
论文标题:
Locate and Label: A Two-stage Identifier for Nested Named Entity Recognition
论文链接:
https://arxiv.org/abs/2105.06804
代码链接:
https://github.com/tricktreat/locate-and-label
摘要
(1)过去的难点:
传统的NER研究只涉及平面实体,忽略了嵌套实体。基于跨度的方法将实体识别视为跨度分类任务。这些方法虽然具有处理嵌套NER的能力,但计算量大,对边界信息的忽略,对部分匹配实体的跨度利用不足,长实体识别困难。
(2)模型:
为了解决这些问题,我们提出了一种两阶段实体标识符( Two-stage Identifier)。
(3)方法:
首先,我们通过对seed span(种子跨度) 进行过滤和边界回归来生成跨度建议(span proposal),以定位实体;
然后用相应的类别标记边界调整后的跨度建议(就是对跨度建议再次调整)。
Introduction
(1)NER: 命名实体识别是自然语言处理中的一项基本任务,重点是识别引用实体的文本范围。NER广泛用于下游任务,如实体链接和关系提取。
(2)当今的NER中,嵌套NER是有所关注的;
主要方法:比如序列模型,基于跨度的方法;
序列模型:序列标记模型预测边界,但在没有动态调整的情况下,边界信息没有得到充分利用。其次,实体部分匹配的跨度会被认为是负跨度。
基于跨度的方法是将NER视为了一项具有识别嵌套NER固有能力的分类任务。首先,由于大量低质量的候选跨度(就是上面说的部分匹配的跨度)导致较高的计算成本。然后,很难识别长实体,因为在训练期间枚举的跨度不是无限长的。其次,边界信息没有得到充分利用,而模型定位实体很重要。
(3)动机:
在目标检测领域,他们将检测任务分为两个阶段,首先生成候选区域,然后对候选区域的位置进行分类和微调。所以,我们将检测任务分为了两个阶段。
(4)贡献:
- 我们提出了一种新的两阶段标识符,用于NER,首先定位实体,然后标记实体。我们将NER视为边界回归和跨度分类的联合任务;
- 我们有效地利用边界信息。通过进一步识别实体边界,我们的模型可以调整边界以准确定位实体。在训练边界回归器时,除了边界级平滑L1损失外,我们还使用跨度级损失,用于测量两个跨度之间的重叠;
- 在训练过程中,我们不是简单地将部分匹配的跨度视为负面示例,而是基于IoU(交并比)构造软示例;
- KBP17、ACE04和ACE05数据集
Method
在第一阶段,我们设计了一个span建议模块,该模块包含两个组件:过滤器和回归器。过滤器将种子跨度分为上下文跨度和跨度建议,使用IoU,在这些种子跨度中,而重叠程度较低的部分为上下文跨度(contextual spans),实体重叠程度较高的部分为提案跨度(proposal spans)。并过滤掉前者以减少候选跨度。回归器通过调整跨度建议的边界来定位实体,以提高候选跨度的质量。
在第二阶段,我们使用实体分类器来标记实体类别,以减少数量并提高质量。在训练期间,为了更好地利用部分与实体匹配的跨度,我们通过基于IoU对模型的损失进行加权来构造软示例。此外,我们将软非最大抑制(soft NMS)(Bodla et al.,2017)算法应用于实体解码,以消除误报。
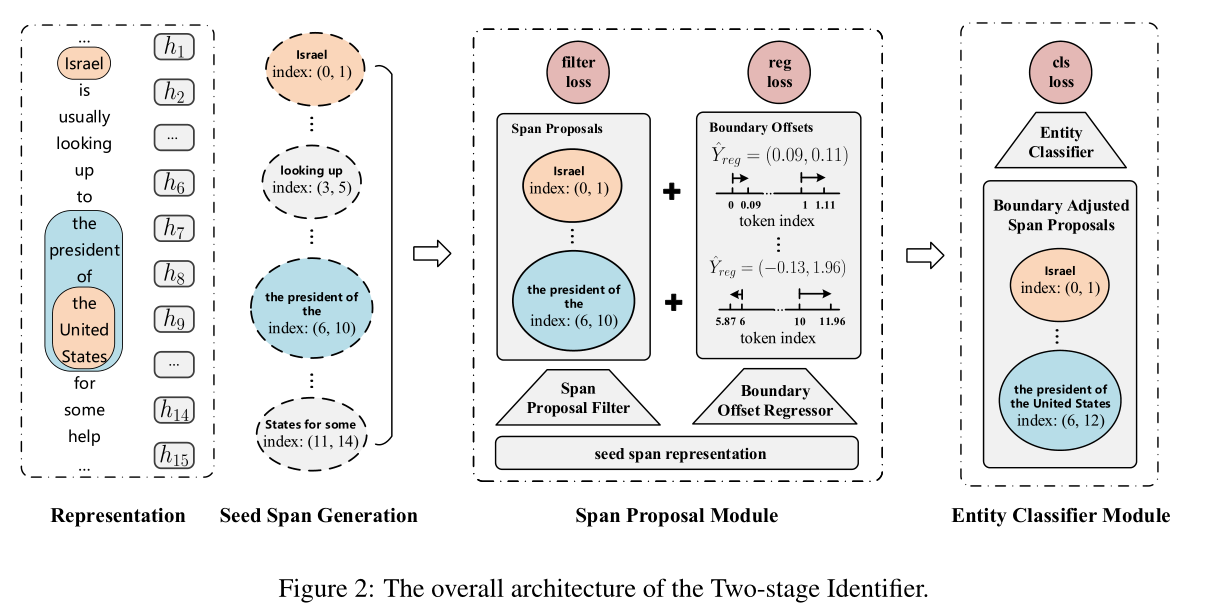
Two-stage Identifier.
1. Token representation:
① 句子: 一个句子有n个单词,对于第i个单词,我们通过concat它的word embedding xiwx_{i}^{w}xiw,上下文word embeddingxilmx_{i}^{lm}xilm,词性标注POS xiposx_{i}^{pos}xipos,字符级嵌入xicharx_{i}^{char}xichar来得到它的表示。
word embedding xiwx_{i}^{w}xiw由具有相同设置的BiLSTM模块生成;对于上下文的Word embedding,我们遵循2020年的文章获取目标标记的上下文相关嵌入,每边有一个环绕的句子。最后concat后放入BiLSTM来获得隐藏状态获得最终的word representation hi∈Rdh_{i}\in\R^{d}hi∈Rd
2. Seed Span Generation
(1)获取种子跨度集
种子跨度集 B=b0,...,bkB = {b_{0},...,b_{k}}B=b0,...,bk,其中bi=(sti,edi)b_{i} = (st_{i},ed_{i})bi=(sti,edi)表示的第i个种子跨度; K表明了生成的种子跨度的数量,并且sti,edist_{i},ed_{i}sti,edi表明了span的起始位置
(2)为种子跨度分配类别和回归目标
具体来说,我们将B中的每个种子跨度与跨度具有最大IoU的基本真相实体配对。
IoU(A,B)=A∩BA∪BIoU(A,B)=\frac{{A}\cap{B}}{{A}\cup{B}}IoU(A,B)=A∪BA∩B,其中A和B是两个跨度; 我们根据两个之间IoU将他们分为了正跨度和负跨度;正跨度是和gt是同一标签,负跨度则是None标签;正负跨度比例:1:5
3. Span Proposal Module
将跨度分为了跨度建议(质量高)和上下文跨度(质量低),目的是消除后者,降低成本。 Span Propos Module由两部分组成: Span建议过滤器和边界回归器; 前者用于删除上下文范围并保留范围建议,而后者用于调整范围建议的边界以定位实体。
(1) Span Proposal Filter
最大池跨度表示法
将整个种子跨度从stist_{i}sti到edied_{i}edi计算最大池化;
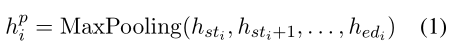
跨度表示
concat最大池化表示和种子跨度的第一个和最后一个单词;
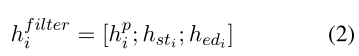
概率计算
最后我们可以计算bib_{i}bi属于该span proposal的概率
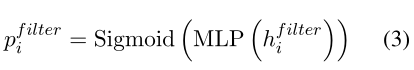
其中所有的hih_{i}hi是某个单词的最终表示; [;]表示的是concat; MLP包含了两个线性层和一个GELU激活函数
(2) Boundary Regressor
尽管有很高的重叠,但是不能命中实体,还需要利用边界回归损失调节边界值(内部和外部信息)。
跨度回归表示
这里我们使用了外部边界单词(index加一和减一)表示和最大池化跨度表示进行concat;
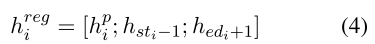
计算左右边界的偏移
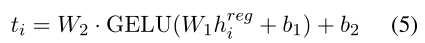
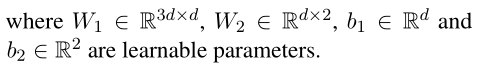
4. 实体分类器模块
调整偏移后的边界
开始位置st~i\widetilde{st}_{i}sti、结束位置ed~i\widetilde{ed}_{i}edi
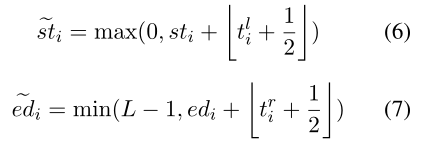
新的边界单词池化
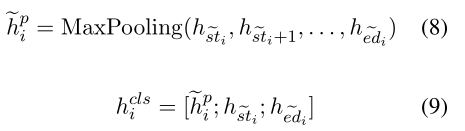
交叉熵损失
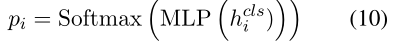
5.Training Objective
我们不将所有的部分匹配的跨度视为负跨度,而是分配权重,对于第i个跨度bib_{i}bi,wiw_{i}wi设置为:
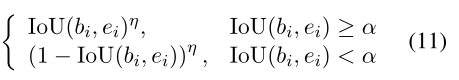
其中α∈{α1,α2}\alpha\in\{\alpha_{1},\alpha_{2}\}α∈{α1,α2}表明了分别用在第一和第二阶段的IoU的阈值;eie_{i}ei表明是bib_{i}bi的gt标签;μ\muμ是聚焦参数,可平滑调整部分匹配示例的下加权率; 如果μ\muμ = 0,那么上式就是一个hard one;此外,如果跨度未与任何实体重叠或与某些实体完全匹配,则损失重量wiw_{i}wi=1。
focal loss(焦点损失)
跨度建议过滤器;解决不平衡问题;
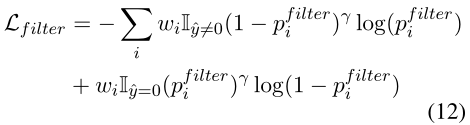
其中,wiw_{i}wi是第i个实例的权重; γ\gammaγ表示的是focal loss的聚焦参数;该损失包含了两个组件,平滑L1L_{1}L1loss是在boundary水平,而重叠loss是在span水平;
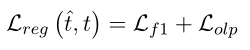
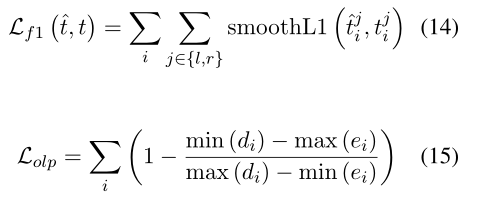
其中di={ed~i,ed^i}d_i = \{\widetilde{ed}_{i},\widehat{ed}_{i}\}di={edi,edi},ei={st~i,st^i}e_i = \{\widetilde{st}_{i},\widehat{st}_{i}\}ei={sti,sti},st^i\widehat{st}_{i}sti,ed^i\widehat{ed}_{i}edi,t^il\widehat{t}_{i}^{l}til和t^ir\widehat{t}_{i}^{r}tir表明了ground-truth的左边界、右边界、左偏移和右偏移
交叉熵损失
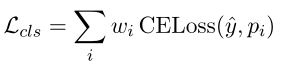
其中wiw_{i}wi通过式子11计算出来的第i个例子的权重,我们联合训练滤波器、回归器和分类器,因此总损失计算如下:
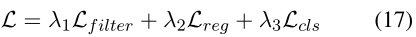
(5)实体encoding
经过上面的步骤,我们已经获得了跨度方案的分类概率和边界偏移回归结果。基于它们我们需要提取句子中所有的实体(找到开始位置,结束位置和实体的类别)。
我们使用yi=argmax(pi)y_i = argmax(p_i)yi=argmax(pi)作为跨度sis_isi的标签,用scorei=max(pi)score_i = max(p_i)scorei=max(pi)作为sis_isi属于yiy_iyi条目的置信度。这样si=(li,ri,yi,scorei)s_i = (l_i,r_i,y_i,score_i)si=(li,ri,yi,scorei)。鉴于分数的阈值δ\deltaδ和span的提议S={si,...,sN}S=\{s_i,...,s_N\}S={si,...,sN},N表示成了span proposals的数目,我们使用Soft-NMS算法来过滤false positives????我们按分数的顺序遍历span proposals(转化术语被表示为sis_isi),并且调整其它span proposals (sjs_jsj)的分数为f(si,sj)f(s_i, s_j)f(si,sj),这个被定义为
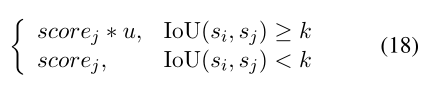
其中u∈(0,1)u\in(0,1)u∈(0,1)表示分数的衰减系数,k表示IoU阈值。之后我们保持所有的span proposals用score>δscore>\deltascore>δ作为最终的提取实体。
Experiment
1. 实验设置
数据集
ACE04、ACR05、KBP17和GENIA
ACE04、ACR05: 嵌套数据集, 7个实体类别;划分为train:dev:test = 8:1:1
KBP17:包含了GPE, ORG, PER, LOC, and FAC;划分为train:dev:test = 866:20:167
GENIA:生物学嵌套命名实体数据集,包含五种实体类型,包括DNA、RNA、蛋白质、细胞系和细胞类型类别。train:test = 9:1
评价指标
当实体边界和实体标签同时正确时,我们使用严格的评估指标来确认实体是正确的。我们使用精确性、召回率和F1分数来评估性能
参数设置
GloVE 和 BERT是一个encoder;
对于GENIA我们用BioWordvec、BERT with BioBERT 代替GloVE ;
维度设置为:xiw,xilm,xipos,xicharx_{i}^{w},x_{i}^{lm},x_{i}^{pos},x_{i}^{char}xiw,xilm,xipos,xichar和h_{i}}分别是100,1024,50,50和1024;
epoch: 25
Adam优化器和一个线性warmup-decay学习率策略; 在filter、regressor和entity classifier之前用0.5的学习率。
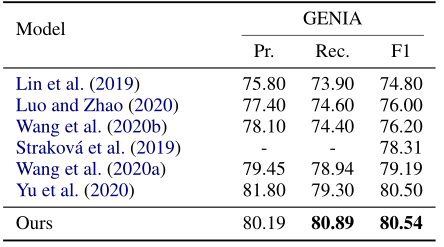
2. 实验结果
在nested NER任务的结果
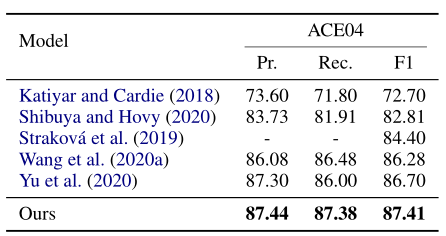
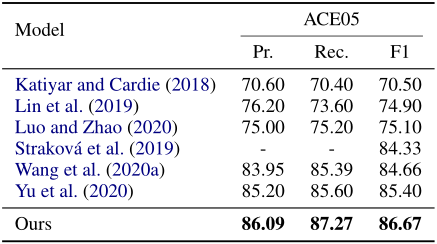
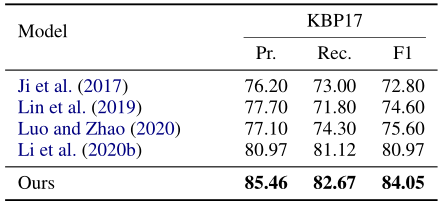


)
【ACL 2021】FEW-NERD: A Few-shot Named Entity Recognition Dataset)
)
)

词性标注)


Word Embedding)



【一直更新】)


)

