
笔记整理:李晓彤,浙江大学硕士,研究方向为大语言模型
论文链接:https://arxiv.org/pdf/2406.06027
发表会议:ACL 2024
1. 动机
多跳问答(Multi-Hop Question Answering, MHQA)技术近年来在自然语言处理领域引起了广泛关注,尤其是在大规模语言模型(LLMs)用于问答任务的背景下。然而,面对复杂的多跳问题时,现有的LLMs表现不尽如人意,其主要原因在于:理解复杂问题所需的信息筛选和上下文聚合存在很大的挑战。为了缓解这一问题,研究人员尝试结合结构化知识图谱(KG)来简化信息,但这仍不足以应对复杂、多跳问题的挑战,因为这些方法通常缺乏上下文依赖性和对查询的具体化。因此,本文提出了一种超关系(Hyper-Relational)知识图谱,以更有效地辅助LLMs进行多跳问答任务。
2. 贡献
本文的主要贡献有:
(1) 引入了一种新的多跳问答方法,通过将非结构化文本转换为基于查询产生的超关系知识图谱来简化信息处理。
(2) 实验表明,该方法在多个数据集上显著提升了多跳问答的性能。具体而言,在HotpotQA数据集上提升了18.7%和20%的EM分数,而在MuSiQue数据集上提升了26%和14.3%。
(3) 相较于现有技术(SoTA)方法,利用本文的查询聚焦的超关系知识图能够减少67%的标记使用,从而提高信息效率。
3. 方法
该方法的关键思想是识别包含多跳问题答案的文档子集,随后从它们中提取上下文感知的结构化信息,进一步使用基于查询的schema来完善信息,以保留与查询相关的信息。
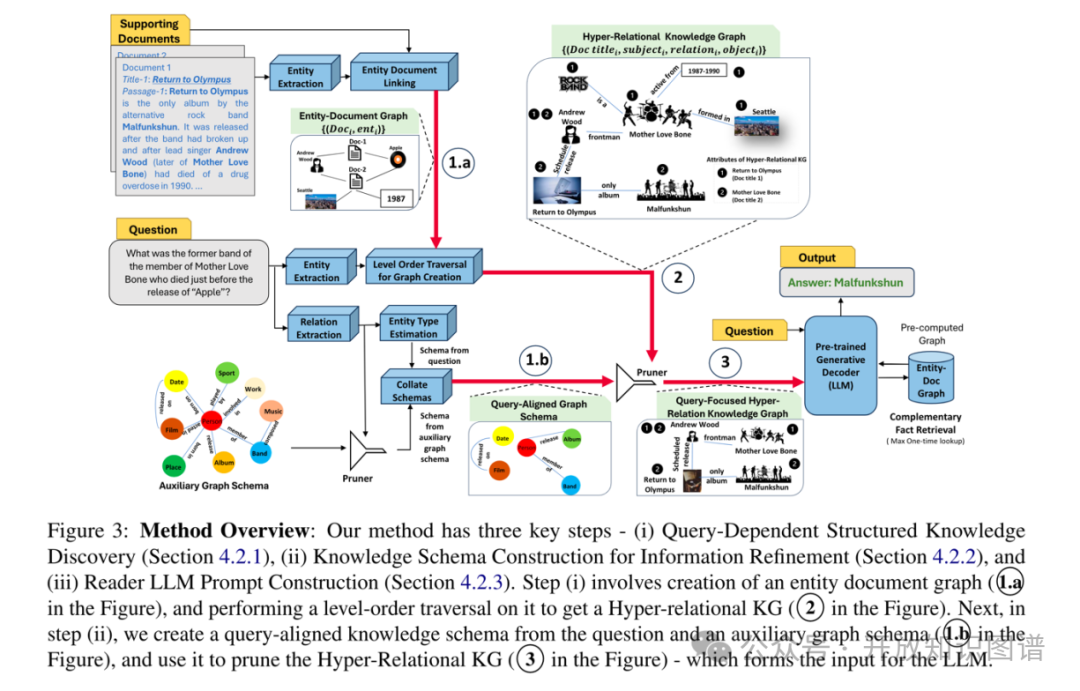
3.1 与查询相关的结构化知识发现
从支持文档中提取指定的实体。然后,在文档和实体节点之间建立边缘,形成了一个两分图,该图捕获了实体与它们出现的文档之间的连接,通过层次遍历来探索相关的潜在语义图,并利用LLMs生成知识图谱三元组,再将其转换为超关系四元组。
3.2 信息精炼的知识架构构建
为了消除超关系图中与检索无关的信息,作者构建了一个与查询对准的知识模式,图模式使用两个来源填充:通过识别推理查询中的关系得出模式元素,然后使用LLMs估算每个关系中的主题和对象实体类型;使用其他领域特定的关系丰富了知识模式,以帮助多跳的推理。然后执行改进步骤中的完善步骤。根据问题和领域内的知识构建查询对齐的知识架构,用其对超关系知识图进行裁剪,保留与查询相关的信息。
3.3 LLM的提示构建
将裁剪后的超关系图谱进行语言化处理,并根据与查询的相关性排序,形成输入提示。由于结构化信息提取是一个未解决的问题,因此在输入图中可能会遗漏一些相关的细节。为了减轻这种情况,作者还在提示构建中包含了一个验步骤。如果LLM识别输入图中缺少有关特定命名实体集的事实,则指示它列出缺失的命名实体。重新从Entity-Document图中获取相应的文档,并将它们与初始相关事实集成在一起。此过程不仅丰富了LLM的输入,而且还确保检索任何缺失的查询信息,从而提高了系统响应的准确性。
4. 实验
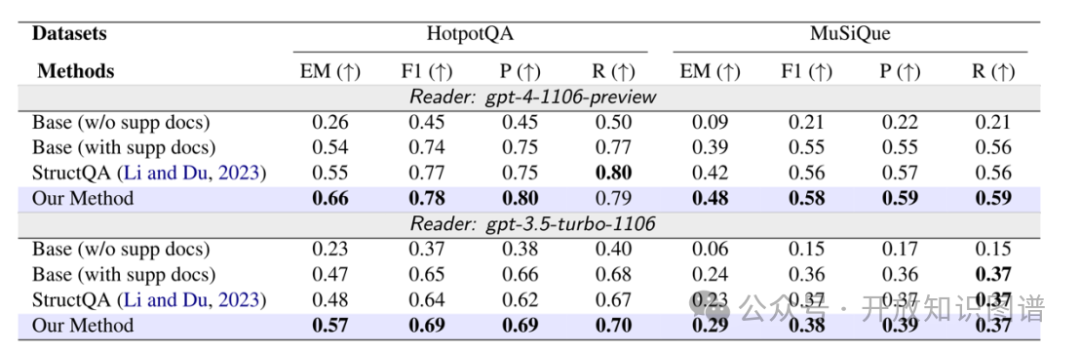
通过两个基准数据集HotpotQA和MuSiQue的验证,使用GPT-3.5、GPT-4等最先进的语言模型,证明了本文方法在多跳问答任务中的显著优越性能。在主要的评价指标(EM、F1、Precision、Recall等)上,该方法在这些数据集上均取得了优于基线方法的结果。
同时,为了衡量LLM提供答案时的信心,还引入了“自知精确匹配”(Self-Aware EM)这一新的评价指标。实验结果显示,相较于其他基线方法,HOLMES方法在自知EM分数上具有更高的表现,在多个数据集和各种LLM模型中均实现了一致的改进。

5. 总结
本文提出了一种基于超关系知识图谱的方法来提升多跳问答的效果,通过减小信息噪声、对相关事实进行精炼及利用LLMs的强大推理能力来解决复杂的自然语言问题。通过一系列实验验证,该方法成功地在具有代表性的问答数据集中实现了先进的性能。此外,几乎所有处理步骤都是零训练的,使得该系统在没有大量标注数据的情况下也能表现优异。总之,HOLMES方法为多跳问答任务提供了更为精确和高效的解决方案,标志着在该领域的一次显著进步。未来的研究方向可能会围绕增强模型的上下文理解能力及进一步减少信息处理的冗余展开。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。












——向量存储)




)

