
文 | 王思若
将视角转换到2020年,OpenAI发布了拥有1750亿参数量的GPT-3, 在阅读理解、语言翻译、问答等多种任务展现了令人惊艳的效果,算法+工程二者结合展现了大模型的“暴力美学”,也同时开启了千亿、万亿参数模型的 “军备竞赛”。
从模型框架到并行架构,从NLP,CV再到多模态,大型语言模型(LLM)逐渐成为了少数几个公司和研究院竞相争抢的赛道。
之后我们见证了从DeepMind的2800亿参数Gopher到NVIDIA和微软联合发布的5300亿参数的Megatron-Turing,从Google的1.6万亿参数的Switch Transformer再到智源的1.75万亿参数的悟道2.0。
尽管有些模型开放了API接口或参数,但详尽的技术细节却未公之于众,导致难以全然复现。
例如,OpenAI拒绝公布GPT-3模型参数,DeepMind对于让蛋白质结构预测走上新阶段的AlphaFold2也只是公布了推理代码。学界和社区呼唤开源,但是我们也无法苛求这些以盈利为立足之本的企业能够全然公开其技术研究成果。
这似乎是一个关于巴别塔的困境——人类联合起来兴建希望能通往天堂的高塔,但是上帝为了阻止人类让人类说不同语言,互相之间不能沟通,进而导致计划失败。
在这些公司试图建立起自己的技术壁垒的同时,也涌现了一批人去尝试打破它们。Meta复现并完全开源了GPT-3,哥伦比亚大学全流程复现并开源了AlphaFold2。
今天我们要介绍的主角,也是这批力量中不可忽视的一个组织——BigScience,一个包容、开放、协作共享的大型语言模型(LLM)社区,围绕研究和创建超大型语言模型的开放式协作研讨会,由HuggingFace、GENCI和IDRIS发起的开放式合作,汇集了全球 1000 多名研究人员。
BigScience既不是实体组织,也不是互联网企业,有人说这是一群希望构造更加开源、开放社区的学者汇聚形成的“星星之火”。接下来,笔者将阐述这群人的故事,或许,从他们开始AI社区的规则将迎来转变。
 BigScience的故事
BigScience的故事

这个故事开始于21年1月,Hugging Face创办者之一的Thomas Wolf、来自超级计算机制造商GENCI的Stéphane Requena和来自运营超级计算机的法国公共研究机构IDRIS的Pierre-François Lavallée对人工智能进行了探讨,并一致认为工业界应该和学术界合作构建开源、开放的通用型研究工具。
21年1月-4月,Hugging Face联合法国学术社区成立了BigScience🌸,并得到了500万GPU时的资助。
21年7月-8月,训练完成了GPT-style架构的多语言预训练语言模型,其在13种语言构建的4000亿tokens组成的语料库中进行训练,模型参数为13亿。
21年底-22年初,尝试训练千亿参数的多语言预训练语言生成模型,并进行了一系列参数量、数据集、模型架构等方面的探索。期间遇到了很多难题,例如1040亿参数的模型训练不收敛,反而1760亿参数的模型训练很稳定以及数据质量不达标。
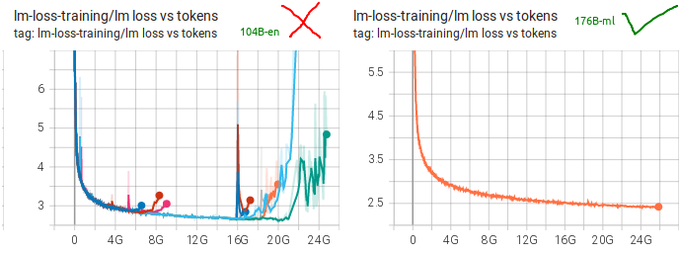
22年3月11日,BigScience正式在384张80GB显存的A100上公开训练了1760亿参数量的多语言预训练预训练语言模型 BLOOM (BigScience Language Open-science Open-access Multilingual) ,采取了类似与GPT的Decoder架构。这一项目由30个工作组参与,其中涉及到1000多人报名以及数百名积极参与者。模型预计训练3-4个月,训练数据包括46种语言,训练期间loss和梯度变化等日志都通过tensorboard的形式在huggingface网站中实时展现了出来,任何人都可以实时跟踪模型训练!
为了让小伙伴不错过大模型BLOOM训练成长的每一天,更是为其开通了twitter账号,从此开启了每日汇报训练进度的日常。从0%开始,到99%、100%,经过111天,模型终于训练完毕。不过,BigScience说让子弹再飞一会,模型会继续训练几天,当然每日的推文就变成了训练进度101%、102%... ... 马上小伙伴们就可以亲自测试BLOOM大模型的效果啦!
虽然最终模型还没有发布,但该模型的checkpoints已经展现了非常酷的效果,可以协助编程例如生成递归函数,纠正语法错误。每一个人都将会有无限的自由去探索大模型未知的潜力,这会是属于每一个人的一场大模型的“狂欢”。

 或将成为AI社区的破局者
或将成为AI社区的破局者
人工智能对社会产生了根本性的影响,特别是大规模预训练语言模型的研发与应用加速了这种影响的深度和广度,但是大模型的核心技术往往被少数的科技巨头牢牢把控,受限于财务、法律或道德原因,这些资源丰富的研究团体或公司对于模型细节并不十分开放,因此社区对这种变革性技术在构建方式、功能以及进一步改进方面缺乏很好的理解,与此同时在环境、伦理和社会等方面的进一步探索也面临着巨大的束缚。
开放的科学合作才会更加促进学术研究并最终造福整个学术界。
我们看到BigScience成为了人工智能时代新的破局者,BigScience是全球数百名研究人员组成的开放科学项目,这些研究人员作为志愿者秉持着开放、多样、包容乃至造福人类的想法参与了BLOOM(BigScience Language Open-science Open-access Multilingual)大模型的构建以及训练过程。只要你感兴趣,提交表格然后加入他们的Slack频道,你就会成为贡献者的一员。
因此,来自世界各地的大量研究人员在其中共同训练大型语言模型(LLM),一切完全公开,任何人都可以参与,所有研究成果都与整个社区共享。
BigScience作为一个跨学科的研讨会,汇聚了人工智能、社会科学、法律、伦理等多种研究领域的学术和工业界的研究人员,集中时间和资源共同实现更大的影响。
BigScience成为AI历史上第一个超过1000多名研究人员参与创建单一模型和数据集的案例,继而,BLOOM也成为目前第一个也是唯一一个在这种规模上创建的完全开源的大型语言模型。

在笔者看来这是一个翻版“石头汤”的故事,每个人都往大锅中加入自己拥有的食材并成功制作了一份美味的汤给大家分享。
BigScience成立了一个特别大的Slack频道:TLDR,并将团队分为多个工作组,包括法律、数据管理、模型管理、模型架构和训练以及模型可视化等。
每个小组都由志愿者主席组成,他们负责组织会议、设定截止日期和确保相关代码和论文写作按时完成。
HuggingFace团队主导,Microsoft DeepSpeed团队和NVIDIA Megatron-LM团队提供了并行训练架构,由核能驱动的超级计算机Jean Zay提供了低碳环保的算力支持... 哇,这将会呈现给AI社区每一个人的绝美的汤!
 一些感想
一些感想
进一步,像BigScience一样协作训练并共享大型语言模型是一个相当有趣的尝试,在之前我们看到类似大小的模型在各种大型科技公司中训练并保持私有,这产生了重复的能源消耗并几乎没有实用逻辑。
同样的,我们也看到了以开源著称的HuggingFace更加蓬勃的“野心”,其牵头成立的BigScience无畏的走向了更加开源、开放的时代浪尖。
更为有意思的是,BigScience使用中国儒家道德理论中的“和”作为其道德章程的根基,建立起包容性、多样性、开放性等构成的内在价值观以及透明性、跨学科性等组成的外在价值观。
BigScience要求成员按照其道德章程建立核心价值观,并希望能够进一步出版、传播和普及来促进学术界的价值观。
按照其章程,笔者构画了BigScience设想的蓝图:这里没有宗教、种族、性别等任何形式的歧视并希望每个成员对BigScience有归属感,每个贡献者都肩负着个人责任以及集体责任,既要对社会负责也要对环境负责,多学科交融互通,多语种美美与共。
BigScience作为刚刚燃起的“星星之火”,不管能否燎原,它用全新的合作形式,完全开源、平等包容的价值观让我们看到了人工智能时代不一样的色彩。
或许,未来某一天当回过头来看,我们会惊奇的发现,BigScience和BLOOM成为了AI社区迈入更加开源、开放人工智能新时代的转折点。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群
[1] BigScience网站:https://bigscience.huggingface.co/
[2] BigScience Twitter: https://twitter.com/BigscienceW

)





)


)


 + map))


)


)
