![[LOGO]:CoreKSets](https://i-blog.csdnimg.cn/direct/731088657ae348d4a1f679ad3008534a.png)
【核知坊】:释放青春想象,码动全新视野。
我们希望使用精简的信息传达知识的骨架,启发创造者开启创造之路!!!
内容摘要: 算法是解决问题的系统化步骤,不同的问题常常可以通过多种算法解决。常见的排序算法包括选择排序、冒泡排序和归并排序等。算法的效率通常通过时间和空间复杂度来衡量。
关键词:算法 排序 算法复杂度
其他相关文章:
[计算机科学#12]:高级编程语言基本元素,迅速上手编程-CSDN博客
[计算机科学#11]:编程语言简史,从二进制到简约表达的华丽转身,造就原因——“懒”-CSDN博客
[计算机科学#10]:早期的计算机编程方式-CSDN博客
算法
算法(algorithm)在数学和计算机科学之中,指一个被定义好的、计算机可施行其指示的有限步骤或次序,常用于计算、数据处理和自动推理。算法可以使用条件语句通过各种途径转移代码执行(称为自动决策),并推导出有效的推论(称为自动推理),最终实现自动化。简单来说,算法就是解决问题的具体步骤。
解决同一个问题可以使用不同的算法,不同的算法可能复杂度不同,运算时间不同,内存使用效率也不同,具体的选择根据实际应用场景决定。
排序算法
最常见的算法问题当属排序算法,例如网上购物时,我们需要同一种商品,为了找到价格便宜且质量好的商品,我们会选择筛选排序,将适合的商品置顶供我们选择。还有手机里的通讯录,可以按照首字母顺序排列,也可以按照联系频率排列。
排序算法针对的数据都是相同性质的数据,这些数据的数量一般都大于1,将他们汇集在一起时,我们统称这种数据格式叫“数组”。例如通讯录里的人名:名字数组=[阿星,李逵,泡泡龙,Koro, 小李,大力];或者一组数字:整数数组=[12,334,13,76,34,55] 。
选择排序
选择排序(Selection Sort)是一种简单直观的排序算法。它的基本思想是:每一轮从未排序的元素中选出最小(或最大)值,放到已排序序列的末尾,直到所有元素都排序完成。
🧠 核心思想:每次从未排序的部分中找出最小(或最大)元素,放到已排序部分的末尾
例如使用[12,334,13,76] 进行演示:首先找到最小的数字 min=12 ,放入已排序数组中[12,];然后再在剩余数字[334,13,76]寻找最小值min=13,放入已排序数组中[12,13];重复这个步骤,最终获得[12,13,76,334]。
下列是使用Python实现的选择排序算法:
def selection_sort(arr):n = len(arr)for i in range(n):min_idx = i# 找到未排序部分的最小元素for j in range(i + 1, n):if arr[j] < arr[min_idx]:min_idx = j# 如果找到更小的元素,则交换if min_idx != i:arr[i], arr[min_idx] = arr[min_idx], arr[i]return arr# 示例数组array = [12, 334, 13, 76, 34, 55]sorted_array = selection_sort(array)print("排序结果:", sorted_array)#排序结果: [12, 13, 34, 55, 76, 334]冒泡排序
冒泡排序(Bubble Sort)是一种简单直观的排序算法。其核心思想是通过重复比较相邻元素并交换它们的位置,使较大的元素逐步“冒泡”到序列的末尾。这个过程就像气泡上升一样,因此得名“冒泡排序”。
🧠 核心思想:通过多次遍历序列,比较并交换相邻的元素,使未排序部分的最大元素逐步移动到序列的末尾。
例如使用[12,334,13,76] 进行演示:
第 1 轮,比较 12 和 334:12 < 334,不交换; 比较 334 和 13:334 > 13,交换,数组变为 [12, 13, 334, 76]; 比较 334 和 76:334 > 76,交换,数组变为 [12, 13, 76, 334];第 1 轮结束,最大值 334 已“冒泡”到数组末尾。
第 2 轮,比较 12 和 13:12 < 13,不交换; 比较 13 和 76:13 < 76,不交换;第 2 轮结束,次大值 76 已到位。
第 3 轮,比较 12 和 13:12 < 13,不交换;第 3 轮结束,数组已完全有序,[12, 13, 76, 334]
下列是使用Python实现的冒泡排序算法:
def bubble_sort(arr):n = len(arr)for i in range(n):# 标志位,用于检测本轮是否有交换swapped = Falsefor j in range(0, n - i - 1):# 如果前一个元素大于后一个元素,交换它们if arr[j] > arr[j + 1]:arr[j], arr[j + 1] = arr[j + 1], arr[j]swapped = True# 如果本轮没有发生交换,说明序列已经有序if not swapped:breakreturn arr# 示例数组array = [12, 334, 13, 76, 34, 55]sorted_array = bubble_sort(array)print("排序结果:", sorted_array)#排序结果: [12, 13, 34, 55, 76, 334]归并排序
归并排序(Merge Sort)是一种高效、稳定的排序算法,采用分治法(Divide and Conquer)策略。
🧠核心思想
其核心思想是将数组分成两个子数组,分别对子数组进行排序,然后合并两个有序子数组以得到最终的排序结果。
-
分解(Divide):将待排序的数组分成两个子数组。
-
解决(Conquer):递归地对两个子数组进行归并排序。
-
合并(Merge):将两个已排序的子数组合并成一个有序数组。
例如使用[12,334,13,76] 进行演示:
分解:将数组分成两部分:[12, 334] 和 [13, 76]。继续分解:[12, 334]→[12]和 334→[13]和 [76]
合并: 合并 [12] 和 [334],比较 12 和 334,12 较小,放入新数组。将剩下的 334 放入新数组。结果为 [12, 334]。合并 [13] 和 [76]:比较 13 和 76,13 较小,放入新数组。将剩下的 76 放入新数组。结果为 [13, 76]。合并 [12, 334] 和 [13, 76]:比较 12 和 13,12 较小,放入新数组。比较 334 和 13,13 较小,放入新数组。比较 334 和 76,76 较小,放入新数组。将剩下的 334 放入新数组。结果为 [12, 13, 76, 334]。
下列是使用Python实现的归并排序算法:
def merge_sort(arr):if len(arr) <= 1:return arr# 分解mid = len(arr) // 2left_half = merge_sort(arr[:mid])right_half = merge_sort(arr[mid:])# 合并return merge(left_half, right_half)def merge(left, right):result = []i = j = 0# 合并两个有序子数组while i < len(left) and j < len(right):if left[i] <= right[j]:result.append(left[i])i += 1else:result.append(right[j])j += 1# 添加剩余元素result.extend(left[i:])result.extend(right[j:])return result# 示例数组array = [12, 334, 13, 76]sorted_array = merge_sort(array)print("排序结果:", sorted_array)# 排序结果: [12, 13, 76, 334]Dijkstra路径算法
Dijkstra算法是一种用于在带权图中寻找从单一源点到所有其他节点的最短路径的贪心算法。它广泛应用于地图导航、网络路由和资源调度等领域。
🧠 核心思想:Dijkstra算法的核心思想是:从起始节点出发,逐步扩展到邻近节点,始终选择当前已知最短路径的节点进行处理,并更新其邻居的最短路径估计。
算法步骤:
-
初始化:
-
为每个节点设置一个初始距离,起始节点为0,其他节点为∞。
-
创建一个未访问节点的集合。
-
-
选择当前节点:
-
从未访问节点中选择距离起始节点最小的节点作为当前节点。
-
-
更新邻居距离:
-
对于当前节点的每个邻居,计算从起始节点经过当前节点到该邻居的路径长度。
-
如果该路径长度小于邻居当前的距离估计,更新邻居的距离。
-
-
标记已访问:
-
将当前节点标记为已访问,从未访问集合中移除。
-
-
重复:
-
重复步骤2至4,直到所有节点都被访问或目标节点的最短路径已确定。
-
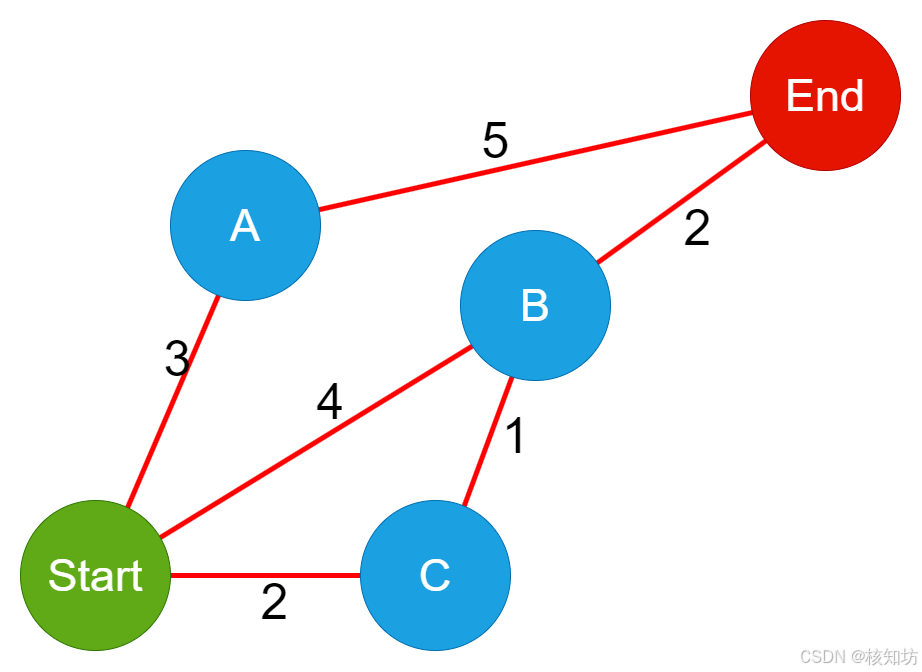
以上图为例,绿色点是起点,红色点是终点,蓝色点是中间的节点,节点之间有直线代表通路,数字代表“代价”或者“权重”。现在我们需要找到一条从起点到终点的最小代价路径。
你可以将该图理解为从你家到学校的行走方式,代价就是花费的时间,例如路径Start->B->End总时间为4+2 = 6小时。
现在我们使用Dijkstra算法找出一条花费最小代价的路径:
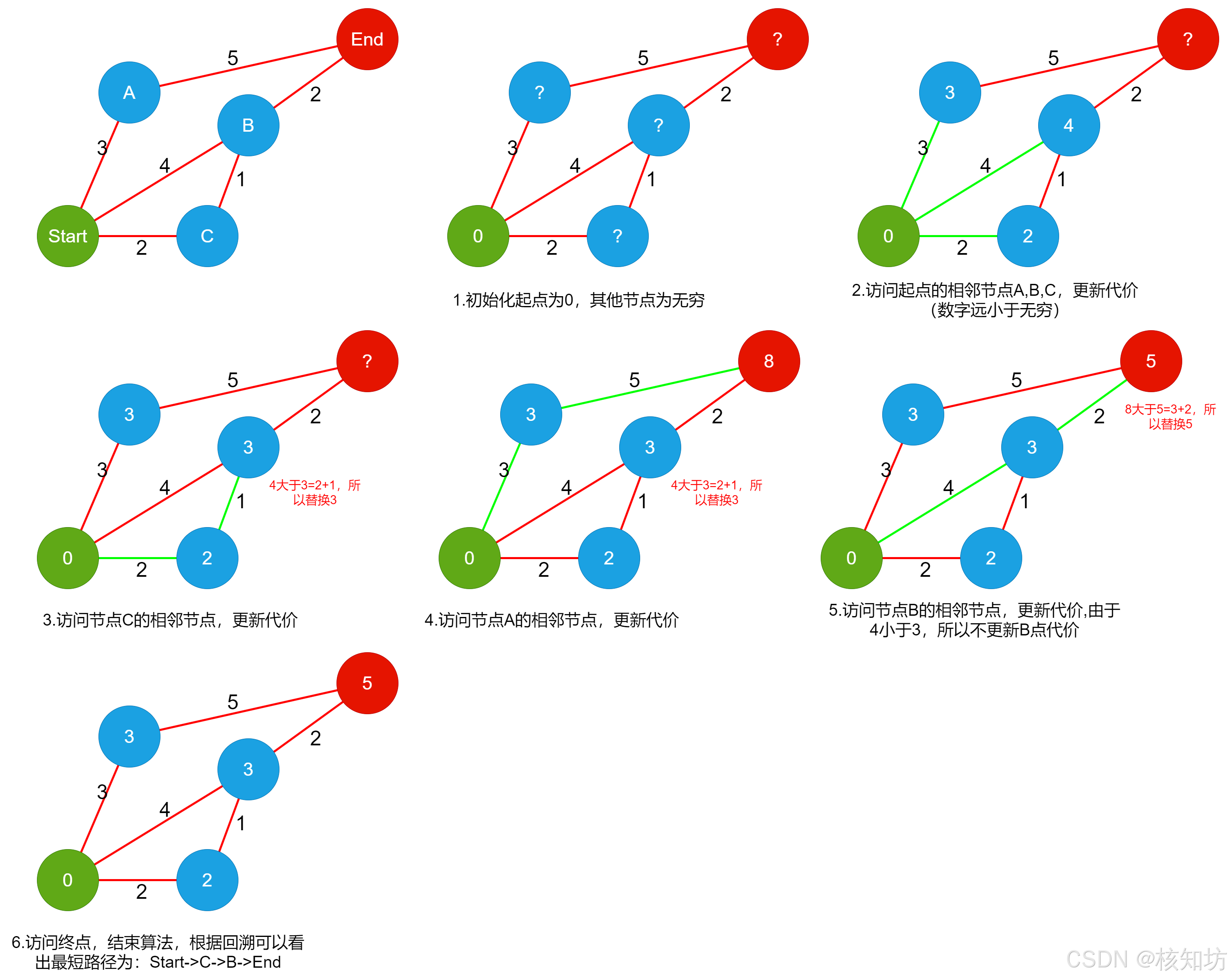
import heapqdef dijkstra(graph, start):# 初始化距离字典,所有节点距离为∞,起始节点距离为0distances = {node: float('inf') for node in graph}distances[start] = 0# 使用优先队列存储待访问节点queue = [(0, start)]while queue:current_distance, current_node = heapq.heappop(queue)# 如果当前距离大于已记录的最短距离,跳过if current_distance > distances[current_node]:continuefor neighbor, weight in graph[current_node].items():distance = current_distance + weight# 如果通过当前节点到邻居的距离更短,更新距离并加入队列if distance < distances[neighbor]:distances[neighbor] = distanceheapq.heappush(queue, (distance, neighbor))return distances# 示例图的邻接表表示graph = {'Start': {'A': 3, 'B': 4, 'C': 2},'A': {'Start': 3, 'End': 5},'B': {'Start': 4, 'End': 2, 'C': 1},'C': {'Start': 2, 'B': 1},'End': {'A': 5, 'B': 2}}# 计算从节点A出发的最短路径shortest_paths = dijkstra(graph, 'Start')print(shortest_paths)#{'Start': 0, 'A': 3, 'B': 3, 'C': 2, 'End': 5}算法复杂度衡量
算法复杂度是指算法在编写成可执行程序后,运行时所需要的资源,资源包括时间资源和内存资源。应用于数学和计算机导论。算法复杂度是衡量算法在执行过程中所需资源(如时间和空间)的一种方式,主要包括时间复杂度和空间复杂度。
⏱ 时间复杂度
时间复杂度用于描述算法执行所需的时间随输入规模增长的变化趋势。它通常用大 O 表示法(Big O notation)来表示。
常见的时间复杂度等级:
-
O(1):常数时间,执行时间不随输入规模变化。
-
O(log n):对数时间,如二分查找。
-
O(n):线性时间,执行时间与输入规模成正比。
-
O(n log n):线性对数时间,如快速排序、归并排序。
-
O(n²):平方时间,如冒泡排序、选择排序。
-
O(2ⁿ):指数时间,如解决某些递归问题。
例如,冒泡排序的时间复杂度为 O(n²),因为它需要进行 n*(n-1)/2 次比较。
🧠 空间复杂度
空间复杂度用于描述算法在执行过程中所需的内存空间随输入规模增长的变化趋势。同样使用大 O 表示法。
常见的空间复杂度等级:
-
O(1):常数空间,算法只需固定数量的空间。
-
O(n):线性空间,所需空间与输入规模成正比。
-
O(n²):平方空间,所需空间与输入规模的平方成正比。
例如,归并排序的空间复杂度为 O(n),因为它需要额外的数组来存储中间结果。
总结
只要与计算机相关的软件,内部都有算法,作为优秀的程序员们,都力求使用最精致的代码完成最高效的算法。
感谢阅览,如果你喜欢该内容的话,可以点赞,收藏,转发。
由于 Koro 能力有限,有任何问题请在评论区内提出,Koro 看到后第一时间回复您!!!
其他精彩内容:
[计算机科学#7]:CPU的三阶段,取指令、解码、执行-CSDN博客
[计算机科学#8]:指令与程序的奥秘-CSDN博客
[计算机科学#9]:更高级的CPU,榨干每个时钟的价值-CSDN博客
参考内容:
Crash Course Computer Science(Y-T)





)





)
)






