本期分享:
1.sync.Map的原理和使用方式
2.实现有序的Map
sync.Map的原理和使用方式
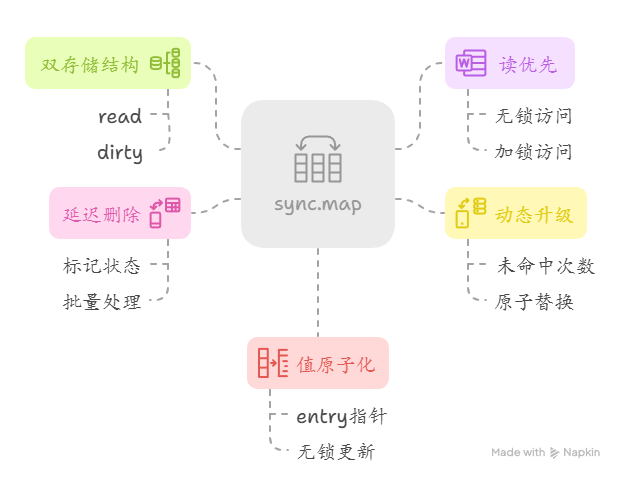
sync.Map的底层结构是通过读写分离和无锁读设计实现高并发安全:
1)双存储结构:
包含原子化的 read(只读缓存,无锁快速访问)和加锁的 dirty(写入缓冲区)
2)读优先:
读取时先尝试无锁访问 read,未命中时加锁访问 dirty 并记录未命中次数
3)动态升级:
当未命中次数超过 dirty 长度时,将 dirty 原子替换为新的 read
4)延迟删除:
删除操作仅标记数据状态(expunged),实际清理在 dirty 升级时批量处理
5)值原子化:
通过 entry 指针的原子操作实现值更新的无锁化,适用于读多写少的高并发场景。
部分源码:
type Map struct {mu sync.Mutex // 保护 dirty 操作read atomic.Value // 只读缓存(atomic 访问)dirty map[interface{}]*entry // 写入缓冲区misses int // read 未命中计数器
}type entry struct {p unsafe.Pointer // 可能的状态:nil, expunged, 有效指针
}Go 语言标准库中的 sync.map 专为以下场景优化:
- 读多写少(98% 读操作)
- 动态键空间(频繁创建/删除键)
- 需要保证并发安全
性能对比测试: 测试场景为4核CPU环境下并发读写
| 实现方式 | 100万次读/写 (ns/op) | 内存占用 (MB) |
|---|---|---|
| map+sync.RWMutex | 420 | 32 |
| sync.Map | 85 | 28 |
实现有序的map
在Go语言中,标准库的map是无序的,但可以通过组合数据结构实现有序映射。以下是几种常见实现方案,根据需求选择最适合的方式:
方案一:维护插入顺序(链表法)
package mainimport"fmt"type OrderedMap struct {items map[interface{}]interface{}order []interface{}
}func NewOrderedMap() *OrderedMap {return &OrderedMap{items: make(map[interface{}]interface{}),order: make([]interface{}, 0),}
}func (m *OrderedMap) Set(key, value interface{}) {if _, exists := m.items[key]; !exists {m.order = append(m.order, key)}m.items[key] = value
}func (m *OrderedMap) Get(key interface{}) (interface{}, bool) {val, exists := m.items[key]return val, exists
}func (m *OrderedMap) Delete(key interface{}) {delete(m.items, key)// 重建顺序切片(简单实现,实际可用更高效方式)newOrder := make([]interface{}, 0, len(m.order)-1)for _, k := range m.order {if k != key {newOrder = append(newOrder, k)}}m.order = newOrder
}func (m *OrderedMap) Iterate() {for _, key := range m.order {fmt.Printf("%v: %v\n", key, m.items[key])}
}方案二:排序映射(使用sort包)
package mainimport ("fmt""sort"
)type SortedMap struct {keys []intitems map[int]string
}func NewSortedMap() *SortedMap {return &SortedMap{keys: make([]int, 0),items: make(map[int]string),}
}func (m *SortedMap) Set(key int, value string) {if _, exists := m.items[key]; !exists {m.keys = append(m.keys, key)sort.Ints(m.keys) // 保持有序}m.items[key] = value
}func (m *SortedMap) Get(key int) (string, bool) {val, exists := m.items[key]return val, exists
}func (m *SortedMap) Iterate() {for _, key := range m.keys {fmt.Printf("%d: %s\n", key, m.items[key])}
}方案三:使用第三方库(推荐)
import "github.com/emirpasic/gods/maps/treemap"func main() {// 自然排序m := treemap.NewWithIntComparator()m.Put(1, "one")m.Put(3, "three")m.Put(2, "two")// 迭代器it := m.Iterator()for it.Next() {fmt.Printf("%d: %s\n", it.Key(), it.Value())}// 反向迭代rit := m.ReverseIterator()for rit.Next() {fmt.Printf("%d: %s\n", rit.Key(), rit.Value())}
}本篇结束~








)










