
文 | 天于刀刀
犹记 2018 年底谷歌开源 BERT 后,一大批基于 Attention 机制 Transformer 结构的大模型横空出世。
XLNet、MPNet、ERNIE,NLP 任务彻底迈入大规模语料训练 + fintune 的时代。之前一段时间爆火的 prompt 概念也离不开大模型中最基本的预训练 MLM 任务。
经过了多年的发展,不知不觉中,大模型的训练逐渐变成了土豪专属。随着大模型的不断刷榜,相应的大模型参数数量也在疯狂变大,令人咋舌。(无形装逼最为致命)
但正如上期报道的前谷歌员工离开 Google AI 后质疑的那样,海量资源无脑砸出的大模型真的会一直那么香吗? 目前一群来自 NYU 的研究员甚至在全网公开发起百万悬赏,征集大模型反规模效应的案例 (Inverse Scaling Prize) [1] !
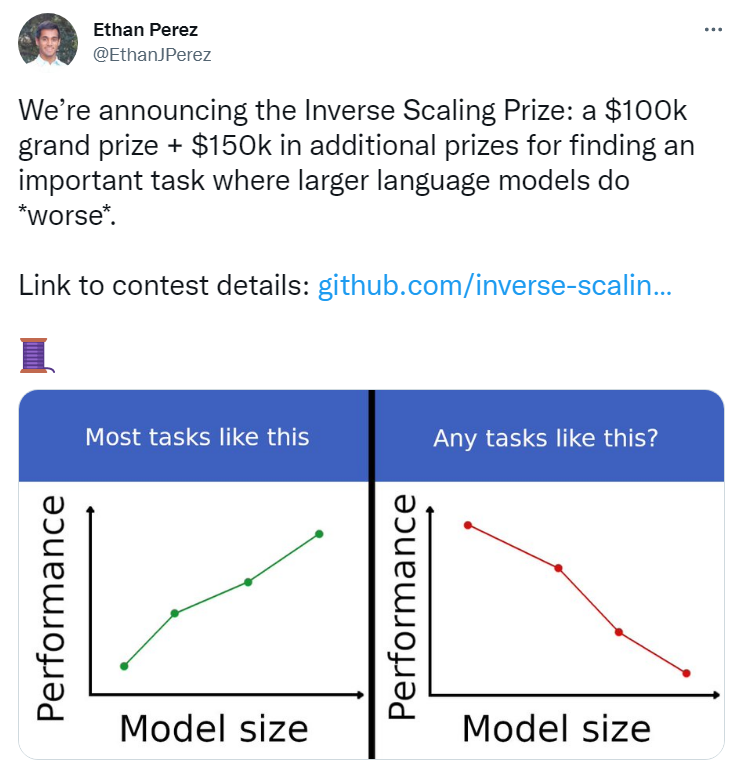
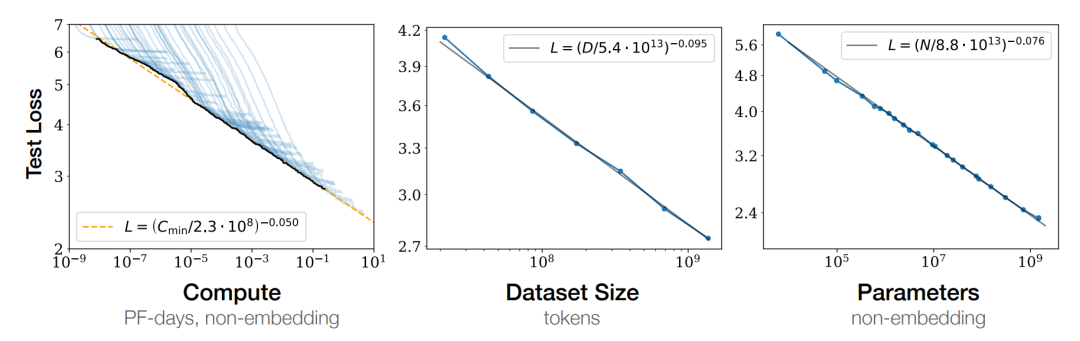
先来简单了解下背景历史。所谓的 Inverse Scaling 即大名鼎鼎的 Scaling Law [2] 的反例,该定律由 OpenAI 于 2020 年初提出,主要贡献是通过实验证明:向神经网络输入的数据越多,这些网络的表现就越好。
其中该论文中经典的八大结论让小编刀刀印象深刻(强烈推荐去看一看他的实验图表):
模型架构不重要,重要的是模型参数 N ,训练数据 D 和计算量 C ;
N, D, C 和 loss 之间存在线性关系;
过拟合? 增加模型参数或是扩大数据集即可避免;
大模型的训练时长是可预测的;
大模型 few-shot 表现更好;
大模型的表现总是好于或不差于小模型;
算力有限时,有策略地训练大模型是一步妙手;
可通过计算得到一个优化的 batch size 使其收敛。
基于这篇文章提供的理论依据,很多大团队在“更多数据,更广领域”的道路上一脚油门踩到底,数据军备、算力军备竞赛打得如火如荼。而另一边,广大小公司空有一堆待赋能的 AI 场景,却只能眼巴巴地在看着巨头烧钱,自己根本玩不起这个越来越昂贵的玩具。
(xx平台云训练云部署服务广告位招租,长期有效)

时间来到了 2022 年,被爆炒了两年的“唯数据论”“唯参数论”渐渐开始被质疑,尤其是在对话生成领域中,老生常谈的“机器偏见”问题依旧存在,并且实践证明这并不是简单地堆砌数据和资源就能解决的。例如,基于 GPT-3 的聊天机器人 Replika 曾表示,新冠病毒是比尔盖茨发明的,新冠病毒疫苗的效果并不好。
本次 Inverse Scaling Prize 的主办单位 Anthropic 正是看到了这个问题,因此他们设置了总计25万美金的奖金(折合约168万元人民币),去寻找哪些任务能证明 Scaling Law 并不是黄金定律,从而定位到一些当下大模型预训练中的一些问题。
本次比赛第一轮投稿截止时间为 2022 年 8 月 27 日,想要凑个热闹的同学可以抓紧去他们主页上看看啦 [3][4]。
消息一出,在 reddit 原贴下方引起一片网友的热烈讨论:
有化学医药的网友表示,大模型的确在他的小样本数据集上表现较差,非常容易过拟合。他甚至一度怀疑是不是因为化学太难了以至于基于人类的语言模型难以学习,但是主办方表示这也许也可能是因为训练数据太少而导致的。
还有网友提问,他手头的项目里 word2vec 要比 BERT 做词嵌入 word embedding 效果好很多,这是否符合要求呢?
其实这也不算数。只要这位网友认真了解过 Scaling Law 就能知道,文中讨论的参数不包含 embedding,即原文中的模型参数都指代 non-embedding parameters。
面对着巨额奖金的诱惑,有的网友开始动起了歪脑筋。例如有网友就提出不如咱们直接设计一个新的问答任务,任务目标就是“答非所问”。那么在这种情况下,大模型的表现理所应当会比小模型要好,从而在 loss 的计算上得到一个更“差”的表现。
其实这想法和小编刀刀的一个“杠精机器人”项目有点雷同,同样是扭曲一个正常对话过程中的目标。但是和刀刀实践后得到的结论不同,在当时的项目中大模型在少量样本 finetune 后依旧比小模型更能抬杠。
因此小编觉得,想要赢得奖金你不但需要设计一个有意义的实际问题,而且需要构造或者提供一部分数据去支持你发现 Inverse Scaling 。(即随着模型的增大 loss 也同样增大的现象)
听着很复杂?别担心,主办团队甚至为了准备了无代码版本的 GPT-3 Colab 资源 [5]!无需任何代码模型基础,对其他从业者十分友好!同时他们也详细描绘了相关任务的评估标准,其 Rubric 之规范程度简直让人梦回期末大作业。
他山之石可以攻玉。也许一些跨领域学科的业务需求可以为目前人工智能领域中的大模型困境提供意料之外的破局点。
那么事不宜迟,也请各位在围观之余多多转发评论。
说不定最终能斩获大奖的,就是各位朋友圈中的大佬呢?
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
[1] Inverse Scaling Prize (Reddit). https://www.reddit.com/r/MachineLearning/comments/vm2sti/n_inverse_scaling_prize_250k_in_prizes_for/
[2] Scaling Laws for Neural Language Models. https://arxiv.org/abs/2001.08361
[3] Inverse Scaling Prize (Github). https://github.com/inverse-scaling/prize
[4] Inverse Scaling Prize (Slack). https://join.slack.com/t/inverse-scaling-prize/shared_invite/zt-1bxdxqtds-3CCbPLkaZH0UqIP9Bg2P~g
[5] Inverse Scaling GPT-3 Colab. https://colab.research.google.com/drive/1SGmUh0NbqSrRkWRUcmjg8BS5eU5qvJ0Y#scrollTo=zoaYc0nsfOIC

)











))

)


)

