点击@计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
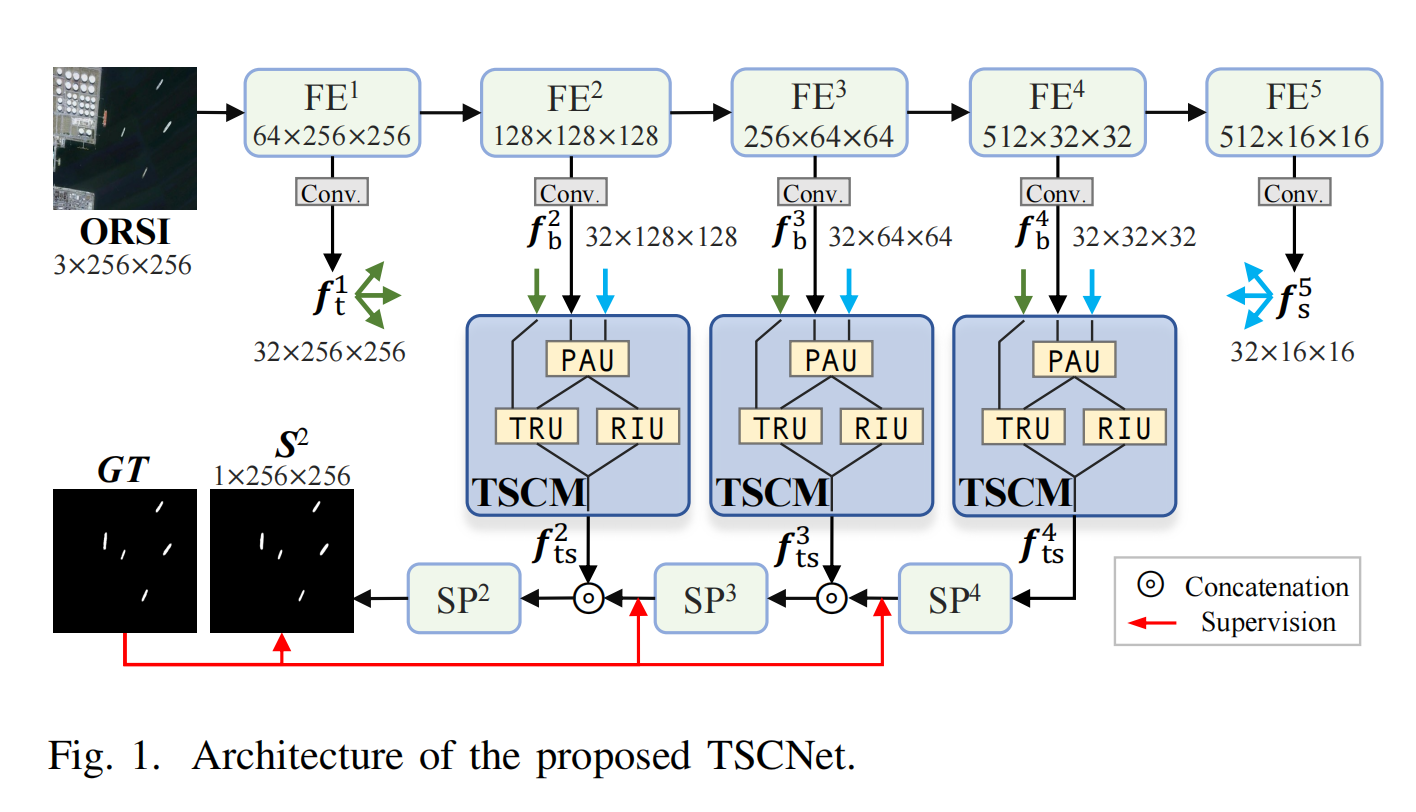
1.【显著目标检测】Texture-Semantic Collaboration Network for ORSI Salient Object Detection
-
论文地址:https://arxiv.org//pdf/2312.03548
-
开源代码:GitHub - MathLee/TSCNet: [TCAS-II 2023] [TSCNet] Texture-Semantic Collaboration Network for ORSI Salient Object Detection
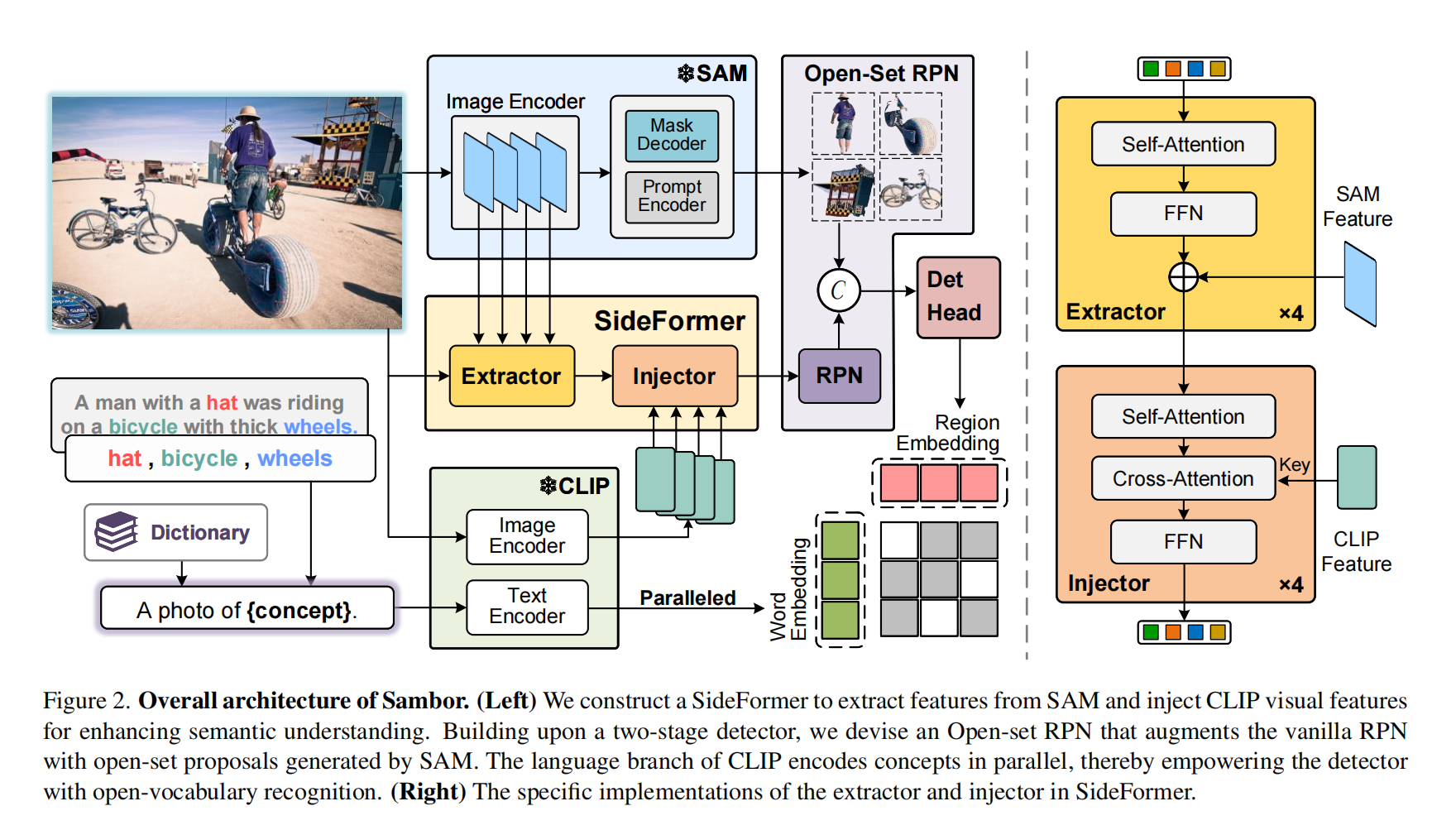
2.【图像分割】Boosting Segment Anything Model Towards Open-Vocabulary Learning
-
论文地址:https://arxiv.org//pdf/2312.03628
-
开源代码(即将开源):GitHub - ucas-vg/Sambor: Sambor: Boosting Segment Anything Model Towards Open-Vocabulary Learning
3.【图像分割】Improving the Generalization of Segmentation Foundation Model under Distribution Shift via Weakly Supervised Adaptation
-
论文地址:https://arxiv.org//pdf/2312.03502
-
开源代码(即将开源):GitHub - zhang-haojie/wesam

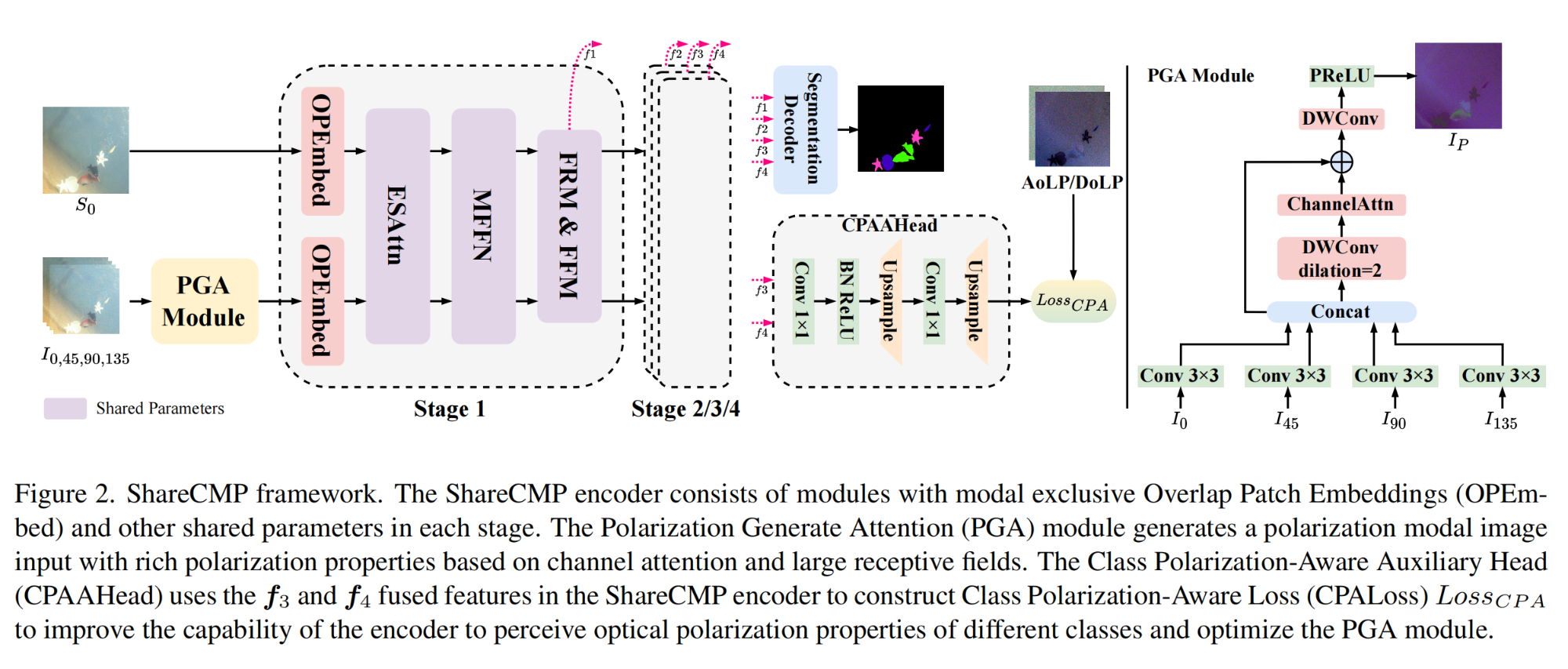
4.【语义分割】ShareCMP: Polarization-Aware RGB-P Semantic Segmentation
-
论文地址:https://arxiv.org//pdf/2312.03430
-
开源代码(即将开源):GitHub - LEFTeyex/ShareCMP: ShareCMP: Polarization-Aware RGB-P Semantic Segmentation.
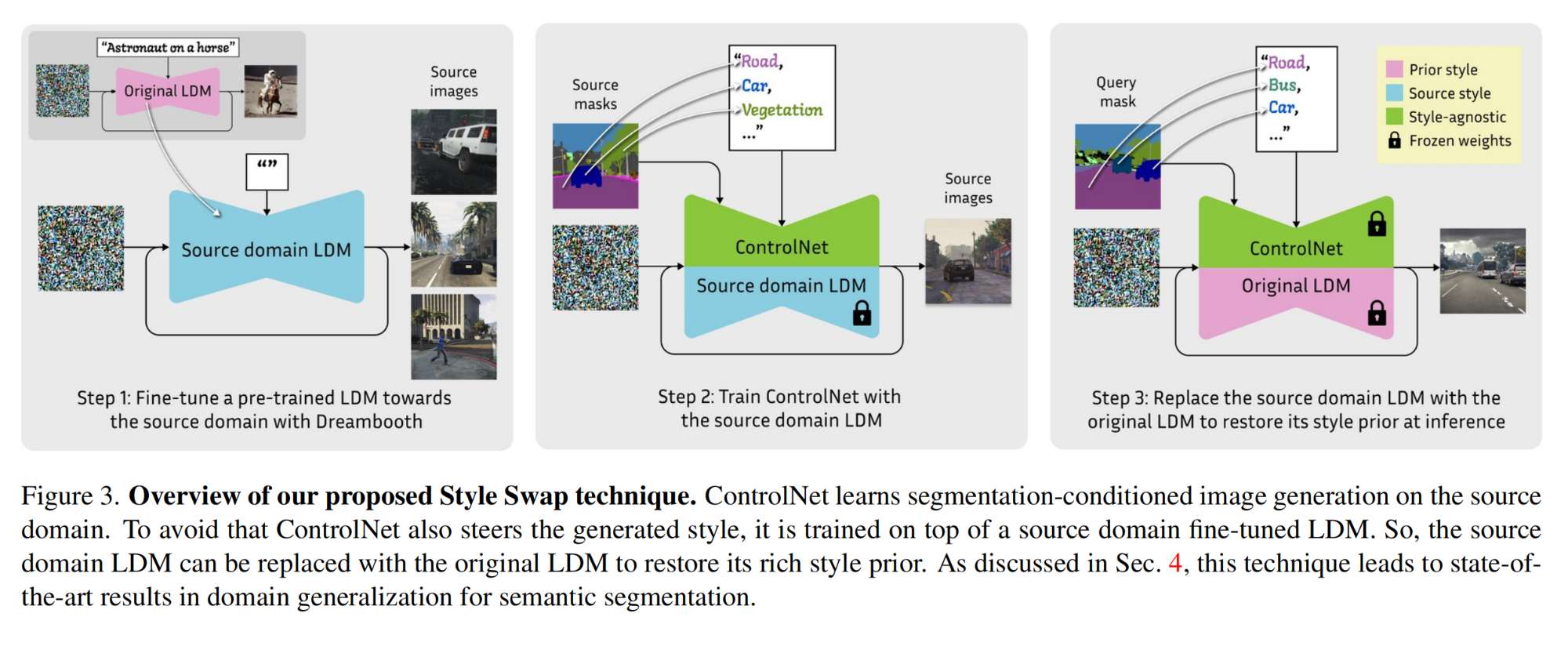
5.【语义分割】DGInStyle: Domain-Generalizable Semantic Segmentation with Image Diffusion Models and Stylized Semantic Control
-
论文地址:https://arxiv.org//pdf/2312.03048
-
工程主页:DGInStyle: Domain-Generalizable Semantic Segmentation with Image Diffusion Models and Stylized Semantic Control
-
代码即将开源
6.【点云分割】PartSLIP++: Enhancing Low-Shot 3D Part Segmentation via Multi-View Instance Segmentation and Maximum Likelihood Estimation
-
论文地址:https://arxiv.org//pdf/2312.03015
-
开源代码:GitHub - zyc00/PartSLIP2

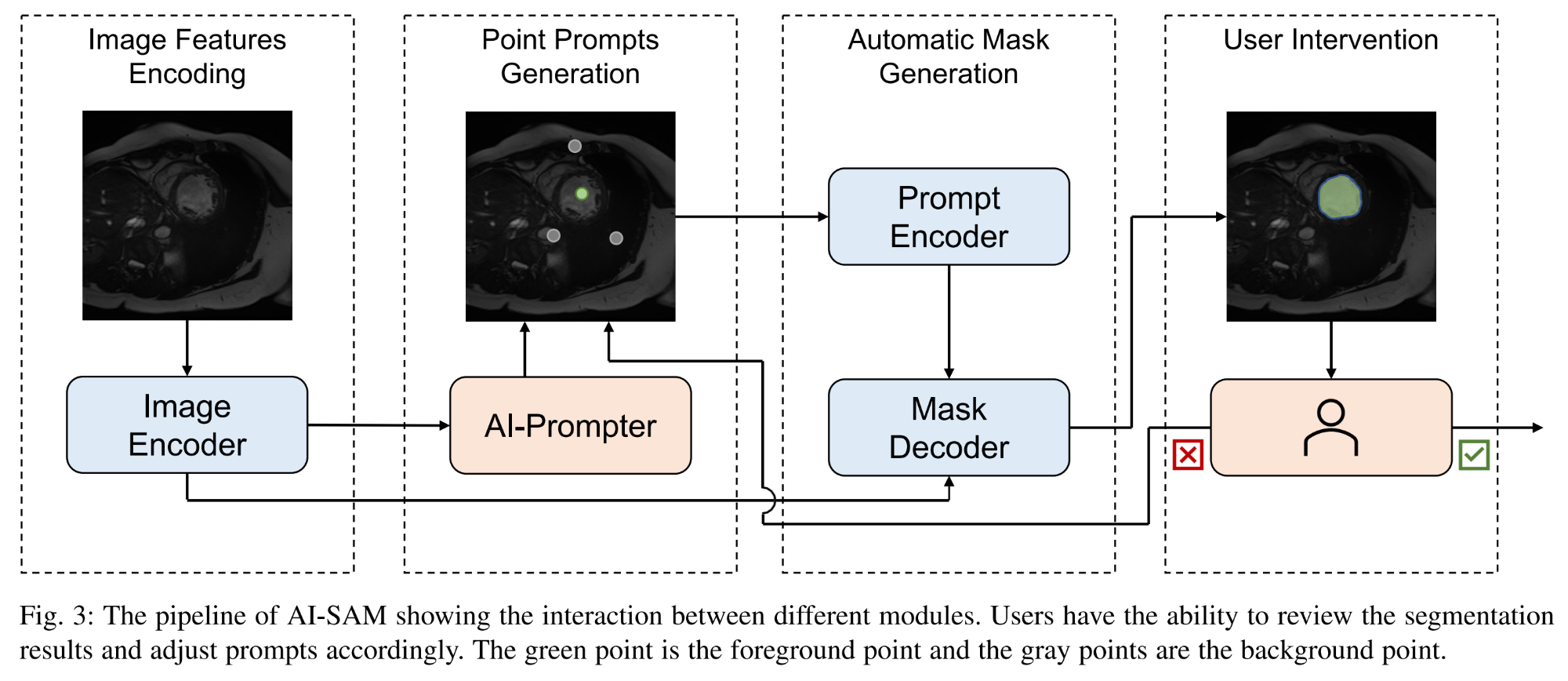
7.【医学图像分割】AI-SAM: Automatic and Interactive Segment Anything Model
-
论文地址:https://arxiv.org//pdf/2312.03119
-
开源代码(即将开源):GitHub - ymp5078/AI-SAM: AI-SAM: Automatic and Interactive Segment Anything Model
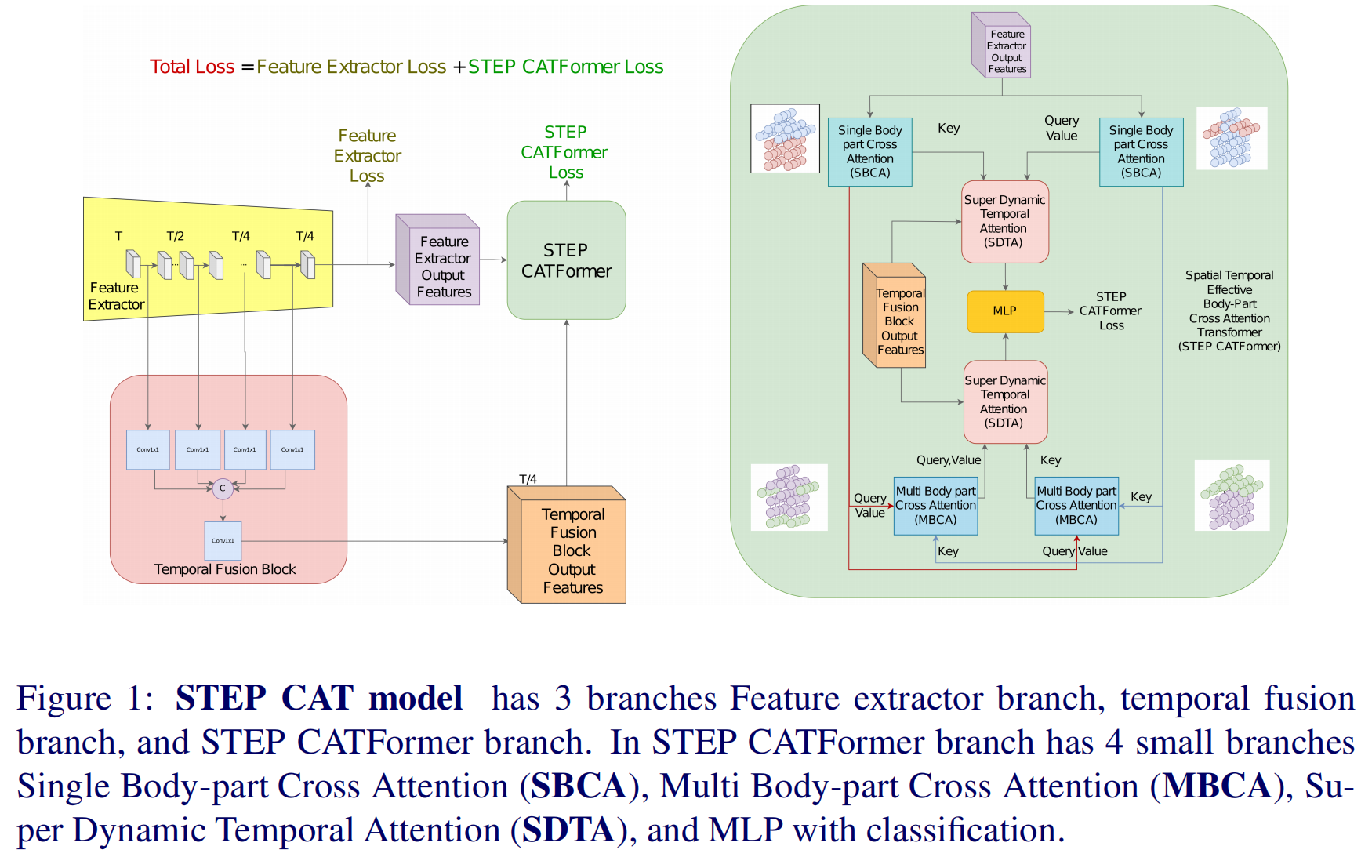
8.【动作识别】STEP CATFormer: Spatial-Temporal Effective Body-Part Cross Attention Transformer for Skeleton-based Action Recognition
-
论文地址:https://arxiv.org//pdf/2312.03288
-
开源代码(即将开源):GitHub - maclong01/STEP-CATFormer: [BMVC 2023] Official code for "STEP CATFormer: Spatial-Temporal Effective Body-Part Cross Attention Transformer for Skeleton-based Action Recognition"
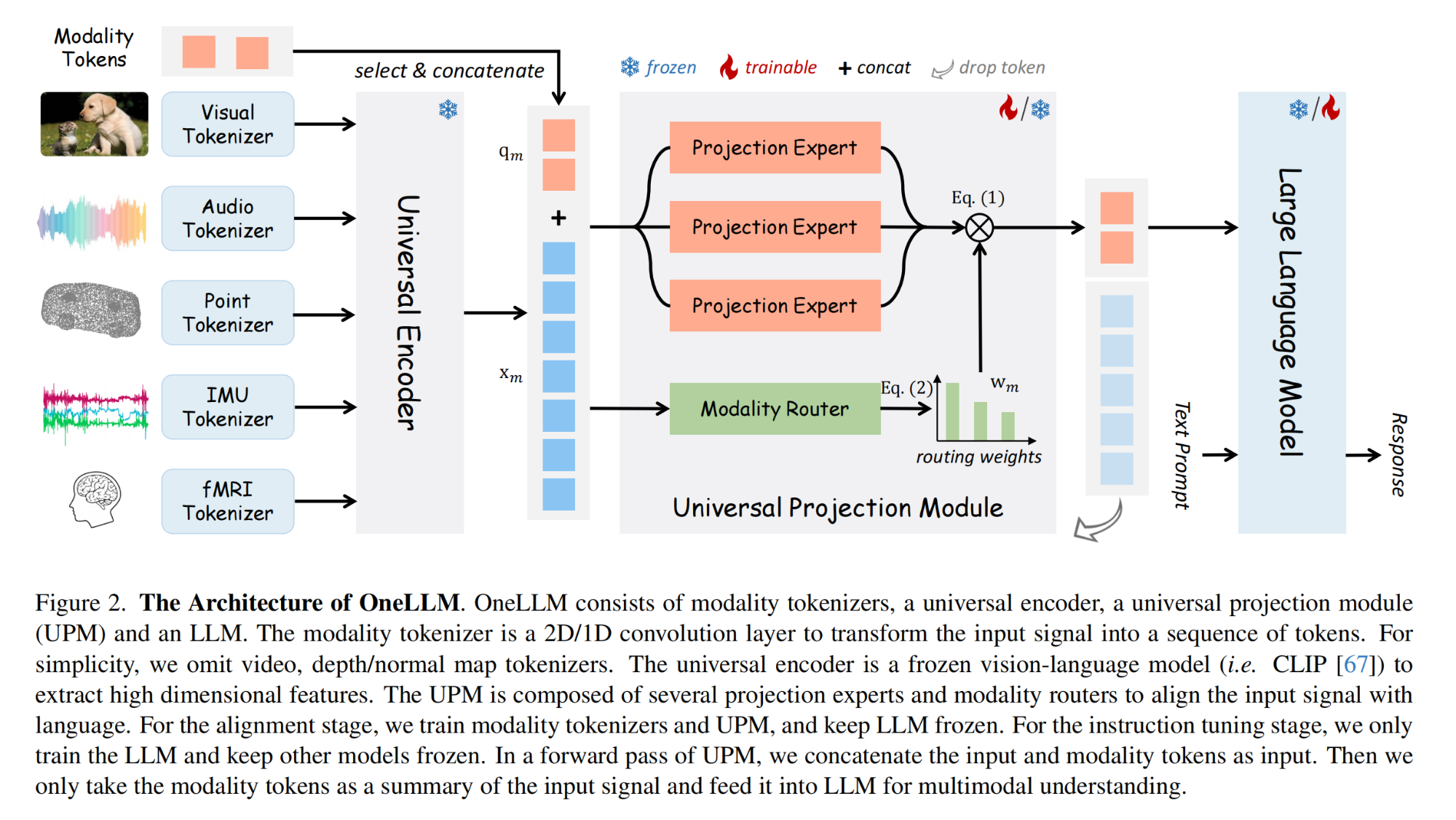
9.【多模态】OneLLM: One Framework to Align All Modalities with Language
-
论文地址:https://arxiv.org//pdf/2312.03700
-
开源代码:GitHub - csuhan/OneLLM: OneLLM: One Framework to Align All Modalities with Language
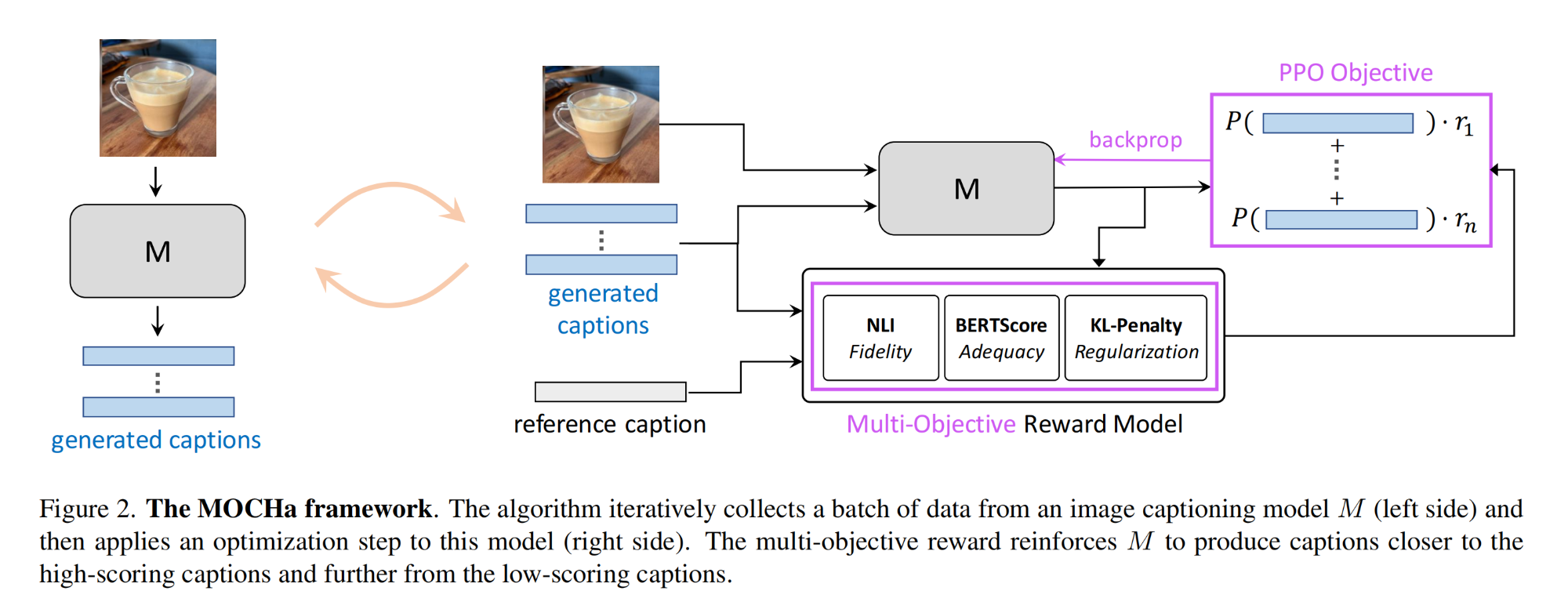
10.【多模态】MOCHa: Multi-Objective Reinforcement Mitigating Caption Hallucinations
-
论文地址:https://arxiv.org//pdf/2312.03631
-
工程主页:MOCHa: Multi-Objective Reinforcement Mitigating Caption Hallucinations
-
开源代码(即将开源):GitHub - assafbk/mocha_code: Code Repo for MOCHa: Multi-Objective Reinforcement Mitigating Caption Hallucinations
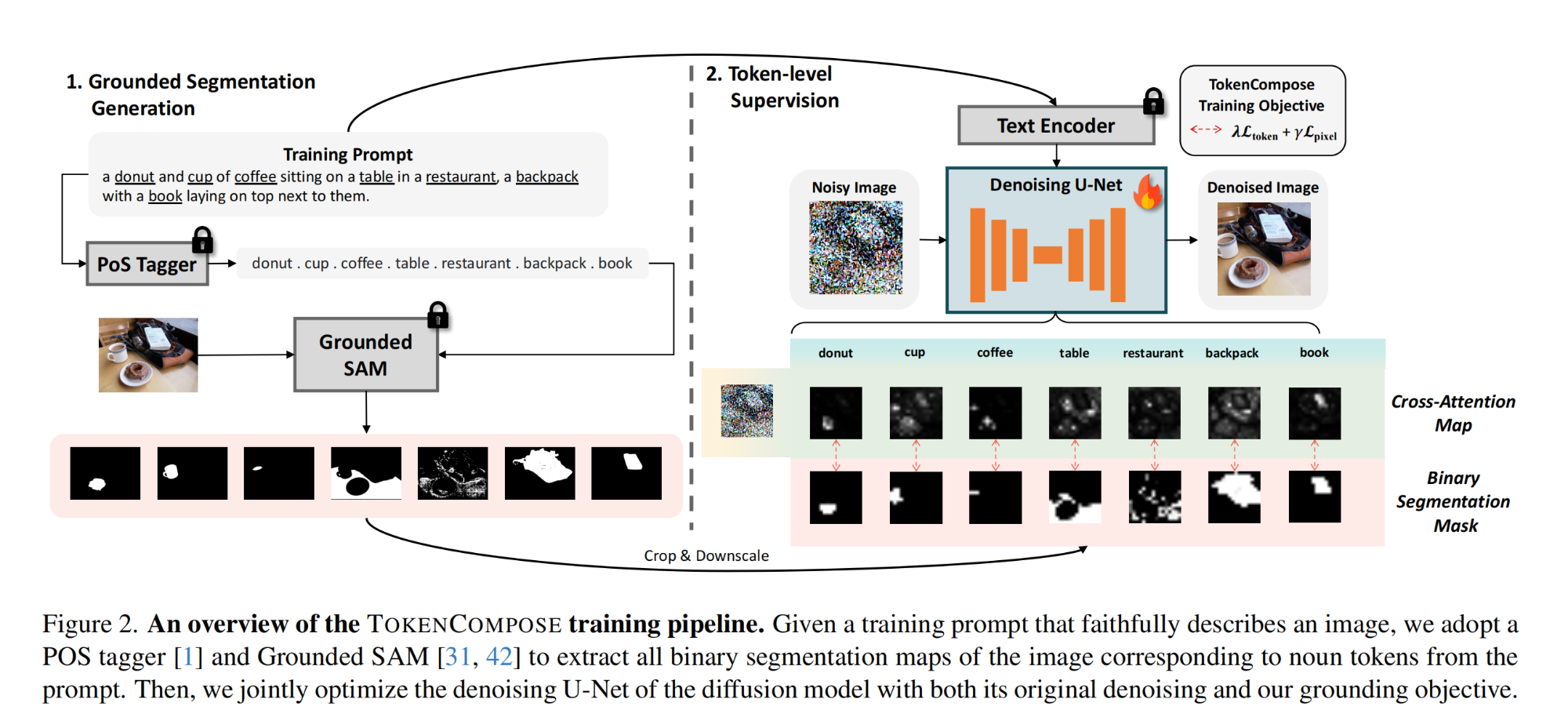
11.【多模态】TokenCompose: Grounding Diffusion with Token-level Supervision
-
论文地址:https://arxiv.org//pdf/2312.03626
-
工程主页:TokenCompose: Grounding Diffusion with Token-level Supervision
-
开源代码:GitHub - mlpc-ucsd/TokenCompose: (arXiv) 🧩 TokenCompose: Grounding Diffusion with Token-level Supervision
12.【多模态】FERGI: Automatic Annotation of User Preferences for Text-to-Image Generation from Spontaneous Facial Expression Reaction
-
论文地址:https://arxiv.org//pdf/2312.03187
-
开源代码:GitHub - ShuangquanFeng/FERGI

13.【多模态】Uni3DL: Unified Model for 3D and Language Understanding
-
论文地址:https://arxiv.org//pdf/2312.03026
-
工程主页:Uni3DL
-
开源代码(即将开源):https://github.com/lx709/Uni3DL

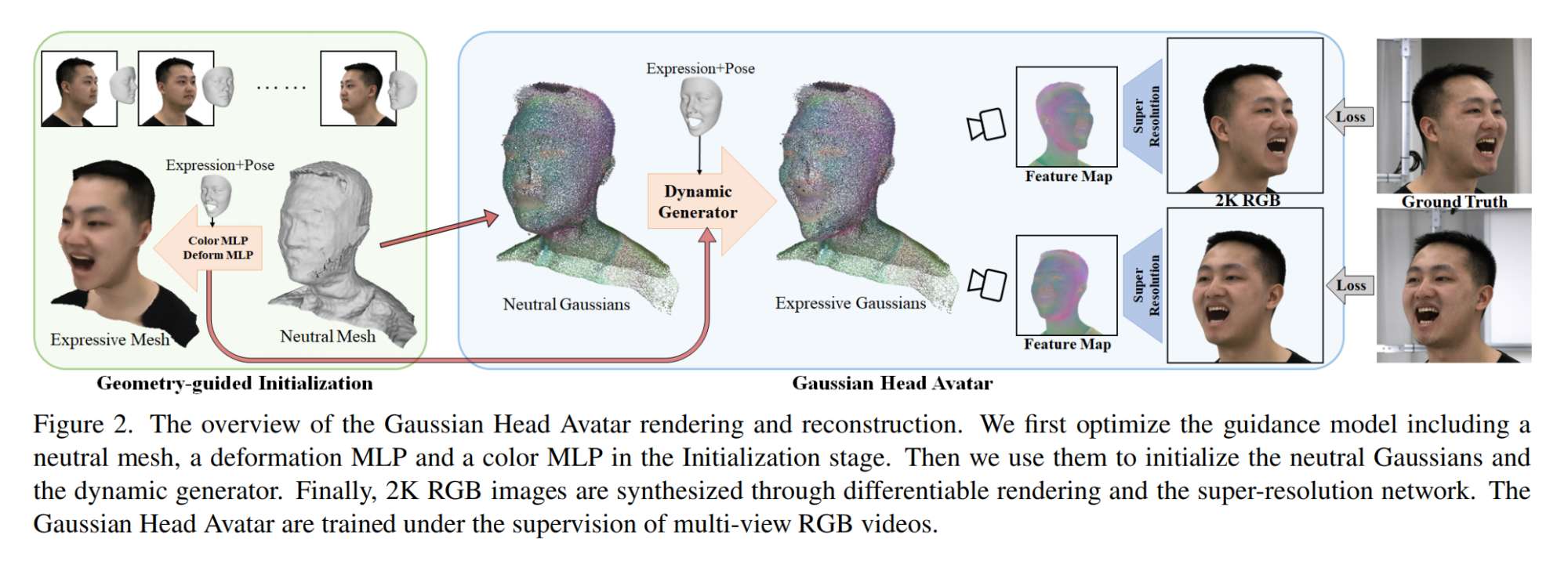
14.【数字人】Gaussian Head Avatar: Ultra High-fidelity Head Avatar via Dynamic Gaussians
-
论文地址:https://arxiv.org//pdf/2312.03029
-
工程主页:Gaussian Head Avatar's Project Page
-
开源代码(即将开源):GitHub - YuelangX/Gaussian-Head-Avatar: Official repository for "Gaussian Head Avatar: Ultra High-fidelity Head Avatar via Dynamic Gaussians"
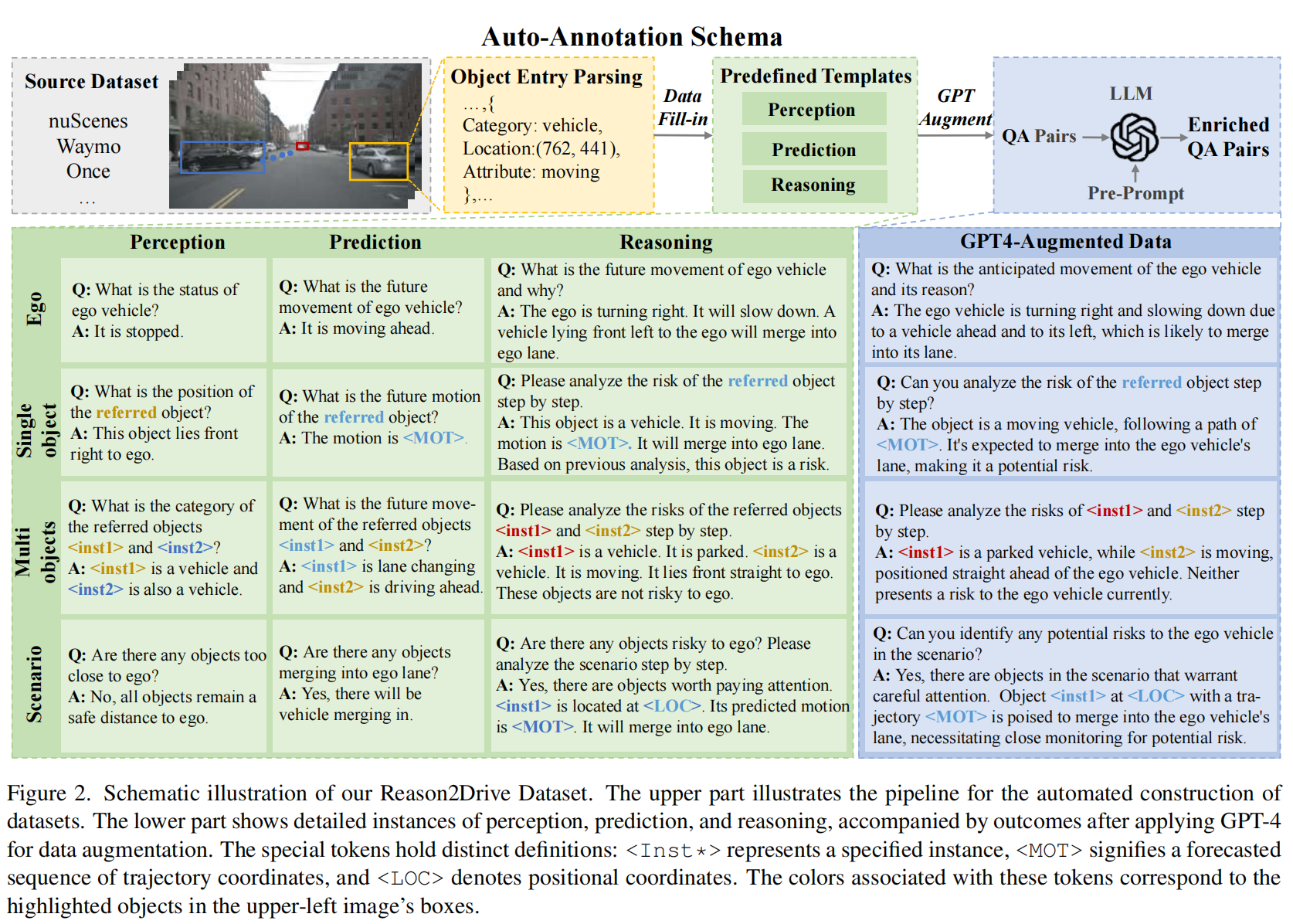
15.【自动驾驶】Reason2Drive: Towards Interpretable and Chain-based Reasoning for Autonomous Driving
-
论文地址:https://arxiv.org//pdf/2312.03661
-
开源代码(即将开源):GitHub - fudan-zvg/Reason2Drive: Reason2Drive: Towards Interpretable and Chain-based Reasoning for Autonomous Driving
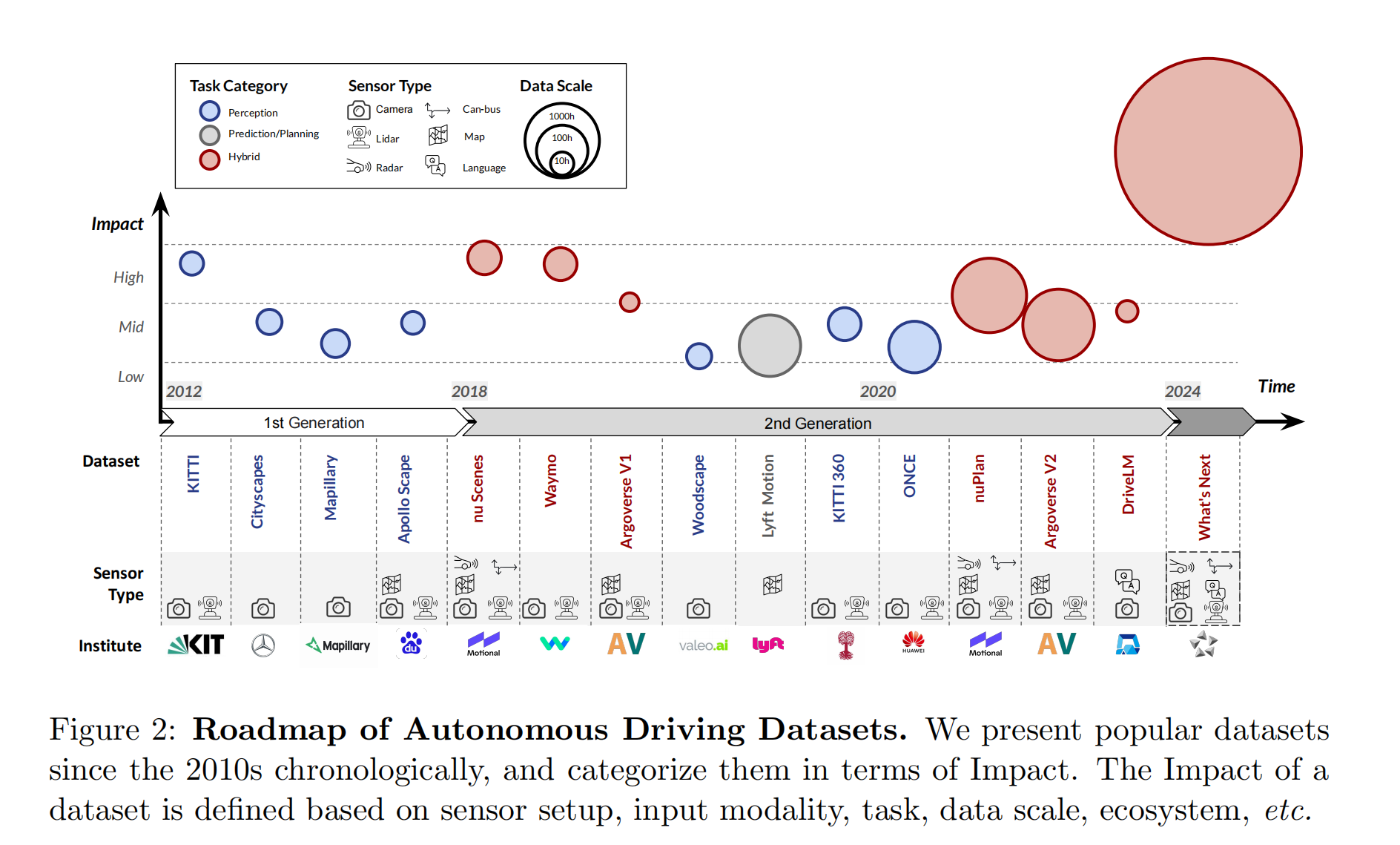
16.【自动驾驶】Open-sourced Data Ecosystem in Autonomous Driving: the Present and Future
-
论文地址:https://arxiv.org//pdf/2312.03408
-
开源代码(即将开源):GitHub - OpenDriveLab/DriveAGI: Embracing Foundation Models into Autonomous Agent and System
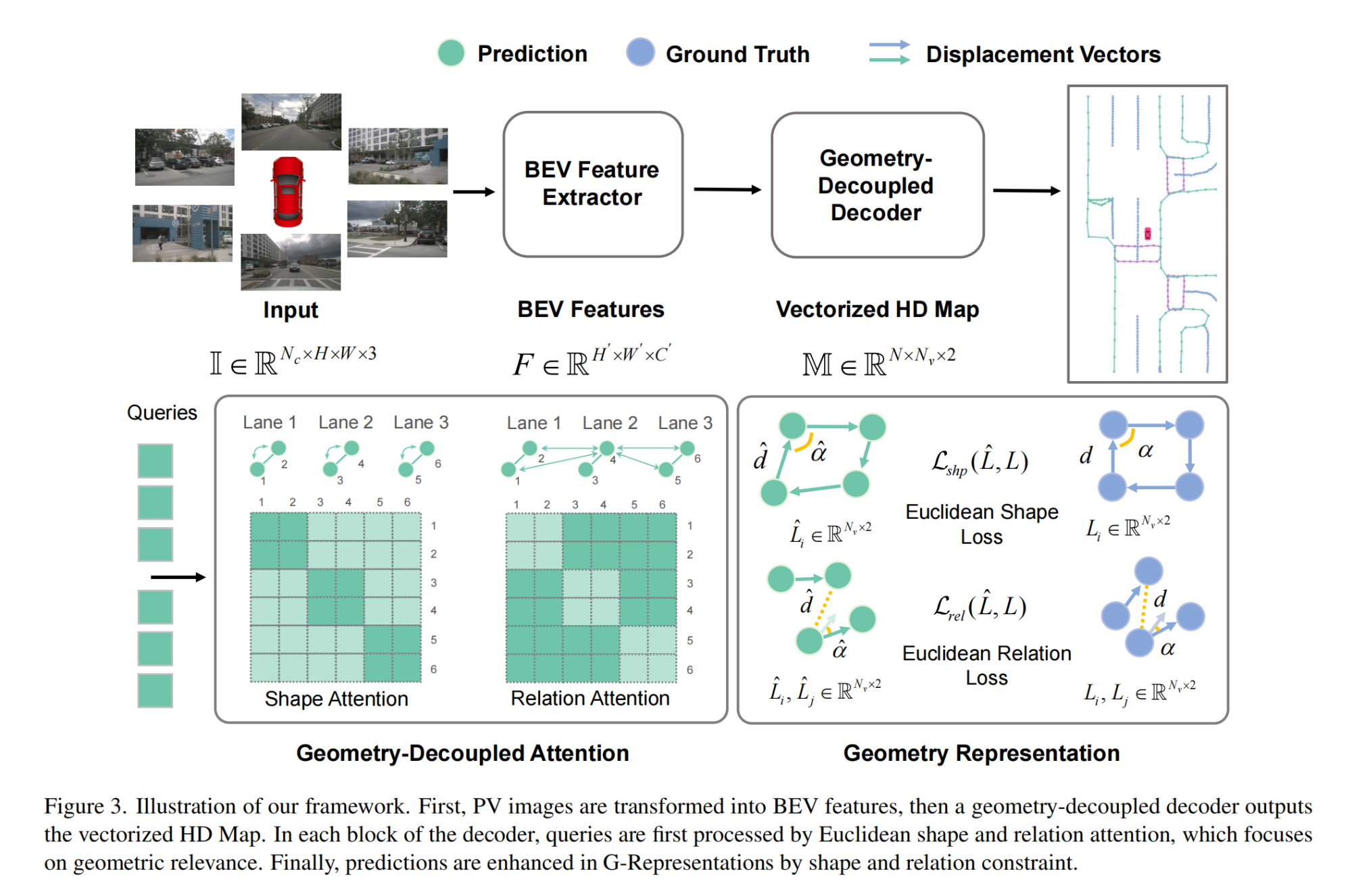
17.【自动驾驶】Online Vectorized HD Map Construction using Geometry
-
论文地址:https://arxiv.org//pdf/2312.03341
-
工程主页:Online Vectorized HD Map Construction using Geometry
-
开源代码:GitHub - cnzzx/GeMap: Online Vectorized HD Map Construction using Geometry
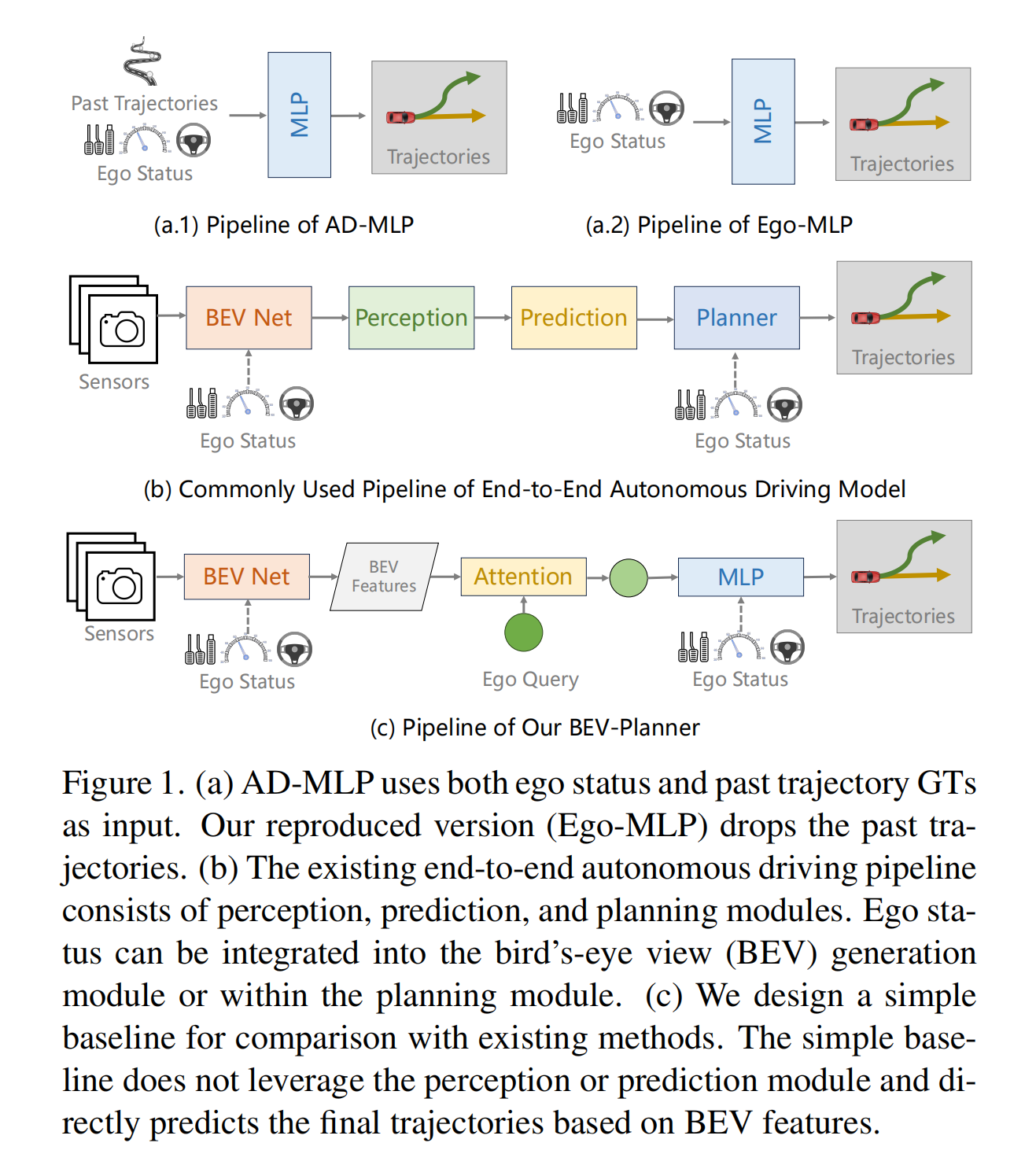
18.【自动驾驶】Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
-
论文地址:https://arxiv.org//pdf/2312.03031
-
开源代码(即将开源):GitHub - NVlabs/BEV-Planner
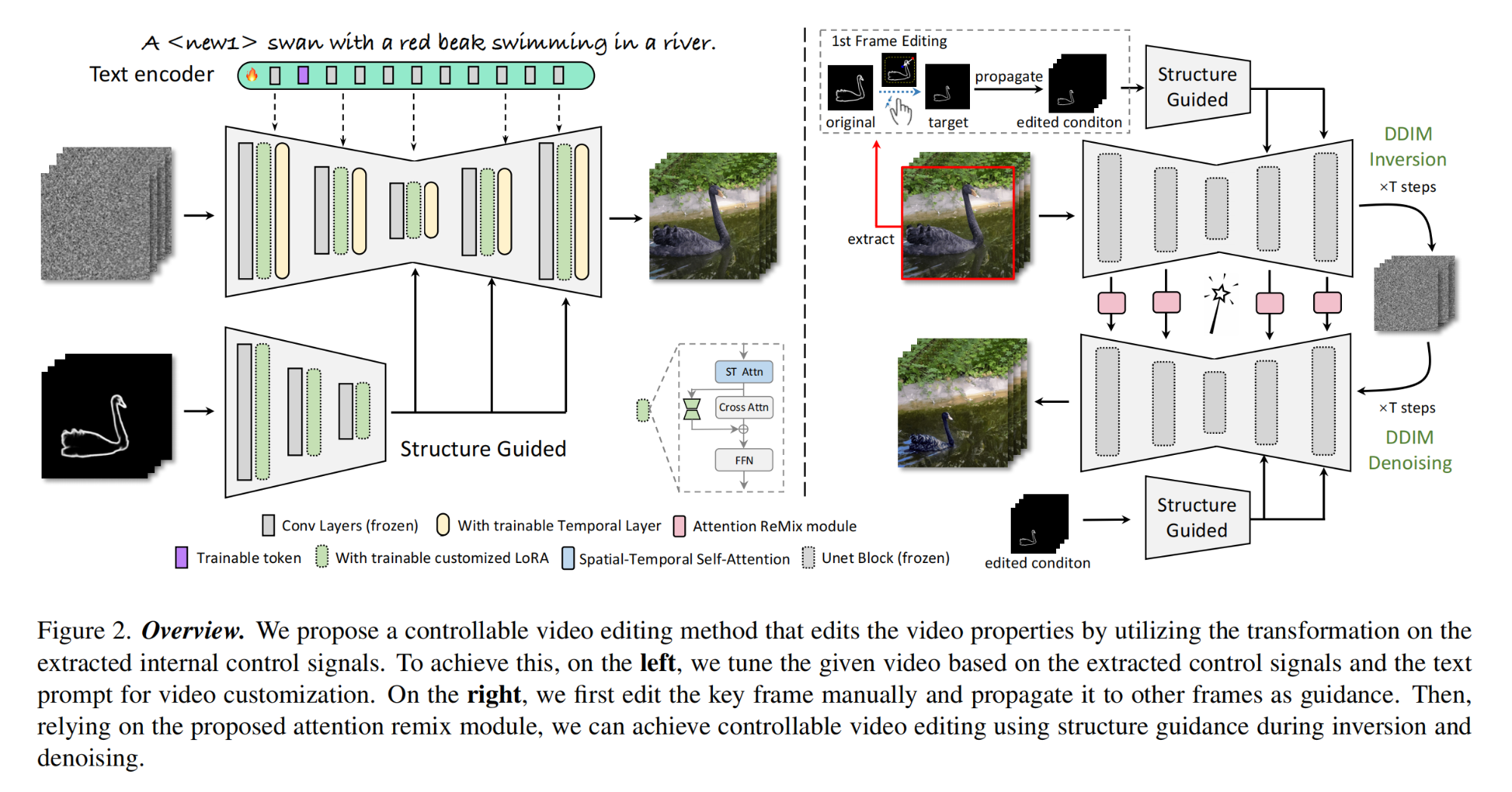
19.【视频编辑】MagicStick: Controllable Video Editing via Control Handle Transformations
-
论文地址:https://arxiv.org//pdf/2312.03047
-
工程主页:MagicStick🪄
-
开源代码(即将开源):GitHub - mayuelala/MagicStick: MagicStick: This repo is the official implementation of "MagicStick: Controllable Video Editing via Control Handle Transformations"
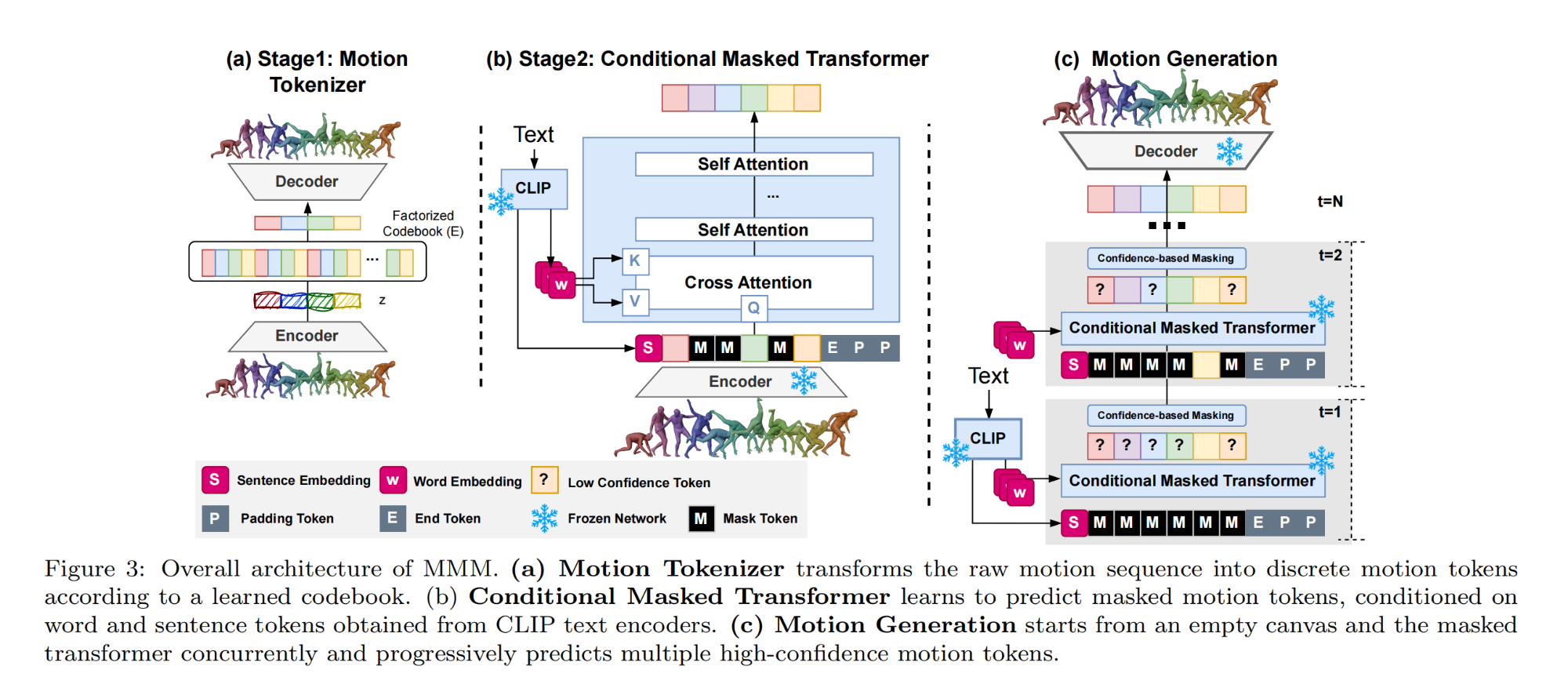
20.【人体运动生成】MMM: Generative Masked Motion Model
-
论文地址:https://arxiv.org//pdf/2312.03596
-
工程主页:MMM: Generative Masked Motion Model
-
开源代码(即将开源):GitHub - exitudio/MMM
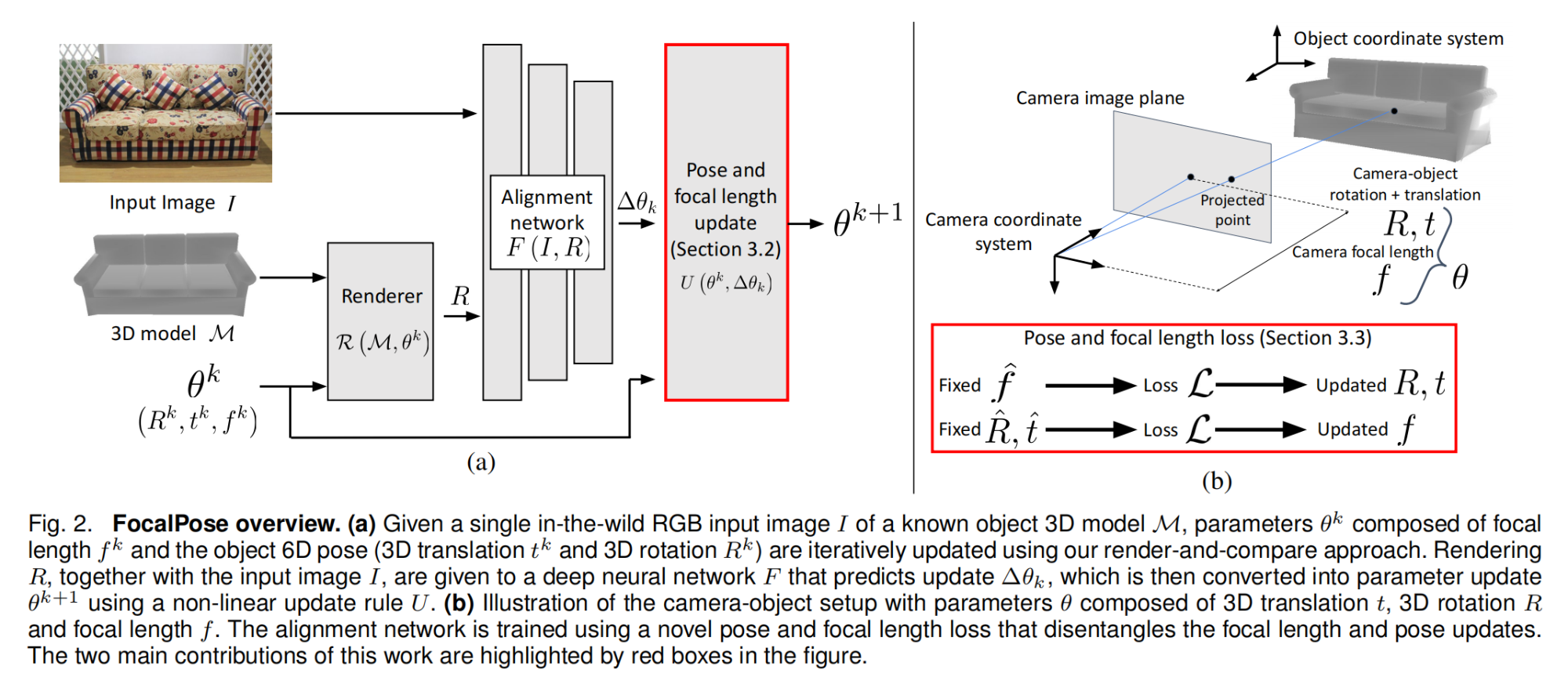
21.【姿态估计】FocalPose++: Focal Length and Object Pose Estimation via Render and Compare
-
论文地址:https://arxiv.org//pdf/2312.02985
-
开源代码:GitHub - cifkam/FocalPosePP
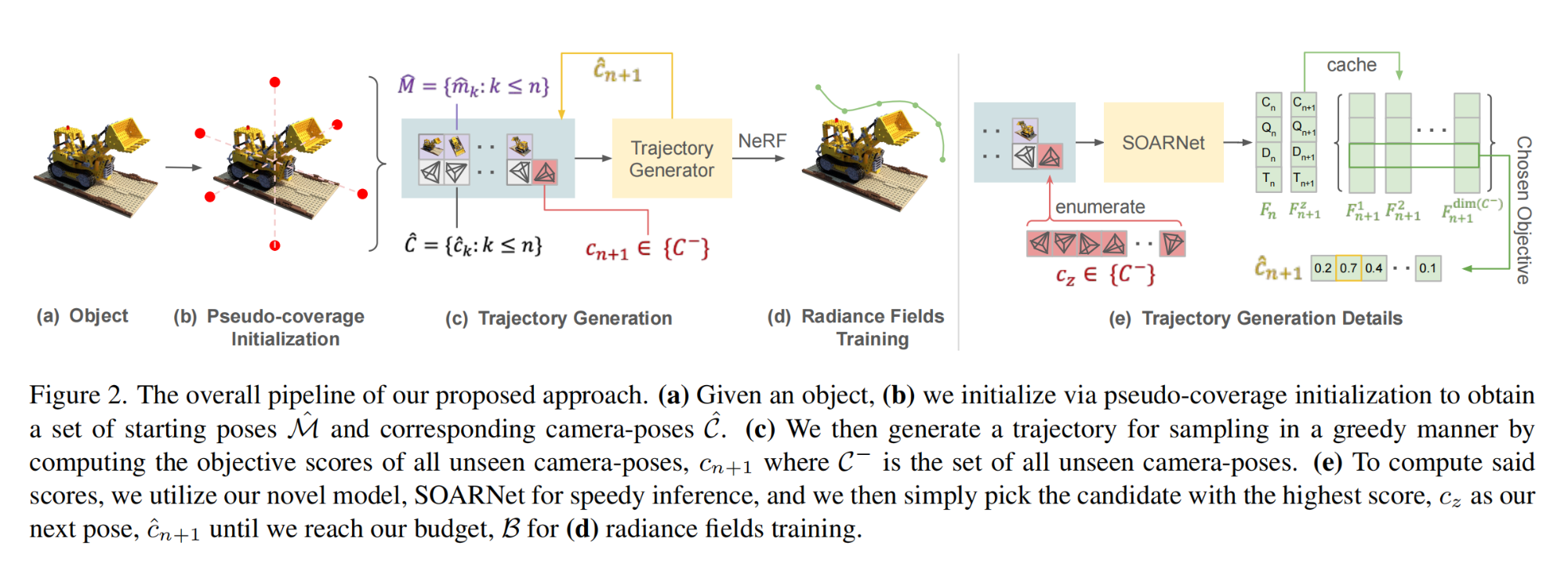
22.【NeRF】SO-NeRF: Active View Planning for NeRF using Surrogate Objectives
-
论文地址:https://arxiv.org//pdf/2312.03266
-
工程主页:SO-NeRF
-
开源代码(即将开源):https://github.com/ai4ce/SO-NeRF
23.【图像合成】Self-conditioned Image Generation via Generating Representations
-
论文地址:https://arxiv.org//pdf/2312.03701
-
开源代码:GitHub - LTH14/rcg: PyTorch implementation of RCG https://arxiv.org/abs/2312.03701

24.【图像合成】LooseControl: Lifting ControlNet for Generalized Depth Conditioning
-
论文地址:https://arxiv.org//pdf/2312.03079
-
工程主页:LooseControl
-
开源代码:GitHub - shariqfarooq123/LooseControl: Lifting ControlNet for Generalized Depth Conditioning

25.【视频生成】MotionCtrl: A Unified and Flexible Motion Controller for Video Generation
-
论文地址:https://arxiv.org//pdf/2312.03641
-
工程主页:MotionCtrl
-
开源代码(即将开源):GitHub - TencentARC/MotionCtrl

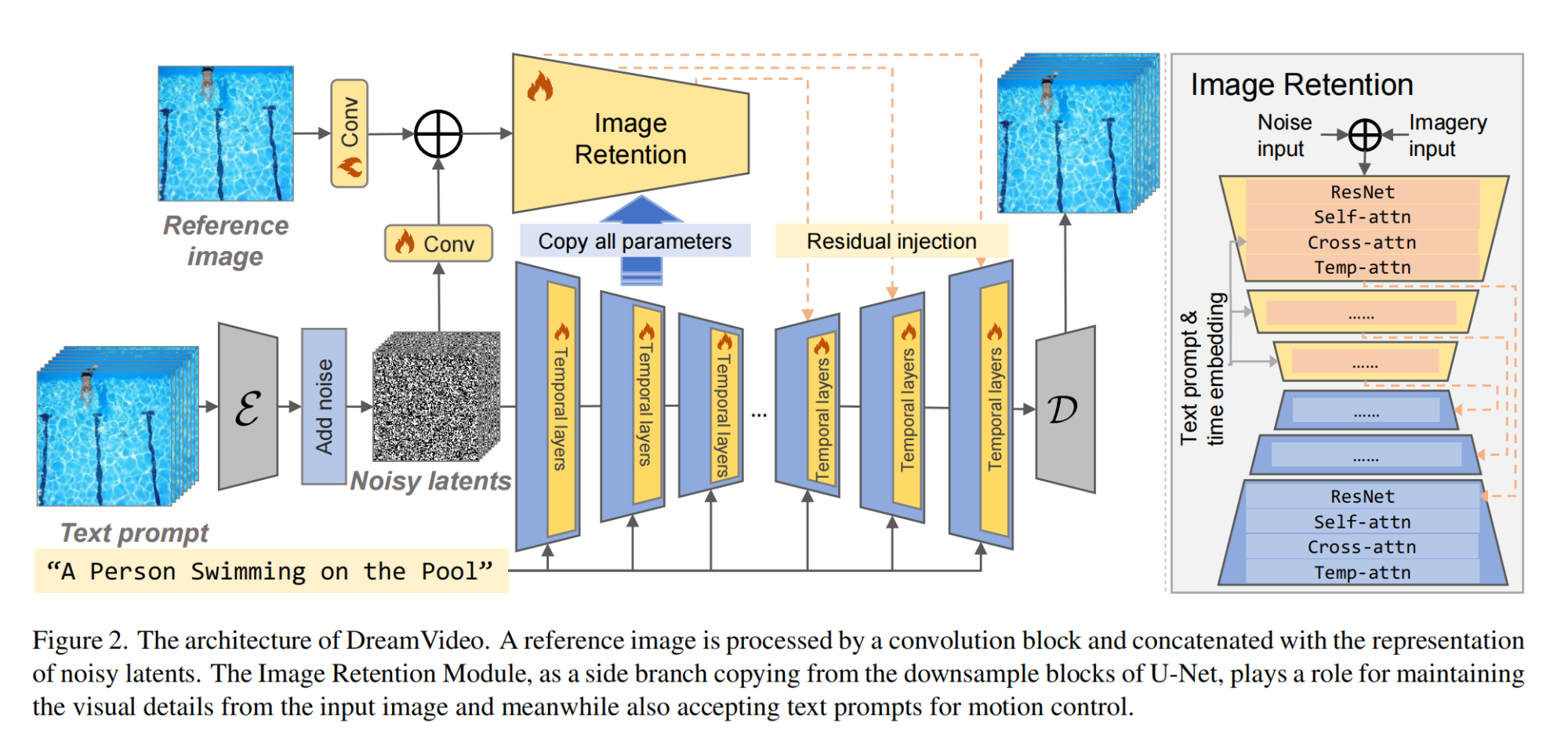
26.【视频生成】DreamVideo: High-Fidelity Image-to-Video Generation with Image Retention and Text Guidance
-
论文地址:https://arxiv.org//pdf/2312.03018
-
工程主页:DreamVideo: High-Fidelity Image-to-Video Generation with Image Retention and Text Guidance
-
开源代码(即将开源):GitHub - anonymous0769/DreamVideo
27.【三维重建】DreamComposer: Controllable 3D Object Generation via Multi-View Conditions
-
论文地址:https://arxiv.org//pdf/2312.03611
-
工程主页:DreamComposer: Controllable 3D Object Generation via Multi-View Conditions
-
开源代码(即将开源):GitHub - yhyang-myron/DreamComposer: [Arxiv23] DreamComposer: Controllable 3D Object Generation via Multi-View Conditions

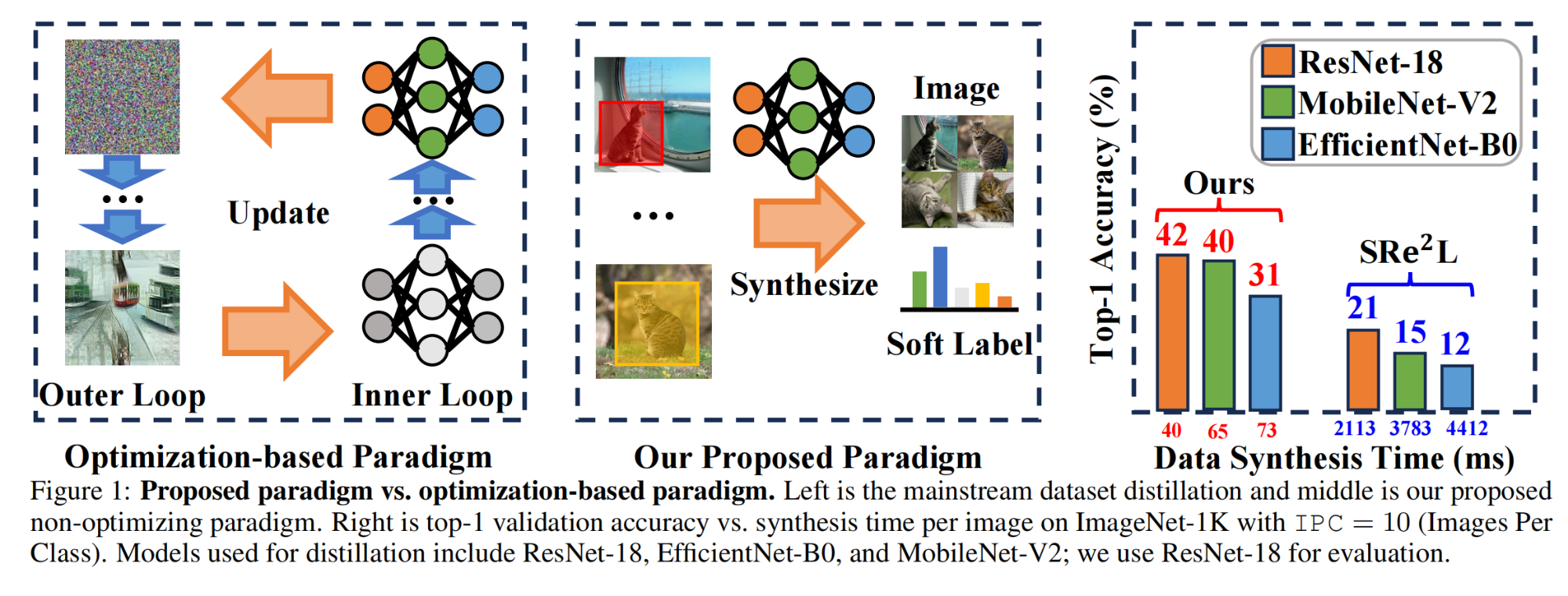
28.【数据蒸馏】On the Diversity and Realism of Distilled Dataset: An Efficient Dataset Distillation Paradigm
-
论文地址:https://arxiv.org//pdf/2312.03526
-
开源代码(即将开源):https://github.com/LINs-lab/RDED
论文已打包,下载链接
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
CV计算机视觉每日开源代码Paper with code速览-2023.12.7
CV计算机视觉每日开源代码Paper with code速览-2023.12.6
CV计算机视觉每日开源代码Paper with code速览-2023.12.5
CV计算机视觉每日开源代码Paper with code速览-2023.12.4
CV计算机视觉每日开源代码Paper with code速览-2023.12.1


)


)
:双核相互激活和启动流程)


:数据库的设计范式)


![[数据集][目标检测]道路坑洞目标检测数据集VOC+YOLO格式665张1类别](http://pic.xiahunao.cn/[数据集][目标检测]道路坑洞目标检测数据集VOC+YOLO格式665张1类别)
模拟量高速信号(50KHz)隔离变送器)


更换硬盘时间和精神双重折磨的教训)


