文章目录
- 1 一条SQL查询语句是如何执行的
- 2 mysql体系结构
- 3 InnoDB存储引擎
- 4 总结
1 一条SQL查询语句是如何执行的
通常我们使用数据库,都是将数据库看成一个整体,我们的应用与数据库完全就是通过SQL语句进行交互。大多数开发者很少去了解数据库的内部实现原理,这样也可以完成我们的应用。但是如果遇到一些疑难问题,如查询变慢、死锁、数据库宕机需要恢复数据时,我们就需要对数据库的实现原理有一定的了解,才能解决这些问题。了解一个东西,先鸟瞰其全貌,再一步步深入到内部。
想要了解mysql的基础架构,从最简单的SQL查询语句来分析,当了解了mysql是如何执行一条SQL查询语句后,就基本了解了mysql的基础体系结构。
下面是一条最简单的SQL查询语句:
select * from T where id = 2;
对于应用开发者来说,看到的就是输入一条语句,返回一个结果。下面是mysql的基本架构简单示意图,这条语句会经过这些过程。

大体来说,mysql可以分为server层和存储引擎层。
- server层包括
-
连接器:连接器负责跟客户端建立连接、获取权限、维持和管理连接等。
-
查询缓存:建立连接后就应该进行数据的查询。在真正进行数据查询之前,mysql会先到缓存查看,之前是否执行过这条语句,如果执行过,会在缓存中缓存这条查询对应的返回数据,此时可以直接从缓存中获取。如果不在缓存中,则继续后面的流程。
2.1 大多数情况下不建议使用查询缓存的功能,因为查询缓存弊大于利。查询缓存失效非常频繁,只要有对表的更新操作,这个表上所有的查询缓存就会被清空,因此很有肯能你很费劲地把结果存起来,还没使用就被一个更新操作清空了。对于更新压力大的数据库来说,查询缓存的命中率非常低。mysql8.0以后直接将查询缓存的功能删掉了。
-
分析器:如果没有命中缓存,就开始这正的执行查询了。mysql首先会需要对你提交的SQL语句进行校验与分析,看是否是正确的SQL语句。分析器主要包括词法分析、语法分析,后面的文章会对其进行详细的分析。
-
优化器:当SQL语句校验成功,没有语法错误,会进行优化器优化,优化器主要是在表里有多个索引的时候决定使用哪个索引,或者在一个语句有多表关联(jion)的时候,决定各个表的连接顺序。
-
执行器:mysql通过分析器知道了要做什么,通过优化器知道了要怎么做。于是就进入了执行阶段,开始执行语句。
- 执行的开始会先判断你对这个表是否有权限。
- 如果有权限则打开表继续执行,执行器会根据表的存储引擎的定义,来调用不同存储引擎的api接口,查询具体的数据。
上面就是一条SQL查询语句的简单执行过程,只是加单的描述了大概的流程,当然里面的细节非常负责,这在后面的文章中会进行一一拆解。
2 mysql体系结构
在了解了上面的一条SQL查询语句的执行流程后,我们再来看下,mysql完整的体系结构是什么样。
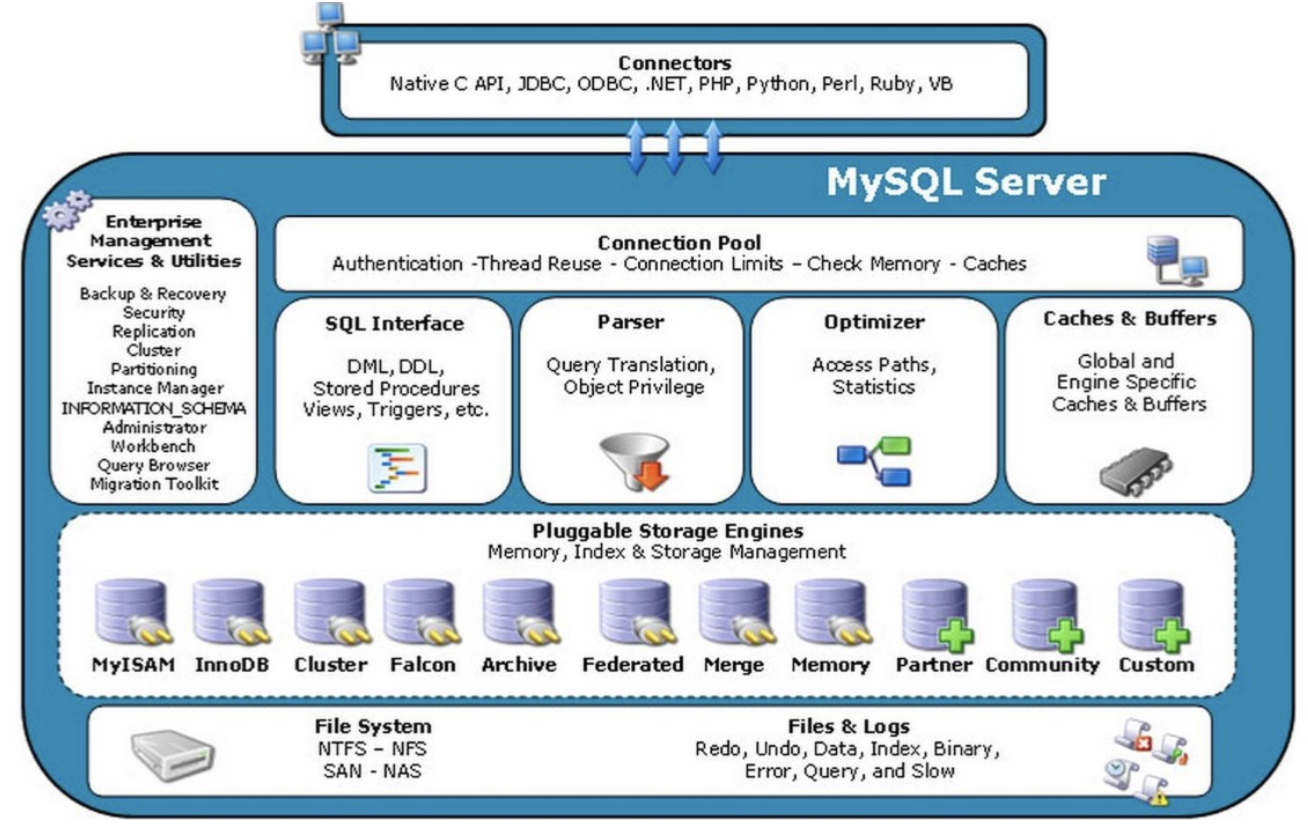
从以上mysql的体系结构中可以看出,主要有以下几个部分组成。
- 连接池组件
- 管理服务和工具组件
- SQL接口组件
- 查询分析器组件
- 优化器组件
- 缓冲组件插件式存储引擎
- 物理文件
mysql数据库区别于其他数据库的最重要的一个特点就是其插件式的表存储引擎。mysq插件式的存储引擎架构提供了一系列标准的管理和服务支持,这些标准与存储引擎本身无关,可能是每个数据库系统本身都需要的,如SQL分析器和优化器。存储引擎是底层物理结构的实现,每个存储引擎开发者可以按照自己的意愿来进行开发。
需要特别注意的是,存储引擎是基于表的,而非数据库的。我们最好牢记上面的mysql体系结构,对我们后面深入理解mysql数据库有很大的帮助。
3 InnoDB存储引擎
我们已经大致了解了mysql数据库独有的插件式体系结构,病了解到存储引擎是mysql数据库区别于其他数据库的一个最重要的特性。存储引擎的好处是,每个存储引擎都有各自的特点,能够根据具体的应用建立不同的存储引擎表。我们业务应用开发平时所说的事务、锁、B+树索引等,也都是在存储引擎层实现的。其中InnoDB存储引擎是目前最常用的一种存储引擎,所以我们总是围绕着InnoDB的原理进行讲解。
InnoDB存储引擎支持事务,其设计的主要目标是面向在线事务处理的应用(OLTP),其特点是行锁设计、支持外键、并通过使用多版本并发控制支持一致性非锁定读。并且实现了SQL的四种隔离级别。默认为RR(REPEATABLE READ)隔离级别,同时使用next-key locking 的策略来避免幻读(phantom)现象的产生。除此之外,InnoDB存储引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引、预读(read ahead)等高性能和高可用的功能。
对于标准红数据的存储,InnoDB采用聚集(clustered)的方式,因此每张表的存储都是按照主键的顺序进行存放。
4 总结
本文是接下来对mysql数据库拆解,并深入分析的基础,我们主要掌握mysql体系结构的图,把上面的图背下来也行,对后面理解索引、锁、以及mysql优化都有莫大的好处。


)






)

)
)

:小练习)




