注:本文为 “字、半字、字节” 相关文章合辑。
略作重排,未全校。
如有内容异常,请看原文。
理解计算机体系结构中的字、半字与字节
在计算机科学中,理解“字 (Word)”、“半字 (Half-Word)”和“字节 (Byte)”等基本数据单元的精确含义至关重要。这些术语的定义可能因上下文(如 CPU 体系结构或软件开发环境)而异。
一、基本定义
1. 字节 (Byte)
字节是计算机信息计量中最基本的数据单位之一。无论处理器体系结构 (如 8 位、16 位、32 位或 64 位处理器) 如何,1 字节 (Byte) 始终定义为 8 位 (bit)。
一个 ASCII 字符通常占用 1 字节,而一个汉字 (根据编码,如 GBK) 通常占用 2 字节。
2. 字 (Word)
“字 (Word)”是计算机设计中的一个基本参数,通常指 CPU 与内存之间一次数据传送的单位。一个字所包含的字节数(即字的大小或字长)并非固定,而是与特定计算机系统的 CPU 结构及其数据总线宽度密切相关。
CPU 按照其处理信息的字长可以分为 8 位微处理器、16 位微处理器、32 位微处理器以及 64 位微处理器等。
3. 半字 (Half-Word)
“半字 (Half-Word)”的长度通常定义为相应“字”长度的一半。其具体大小同样随处理器体系结构而变化。
4. 其他相关术语
在某些体系结构,特别是 Intel 体系结构中,还存在以下术语:
- 双字 (Double Word, DWORD):通常指字 (Word) 的两倍大小。
- 四字 (Quad Word, QWORD):通常指字 (Word) 的四倍大小,或双字的两倍大小。
二、CPU 体系结构与数据单元
1. CPU 字长与分类
CPU 的字长 (Word Size) 决定了处理器一次能够处理的二进制数据的长度,同时也影响其通用寄存器、内部存储器、算术逻辑单元 (ALU) 的位数以及数据总线的宽度。
根据字长的不同,CPU 可分为:
- 8 位微处理器
- 16 位微处理器
- 32 位微处理器
- 64 位微处理器
2. 总线系统
计算机系统中的总线用于在各部件之间传输信息。
- 数据总线 (Data Bus):用于 CPU 与存储器或 I/O 接口之间双向传输数据。数据总线的位数通常与 CPU 的字长一致,决定了 CPU 一次可以传送的数据量。
- 地址总线 (Address Bus):用于 CPU向外部存储器或 I/O 端口单向传输地址。地址总线的位数决定了 CPU 可直接寻址的内存空间大小。
- 控制总线 (Control Bus):用于传输控制信号和时序信号,其方向和位数取决于具体的控制需求和 CPU 设计。例如,读/写信号、片选信号、中断请求/响应信号等。
3. CPU 寻址能力
CPU 的寻址能力通常以字节为单位进行度量。它表示 CPU 能够访问的最大内存地址范围。例如:
- 一个拥有 32 位地址总线的 CPU,其可寻址 2 32 2^{32} 232 个不同的字节地址,即 4 GB (Gigabytes) 的内存空间。这就是为什么 32 位 CPU 通常最大支持 4 GB 内存的原因。
三、特定平台下的定义与示例
1. 嵌入式与底层开发 (以 CPU 架构为准)
a. ARM 体系结构
ARM 处理器广泛应用于嵌入式系统。
- 字节 (Byte):8 位。
- 半字 (Half-Word):对于 32 位 ARM 架构,半字为 16 位 (2 字节)。这与一些 8 位/16 位处理器体系结构中“字”的长度一致。
- 字 (Word):对于 32 位 ARM 架构 (如 ARM7, ARM9, Cortex-M 系列如 STM32),字为 32 位 (4 字节)。
示例:ARM920T 缓存行
在 ARM920T 的数据手册中提及:
Two 16KB caches are implemented, one for instructions, the other for data, both with an 8-word line size.
实现了两个 16KB 的缓存,一个用于存储指令,另一个用于存储数据,两者的缓存行大小均为 8 个字。
由于 ARM920T 是 32 位架构,1 Word = 4 Bytes。因此,这里的 8-word line size 等于 8 × 4 Bytes = 32 Bytes 8 \times 4 \text{ Bytes} = 32 \text{ Bytes} 8×4 Bytes=32 Bytes。
基于此,U-Boot 代码中为了提高异常处理代码的读取效率,会将异常处理程序进行 32 字节对齐 (因为缓存行大小为 32 字节):
/** exception handlers*/.align 5 /* 2^5 = 32 bytes alignment */undefined_instruction:get_bad_stackbad_save_user_regsbl do_undefined_instruction.align 5software_interrupt:get_bad_stackbad_save_user_regsbl do_software_interrupt.align 5prefetch_abort:get_bad_stackbad_save_user_regsbl do_prefetch_abort.align 5data_abort:get_bad_stackbad_save_user_regsbl do_data_abort
STM32 微控制器 (基于 ARM Cortex-M 内核)
- STM32 通常是 32 位处理器,因此其字是 32 位 (4 字节),半字是 16 位 (2 字节),字节是 8 位。
- 与某些传统 ARM 处理器 (如 ARM7/ARM9) 可能要求严格的地址对齐不同,许多 STM32 型号 (基于 Cortex-M 内核) 支持非对齐访问,允许不同大小的数据类型在内存中紧密存放,从而减少内存浪费。
- 访问寄存器时,建议使用匹配其大小的数据类型。例如,半字型 (16 位) 寄存器建议使用
uint16_t(或等效的u16) 类型变量访问。使用uint8_t(或u8) 可能只能访问低 8 位,而使用uint32_t(或u32) 进行写操作时,行为可能因编译器实现而异。
b. Intel 体系结构
Intel 处理器体系结构从 16 位基础上发展而来,因此其术语有历史延续性。
- 字节 (Byte):8 位。
- 字 (Word):在 Intel 语境下,通常指 16 位 (2 字节) 数据类型,无论是在 16 位、32 位还是 64 位处理器上。
- 半字 (Half-Word):相应地,为 8 位 (1 字节)。
- 双字 (Double Word, DWORD):指 32 位 (4 字节) 数据类型。
- 四字 (Quad Word, QWORD):指 64 位 (8 字节) 数据类型。
下表总结了 Intel 平台常见的定义:
| Intel 处理器平台 | 64 位处理器 | 32 位处理器 | 16 位处理器 |
|---|---|---|---|
| 字 (Word) | 16 位 | 16 位 | 16 位 |
| 半字 (Half-Word) | 8 位 | 8 位 | 8 位 |
| 字节 (Byte) | 8 位 | 8 位 | 8 位 |
| 双字 (Double Word) | 32 位 | 32 位 | 32 位 |
| 四字 (Quad Word) | 64 位 | 64 位 | N/A (通常) |
c. 其他处理器示例 (如 MSP430)
- MSP430 是 16 位微处理器,因此其字 (Word) 是 16 位 (2 字节)。
- 对于 MSP430,半字 (Half-Word) 通常是 8 位 (1 字节),与字节大小相同。
2. 上层应用开发 (以编程语言和操作系统 API 为准)
在高级语言编程或特定操作系统 API 中,WORD 等术语可能有其固定的类型定义。
Windows API 中的数据类型
在 Microsoft Windows 开发中,头文件 WINDEF.H 为常用的数据大小定义了特定类型。例如,在 Visual C++ 6.0 (以及后续版本) 中:
typedef unsigned char BYTE;
typedef unsigned short WORD;
typedef unsigned long DWORD;
这些类型定义如下:
BYTE:定义为unsigned char。在典型的 C/C++ 实现中,char类型长度为 1 字节。因此,BYTE类型的变量占用 1 字节内存。WORD:定义为unsigned short。short类型通常长度为 2 字节。因此,WORD类型的变量占用 2 字节内存。DWORD(Double Word):定义为unsigned long。在 32 位 Windows 编程环境中 (即使在 64 位系统上编译 32 位应用程序),long类型通常长度为 4 字节。因此,DWORD类型的变量占用 4 字节内存。
Windows 计算器示例
Windows 操作系统内置的计算器 (Programmer mode) 也反映了这些约定:
- Byte 选项通常对应 8 位。
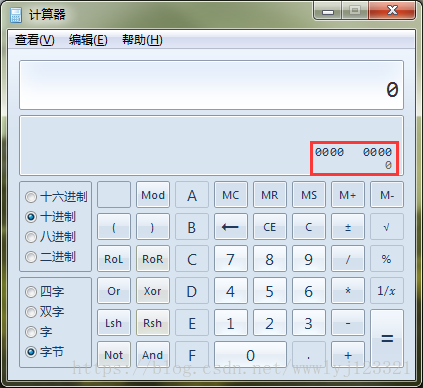
- Word 选项通常对应 16 位。
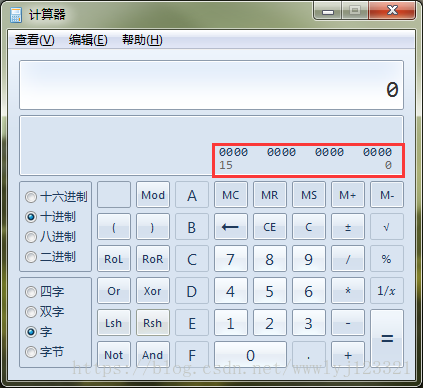
- Dword (Double Word) 选项通常对应 32 位。
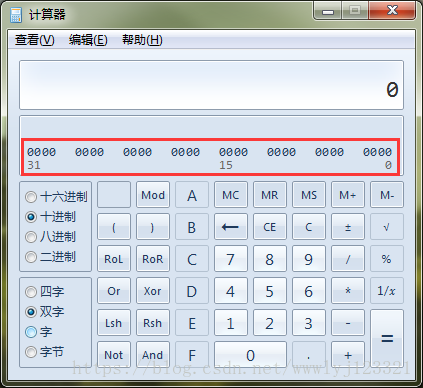
- Qword (Quad Word) 选项通常对应 64 位。

- 这些在计算器中的表示与 Windows API 的类型定义和 Intel 的术语习惯(Word=16-bit)保持一致,且通常与编译目标平台的位数(32-bit vs 64-bit OS/CPU)无关,而是遵循历史定义。
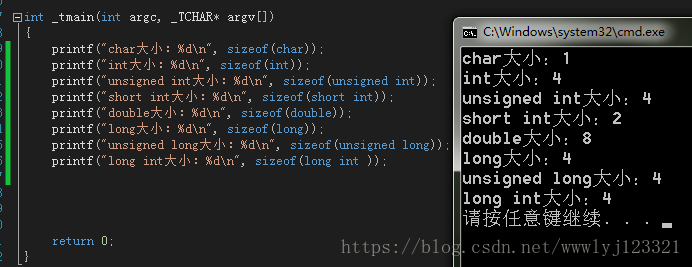
Visual Studio 实验
在 Windows 7 64-bit 系统上使用 Visual Studio 2010 的实验中,分别针对 Win32 和 x64 配置编译,sizeof 运算符的结果如下:
sizeof(BYTE): 1sizeof(WORD): 2sizeof(DWORD): 4sizeof(char): 1sizeof(short): 2sizeof(int): 4sizeof(long): 4sizeof(float): 4sizeof(double): 8sizeof(long long): 8 (C++11 standard, typically 8 bytes on most modern systems)sizeof(bool): 1 (typically)
Win32 配置下的 sizeof 结果示例图示:
x64 配置下的 sizeof 结果示例图示:
这些实验结果表明,在 Windows 开发环境中,
-
BYTE,WORD, 和DWORD的大小是固定的。 -
int和long在 Win32 和 x64 (针对 Windows 的 LLP64 数据模型) 下均为 4 字节。 -
指针类型的大小则会随目标平台变化 (Win32 下为 4 字节,x64 下为 8 字节)。
四、int 类型的大小与 sizeof 运算符的重要性
1. int 类型的大小可变性
int 类型所占用的字节数并非在所有系统和编译器上都相同。它通常与目标机器的“自然”字长 (native word size) 相关,但具体实现由编译器决定。
-
在早期的 16 位系统 (如 Turbo C 编译器环境),
int通常是 2 字节。 -
在 32 位系统 (如许多 GCC 版本或 Visual C++ for Win32),
int通常是 4 字节。 -
在 64 位系统,
int的大小可能会有所不同:- 在许多 Unix-like 系统的 LP64 模型下,
int仍然是 4 字节,而long和指针是 8 字节。 - 在 Windows 的 LLP64 模型下,
int和long均为 4 字节,而long long和指针是 8 字节。
- 在许多 Unix-like 系统的 LP64 模型下,
2. 使用 sizeof 提高代码可移植性与健壮性
由于 int (以及其他一些基本数据类型) 的大小可能因平台和编译器而异,在编写需要精确控制内存大小或进行跨平台移植的代码时,不应硬编码类型的大小 (例如,假定 int 总是 4 字节)。
应使用 sizeof 运算符 来动态获取特定类型或变量在当前编译环境下所占用的字节数。
sizeof() 返回一个数据类型或变量占用的内存地址长度 (以字节为单位)。
示例:动态内存分配
假设需要在机器 A 和机器 B 上为 int 类型数据分配内存。
- 机器 A:
int占用 2 字节。 - 机器 B:
int占用 4 字节。
如果代码硬编码为:
int *i = (int*)malloc(2); // 假定 int 为 2 字节
这段代码在机器 A 上可能正常工作,但在机器 B 上会导致内存分配不足,引发错误。
正确的、可移植的写法是:
int *i = (int*)malloc(sizeof(int));
这样,无论在哪台机器上编译,sizeof(int) 都会返回当前环境下 int 类型的正确大小,确保分配足够的内存。这显著增强了程序的健壮性和在不同处理器及编译环境间的兼容性。
五、总结
“字 (Word)”的大小并非一个绝对固定的值,而是高度依赖于上下文:
-
CPU 体系结构:在底层,一个字的大小通常由 CPU 的数据总线宽度或其“自然”处理单元的大小决定。例如,32 位 CPU 的字通常是 32 位 (4 字节),而 64 位 CPU 的字通常是 64 位 (8 字节)。
-
特定平台约定:某些平台或制造商 (如 Intel) 对“字”有其历史定义,可能与当前 CPU 的主流字长不同 (例如,Intel 语境下 Word 通常指 16 位)。
-
编程语言/API 定义:在高级编程中,如 Windows API,
WORD可能被typedef为一个固定大小的类型 (如unsigned short, 即 16 位)。
与此相对:
- 字节 (Byte):始终为 8 位。
- 半字 (Half-Word):通常是字的一半,其具体大小也随“字”的定义而变。
- 双字 (Double Word):通常是字的两倍。
因此,在讨论“一个字占多少字节?”时,必须明确其所处的具体环境。
- 字、半字、字节的大小取决于处理器架构和平台。
- 字节始终为 8 位,半字为字的一半,双字为字的两倍。
- 在开发中,应使用
sizeof函数动态获取数据类型大小,避免硬编码。
为确保代码的准确性和可移植性,特别是在处理依赖于数据类型大小的操作时,应优先使用 sizeof() 运算符。
via:
-
WORD 是 2Bytes 还是 4bytes?-enzo26-ChinaUnix博客
http://blog.chinaunix.net/uid-21977330-id-3801847.html -
字、半字、字节的定义 - CSDN 博客
https://blog.csdn.net/guosir_/article/details/78346472 -
字 (word)、字节 (byte)、半字 (half-word) 的理解_word byte-CSDN 博客
https://blog.csdn.net/breadheart/article/details/113482110 -
字、半字、字节理解 - CSDN 博客
https://blog.csdn.net/Yin_w/article/details/129909536 -
ARM 中的字、半字、字节是多少位? - CSDN 博客
https://blog.csdn.net/wwwlyj123321/article/details/80796974 -
【stm32f103 学习笔记】字、半字、字节和 sizeof()- 电子工程世界
https://news.eeworld.com.cn/mcu/article_2018050138902.html



的信息融合效率)







)

)




—组件通信(1)》)
