引入:智能指针的意义是什么?
RAll是一种利用对象生命周期来控制程序资源(如内存、文件句柄、网络连接、互斥量等等)的简单技术。
在对象构造时获取资源,接着控制对资源的访问使之在对象的生命周期内始终保持有效,最后在
对象析构的时候释放资源。借此,我们实际上把管理一份资源的责任托管给了一个对象。这种做
法有两大好处:
· 不需要显式地释放资源。
· 采用这种方式,对象所需的资源在其生命期内始终保持有效。
说白了就是为了解决异常引起的内存泄漏!我们知道,如果一个内存在申请和释放这二者之间被抛出异常了,那么有可能就会出现内存泄漏,而智能指针的本质就是将指向这块内存的指针封装成一个类,该指针作为类的对象以后,就会在出作用域是自动的进行析构,所以我们再也不用担心异常引出的内存泄漏问题了!
一:智能指针的使用场景
1:异常导致的内存泄漏
#include<exception>
int div()
{int a, b;cin >> a >> b;if (b == 0)throw invalid_argument("除0错误");return a / b;
}
void func()
{int* ptr = new int(1); //赋值1 方便监视窗口观察//...cout << div() << endl;//...delete ptr;
}
int main()
{try{func();}catch (exception& e){cout << e.what() << endl;}return 0;
}运行结果:
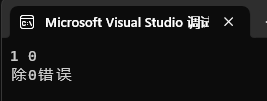

通过监视窗口体现内存泄漏:

2:异常的重新抛出
根据上篇博客,可知,其实这种简单的用异常的重新抛出也可以解决,代码:
int div()
{int a, b;cin >> a >> b;if (b == 0)throw invalid_argument("除0错误");return a / b;
}
void func()
{int* ptr = new int;try{cout << div() << endl;}catch (...){delete ptr;throw;}delete ptr;
}
int main()
{try{func();}catch (exception& e){cout << e.what() << endl;}return 0;
}
运行结果及监视窗口:
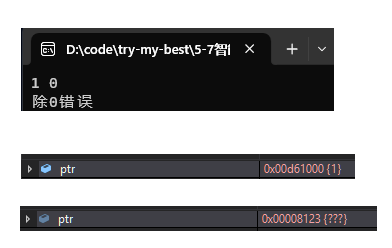
解释:即使是抛出异常,但仍然没有内存泄漏!
3:智能指针的实现
对于上面这个内存泄漏的问题,我们还可以采取智能指针来解决:
// SmartPtr类(译为智能指针类)
template<class T>
class SmartPtr
{
public:SmartPtr(T* ptr = nullptr): _ptr(ptr){}~SmartPtr(){if (_ptr)delete _ptr;cout << "析构被调用" << endl;}private:T* _ptr;
};int div()
{int a, b;cin >> a >> b;if (b == 0)throw invalid_argument("除0错误");return a / b;
}
void Func()
{SmartPtr<int> sp1(new int);SmartPtr<int> sp2(new int);cout << div() << endl;
}int main()
{try {Func();}catch (const exception& e){cout << e.what() << endl;}return 0;
}运行结果:
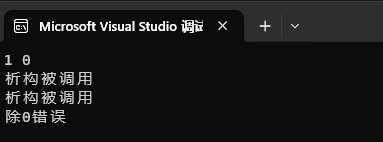
解释:和引入中说的一样,将指向申请的内存的指针封装成一个类,该类的析构函数会被自动的调用,再也不用担心异常引发的内存泄漏了!至于析构函数怎么写,就根据内存怎么申请的来写,这里若是申请的数组,则delete的时候加上[ ]即可!
但是智能指针,是能像指针一样去使用的,也就是可以* -> 等操作,所以我们还要加上*和->的重载,完整版如下:
// SmartPtr类(译为智能指针类)
template<class T>
class SmartPtr
{
public:SmartPtr(T* ptr = nullptr): _ptr(ptr){}~SmartPtr(){if (_ptr)delete _ptr;cout << "析构被调用" << endl;}T& operator*(){return *_ptr;}T* operator->(){return _ptr;}private:T* _ptr;
};
此时我们func函数变成这样,方便体现*的作用:
void Func()
{SmartPtr<int> sp1(new int(1));SmartPtr<int> sp2(new int(2));cout << "sp1值为->" << *sp1 << endl;cout << "sp2值为->" << *sp2 << endl;cout << div() << endl;}运行结果:

看过上篇博客的人都知道,有这么一种场景,连异常的重新抛出也解决不了:
void riskyOperation() {int* ptr1 = new int(100); // 内存1int* ptr2 = new int(200); // 内存2int* ptr3 = new int(300); // 内存3// 模拟后续操作抛出异常throw runtime_error("操作失败");// 正常释放(永远不会执行)delete ptr1;delete ptr2;delete ptr3;
}
我们现在有了智能指针,简直小case啦:
// SmartPtr类(译为智能指针类)
template<class T>
class SmartPtr
{
public:SmartPtr(T* ptr = nullptr): _ptr(ptr){}~SmartPtr(){if (_ptr)delete _ptr;cout << "析构被调用" << endl;}T& operator*(){return *_ptr;}T* operator->(){return _ptr;}private:T* _ptr;
};void riskyOperation() {SmartPtr<int> ptr1(new int(100)); // 内存1SmartPtr<int> ptr2(new int(200)); // 内存2SmartPtr<int> ptr3(new int(300)); // 内存3// 模拟后续操作抛出异常throw runtime_error("操作失败");// 正常释放(永远不会执行)}int main() {try {riskyOperation();}catch (const exception& e) {cerr << "捕获异常: " << e.what() << endl;// 问题:ptr1/ptr2/ptr3 内存泄漏!}
}运行结果:
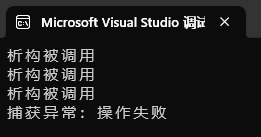 完美❀~!
完美❀~!
智能指针乍一看,很简单啊,真的如此吗,实则不然~
二:智能指针的问题
1:问题场景
先把智能指针类放这:
// SmartPtr类(译为智能指针类)
template<class T>
class SmartPtr
{
public:SmartPtr(T* ptr = nullptr): _ptr(ptr){}~SmartPtr(){if (_ptr)delete _ptr;cout << "析构被调用" << endl;}T& operator*(){return *_ptr;}T* operator->(){return _ptr;}private:T* _ptr;
};
智能指针的难点在于两个智能指针间的拷贝或赋值会出问题:
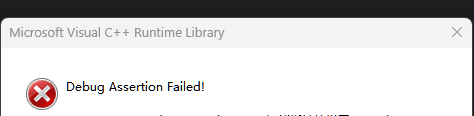
当在main中如下的时候:
int main()
{SmartPtr<int> sp1(new int);SmartPtr<int> sp2(sp1); //拷贝构造 会报错SmartPtr<int> sp3(new int);SmartPtr<int> sp4(new int);sp3 = sp4; //拷贝赋值 也会报错return 0;
}
报错:
2:拷贝赋值的问题本质
①:编译器默认生成的拷贝构造函数对内置类型完成值拷贝(浅拷贝),因此用sp1拷贝构造sp2后,相当于这sp1和sp2管理了同一块内存空间,当sp1和sp2析构时就会导致这块空间被释放两次。
②:编译器默认生成的拷贝赋值函数对内置类型也是完成值拷贝(浅拷贝),因此将sp4赋值给sp3后,相当于sp3和sp4现在管理的都是sp4管理的空间,当sp3和sp4析构时就会导致这块空间被释放两次,并且还会导致sp3原来管理的空间没人管理了,所以没有得到释放。
Q:那去手动写拷贝和赋值的深拷贝类型就能解决问题了,对吗?
A:如果这么想,那么就更错了~因为智能指针就是要模拟原生指针的行为,当我们将一个指针赋值给另一个指针时,目的就是让这两个指针指向同一块内存空间,所以这里本就应该进行浅拷贝,但单纯的浅拷贝又会导致空间被多次释放,因此根据解决智能指针拷贝问题方式的不同,从而衍生出了不同版本的智能指针。
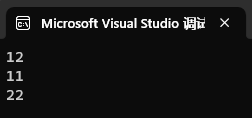
体现指针间的赋值和拷贝本身就是让两个指针指向同一块内存空间的例子:
int main()
{int a = 1;int b = 2;int* p1 = &a;int* p2 = &b;cout << *p1 << *p2 << endl;//拷贝int* p3(p1);cout << *p1 << *p3 << endl;//赋值p1 = p2;cout << *p1 << *p2 << endl;return 0;
}运行结果:
Q:那岂不是,没办法了,咱们虽然白嫖了类的析构自动调用去成功解决异常引发的内存泄漏,但是呢在拷贝和赋值的时候,却又想避开类带来的影响->类的两次析构,那怎么办呢o(╥﹏╥)o?
A:C++官方对于这个问题的解决过程中,过程是曲折的,也走过弯路~,C++的库中的常用的智能指针类我会按照产生时间(也正好是从不优秀 到 优秀)来介绍:
①:auto_ptr -> 极其大坑,大多数公司也都明确规定了禁止使用auto_ptr
②:unique_ptr -> 略有不妥
③:shared_ptr ->完美
④:weak_ptr ->某些场景,会和shared_ptr一起使用
三:智能指针的种类
1:auto_ptr
是C++98中引入的智能指针,auto_ptr通过管理权转移的方式解决智能指针的拷贝问题,保证一个资源在任何时刻都只有一个对象在对其进行管理,这时同一个资源就不会被多次释放了。比如:
int main()
{std::auto_ptr<int> ap1(new int(1));std::auto_ptr<int> ap2(ap1);*ap2 = 10;//*ap1 = 10; //errorstd::auto_ptr<int> ap3(new int(1));std::auto_ptr<int> ap4(new int(2));ap3 = ap4;//*ap4 = 10; //errorreturn 0;
}
但你解开任意一个注释的时候,就会报错:
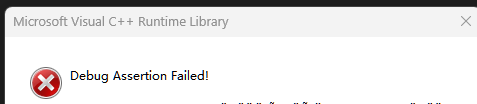
解释:被拷贝/赋值对象把资源管理权转移给拷贝/赋值对象,导致被拷贝/赋值对象悬空!
这是一个极其不好的设计,进了公司,用这个就GG,而且面试的时候,问到你了解哪种智能指针,你说你了解这个,你也GG~
2:unique_ptr
unique_ptr是C++11中引入的智能指针,unique_ptr通过防拷贝/赋值的方式解决智能指针的拷贝问题,也就是简单粗暴的防止对智能指针对象进行拷贝/赋值,这样也能保证资源不会被多次释放。比如:
int main()
{std::unique_ptr<int> up1(new int(0));//std::unique_ptr<int> up2(up1); //errorstd::unique_ptr<int> up3(new int(0));//up3 = up1; //errorreturn 0;
}解释:当你解开注释的时候,会报错尝试引用已经删除的函数!但防拷贝/赋值,其实也不是一个很好的办法,因为总有一些场景需要进行拷贝或者赋值。
3:shared_ptr
最好用最优秀的智能指针就是shared_ptr!
C++11中引入的智能指针shared_ptr,通过引用计数的方式解决智能指针的拷贝问题。
· 每一个被管理的资源都有一个对应的引用计数,通过这个引用计数记录着当前有多少个对象在管理着这块dain当新增一个对象管理这块资源时则将该资源对应的引用计数进行++,当一个对象不再
· 管理这块资源或该对象被析构时则将该资源对应的引用计数进行--。
· 当一个资源的引用计数减为0时说明已经没有对象在管理这块资源了,这时就可以将该资源进行释放了。
引用计数例子:老师晚上在下班之前都会通知,让最后走的学生记得把门锁下。所以只要不是最后一个学生离开教室,都不会锁门,直到最后一个学生离开,才会锁门
同理,只有该资源的引用计数到了0,才会释放资源,反之不会
注意:博主会说资源 也会说空间 知道是一个意思就行啦
通过这种引用计数的方式就能支持多个对象一起管理某一个资源,也就是支持了智能指针的拷贝和赋值,并且只有当一个资源对应的引用计数减为0时才会释放资源,因此保证了同一个资源不会被释放多次。比如:
须知: use_count成员函数,用于获取当前对象管理的资源对应的引用计数。
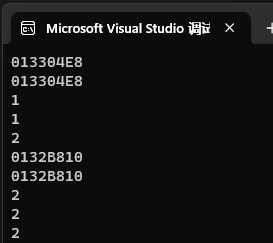
直接用库中的share_ptr ,可以进行随意的赋值拷贝!:
int main()
{shared_ptr<int> sp1(new int(1));shared_ptr<int> sp2(sp1);//体现二者的地址一致cout << sp1 << endl;cout << sp2 << endl;//内容一致cout << *sp1 << endl;cout << *sp2 << endl;//打印内存的引用计数cout << sp1.use_count() << endl; //2shared_ptr<int> sp3(new int(1));shared_ptr<int> sp4(new int(2));sp3 = sp4;//体现二者的地址一致cout << sp3 << endl;cout << sp4 << endl;//内容一致cout << *sp3 << endl;cout << *sp4 << endl;//打印内存的引用计数cout << sp3.use_count() << endl; //2return 0;
}运行结果:
用谁都会用,重点是自己模拟实现shared_ptr,智能指针面试问到,跑不了的模拟实现
①:典型错误实现shared_ptr
实现shared_ptr有一种非常经典的错误实现,理解错误在哪,会提升自己,代码:
class wtt
{
public:template<class T>class shared_ptr{public:// RAIIshared_ptr(T* ptr):_ptr(ptr){_count = 1;}// sp2(sp1)shared_ptr(const shared_ptr<T>& sp){_ptr = sp._ptr;++_count;}~shared_ptr(){if (--_count == 0){cout << "delete:" << _ptr << endl;delete _ptr;}}int use_count(){return _count;}// 像指针一样T& operator*(){return *_ptr;}T* operator->(){return _ptr;}private:T* _ptr;static int _count;};};template<class T>
int wtt::shared_ptr<T>::_count = 0; // 正确:加上 wtt::解释:
首先,先不看为什么错误,咱们先看好处
细节1:
类的静态成员必须在类外初始化,而模板类的静态成员,不仅要在类外初始化,还要带上模版
template<class T>
int shared_ptr<T>::_count = 0; // 正确:加上 wtt::细节2:
当你想不和库中的shared_ptr冲突的时候,你选择在自己实现的shared_ptr外面套一层域的时候,要记住嵌套类是外层类的 private 成员!所以此时你必须在两个类之间加上public,用来将嵌套类声明为 public:
class wtt
{
public://一定要加template<class T>class shared_ptr{//.....};};细节3:
当你采取细节2的方法的时候,内层类的静态变量的初始化是在类外,此时的类外指的是,嵌套类的类外(也就是两个类的类外),而不是两个类之间进行初始化,而且你还要在原先的基础上,再加上外层类wtt域名:
template<class T>
int wtt::shared_ptr<T>::_count = 0; // 正确:加上 wtt::
现在再来看为什么错?
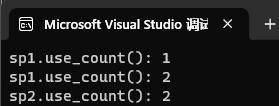
首先如果shared_ptr类只有一个对象的时候,也就是只开辟了一块空间A的时候,那么此时的对象无论是拷贝还是赋值去生成新的对象的时候,这些新生成的对象,都是指向的空间 A,所以引用计数都可以正确++,例子如下:
int main() {wtt::shared_ptr<int> sp1(new int(42));cout << "sp1.use_count(): " << sp1.use_count() << endl; // 输出 1(正确)wtt::shared_ptr<int> sp2(sp1);cout << "sp1.use_count(): " << sp1.use_count() << endl; // 输出 2(正确)cout << "sp2.use_count(): " << sp2.use_count() << endl; // 输出 2(正确)return 0;
}运行结果:
 正确!
正确!
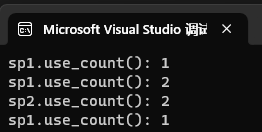
但是问题是,如果你现在通过构造创建一个新的对象的时候,那么引用计数将会出错,例子:
int main() {wtt::shared_ptr<int> sp1(new int(42));cout << "sp1.use_count(): " << sp1.use_count() << endl; // 输出 1(但实际是 1)wtt::shared_ptr<int> sp2(sp1);cout << "sp1.use_count(): " << sp1.use_count() << endl; // 输出 2(但实际是 2)cout << "sp2.use_count(): " << sp2.use_count() << endl; // 输出 2(但实际是 2)wtt::shared_ptr<int> sp3(new int(100)); // 错误:sp3 的计数会干扰 sp1/sp2cout << "sp1.use_count(): " << sp1.use_count() << endl; //应该输出 3(但是是1)return 0;
}运行结果:
 错误!
错误!
解释:这不符合我们的预期,我们的预期是sp3对象对应的空间的引用计数是1,而不是将sp1和sp2共同的空间对应的引用计数2影响到了1!!
Q:为什么会发生这种情况?
A:因为这写法就是错的, 所有对象共享 static _count,当我们sp1、sp2指向同一块空间的时候,此时还看不出错,但是当一个sp3指向新的空间的时候,此时所有对象的引用计数都会被置为1!因为我们的构造函数里面,将引用计数初始化为了1,本意是让每一块空间在第一次开辟的时候让其自己的引用计数为1,但是却变成了每次有新空间都会影响所有空间的引用计数为1
②:正确实现shared_ptr
namespace wtt
{template<class T>class shared_ptr{public://构造shared_ptr(T* ptr = nullptr):_ptr(ptr), _pcount(new int(1)){}//拷贝shared_ptr(shared_ptr<T>& sp):_ptr(sp._ptr), _pcount(sp._pcount){(*_pcount)++;}//赋值shared_ptr& operator=(shared_ptr<T>& sp){if (_ptr != sp._ptr) //管理同一块空间的对象之间无需进行赋值操作{if (--(*_pcount) == 0) //将管理的资源对应的引用计数--{cout << "delete: " << _ptr << endl;delete _ptr;delete _pcount;}_ptr = sp._ptr; //与sp对象一同管理它的资源_pcount = sp._pcount; //获取sp对象管理的资源对应的引用计数(*_pcount)++; //新增一个对象来管理该资源,引用计数++}return *this;}//析构~shared_ptr(){if (--(*_pcount) == 0){if (_ptr != nullptr){cout << "delete: " << _ptr << endl;delete _ptr;_ptr = nullptr;}delete _pcount;_pcount = nullptr;}}//获取引用计数int use_count(){ return *_pcount;}//*重载T& operator*(){ return *_ptr;}//->重载T* operator->(){ return _ptr;}private:T* _ptr; //管理的资源int* _pcount; //管理的资源对应的引用计数};
}int main() {wtt::shared_ptr<int> sp1(new int(42));cout << "sp1.use_count(): " << sp1.use_count() << endl; // 输出 1(但实际是 1)wtt::shared_ptr<int> sp2(sp1);cout << "sp1.use_count(): " << sp1.use_count() << endl; // 输出 2(但实际是 2)cout << "sp2.use_count(): " << sp2.use_count() << endl; // 输出 2(但实际是 2)wtt::shared_ptr<int> sp3(new int(100)); // 错误:sp3 的计数会干扰 sp1/sp2cout << "sp1.use_count(): " << sp1.use_count() << endl; // 输出 3(错误!)return 0;
}运行结果:
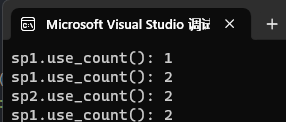 正确!每个空间的引用计数互不干扰!
正确!每个空间的引用计数互不干扰!
解释:先知道是对的就行了,下面慢慢解释
①:成员变量的改变
shared_ptr类增加一个int*变量,int*指向一个整形,该整形表示引用计数的值, 因为你只有构造的时候,就会新增一份新的引用计数,新的对象意味着新的空间,所以需要新的引用计数,而不是像错误方法:只有第一次实例化对象的时候,才会有引用计数 而每次构造的时候,不会出现新的引用计数,而是在原有的上面++
说白了,现在就变成了每个空间对应的引用计数在独立的空间之中,因为引用计数是new出来的一个整形的空间
②:构造
//构造shared_ptr(T* ptr = nullptr):_ptr(ptr), _pcount(new int(1)){}正如①所言,构造意味着新的对象,则意味着新的空间要产生了,所以需要一个新的独立的引用计数来跟随这块空间,所以每次构造进来就是给成员变量引用计数new上一个空间,初始化为1
③:拷贝函数
shared_ptr(shared_ptr<T>& sp): _ptr(sp._ptr), _pcount(sp._pcount)
{(*_pcount)++; // 引用计数 +1
}-
功能:用另一个
shared_ptr(sp)构造新对象,共享同一块内存和引用计数。 -
引用计数:递增计数器(表示多了一个
shared_ptr管理该资源)。
Q:(*_pcount)++; 对吗?不是应该加对象sp的成员变量pcount吗?
A:两种写法完全等价
在拷贝构造函数中:
-
_pcount已经被初始化为sp._pcount(通过成员初始化列表:_pcount(sp._pcount))。 -
因此,
(*_pcount)++和(*sp._pcount)++访问的是同一个内存地址,效果完全相同。
④:赋值函数
shared_ptr& operator=(shared_ptr<T>& sp) {if (_ptr != sp._ptr) { // 避免自赋值// 1. 减少原资源的引用计数if (--(*_pcount) == 0) {cout << "delete: " << _ptr << endl;delete _ptr;delete _pcount;}// 2. 共享新资源_ptr = sp._ptr;_pcount = sp._pcount;(*_pcount)++; // 引用计数 +1}return *this;
}赋值是难点,假设B要赋值A,所以A对象会指向和B相同的空间,所以A原先的空间的引用计数就需要事先被--,然后再++B指向的空间的对应的引用计数
-
功能:将当前
shared_ptr改为管理sp的资源。 -
关键步骤:
-
释放原资源:
-
减少原引用计数,若归零则释放内存和计数器。
-
-
共享新资源:
-
指向
sp的资源,并递增其引用计数。
-
-
-
自赋值检查:
if (_ptr != sp._ptr)避免无意义操作。
⑤:析构函数
~shared_ptr() {if (--(*_pcount) == 0) // 1. 引用计数减1{ if (_ptr != nullptr) // 2. 检查资源是否有效{ delete _ptr; // 3. 释放管理的资源_ptr = nullptr; // 4. 置空指针(避免悬空指针)}delete _pcount; // 5. 释放引用计数器_pcount = nullptr; // 6. 置空计数器指针}
}-
功能:递减引用计数,若归零则释放资源。
-
细节:
-
只有最后一个
shared_ptr析构时(计数为0),才会释放内存。 -
安全处理
nullptr情况。
-
if (_ptr != nullptr)-
确保
_ptr不是空指针(避免对nullptr调用delete,这是安全的编程习惯)。
至此 才是正确的实现shared_ptr!
4:weak_ptr
但是智能指针在某些场景(循环引用)下,还需要weak_ptr的使用,才能完美的应对所有的场景,所以shared_ptr也不例外
①:循环引用的定义
循环引用(Circular Reference)指 两个或多个对象通过智能指针互相持有对方的引用,导致它们的引用计数始终无法归零,从而无法释放内存。
场景:循环引用
shared_ptr的循环引用问题在一些特定的场景下才会产生。比如如下的结点类,
struct ListNode
{ListNode* _next;ListNode* _prev;int _val;~ListNode(){cout << "~ListNode()" << endl;}
};
现在以new的方式构建两个结点,并将这两个结点连接起来,在程序的最后以delete的方式释放这两个结点。比如:
int main()
{ListNode* node1 = new ListNode;ListNode* node2 = new ListNode;node1->_next = node2;node2->_prev = node1;//...delete node1;delete node2;return 0;
}
上述程序是没有问题的,两个结点都能够正确释放!
但现在我们既然学了智能指针,那肯定要给它安排上了,期望有效的防止抛异常导致的内存泄漏
我们将这两个结点分别交给两个shared_ptr对象进行管理,这时为了让连接节点时的赋值操作能够执行,就需要把ListNode类中的next和prev成员变量的类型也改为shared_ptr类型。如下:
struct ListNode
{std::shared_ptr<ListNode> _next;std::shared_ptr<ListNode> _prev;int _val;~ListNode(){cout << "~ListNode()" << endl;}
};
此时我们在main中进行:
int main()
{std::shared_ptr<ListNode> node1(new ListNode);std::shared_ptr<ListNode> node2(new ListNode);node1->_next = node2;return 0;
}运行结果:
 正确!
正确!
解释:没有引发循环引用的本质是n1 和 n2 的引用关系是单向的
Q:为什么没有触发循环引用?
A:分析如下
a:创建 n1 和 n2
-
n1的引用计数 = 1(main中的n1) -
n2的引用计数 = 1(main中的n2)
b:n1->_next = n2
-
n2的引用计数 +1 → 2(n1->_next也指向n2) -
n1的引用计数 不变(n2没有指向n1)
c: main 函数结束
-
n2析构:-
n2的引用计数 -1 → 1(n1->_next仍然持有n2)
-
-
n1析构:-
n1的引用计数 -1 → 0(n1被释放) -
n1->_next析构 →n2的引用计数 -1 → 0(n2被释放)
-
总结:
“
n1->_next = n2本质是复制n2的shared_ptr,使n2的引用计数变为 2。
当n2离开作用域时,其引用计数减为 1(因n1->_next仍持有它)。
接着n1离开作用域,引用计数减为 0,触发n1的析构。
在n1的析构过程中,其成员_next(类型为shared_ptr)也会析构,导致n2的引用计数归零,从而释放n2。由于n2从未持有n1的shared_ptr,因此没有形成循环引用。”
所以单独的node2->_prev = node1;也不会引发循环引用!
②:循环引用的场景
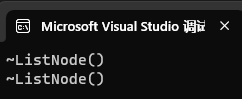
而下面这个场景则会形成引用循环:
int main()
{std::shared_ptr<ListNode> node1(new ListNode);std::shared_ptr<ListNode> node2(new ListNode);node1->_next = node2;node2->_prev = node1;return 0;
}
解释:
Q:为什么会引发循环引用?
A:分析如下
(1) 初始化阶段
-
node1的引用计数 = 1(由std::shared_ptr<ListNode> node1管理)。 -
node2的引用计数 = 1(由std::shared_ptr<ListNode> node2管理)。
(2) 建立双向链接
-
node1->_next = node2:
node2的引用计数 +1 → 2(node1->_next持有node2)。 -
node2->_prev = node1:
node1的引用计数 +1 → 2(node2->_prev持有node1)。
(3) main 函数结束时
-
node1和node2离开作用域,触发析构:-
node1的引用计数 -1 → 1(因node2->_prev仍持有node1)。 -
node2的引用计数 -1 → 1(因node1->_next仍持有node2)。
-
内存泄漏的根源
-
循环依赖:
node1和node2的成员变量_next和_prev互相持有对方的shared_ptr。 -
引用计数无法归零:
即使外部的node1和node2被销毁,它们的成员变量仍然保持对方的引用计数为1。 -
结果:
两个ListNode对象永远不会被释放(内存泄漏),它们的析构函数也不会被调用。
验证现象
-
输出结果:
运行代码后,不会输出~ListNode(),说明析构函数未被调用。
 错误!永远不会析构
错误!永远不会析构
所以此时就需要weak_ptr了!
weak_ptr是C++11中引入的智能指针,weak_ptr不是用来管理资源的释放的,它主要是用来解决shared_ptr的循环引用问题的。
weak_ptr支持用shared_ptr对象来构造weak_ptr对象,构造出来的weak_ptr对象与shared_ptr对象管理同一个资源,但不会增加这块资源对应的引用计数。
所以将ListNode中的next和prev成员的类型换成weak_ptr就不会导致循环引用问题了,此时当node1和node2生命周期结束时两个资源对应的引用计数就都会被减为0,进而释放这两个结点的资源。比如:
struct ListNode
{std::weak_ptr<ListNode> _next;std::weak_ptr<ListNode> _prev;int _val;~ListNode(){cout << "~ListNode()" << endl;}
};
int main()
{std::shared_ptr<ListNode> node1(new ListNode);std::shared_ptr<ListNode> node2(new ListNode);cout << node1.use_count() << endl;cout << node2.use_count() << endl;node1->_next = node2;node2->_prev = node1;//...cout << node1.use_count() << endl;cout << node2.use_count() << endl;return 0;
}
运行结果:
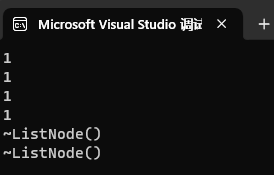
通过use_count获取这两个资源对应的引用计数就会发现,在结点连接前后这两个资源对应的引用计数就是1,根本原因就是weak_ptr不会增加管理的资源对应的引用计数。
weak_ptr的模拟实现:
namespace cl
{template<class T>class weak_ptr{public:weak_ptr():_ptr(nullptr){}weak_ptr(const shared_ptr<T>& sp):_ptr(sp.get()){}weak_ptr& operator=(const shared_ptr<T>& sp){_ptr = sp.get();return *this;}//可以像指针一样使用T& operator*(){return *_ptr;}T* operator->(){return _ptr;}private:T* _ptr; //管理的资源};
}
解释:很简单
构造和赋值均不会增加增加 shared_ptr 的引用计数(与 shared_ptr 的拷贝赋值不同)。
四:C++11和boost库中智能指针的关系
C++98中产生了第一个智能指针auto_ptr。
C++boost给出了更实用的scoped_ptr、shared_ptr和weak_ptr。
C++TR1,引入了boost中的shared_ptr等。不过注意的是TR1并不是标准版。
C++11,引入了boost中的unique_ptr、shared_ptr和weak_ptr。需要注意的是,unique_ptr对应的就是boost中的scoped_ptr,并且这些智能指针的实现原理是参考boost中实现的。
说明一下:boost库是为C++语言标准库提供扩展的一些C++程序库的总称,boost库社区建立的初衷之一就是为C++的标准化工作提供可供参考的实现,比如在送审C++标准库TR1中,就有十个boost库成为标准库的候选方案。
本文还有智能指针和线程安全的问题没讲,后面会增加在此篇博客中~❀



)







创建窗口)




)


