问题导读:
1.如何在讲mapreduce函数中的字符串等信息,输出到eclipse控制台?
2.除了使用下文方法,还有其它方法输出到控制台?
3.map中,系统默认接受的value值是什么?
4.reduce输出不是自己想要的结果,可能的原因是什么?

附件不能下载,可查看原文链接:
http://www.aboutyun.com/thread-8303-1-1.html
mapreduce不是很好理解,为什么?
因为我们传统编程,运行程序,都在本地,怎么会跑到别的客户端或则服务器那,总之运行程序就是一太电脑。mapreduce牛啊,他竟然可以让一个程序多台电脑一块跑,这也是它的神奇不同之处,同时也让mapreduce蒙上了一层神秘的面纱。
这里我们就来揭开这个面纱。
这里难以理解的地方是什么?它是如何分割的,如何分组、如何分区的,什么shuffer,等等各种概念涌入初学者脑海中,然后就是云里雾里、似看清、又看不清。

这里我们抛弃这些所有的概念,让我们来一个短平快、更直接、更简单的的认识。
记得我们在上学的时候,有一种题型是填空题,而mapreduce就是一个填空式编程。
为什么被认为是填空式编程,因为mapreduce是一个框架,我们所作的就是编写map函数、reduce函数、然后驱动函数main()。
填空,让我们填写的就是map、reduce函数。剩下的则是由整个mapreduce框架来完成。
首先从map函数入手
我们知道map接受了数据,那么这个数据是是怎么个数据??
假如我们有下面数据
我们map函数如下:
map(LongWritable key, Text value, Context context)
上面有三个参数,其中key是偏移量,这里不是我们的重点,对于Context不了解,可以查看hadoop开发必读:认识Context类的作用.
我们这里重点讲value,这个value到底是什么?
是
还是
还是
我们在做填空题,框架之外的我们还没有看到,所以我需要明白value到底是什么?
下面我们开始运行程序
运行程序,这里让我们犯愁了,为什么,因为在运行这个程序之前,你有环境了吗?没有,
更多插件:hadoop家族、strom、spark、Linux、flume等jar包、安装包汇总下载(持续更新)
 hadoop-common-2.2.0-bin-master.zip (273.06 KB, 下载次数: 0, 售价: 2 云币)
hadoop-common-2.2.0-bin-master.zip (273.06 KB, 下载次数: 0, 售价: 2 云币)
上面下载附件,上面没有必要都放到hadoop_home/bin下面,缺什么我们放到里面就ok了。我们的路径是
复制代码
环境有了,我们需要准备数据以及mapreduce程序
一、准备数据
首先第一步我们上传待分析文件:
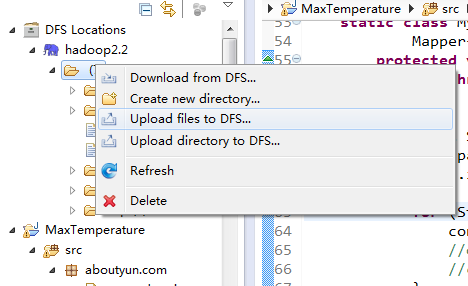
第二步:找到文件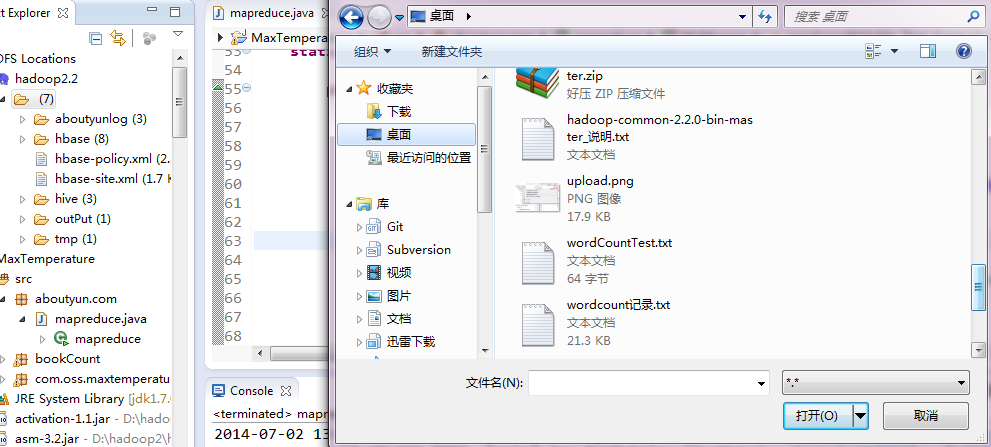
第三步:上传成功

二、mapreduce函数分析
map函数:
我们看到上面红字部分他的作用是什么,这也正是很多犯愁的地方,因为我们想把我们想看到的数据输出到eclipse的控制台,可惜的是 System.out.println并不如我们愿,所以我们可以使用 getCounter输出我们想看到的内容:
复制代码 这里我们主要验证:value值传递过来到底是什么?
运行之后下面结果
结果分析:
复制代码 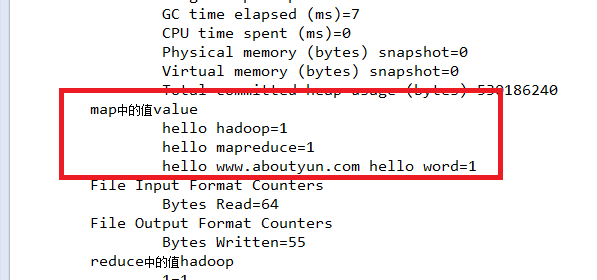
上面我们看到输出数据输出了3次,也就是说,我们的map执行了3次,那么我们的原始数据是什么情况,看下图:
结论:
从这里我们看到有多少行就有多少个map,也就是说,系统默认一行调用一个map函数,value值为一行的数据

同理reduce也是如此:
这里我们主要验证:reduce中key出现的次数:
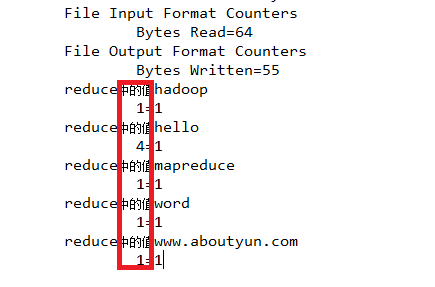
从上面结果我们看到
hadoop: 1个
hello : 4个
mapreduce: 1个
www.aboutyun.com:1个
这里我们并没有通过mapreduce的输出文件来查看,而是通过getCounter来实现的。
我们来看看reduce的输出文结果:

这里在做一个有趣的实验:
为什么那,因为很多初学者,可能会遇到一个问题,就是reduce的输出结果不正确,为什么会不正确,下面我们对reduce稍微做一些改动:
我们查看下面结果:

我们来看看reduce的输出文结果:
仔细对比我们把
一个放在循环内,一个放在了循环外,所以产生了下面的结果。这是很多初学者,在学习之初可能会碰到的问题
1.如何在讲mapreduce函数中的字符串等信息,输出到eclipse控制台?
2.除了使用下文方法,还有其它方法输出到控制台?
3.map中,系统默认接受的value值是什么?
4.reduce输出不是自己想要的结果,可能的原因是什么?
附件不能下载,可查看原文链接:
http://www.aboutyun.com/thread-8303-1-1.html
mapreduce不是很好理解,为什么?
因为我们传统编程,运行程序,都在本地,怎么会跑到别的客户端或则服务器那,总之运行程序就是一太电脑。mapreduce牛啊,他竟然可以让一个程序多台电脑一块跑,这也是它的神奇不同之处,同时也让mapreduce蒙上了一层神秘的面纱。
这里我们就来揭开这个面纱。
这里难以理解的地方是什么?它是如何分割的,如何分组、如何分区的,什么shuffer,等等各种概念涌入初学者脑海中,然后就是云里雾里、似看清、又看不清。
这里我们抛弃这些所有的概念,让我们来一个短平快、更直接、更简单的的认识。
记得我们在上学的时候,有一种题型是填空题,而mapreduce就是一个填空式编程。
为什么被认为是填空式编程,因为mapreduce是一个框架,我们所作的就是编写map函数、reduce函数、然后驱动函数main()。
填空,让我们填写的就是map、reduce函数。剩下的则是由整个mapreduce框架来完成。
首先从map函数入手
// map类
static class MyMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
final String[] splited = value.toString().split(" ");
org.apache.hadoop.mapreduce.Counter count= context.getCounter("map中的值value", value.toString());
count.increment(1l);
for (String word : splited) {
context.write(new Text(word), new LongWritable(1L));
//org.apache.hadoop.mapreduce.Counter count= context.getCounter("map中的值value", new Text(word).toString()+"个数"+new LongWritable(1L).toString());
//count.increment(1l);
}
}
}
我们知道map接受了数据,那么这个数据是是怎么个数据??
假如我们有下面数据
hello www.aboutyun.com hello word
hello hadoop
hello mapreduce
我们map函数如下:
map(LongWritable key, Text value, Context context)
上面有三个参数,其中key是偏移量,这里不是我们的重点,对于Context不了解,可以查看hadoop开发必读:认识Context类的作用.
我们这里重点讲value,这个value到底是什么?
是
hello www.aboutyun.com hello word
还是
hello
还是
hello www.aboutyun.com
我们在做填空题,框架之外的我们还没有看到,所以我需要明白value到底是什么?
下面我们开始运行程序
运行程序,这里让我们犯愁了,为什么,因为在运行这个程序之前,你有环境了吗?没有,
一、搭建环境
参考新手指导:Windows上使用Eclipse远程连接Hadoop进行程序开发,首先搭建环境,这里还用到了eclipse插件,
二、插件下载
hadoop-eclipse-plugin-2.2.0.jar链接: http://pan.baidu.com/s/1sjQ6Nnv密码: uvwx
更多插件:hadoop家族、strom、spark、Linux、flume等jar包、安装包汇总下载(持续更新)
三、遇到问题
环境搭建好了,我们开发运行程序了,遇到各种问题该如何解决,可参考
Win7 Eclipse调试Centos Hadoop2.2-Mapreduce出现问题解决方案
在window中,我们遇到最多的问题就是缺少
1.winutils.exe
2.hadoop.dll
 hadoop-common-2.2.0-bin-master.zip (273.06 KB, 下载次数: 0, 售价: 2 云币)
hadoop-common-2.2.0-bin-master.zip (273.06 KB, 下载次数: 0, 售价: 2 云币) 上面下载附件,上面没有必要都放到hadoop_home/bin下面,缺什么我们放到里面就ok了。我们的路径是
- D:\hadoop2\hadoop-2.2.0\bin
环境有了,我们需要准备数据以及mapreduce程序
一、准备数据
首先第一步我们上传待分析文件:
第二步:找到文件
第三步:上传成功
二、mapreduce函数分析
map函数:
static class MyMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
final String[] splited = value.toString().split(" ");
org.apache.hadoop.mapreduce.Counter count= context.getCounter("map中的值value", value.toString());
count.increment(1l);
for (String word : splited) {
context.write(new Text(word), new LongWritable(1L));
}
}
我们看到上面红字部分他的作用是什么,这也正是很多犯愁的地方,因为我们想把我们想看到的数据输出到eclipse的控制台,可惜的是 System.out.println并不如我们愿,所以我们可以使用 getCounter输出我们想看到的内容:
- org.apache.hadoop.mapreduce.Counter count= context.getCounter("map中的值value", value.toString());
- count.increment(1l);
运行之后下面结果
结果分析:
- map中的值value
- hello hadoop=1
- hello mapreduce=1
- hello www.aboutyun.com hello word=1
上面我们看到输出数据输出了3次,也就是说,我们的map执行了3次,那么我们的原始数据是什么情况,看下图:
结论:
从这里我们看到有多少行就有多少个map,也就是说,系统默认一行调用一个map函数,value值为一行的数据
同理reduce也是如此:
// reduce类
static class MyReduce extends
Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text k2, java.lang.Iterable<LongWritable> v2s,
Context ctx) throws java.io.IOException, InterruptedException {
long times = 0L;
for (LongWritable count : v2s) {
times += count.get();
}
org.apache.hadoop.mapreduce.Counter count1= ctx.getCounter("reduce中的值"+k2.toString(), new LongWritable(times).toString());
count1.increment(1l);
ctx.write(k2, new LongWritable(times));
}
}
这里我们主要验证:reduce中key出现的次数:
从上面结果我们看到
hadoop: 1个
hello : 4个
mapreduce: 1个
www.aboutyun.com:1个
这里我们并没有通过mapreduce的输出文件来查看,而是通过getCounter来实现的。
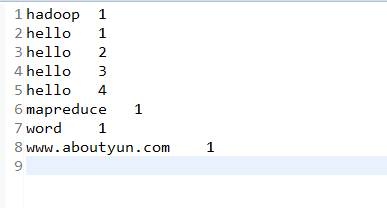
我们来看看reduce的输出文结果:
这里在做一个有趣的实验:
为什么那,因为很多初学者,可能会遇到一个问题,就是reduce的输出结果不正确,为什么会不正确,下面我们对reduce稍微做一些改动:
static class MyReduce extends
Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text k2, java.lang.Iterable<LongWritable> v2s,
Context ctx) throws java.io.IOException, InterruptedException {
long times = 0L;
for (LongWritable count : v2s) {
times += count.get();
org.apache.hadoop.mapreduce.Counter count1= ctx.getCounter("reduce中的值"+k2.toString(), new LongWritable(times).toString());
count1.increment(1l);ctx.write(k2, new LongWritable(times));
}
}
}
我们查看下面结果:
我们来看看reduce的输出文结果:
仔细对比我们把
org.apache.hadoop.mapreduce.Counter count1= ctx.getCounter("reduce中的值"+k2.toString(), new LongWritable(times).toString());
count1.increment(1l);ctx.write(k2, new LongWritable(times));
一个放在循环内,一个放在了循环外,所以产生了下面的结果。这是很多初学者,在学习之初可能会碰到的问题









)








函数浅析)
)