文章目录
- 1. 感知机模型
- 2. 感知机学习策略
- 3. 感知机学习算法
- 3.1 原始形式
- 3.2 算法收敛性
- 3.3 对偶形式
- 4. 基于感知机Perceptron的鸢尾花分类实践
感知机(perceptron)是 二类分类的线性分类模型
- 输入:实例的特征向量
- 输出:实例的类别,取 +1 和 -1 二值
- 感知机对应于输入空间(特征空间)中将实例划分为正负两类的分离超平面,属于判别模型
- 旨在求出将训练数据进行线性划分的分离超平面,为此,导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型。
- 感知机学习算法具有简单而易于实现的优点,分为原始形式和对偶形式。
- 预测:对新的输入进行分类
感知机1957年由Rosenblatt(罗森布拉特)提出,是神经网络与支持向量机的基础。
1. 感知机模型
感知机定义:
- 输入空间:X⊆Rn\mathcal X \subseteq \mathbf R^nX⊆Rn
- 输出空间:Y={+1,−1}\mathcal Y = \{+1,-1\}Y={+1,−1}
- x∈Xx \in \mathcal Xx∈X 特征实例,y∈Yy \in \mathcal Yy∈Y 表示实例类别
- 输入到输出的函数:f(x)=sign(ω⋅x+b)f(x) = sign (\omega \cdot x+b)f(x)=sign(ω⋅x+b)
- 参数:ω\omegaω 权重向量,bbb 偏置
- sign 是符号函数:sign(x)={+1,x≥0−1,x<0sign(x)=\left\{ \begin{aligned} +1, \quad x \geq 0\\ -1, \quad x < 0 \end{aligned} \right. sign(x)={+1,x≥0−1,x<0
- 感知机是线性分类模型,判别模型
- 几何解释:ω⋅x+b=0\omega \cdot x+b = 0ω⋅x+b=0 对应 n 维空间的一个超平面,ω\omegaω 是其法向量,bbb 为其截距,将点(特征向量)分位正负两类
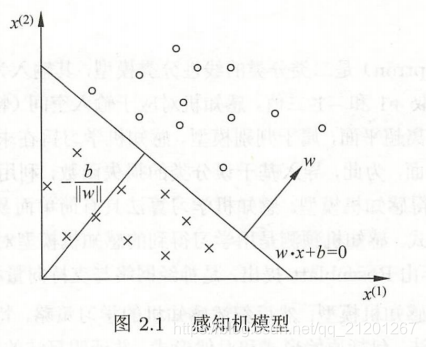
2. 感知机学习策略
- 如果存在一个超平面将所有实例正确的分在平面两侧,称线性可分数据集,否则线性不可分
- 策略:定义损失函数(误分类点到超平面 S 的总距离),并极小化它
-
任意一点 x0x_0x0 到超平面 SSS 的距离: 1∣∣ω∣∣2∣ω⋅x0+b∣\frac{1}{||\omega||_2}|\omega \cdot x_0 + b|∣∣ω∣∣21∣ω⋅x0+b∣,∣∣ω∣∣2||\omega||_2∣∣ω∣∣2 是 ω\omegaω 的 L2L_2L2 范数
-
所有误分类的点记得集合为 MMM,不考虑分母范数,错误的点 yi(ω⋅xi+b)<0y_i(\omega \cdot x_i +b) < 0yi(ω⋅xi+b)<0,取距离为正,则感知机的损失函数(经验风险函数)为:
L(ω,b)=−∑xi∈Myi(ω⋅xi+b)\color{red}L(\omega,b) = -\sum\limits_{x_i \in M} y_i(\omega \cdot x_i +b)L(ω,b)=−xi∈M∑yi(ω⋅xi+b) -
选择使上面损失函数最小的模型参数 ω,b\omega,bω,b
3. 感知机学习算法
3.1 原始形式
损失函数的最优化问题:随机梯度下降法
-
损失函数的梯度:
∇ωL(ω,b)=−∑xi∈Myixi∇bL(ω,b)=−∑xi∈Myi\nabla_\omega L(\omega,b) = -\sum\limits_{x_i \in M} y_ix_i \\ \quad\\ \nabla_b L(\omega,b) = -\sum\limits_{x_i \in M} y_i ∇ωL(ω,b)=−xi∈M∑yixi∇bL(ω,b)=−xi∈M∑yi -
给定 η(0<η≤1)\eta (0< \eta \leq 1)η(0<η≤1) 步长(学习率)
-
目标:输出 ω,b\omega,bω,b,感知机模型 f(x)=sign(ω⋅x+b)f(x) = sign(\omega \cdot x+b)f(x)=sign(ω⋅x+b)
1.选取初值 ω0,b0\omega_0,b_0ω0,b0
2.在训练集中选取数据 (xi,yi)(x_i,y_i)(xi,yi)
3.如果 yi(ω⋅xi+b)≤0y_i(\omega \cdot x_i+b) \leq 0yi(ω⋅xi+b)≤0,
ω←ω+ηyixib←b+ηyi\omega \leftarrow \omega+\eta y_ix_i\\ b \leftarrow b+\eta y_iω←ω+ηyixib←b+ηyi
4.转到2,直到没有误分类点 -
感知机采用不同的初值或选取不同的误分类点,解可以不同
3.2 算法收敛性
算法收敛性证明:(略)
结论:
- 误分类次数 k 有上界,有限次搜索可以找到将训练数据完全正确分开的超平面。
- 当训练数据集线性可分时,感知机学习算法原始形式迭代是收敛的。
- 感知机学习算法存在许多解,既依赖于初值,也依赖于迭代过程中误分类点的选择顺序。为了得到唯一的超平面,需要对分离超平面增加约束条件。这就是第7章将要讲的线性支持向量机的想法。
- 当训练集线性不可分时,感知机学习算法不收敛,迭代结果会发生震荡。
3.3 对偶形式
基本想法:将 ω,b\omega,bω,b 表示成实例 xix_ixi 和标记 yiy_iyi 的线性组合形式。
-
经过 n 次修改 ω,b\omega,bω,b ,ω,b\omega,bω,b 关于 (xi,yi)(x_i,y_i)(xi,yi) 的增量分别是 αiyixi,αiyi\alpha_iy_ix_i, \alpha_iy_iαiyixi,αiyi,这里 αi=niη\alpha_i = n_i\etaαi=niη
-
最后学到的 ω,b\omega,bω,b 可表示成:
ω=∑i=1Nαiyixib=∑i=1Nαiyi\omega = \sum\limits_{i=1}^N \alpha_iy_ix_i\\ \quad \\ b=\sum\limits_{i=1}^N \alpha_iy_iω=i=1∑Nαiyixib=i=1∑Nαiyi -
当 η=1\eta = 1η=1 时,αi\alpha_iαi 表示第 iii 个实例点由于误分类进行更新的次数,次数越多,意味着它距离分离超平面越近,很难正确分类,这样的实例对学习结果影响很大
目标:求 α,b\alpha,bα,b,感知机模型 f(x)=sign(∑j=1Nαjyjxj⋅x+b)f(x) = sign \bigg( \sum\limits_{j=1}^N \alpha_jy_jx_j \cdot x+b\bigg)f(x)=sign(j=1∑Nαjyjxj⋅x+b),其中 α=(α1,α2,...,αN)T\alpha = (\alpha_1,\alpha_2,...,\alpha_N)^Tα=(α1,α2,...,αN)T
- α=0,b=0\alpha = 0, b =0α=0,b=0
- 选取训练集数据 (xi,yi)(x_i,y_i)(xi,yi)
- 如果 yi(∑j=1Nαjyjxj⋅xi+b)≤0y_i \bigg( \sum\limits_{j=1}^N \alpha_jy_jx_j \cdot x_i+b\bigg) \leq 0yi(j=1∑Nαjyjxj⋅xi+b)≤0
αi←αi+ηb←b+ηyi\alpha_i \leftarrow \alpha_i+ \eta \\ \quad\\ b \leftarrow b+ \eta y_iαi←αi+ηb←b+ηyi
4.转至2,直到没有误分数据
- 对偶形式可以预先将训练集中的实例间的内积计算存储在矩阵中,称为 Gram 矩阵 G=[xi⋅xj]N×N\mathbf G = [x_i \cdot x_j]_{N \times N}G=[xi⋅xj]N×N
4. 基于感知机Perceptron的鸢尾花分类实践
请查阅链接







)

)


)






