http://blog.csdn.net/a1154761720/article/details/51516273
MMD:maximum mean discrepancy。最大平均差异。最先提出的时候用于双样本的检测(two-sample test)问题,用于判断两个分布p和q是否相同。它的基本假设是:如果对于所有以分布生成的样本空间为输入的函数f,如果两个分布生成的足够多的样本在f上的对应的像的均值都相等,那么那么可以认为这两个分布是同一个分布。现在一般用于度量两个分布之间的相似性。在[1]中从任意空间到RKHS上介绍了MMD的计算,这里根据这个顺序来介绍。
1.任意函数空间(arbitary function space)的MMD
具体而言,基于MMD(maximize mean discrepancy)的统计检验方法是指下面的方式:基于两个分布的样本,通过寻找在样本空间上的连续函数f,求不同分布的样本在f上的函数值的均值,通过把两个均值作差可以得到两个分布对应于f的mean discrepancy。寻找一个f使得这个mean discrepancy有最大值,就得到了MMD。最后取MMD作为检验统计量(test statistic),从而判断两个分布是否相同。如果这个值足够小,就认为两个分布相同,否则就认为它们不相同。同时这个值也用来判断两个分布之间的相似程度。如果用F表示一个在样本空间上的连续函数集,那么MMD可以用下面的式子表示:
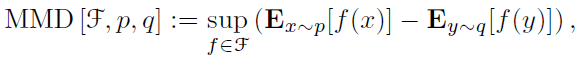
假设X和Y分别是从分布p和q通过独立同分布(iid)采样得到的两个数据集,数据集的大小分别为m和n。基于X和Y可以得到MMD的经验估计(empirical estimate)为:
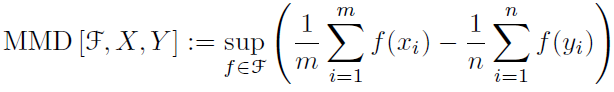
在给定两个分布的观测集X,Y的情况下,这个结果会严重依赖于给定的函数集F。为了能表示MMD的性质:当且仅当p和q是相同分布的时候MMD为0,那么要求F足够rich;另一方面为了使检验具有足够的连续性(be consistent in power),从而使得MMD的经验估计可以随着观测集规模增大迅速收敛到它的期望,F必须足够restrictive。文中证明了当F是universal RKHS上的(unit ball)单位球时,可以满足上面两个性质。
2.再生核希尔伯特空间的MMD(The MMD In reproducing kernel Hilbert Spaces):
这部分讲述了在RHKS上单位球(unit ball)作为F的时,通过有限的观测来对MMD进行估计,并且设立一些MMD可以用来区分概率度量的条件。
在RKHS上,每个f对应一个feature map。在feature map的基础上,首先对于某个分布p定义一个mean embedding of p,它满足如下的性质:
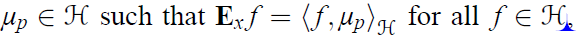
mean embedding存在是有约束条件的[1]。在p和q的mean embedding存在的条件下,MMD的平方可以表示如下:
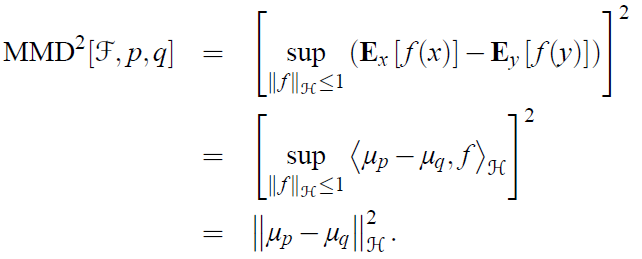
下面是关于MMD作为一个Borel probability measures时,对F的一个约束及其证明,要求F:be a unit ball in a universal RKHS。比如Gaussian和Laplace RKHSs。进一步在给定了RKHS对应核函数,这个MMD的平方可以表示:
x和x’分别表示两个服从于p的随机变量,y和y‘分别表示服从q的随机变量。对于上面的一个统计估计可以表示为:
对于一个two-sample test, 给定的null hypothesis: p和q是相同,以及the alternative hypothesis: p和q不等。这个通过将test statistic和一个给定的阈值相比较得到,如果MMD大于阈值,那么就reject null hypothesis,也就是两个分布不同。如果MMD小于某个阈值,就接受null hypothesis。由于MMD的计算时使用的是有限的样本数,这里会出现两种类型的错误:第一种错误出现在null hypothesis被错误的拒绝了;也就是本来两个分布相同,但是却被判定为相同。反之,第二种错误出现在null hypothesis被错误的接受了。文章[1]中提供了许多关于hypothesis test的方法,这里不讨论。
在domain adaptation中,经常用到MMD来在特征学习的时候构造正则项来约束学到的表示,使得两个域上的特征尽可能相同。从上面的定义看,我们在判断两个分布p和q的时候,需要将观测样本首先映射到RKHS空间上,然后再判断。但实际上很多文章直接将观测样本用于计算,省了映射的那个步骤。
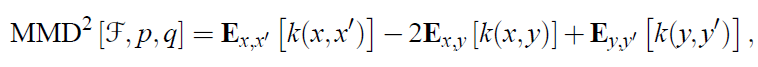
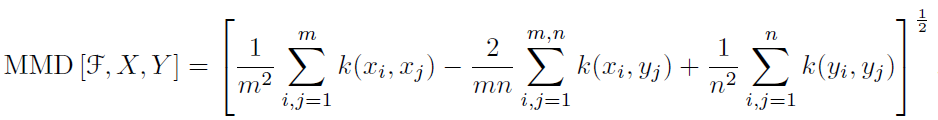
reference
[1] A kernel two sample test
[2] Optimal kernel choice for large-scale two-sample tests
[3] Deep domain confusion: maximizing for domain invariance
[4] Learning transferable feature with deep adaptation nets
[5] Deep transfer network:Unsupervised domain adaptation
[6] Adaptive visual category models to new domains
[7] Geodesic flow kernel for unsupervised domain adaptation
[8] Transfer sparse coding for robust image representation


)













 - 共享框架)


