目录
前言
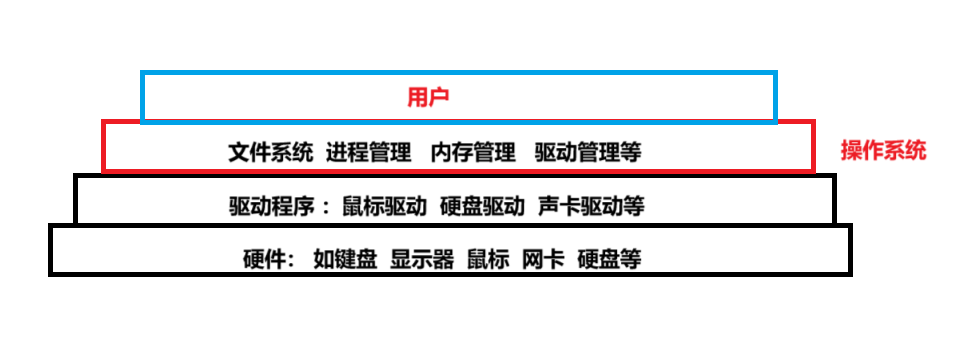
一、从硬件角度理解"Linux下一切皆文件"
从理解硬件是种“文件”到其他系统资源的抽象
二、缓冲区
1.缓冲区介绍
2.缓冲区的刷新策略
3.用户级缓冲区
这个用户级缓冲区在哪呢?
解释关于fork再加重定向“>”后数据会打印两份的原因
4.内核缓冲区简介
总结
前言
"Linux下一切皆文件",这是Linux的一个基本设置理念同时也是Linux的设计哲学所在。
这篇博客,笔者首先总结一下我自学习Linux以来,到目前自己对“Linux下一切皆文件”的感悟和理解,其次再讨论Linux中的缓冲区机制。
提示:以下是本篇文章正文内容,下面案例可供参考
一、从硬件角度理解"Linux下一切皆文件"
首先需要再次明确Linux操作系统的主要目的或者作用:
对上,方便用户使用——为用户提供稳定的、高效的、安全的使用环境。
对下,管理好计算机繁杂的软硬件资源;
其次需要明确的是文件无外乎由两部分构成:内容和属性
内容决定文件“是什么”(数据含义)。
属性决定文件的“如何用”(权限、存储、类型)。
比如一个普通文件:
他的内容是文本、二进制数据;
他的属性是文件名、权限、大小、时间戳等。
我们可以通过write、read等修改文件内容,也可以用chmod函数修改文件的权限等属性。
初识Linux:常见指令介绍,文件权限的更改,以及粘滞位的理解-CSDN博客

那么思维发散一下,我们能否将这些硬件的自身状态、操作方法抽象为“内容+属性”,并用统一的接口修改这些硬件呢?
已知的是Linux似乎正是将系统资源(如硬件设备等)抽象为文件,提供统一的文件操作接口(open, read, write, close等)。使得无论操作对象是普通文件、目录、设备,用户都可以通过相同的文件系统与之交互。
从理解硬件是种“文件”到其他系统资源的抽象
对于计算机上诸多的硬件资源,我目前认为操作系统通过:先整理,再管理的方法管理这些硬件。
所谓先整理,在管理。这是笔者从进程PCB的创建受到的启发。OS为方便管理不同的进程会为其创建PCB,其中包含着进程的所有属性信息,那管理硬件是不是也可以通过创建某种数据结构来实现管理呢?
①假设OS为方便管理各种硬件资源会为其创建某种数据结构——这里想象成某种结构体struct file,该结构体中记录着该硬件的各种属性信息和行为函数——即IO操作。
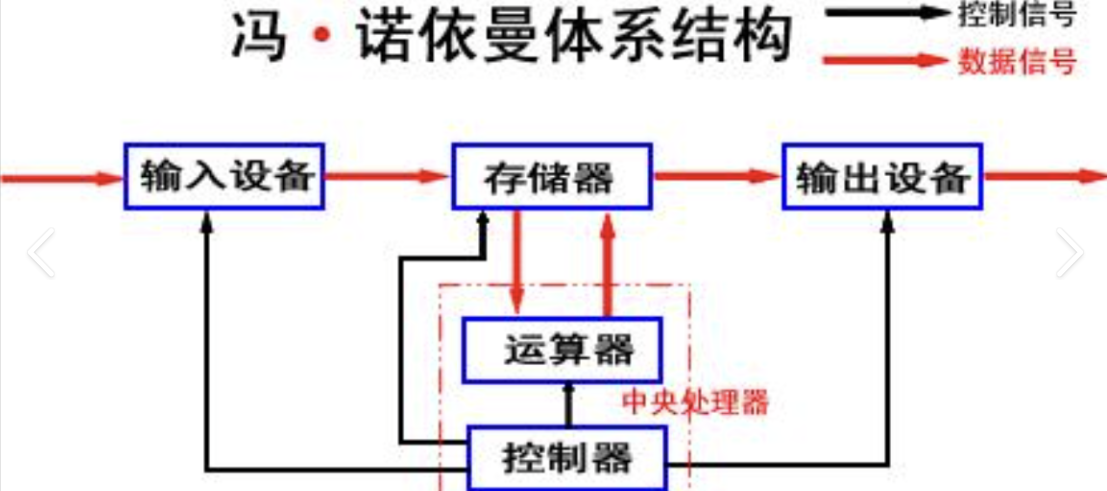
②通过对冯诺依曼体系结构的抽象,将计算机抽象为存储器和其他。这个其他中包括cpu和各种硬件设备,这么划分的原因是这些硬件都要与内存进行IO操作。我们不妨暂将所有硬件的IO操作抽象为两个函数read( )和write( )。
通过上述两点,创建一个struct file结构体,其中有着各硬件的状态信息和函数行为:
struct file
{//内容int type;int status;……//属性int (*write)();//函数指针int (*read)();……
}那么将每个硬件file实例化(与多态有些相似),再通过一个数据结构如链表将这些硬件的struct对象管理起来,如链表。
综上,当站在上层视角来看,这些硬件都是一种统一的数据,其中有着“内容+属性”,这不就是一种抽象的“文件”吗。这些个文件提供统一的文件操作接口(write、read、open、close等),无论操作对象是键盘、鼠标还是其他什么硬件,用户都可以通过相同的接口与之交互。
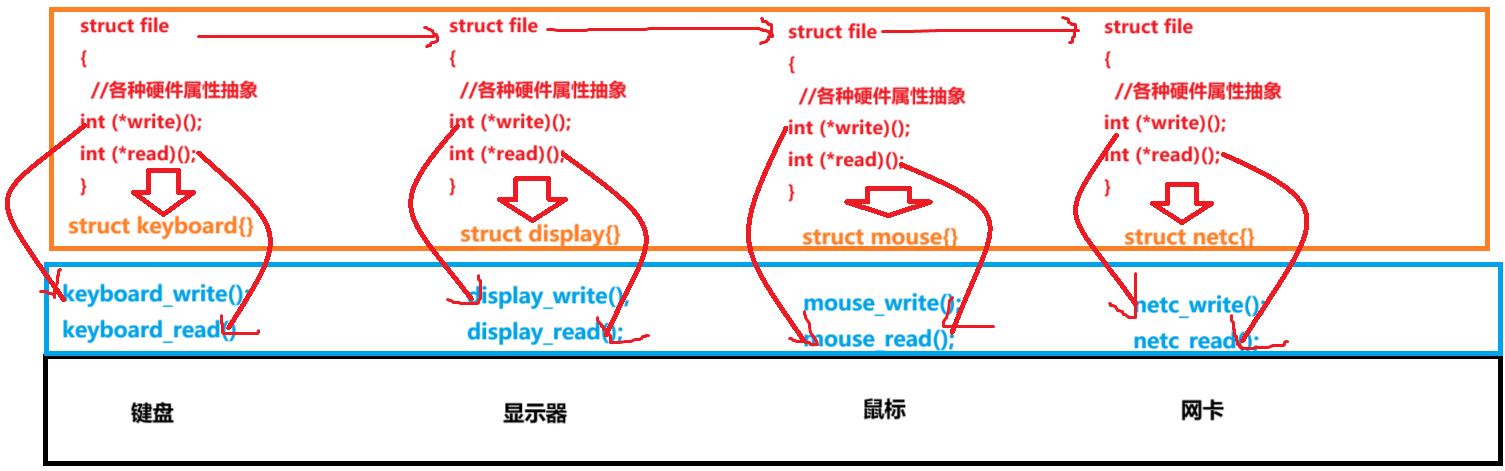
将上述思想和方法发散到其他系统资源,同样通过“先整理,再管理”的思想,这或许是理解“Linux下一切皆文件”的思路之一吧。
问:磁盘等硬件有输入输出好理解,那如显示器等硬件不是只有输入或者只有输出吗?
答:虽然如显示器等设备没有输入操作,我们只需将其struct内部的函数指针置为NULL即可。
以上是笔者目前对“Linux下一切皆文件”的理解,若笔者有错误的认识或者读者有更深的理解,还请读者不吝赐教,在评论区中一起讨论。
二、缓冲区
1.缓冲区介绍
1)什么是缓冲区
缓冲区本质上就是一段内存。
2)为什么要有缓冲区
磁盘等存储设备物理I/O效率极低,通过引入缓冲区将多次小数据操作合并为大数据操作,从而节省数据IO时间,提升性能。
2.缓冲区的刷新策略
通过以下代码观察缓冲区:
在程序sleep的十秒之间printf不会打印,等sleep结束后才会打印。
注意printf没有带\n。
1 #include<stdio.h>2 #include<unistd.h>3 int main()4 {5 printf("hello Linux");//注意没带\n6 sleep(10); 7 return 0;8 }
但在printf和sleep之间添加了fflsh(stdout)后,printf会立即打印。
下面是缓冲区的三种刷新策略。
1)立即刷新——无缓冲
2)行刷新——行缓冲
3)缓冲区满——全缓冲(效率最高)
有两种特殊情况缓冲区会立即刷新:
①用户强制刷新(如上述的fflush函数);
②程序退出——这也是为什么在某些集成开发环境下(如vs2022)程序时得等一会才能在控制台上看到打印结果。
3.用户级缓冲区
引子——观察下列代码在bash不同指令下的执行情况:
1 #include<stdio.h>2 #include<unistd.h>3 #include<string.h>4 int main()5 {6 printf("hello Linux\n");//注意没带\n7 fprintf(stdout,"hello fprintf\n");8 fputs("hello fpurs",stdout);9 const char *str="hello writie\n";10 write(stdout->_fileno,str,strlen(str));11 12 fork(); 13 return 0;14 }
执行 . / test:
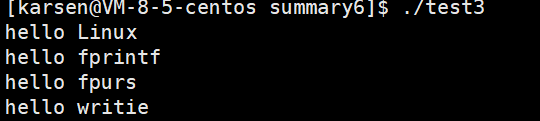
执行. / test > log.txt
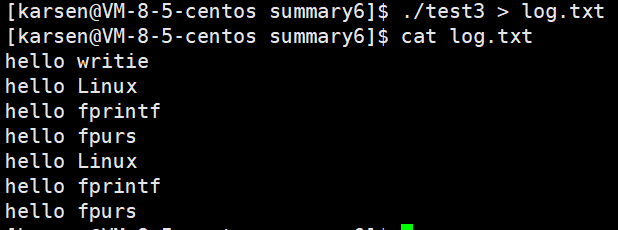
可以发现. / test > log.txt比. / test多打印了几行,这多打印的全是C标准库提供的函数。

这个用户级缓冲区在哪呢?
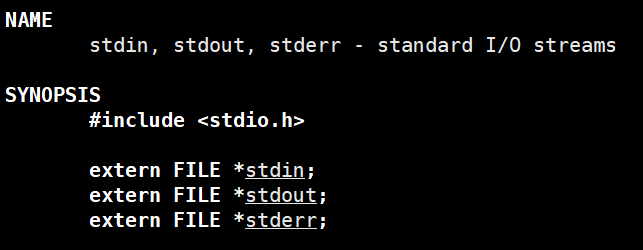
通过观察stdout的类型,我们可以推导出FILE中不仅有文件描述符,还存在缓冲区,所有当我们想要主动刷新缓冲区时,fflush传入的是FILE*指针。
解释关于fork再加重定向“>”后数据会打印两份的原因
①没有进行>时,我们看到打印了四条数据。stdout默认采用的是行刷新,在进行fork之前三条C函数已经将数据打印到显示器上了,FILE中不在存有相应数据了;
![]()
②如果我们进行了>,写入的文件不再是显示器,而是普通文件,采用的刷新策略也不再是行缓冲而是全缓冲,而这三条C打印显然不能填满缓冲区,于是数据就没有被刷新。fork函数之后紧接着就是程序退出,故当fork创建子进程后,无论父子进程谁先退出都必定会发生写时拷贝(缓冲区刷新就是修改),因此父子进程分别向log.txt中打印了数据。
至于write,他是linux系统调用,不属于C,且write用的是fd文件描述符没有使用FILE结构体,所以C提供的缓冲区中就不考虑write,因此无论那种情况write都只打印了一次。
为什么stdout标准输出默认采用行缓冲?

有关文件描述符的解释,参看:Linux中有关文件操作的系统接口,文件描述符,重定向的介绍-CSDN博客
有关fork函数和写时拷贝的解释,参看:
Linux环境下的进程创建-fork函数的使用与写时拷贝, 进程退出exit和_exit的区别,以及进程等待waitpid和status数据的提取方法-CSDN博客
4.内核缓冲区简介
1)内核缓冲区在相应文件的file_struct中。流是文件的特殊或者说流是文件的一种高级抽象。
file_struct与task_struct(PCB)一样都是内核级数据结构,在task_struct中有着指向file_struct的指针。
2)内核缓冲区的刷新策略完全由OS自主决定;
3)完整的数据刷新过程:

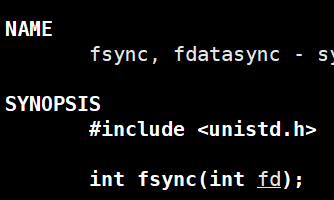
4)fsync函数:强制将内核缓冲区中的数据刷入磁盘。
总结
笔者水平浅薄,对于上述内容难免有疏忽疑错,还请读者多多指处。
希望本文对你有所帮助
读完点赞,手留余香~

:0x2ECC ML307R 的 USB Product ID (PID):0x3012)





)







和HAProxy负载均衡)

)

