1. 介绍transformer算法
Transformer本身是一个典型的encoder-decoder模型,Encoder端和Decoder端均有6个Block,Encoder端的Block包括两个模块,多头self-attention模块以及一个前馈神经网络模块;Decoder端的Block包括三个模块,多头self-attention模块,多头Encoder-Decoder attention交互模块,以及一个前馈神经网络模块;需要注意:Encoder端和Decoder端中的每个模块都有残差层和Layer Normalization层。
2. 在大型语言模型 (llms) 中减少幻觉的策略有哪些?
- DoLa:通过对比层解码提高大型语言模型的真实性:大型预训练 LLM 中的简单解码策略可减少幻觉;
- 在高质量数据上微调模型——在高质量数据上微调小型法学硕士模型已显示出有希望的结果,并有助于减少幻觉;
- 上下文学习:使用上下文学习为模型提供更好的上下文;
- 限制:将输出限制为受限列表,而不是自由浮动文本;
LLMS
3. 你能否概括介绍一下 ChatGPT 的训练过程?
-
𝗣𝗿𝗲-𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴:预训练,大型语言模型在来自互联网的广泛数据集上进行训练,其中 Transformer 架构是自然语言处理的最佳选择,这里的主要目标是使模型能够预测给定文本序列中的下一个单词。此阶段使模型具备理解语言模式的能力,但尚未具备理解指令或问题的能力。
-
监督微调或者指令微调。模型将用户消息作为输入,模型通过最小化其预测与提供的响应之间的差异来学习生成响应,此阶段标志着模型从仅仅理解语言模式到理解并响应指令的转变。
-
采用人类反馈强化学习 (RHFL) 作为后续微调步骤。
4. 在大型语言模型 (llms) 上下文中的标记是什么?
将输入文本分解为多个片段,每一部分大约是一个单词大小的序列,我们称之为子词标记,该过程称为标记化。标记可以是单词或只是字符块。
5. 大模型微调的LORA原理及Lora怎么训练?
大模型实战:使用 LoRA(低阶适应)微调 LLM
6. lora的矩阵怎么初始化?为什么要初始化为全0?
大模型实战:使用 LoRA(低阶适应)微调 LLM
7. Stable Diffusion里是如何用文本来控制生成的?
Stable Diffusion是一种潜在扩散模型,主要通过自动编码器(VAE),U-Net以及文本编码器三个核心组件完成用文本来控制生成的图像。Unet的Attention模块Latent Feature和Context Embedding作为输入,将两者进行Cross Attenetion操作,将图像信息和文本信息进行了融合,整体上是一个经典的Transformer流程。
8. Stable Diffusion相比Diffusion主要解决的问题是什么?
Diffusion的缺点是在反向扩散过程中需要把完整尺寸的图片输入到U-Net,这使得当图片尺寸以及time step t足够大时,Diffusion会非常的慢。
9. Diffusion每一轮训练样本选择一个随机时间步长?
训练过程包含:每一个训练样本选择一个随机时间步长,将time step 对应的高斯噪声应用到图片中,将time step转化为对应embedding;
模型在训练过程中 loss 会逐渐降低,越到后面 loss 的变化幅度越小。如果时间步长是递增的,那么必然会使得模型过多的关注较早的时间步长(因为早期 loss 大),而忽略了较晚的时间步长信息。
10. 领域数据训练后,通用能力往往会有所下降,如何缓解模型遗忘通用能力?
为了解决这个问题通常在领域训练的过程中加入通用数据集。那么这个比例多少比较合适呢?目前还没有一个准确的答案。主要与领域数据量有关系,当数据量没有那么多时,一般领域数据与通用数据的比例在1:5到1:10之间是比较合适的。
11. 在大型语言模型 (llms)中数据模态的对齐如何处理?
- Qformer
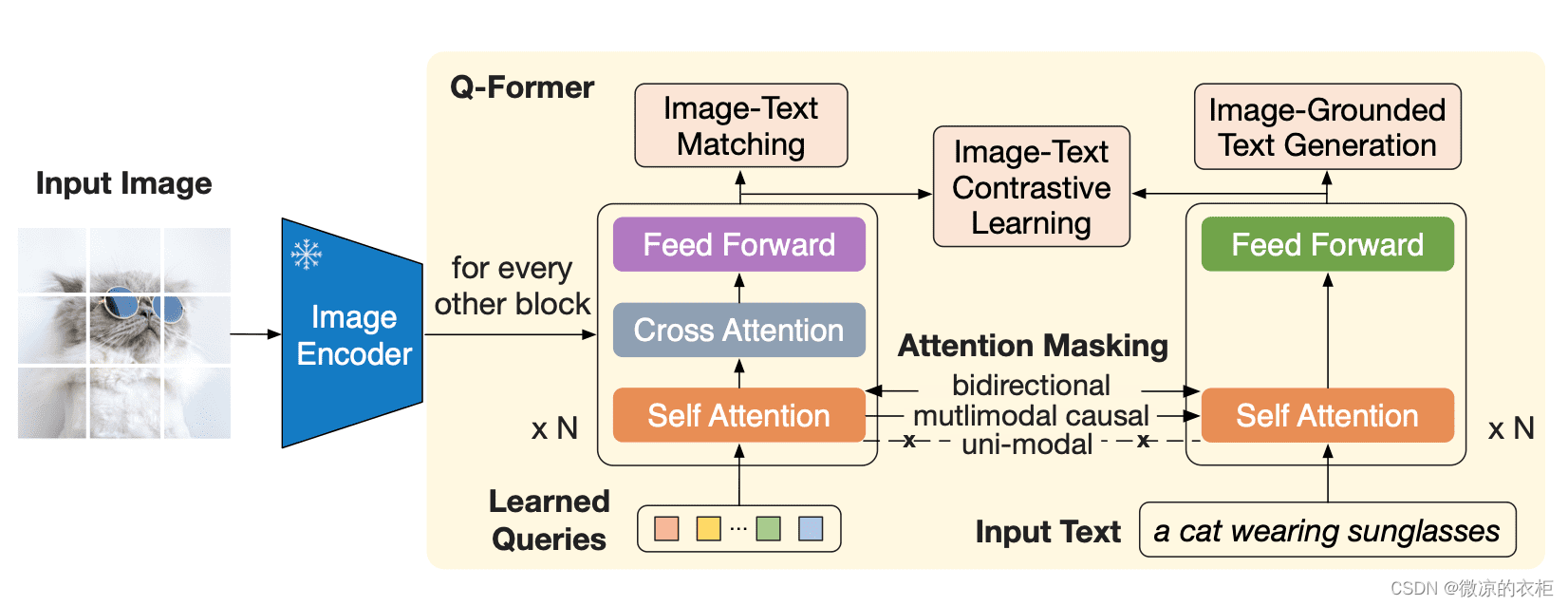
深度剖析|建模完整过程+详细思路+代码全解析)






 函数的构建细节)



)



——vim)

——在ros中编译usb_cam)

