Internal Memory Overview
Top Command Counters
MySQL Handlers
MySQL Transaction Handlers
Process States
Top Process States Hourly
MySQL Query Cache Memory
MySQL Query Cache Activity
MySQL File Openings
MySQL Open Files
MySQL Table Open Cache Status
MySQL Open Tables
MySQL Table Definition Cache
其他
官方有很多优秀的监控库:https://prometheus.io/docs/instrumenting/exporters/
链路追踪方案
社区上链路追踪使用广泛的有 Jaejer、SkyWalking、Zipkin 等,它们各有优缺点,这里就不一一介绍了。
链路追踪主要是存储器和 UI 两部分,例如 Jaeger 支持内存、Cassandra、ElasticSearch 等方式存储接收到的数据,然后通过操作界面查找、分析链路。
随着云原生的发展,很多组件其实都对 Metrics、Logging、Tracing 有不同程度的支持,例如 ElasticSearch + Kibana 可以直接支持三者,无需另外部署 Prometheus、Grafana。
而 Grafana 家有 Prometheus + Grafana 监控、Grafana Loki 日志、Grafana Tempo 链路追踪,而且也有很多商业一体化的平台。
所以要感觉自身情况选用合适的方案。
为了方便起见,这里选用 Jaeger + ElasticSearch 的方式实现链路追踪。
Jaeger 原生支持接收 OpenTelemetry 协议格式的数据,无需额外部署 OpenTelemetry Collector,所以这里不需要 OpenTelemetry 相关组件的部署。
创建 /data/jaeger/jaeger.yml 文件:
service:extensions: [jaeger_storage, jaeger_query]pipelines:traces:receivers: [otlp]processors: [batch]exporters: [jaeger_storage_exporter]extensions:jaeger_query:storage:traces: elasticsearch_trace_storagemetrics: elasticsearch_trace_storagejaeger_storage:backends:elasticsearch_trace_storage: &elasticsearch_configelasticsearch:server_urls:- http://192.168.50.199:9200username: elasticpassword: "your-password"# 索引配置index_prefix: jaeger# 索引生命周期管理use_ilm: trueilm:policy_name: jaeger-ilm-policyrollover_alias: jaeger-spanpattern: "{now/d}-000001"max_age: 7d # 数据保留7天# 批量写入配置bulk_size: 1000flush_interval: 5smetric_backends:elasticsearch_trace_storage: *elasticsearch_configreceivers:otlp:protocols:grpc:endpoint: "0.0.0.0:4317"http:endpoint: "0.0.0.0:4318"processors:batch:timeout: 10ssend_batch_size: 1024exporters:jaeger_storage_exporter:trace_storage: elasticsearch_trace_storage
启动 Jaeger:
docker run -d \--name jaeger \-p 4317:4317 \-p 4318:4318 \-p 5775:5775/udp \-p 6831:6831/udp \-p 6832:6832/udp \-p 5778:5778 \-p 16686:16686 \-p 14268:14268 \-p 14250:14250 \
-v /data/jaeger/jaeger.yml:/etc/jaeger/jaeger.yml \jaegertracing/all-in-one:latest \--config-file=/etc/jaeger/jaeger.yml
以下是 Jaeger 各组件常用端口及其作用的详细说明:
| 端口号 | 协议 | 组件 / 用途 | 具体作用说明 |
|---|---|---|---|
| 5775 | UDP | Agent (Zipkin) | 接收 Zipkin 兼容的 thrift 协议数据(较少使用) |
| 6831 | UDP | Agent (Jaeger Thrift) | 接收 Jaeger 原生客户端通过 compact 编码格式发送的追踪数据 |
| 6832 | UDP | Agent (Jaeger Thrift) | 接收 Jaeger 原生客户端通过 binary 编码格式发送的追踪数据 |
| 5778 | TCP | Agent/Health Check | 提供 Agent 的配置接口和健康检查端点(可获取采样策略等) |
| 16686 | TCP | Query Service (UI) | Jaeger Web UI 访问端口,通过浏览器访问查看追踪数据 |
| 14268 | TCP | Collector (Jaeger Thrift) | 接收 Jaeger 原生客户端直接发送的追踪数据(不经过 Agent 时使用) |
| 14250 | TCP | Collector (gRPC) | 接收通过 gRPC 协议发送的 Jaeger 格式数据 |
| 4317 | TCP | Collector (OTLP gRPC) | 接收 OpenTelemetry 客户端通过 gRPC 协议发送的追踪数据(OTLP 标准端口) |
| 4318 | TCP | Collector (OTLP HTTP) | 接收 OpenTelemetry 客户端通过 HTTP 协议发送的追踪数据(OTLP 标准端口) |
| 9411 | TCP | Collector (Zipkin) | 兼容 Zipkin 协议的接收端口,用于接收 Zipkin 客户端发送的数据(可选启用) |
访问 16686 端口即可访问 UI。

如果有需要,你可以启动一个任务,将超过一段时间的链路追踪数据移到其它索引中。
docker run -it --rm --net=host \-e CONDITIONS='{"max_age": "2d"}' \-e ES_USERNAME=elastic \-e ES_PASSWORD=你的密码 \jaegertracing/jaeger-es-rollover:latest \rollover http://localhost:9200
如果有需要,你可以启动一个任务,将时间太长的数据删除。
docker run -it --rm --net=host \-e UNIT=days -e UNIT_COUNT=7 \-e ES_USERNAME=elastic \-e ES_PASSWORD=你的密码 \jaegertracing/jaeger-es-rollover:latest \lookback http://localhost:9200
接入 OpenTelemetry
随着 OpenTelemetry 的发展,对 Metrics、Logging、 做了完整的支持,通过 Opentelemetry Collector 统一收集再将其转发到不同的后端,Collector 本身是不存储数据的,它是一个收集器。
不过实践中主要还是作为链路追踪和监控的收集器来使用,很少当作 Logging 收集器。
Opentelemetry 暴露的端口如下:
ports:- 1888:1888 # pprof extension- 8888:8888 # Prometheus metrics exposed by the Collector- 8889:8889 # Prometheus exporter metrics- 13133:13133 # health_check extension- 4317:4317 # OTLP gRPC receiver- 4318:4318 # OTLP http receiver- 55679:55679 # zpages extension
Opentelemetry Collector 在端口还暴露了对应的地址,用来收集不同的内容,例如 /v1/traces 收集链路追踪 /v1/metrics 收集监控。
参考 C# 代码:
builder.Services.AddOpenTelemetry().ConfigureResource(resource => resource.AddService(serviceName)).WithTracing(tracing =>{.AddAspNetCoreInstrumentation().AddOtlpExporter(options =>{options.Endpoint = new Uri("http://192.168.50.199:4318" + "/v1/traces");options.Protocol = OtlpExportProtocol.HttpProtobuf;});}).WithMetrics(metrices =>{metrices.AddAspNetCoreInstrumentation().AddOtlpExporter(options =>{options.Endpoint = new Uri("http://192.168.50.199:4318" + "/v1/metrics");options.Protocol = OtlpExportProtocol.HttpProtobuf;});});
这里我们使用 OpenTelemetry Collector 做统一接入层,接入链路追踪和监控,主要目标是面向后端服务,也就是后端服务统一接入 OpenTelemetry Collector 推送内容。OpenTelemetry Collector 再将链路追踪和监控数据推送到 Jaeger 和 Prometheus。
拉取 OpenTelemetry Collector 镜像。
docker pull otel/opentelemetry-collector-contrib:0.135.0
Prometheus 默认不开启写如果功能,需要加上 --web.enable-remote-write-receiver 环境变量开启写入,还支持使用 --web.enable-otlp-receiver 开启 /api/v1/otlp/v1/metrics OTLP 接收 监控数据。
不过官网提示这两种方式都不是高效的,但是阿里云官方相关的产品用的是 --web.enable-remote-write-receiver 。
参考:https://help.aliyun.com/zh/prometheus/use-cases/write-metrics-to-managed-service-for-prometheus-based-on-opentelemetry-collector
有两种方法接收 Opentelemetry Collector 的 metrics,一种是删除 Prometheus 容器,使用新的命令启动:
docker run -itd --restart=always -p 9090:9090 \
-v /data/prometheus/config/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /data/prometheus/data:/prometheus \
prom/prometheus --web.enable-remote-write-receiver
另一种是推送到 pushgateway,然后 prometheus 采集 pushgateway 即可,下面采用这种方法。
新建 /data/opentelemetry/config.yaml 配置文件:
receivers:# 仅保留 OTLP 接收器(接收应用推送的 OTLP 格式数据)otlp:protocols:grpc:endpoint: "0.0.0.0:4317" # 接收 OTLP gRPC 协议数据http:endpoint: "0.0.0.0:4318" # 接收 OTLP HTTP 协议数据processors:# 批量处理(减少网络请求次数,提高效率)batch:timeout: 10ssend_batch_size: 1024# 资源属性增强(添加环境、集群等标签)resource:attributes:- key: "env"value: "production"action: upsert- key: "cluster"value: "k8s-cluster-01"action: upsertexporters:# 导出追踪数据到 Jaeger(通过 OTLP HTTP 协议)otlphttp/jaeger:endpoint: "http://192.168.50.199:4318"tls:insecure: true# 导出指标数据到 Prometheus(通过 remote_write 协议)prometheusremotewrite:endpoint: "http://192.168.50.199:9090/api/v1/write"tls:insecure: trueheaders:X-Prometheus-Remote-Write-Version: "0.1.0"# 可选:在本地暴露 Prometheus 格式指标(供调试或临时抓取)prometheus:endpoint: "0.0.0.0:8889"const_labels:source: "otel-collector"service:telemetry:logs:level: debug # 调试日志级别,生产环境可改为 infopipelines:# 追踪数据处理管道traces:receivers: [otlp] # 仅接收 OTLP 追踪数据processors: [batch, resource] # 批量处理 + 资源增强exporters: [otlphttp/jaeger] # 导出到 Jaeger# 指标数据处理管道metrics:receivers: [otlp] # 仅接收 OTLP 指标数据processors: [batch, resource] # 批量处理 + 资源增强exporters: [prometheusremotewrite, prometheus] # 导出到 Prometheus 及本地端点如果,你想使用 Collocter 帮你抓取,而不是使用 Prometheus 抓取,可以添加 prometheus 配置,参考:
receivers:# 仅保留 OTLP 接收器(接收应用推送的 OTLP 格式数据)otlp:protocols:grpc:endpoint: "0.0.0.0:4317" # 接收 OTLP gRPC 协议数据http:endpoint: "0.0.0.0:4318" # 接收 OTLP HTTP 协议数据prometheus:config:scrape_configs:- job_name: "otel-collector-self"scrape_interval: 10sstatic_configs:- targets: ["localhost:8888"]- job_name: "your-app"scrape_interval: 15sstatic_configs:- targets: ["app-service:8080"]# 修正:prometheusremotewrite接收器只需要配置端口,不需要路径prometheusremotewrite:endpoint: "0.0.0.0:9090" # 移除了/api/v1/write路径
... 省略 ...
http://192.168.50.199:9091/api/v1/write是 pushgateway 的地址。
启动 opentelemetry-collector-contrib:
docker run -itd \
--name=otelcol \
--restart=always \
-p 1888:1888 \
-p 8888:8888 \
-p 8889:8889 \
-p 13133:13133 \
-p 4317:4317 \
-p 4318:4318 \
-p 55679:55679 \
-v /data/opentelemetry/config.yaml:/etc/otelcol-contrib/config.yaml \
otel/opentelemetry-collector-contrib:0.135.0
由于 Opentelemetry Collector 跟 Jaeger 有端口冲突,因此读者需要修改映射的 4317 、4318 端口。

Grafana 全家桶
本节探索 Grafana Prometheus、Grafana Loki、Grafana Tempo 全家桶方案。
Metrics 方案
在上一节,监控数据通过 Opentelemetry Collector 推送到 Prometheus,这是比较推荐的做法。
当然 Prometheus 也可以直接提供兼容 Collector 接口的功能,要兼容 OpenTelemetry 的 /v1/metrics 接口,需要在 Prometheus 上使用 --web.enable-otlp-receiver 开启 /api/v1/otlp/v1/metrics OTLP 接收 监控数据。
docker run -itd --restart=always -p 9090:9090 \
-v /data/prometheus/config/prometheus.yml:/prometheus/prometheus.yml \
-v /data/prometheus/data:/prometheus \
prom/prometheus \
--web.enable-remote-write-receiver \
--web.enable-otlp-receiver
C# 代码参考:https://opentelemetry.io/docs/languages/dotnet/metrics/getting-started-prometheus-grafana/
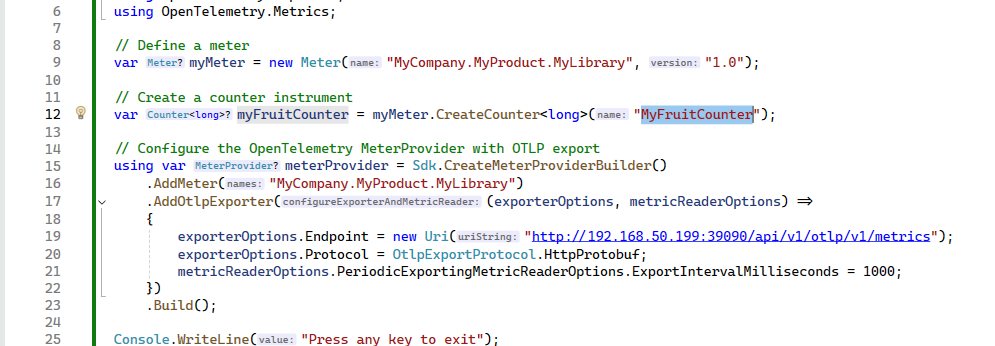

不过还是建议先走 Opentelemetry Collector,由 Collector 走转发。
应用程序只需要统一接口 Collector,具体的后端由运维灵活处理,后期万一某个方案不满足增长需求,只需要替换 Collector 配置即可,后端服务无需修改代码和配置。
Logging 方案
Loki 支持在 Kubernetes 上水平伸缩,不过由于笔者是家庭服务器,因此单机 docker 部署即可满足需求,单机架构适合每天 20GB 左右的少量日志读写。
Loki 日志的资源使用量主要取决于摄入的日志量,根据官方文档的说法,每秒摄入 1 MiB 日志,预计会使用大约
- 1 CPU 核心
- 120 MiB 内存
Grafana 有 Alloy 可以支持对宿主机、容器、Kubernetes 集群采集日志,不过由于习惯上,我们继续使用原本的 Filebeat、Kafka 日志采集方案。
笔者提示,Loki 方案不太成熟,吞吐量没有 ElasticSearch 大,Grafana Alloy 推送的量一大 Loki 就返回 429。
创建 /data/loki/config 、``/data/loki/data目录,在 /data/loki/config` 目录下执行命令下载配置文件。
wget https://raw.githubusercontent.com/grafana/loki/v3.4.1/cmd/loki/loki-local-config.yaml -O loki-config.yaml
配置文件规定了使用 TSDB:
schema_config:configs:- from: 2020-10-24store: tsdbobject_store: filesystem修改 config.yaml 文件,配置 TSDB 存储目录映射到宿主机,以便实现持久化:
auth_enabled: falseserver:http_listen_port: 3100grpc_listen_port: 9096log_level: debuggrpc_server_max_concurrent_streams: 1000common:instance_addr: 192.168.50.199path_prefix: /var/lib/loki # 更改为非临时目录storage:filesystem:chunks_directory: /var/lib/loki/chunksrules_directory: /var/lib/loki/rulesreplication_factor: 1# 单机部署,集群部署需要使用 consulring:kvstore:store: inmemoryquery_range:results_cache:cache:embedded_cache:enabled: truemax_size_mb: 100limits_config:metric_aggregation_enabled: trueschema_config:configs:- from: 2020-10-24store: tsdbobject_store: filesystemschema: v13index:prefix: index_period: 24hpattern_ingester:enabled: truemetric_aggregation:loki_address: 192.168.50.199:3100ruler:alertmanager_url: http://192.168.50.199:9093frontend:encoding: protobuf
启动 Loki 服务:
docker run --name loki -itd --restart=always \
-v /data/loki/config:/mnt/config \
-v /data/loki/data:/var/lib/loki \
-p 3100:3100 \
-p 9096:9096 \
grafana/loki:3.4.1 \
-config.file=/mnt/config/loki-config.yaml
部署 loki 后,还需要做两个事情,一个是使用 Prometheus 监控 Loki 的 http://:3100/metrics 地址,一个是使用 Alloy 消费 Kafka 日志推送到 Loki。
修改 prometheus.yml 文件,添加配置并重启 Prometheus 容器。
- job_name: lokistatic_configs:- targets: ['192.168.50.199:3100']

要将 logstash 的数据推送到 Loki,需要安装插件, Loki 官方不推荐这样用,官方推送使用 Grafana Alloy ,或者接入 OpenTelepmetry。
由于 Logstash 推送到 Loki 的配置比较麻烦,因此这里就不使用 了。
读者可参考:https://grafana.org.cn/docs/loki/latest/send-data/logstash/
Grafana Alloy 是官方主推的日志采集方案组件,功能类似 Filebeat、Logstash。

图片来自 Grafana 官网文档。
Alloy 流水线由执行特定功能的组件构建而成,对于日志,这些组件可以分为三类:
- 采集器: 这些组件从各种源采集/接收日志。这包括从文件抓取日志、通过 HTTP、gRPC 接收日志或从消息队列采集日志。
- 转换器: 这些组件用于在日志发送到写入器之前对其进行处理。例如,可以添加额外元数据、过滤日志或在发送前批量处理日志。
- 写入器: 这些组件将日志发送到目标目的地。重点介绍如何将日志发送到 Loki,但 Alloy 支持将日志发送到各种目的地。
Alloy 可以采集 Filebeat 推送到 Kafak 的日志,然后处理再推送到 Loki,或者 Alloy 直接采集 Docker 和 主机的日志,但是既然已经有 Filebeat 了,我们就不折腾采集这一步了,而是使用 Alloy 替换 Logstash 这一步。
Grafana Loki
部署 Loki 之后,需要在 Grafana 里面显示 Loki,添加数据源。

然后使用 13186 模板显示 Loki 日志: https://grafana.com/grafana/dashboards/13186-loki-dashboard/

Filebeat + Kafka + Alloy
创建 /data/alloy/data 目录,在 /data/alloy/config 目录下创建 config.alloy 文件:
loki.source.kafka "local" {brokers = ["192.168.50.199:9092"]topics = ["docker-logs"]labels = {component = "loki.source.kafka"}forward_to = [loki.process.add_labels.receiver]use_incoming_timestamp = truerelabel_rules = loki.relabel.kafka.rules
}loki.process "add_labels" {// 解析 JSON 消息内容,提取 container.name、host.name 等字段stage.json {expressions = {container_name = "container.name",host_name = "host.name",image_name = "container.image.name",}}// 将提取的字段作为标签stage.labels {values = {container = "container_name",host = "host_name",image = "image_name",}}forward_to = [loki.write.local.receiver]
}loki.relabel "kafka" {forward_to = [loki.write.local.receiver]rule {source_labels = ["__meta_kafka_topic"]target_label = "topic"}
}loki.write "local" {endpoint {url = "http://192.168.50.199:3100/loki/api/v1/push"}
}
启动 alloy:
docker run -itd --restart=always \-v /data/alloy/config/config.alloy:/etc/alloy/config.alloy \-v /data/alloy/data:/var/lib/alloy/data \-p 12345:12345 \grafana/alloy:latest \run --server.http.listen-addr=0.0.0.0:12345 --storage.path=/var/lib/alloy/data \/etc/alloy/config.alloy
重启 Loki,会发现 Kafka 多了一个消费者:

在 Grafana 下的 Drilldown/Logs 可以看到被收集的日志。
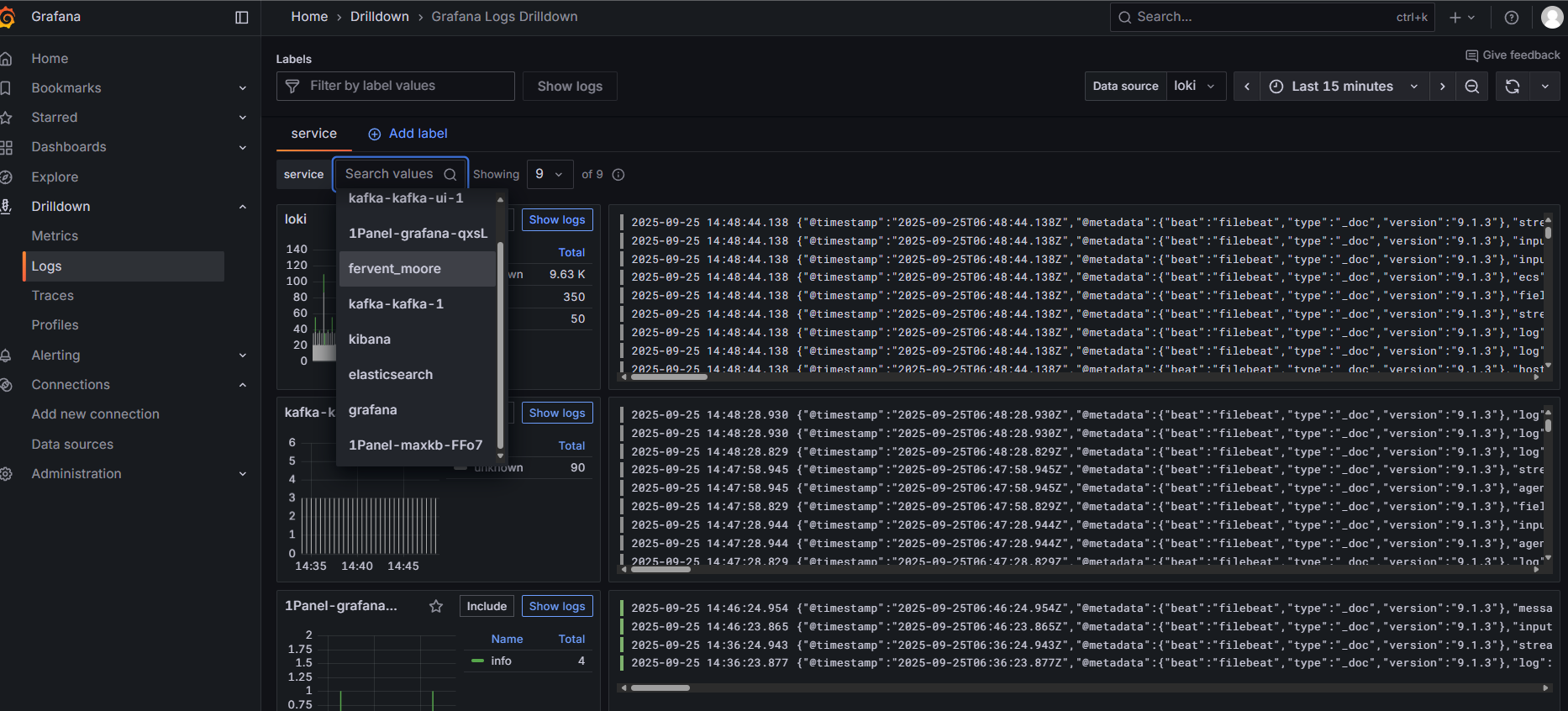
Alloy 的资料太少了,要定制化比较困难,例如从 Kafka 的 docker-logs 主题消费后,需要给消息打标签,以便可以筛选对应的容器日志,笔者陆陆续续搞了两天,使用了元宝、豆包和 Grafana 自己的 Grot AI 都不行,最后根据文档重新换了个办法才行。生产级别的使用需求会比较复杂,使用 Alloy 折腾配置需要消耗非常多的时间,而且 Loki 的吞吐量似乎没有 ElasticSearch 高,资料也少,还是建议采用 ElasticSearch 存储方案。
Loki 吞吐量似乎不高,Alloy 消费推送带 Loki ,量大了会被拒绝。

所以笔者并不建议使用 Loki 做日志存储后端,省得折腾。
Tracing 方案
Tempo 挺值得用,可以轻松应对中小公司的数据量,搭配 Grafana 的 UI,用起来挺方便。
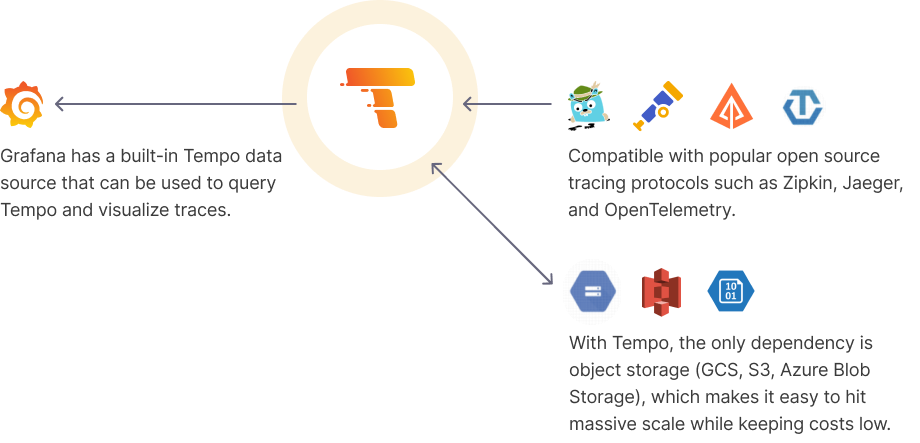
Tempo 主要使用 OSS 存储数据,利用 memcached 的加快 trace id 筛选和查询的速度,但是感觉数据量非常大之后,OSS 查询比较吃力,查询会缓慢,可能需要维护者调整各类压缩配置等。
Tempo 的配置项非常多,对压缩、存储、搜索等涉及的配置非常多,维护者要注意不同事情的数据和数据量如何合理配置。
拉取 Tempo 仓库:
git clone https://github.com/grafana/tempo.git
这里只使用到官方的
tempo.yaml文件,如拉取仓库可能,只需要下载 https://github.com/grafana/tempo/blob/main/example/docker-compose/local/tempo.yaml
创建 /data/tempo/data 目录,在 /data/tempo/ 下创建 docker-compose.yaml 文件。
services:init:image: &tempoImage grafana/tempo:latestuser: rootentrypoint:- "chown"- "10001:10001"- "/var/tempo"volumes:- /data/tempo/data:/var/tempomemcached:image: memcached:1.6.38container_name: memcachedports:- "11211:11211"environment:- MEMCACHED_MAX_MEMORY=64m # Set the maximum memory usage- MEMCACHED_THREADS=4 # Number of threads to usetempo:image: *tempoImagecommand: [ "-config.file=/etc/tempo.yaml" ]volumes:- /data/tempo/tempo.yaml:/etc/tempo.yaml- /data/tempo/data:/var/tempoports:- "14268:14268" # jaeger ingest- "3200:3200" # tempo- "9095:9095" # tempo grpc- "4317:4317" # otlp grpc- "4318:4318" # otlp http- "9411:9411" # zipkindepends_on:- init- memcachedk6-tracing:image: ghcr.io/grafana/xk6-client-tracing:v0.0.7environment:- ENDPOINT=tempo:4317restart: alwaysdepends_on:- tempo
k6-tracing是模拟产生链路追踪信息的程序,可以去掉。Memcached 缓存主要用于通过存储所有后端块的布隆过滤器(在每次查询时访问)来提升查询性能。
由于 tempo 服务启动的端口跟 jaeger、Opentelemetry Collector 冲突,所以需要先把这两个停掉。
修改 tempo.yaml 文件,复制到 /data/tempo/tempo.yaml,替换 Prometheus 地址:
如果从 git 仓库找,位置在
example/docker-compose/local/tempo.yaml。
storage:path: /var/tempo/generator/walremote_write:- url: http://192.168.50.199:9090/api/v1/writesend_exemplars: true
执行 docker-compose up -d 部署,然后在 Grafana 添加 Tempo 数据源,在 Drilldown/Traces 可以看到一些数据,但是主要使用 Explore 菜单检索和分析链路。
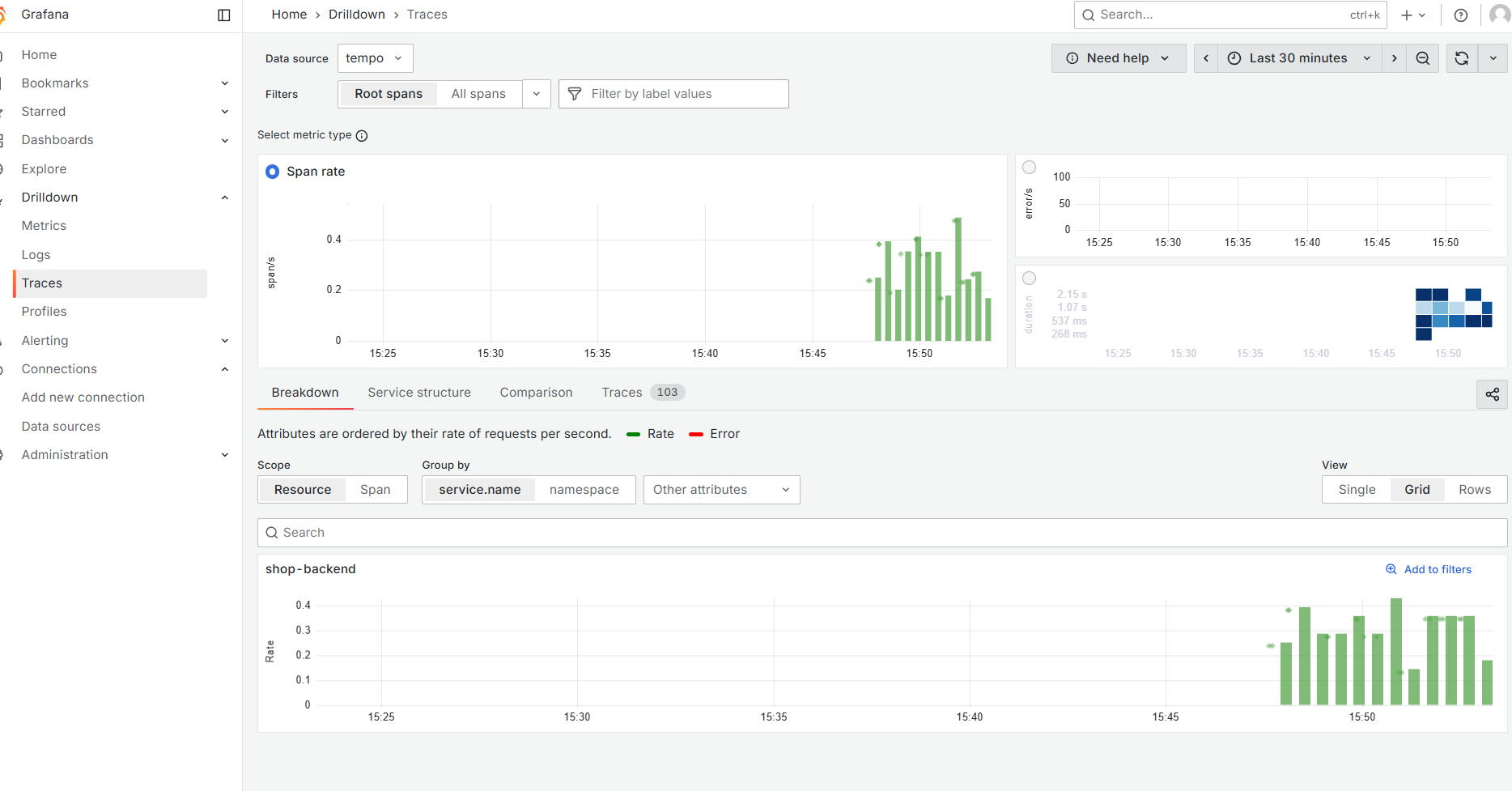
在各种链路追踪 UI 里面,感觉 Tempo 的 UI 非常舒服。


默认 Tempo 使用的是本地 TSDB 存储,不支持分布式存储,所以对于业务量大的公司,使用 OSS 存储。
不过 TSDB 确实性能强。
另外考虑到,公司业务比较大时,链路追踪数据量增长速度快,需要将太长时间之前链路数据移动到其它地方。
修改 tempo.yaml 文件,找到以下内容:
storage:trace:backend: local # backend configuration to usewal:path: /var/tempo/wal # where to store the wal locallylocal:path: /var/tempo/blocks
修改为:
storage:trace:backend: s3s3:endpoint: 192.168.50.199:9000 # 例如 s3.us-east-1.amazonaws.com 或 MinIO 的地址bucket: tempo # S3 存储桶名称access_key: <ACCESS_KEY> # S3 Access Keysecret_key: <SECRET_KEY> # S3 Secret Keyregion: <REGION> # 区域(可选,部分 S3 兼容存储需要)insecure: true # 如果使用 http 协议,需设置为 trueforcepathstyle: true # 对于 MinIO 等 S3 兼容存储建议开启
笔者使用的是 MinIO,相对比较简单,另外阿里云、腾讯云等云服务商的对象存储都支持 S3 协议。
不过 Tempo 本身没有自动数据过期或清理机制,所以需要依赖 OSS 本身的对象过期机制,例如 MinIO 可以使用 mc 工具每天处理过期的对象,移动到低频存储或删除。
参考:https://min-io.cn/docs/minio/linux/administration/object-management/create-lifecycle-management-expiration-rule.html
至于 SkyWalking + ElasticSearch 之类的方案,这里就不再讲解,读者可以自行尝试。
低成本的 ClickStack 可观察性平台
本节介绍基于 Clickhouse 家的产品 ClickStack 建设低成本的课观测性平台。
ClickStack 是一个基于 ClickHouse 和 OpenTelemetry (OTel) 的生产级可观测性平台,统一了日志、跟踪、指标和会话,提供单一高性能解决方案。旨在监控和调试复杂系统,ClickStack 使开发者和 SRE 能够端到端地追踪问题,无需在工具之间切换或手动使用时间戳或关联 ID 拼凑数据。
介绍来自官网:https://clickhouse.com/docs/zh/use-cases/observability/clickstack/overview

图片来自 ClickStack 官网文档。
ClickStack 由三个核心组件组成:
- HyperDX UI – 专为探索和可视化可观察性数据而设计的前端
- OpenTelemetry collector – 一个定制构建的、预配置的收集器,具有针对日志、跟踪和指标的立场导向架构
- ClickHouse – 堆栈核心的高性能分析数据库
这些组件可以独立或一起部署,官方都提供了镜像,部署起来比较简单。
为了方便起见,笔者这里使用 All-in-One 的方式部署,单个 Docker 容器部署所有组件,但是生产需要容错、分布式部署时建议根据官方的文档部署。如果规模小、要求不高,All-in-One 是个不错的选择,一个容器支撑三大组件,不需要那么多中间件服务。
官方文档地址:https://clickhouse.com/docs/zh/use-cases/observability/clickstack/deployment
| 名称 | 描述 | 适用对象 | 限制 |
|---|---|---|---|
| All-in-One | 单个 Docker 容器,捆绑了所有 ClickStack 组件。 | 演示、局部全栈测试 | 不推荐用于生产 |
| Helm | 官方的 Helm 图表,用于基于 Kubernetes 的部署。支持 ClickHouse Cloud 和生产扩展。 | Kubernetes 上的生产部署 | 需要 Kubernetes 知识,需通过 Helm 进行自定义 |
| Docker Compose | 通过 Docker Compose 单独部署每个 ClickStack 组件。 | 本地测试、概念验证、在单个服务器上的生产、自管理 ClickHouse | 无容错能力,需要管理多个容器 |
| HyperDX Only | 独立使用 HyperDX,并使用您自己的 ClickHouse 和架构。 | 现有 ClickHouse 用户、自定义事件管道 | 不包括 ClickHouse,用户必须管理数据摄取和架构 |
| Local Mode Only | 完全在浏览器中运行,使用本地存储。没有后端或持久性。 | 演示、调试、与 HyperDX 的开发 | 无身份验证,无持久性,无警报,仅限单用户 |
部署 ClickStack
新建目录:
mkdir /data/clickstack
mkdir /data/clickstack/db
mkdir /data/clickstack/ch_data
mkdir /data/clickstack/ch_logschmod -R 777 /data/clickstack/*
部署服务:
docker run -itd --restart=always \-p 8080:8080 \-p 4317:4317 \-p 4318:4318 \-e FRONTEND_URL="http://192.168.50.199:8080" \-v "/data/clickstack/db:/data/db" \-v "/data/clickstack/ch_data:/var/lib/clickhouse" \-v "/data/clickstack/ch_logs:/var/log/clickhouse-server" \docker.hyperdx.io/hyperdx/hyperdx-all-in-one
国内用户有配置镜像加速器,可去掉镜像的
docker.hyperdx.io/前缀。
部署选项 | ClickHouse Docs
打开 8080 端口,访问 HyperDX UI。


打开 Team Settings 配置,复制 API Key,对接 OpenTelemetry 协议推送数据时需要使用。

为了观察 ClickStack 的使用,你可以写程序推送数据,也可以使用官方的模拟数据。
官方模拟数据教程:https://clickhouse.com/docs/zh/use-cases/observability/clickstack/getting-started/sample-data#load-sample-data

ClickStack 默认已经配置好了各种数据源。
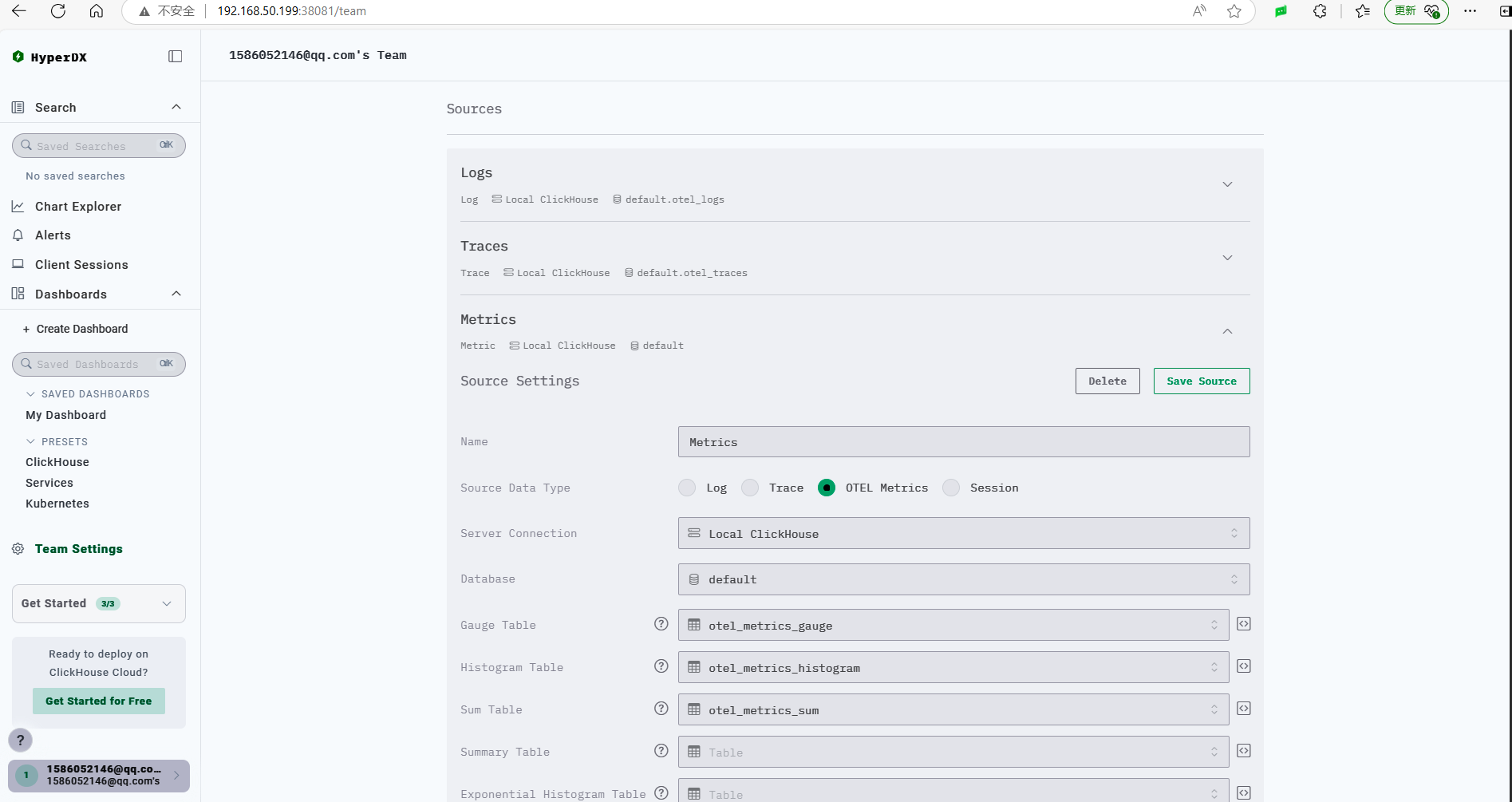
如果需要查看只需要数据源,需要在左侧菜单 Search 操作。

搜索 Traces
以 Traces 为例,默认 ClickStack 按照 span 来显示,你可以点击到具体的 span 后,搜索对应的 TraceId 或者使用 TraceId = 'ea32fc1170b28d49f40b897b4624b6f4' 这样的条件查找。


动图演示:

搜索 Logs
ClickStack 的日志有个好用的功能,就是可以自动聚合上下文,例如如图,这条日志有对应的 TraceId ,Surrounding Context 就是相同的 TraceId 中按时间顺序发生的日志列表。

查看 Metrics
ClickStack 的图表没有 Grafana 看起来舒服,界面比较原始。
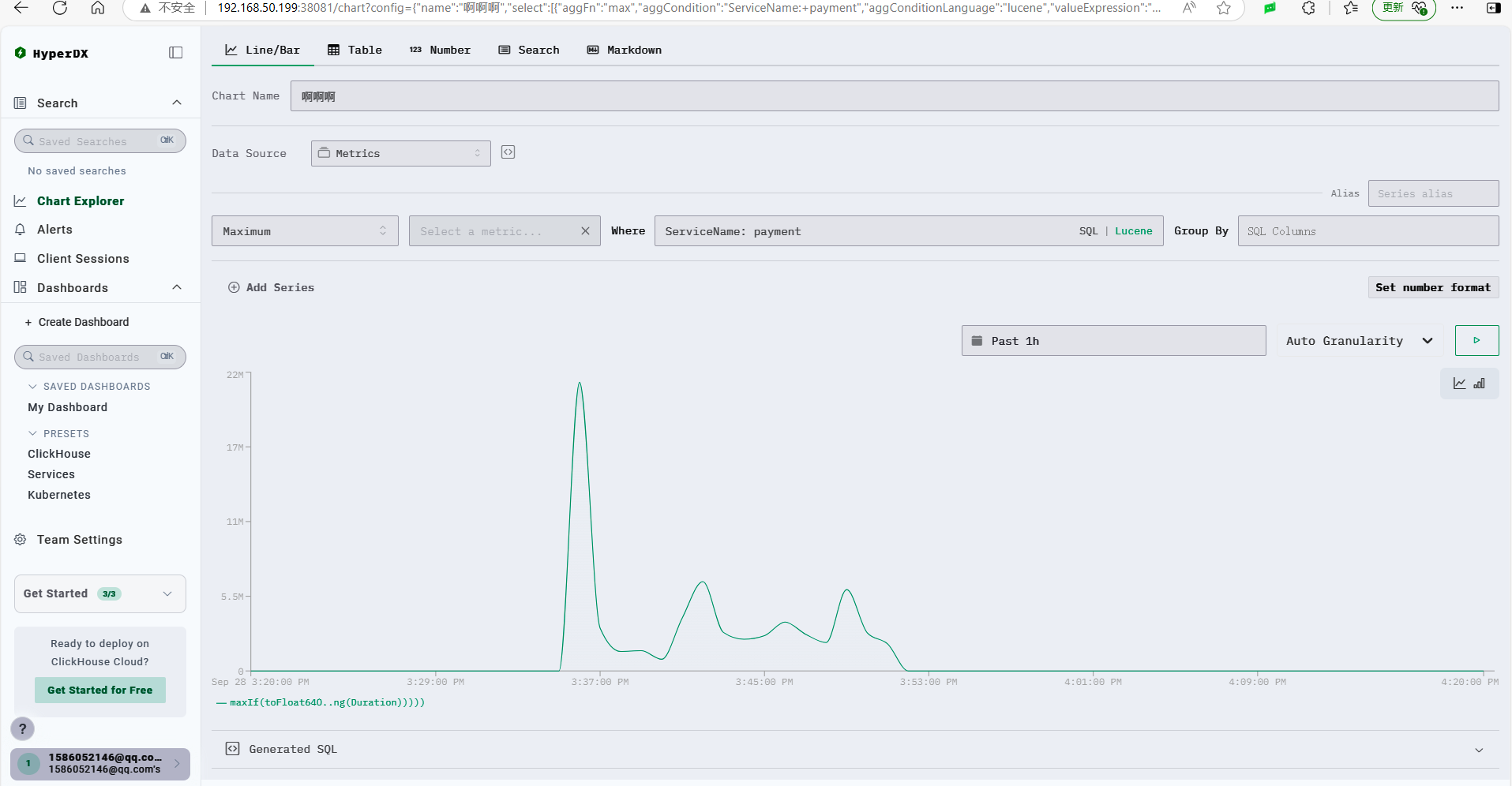
比如笔者的 demo 程序有个 orders.created 订单创建计数器,每下一个订单,计算器 +1。

你可以新增面板,在里面添加需要显示的图表。
不过功能没有 Grafana 强大,并且没有社区模板,需要自行一点点配置。

其它
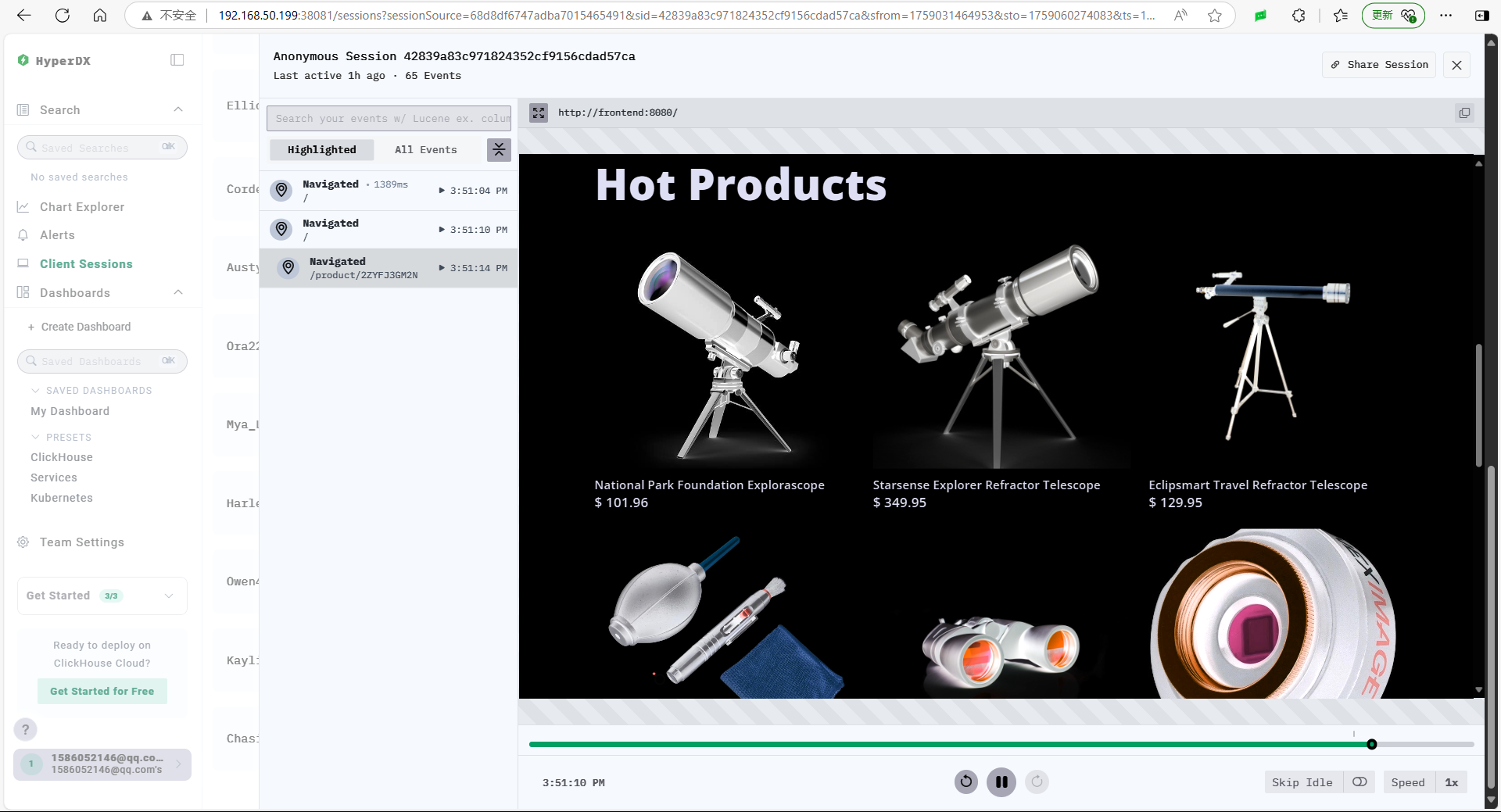
ClickStack 有个非常好用的功能叫回话回放,可以记录用户在页面进行的操作。







)












 总结)