📢博客主页:https://blog.csdn.net/2301_779549673
📢博客仓库:https://gitee.com/JohnKingW/linux_test/tree/master/lesson
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 JohnKi 原创,首发于 CSDN🙉
📢未来很长,值得我们全力奔赴更美好的生活✨


文章目录
- 🏳️🌈一、InnoDB支持的数据行格式都有哪些?
- 1.1 如何查看当前数据库或表应用了哪种行格式?
- 1.2 如何指定行格式?
- 1.3 DYNAMIC 格式由哪些部分组成?
- 🏳️🌈二、数据区是怎么存储真实数据的?
- 🏳️🌈三、额外(管理)信息区包含了关于行的哪些信息?
- 🏳️🌈四、头信息区域包含了哪些信息?
- 4.1 删除一行记录时在InnoDB内部执行了哪些操作?
- 🏳️🌈五、NuIl列表有啥作用? 列表中的值是什么?
- 🏳️🌈六、变长字段列表有啥作用?列表中的值是什么?
- 6.1 如何记录变长字段的实际长度?
- 6.2 读取长度时如何处理粘包问题?
- 🏳️🌈七、其他的行格式与 DYNAMIC 有什么区别?
- 7.1 REDUNDANT 冗余格式
- 7.2 COMPRESSED 压缩格式
- 7.3 COMPACT 紧凑格式
- 👥总结
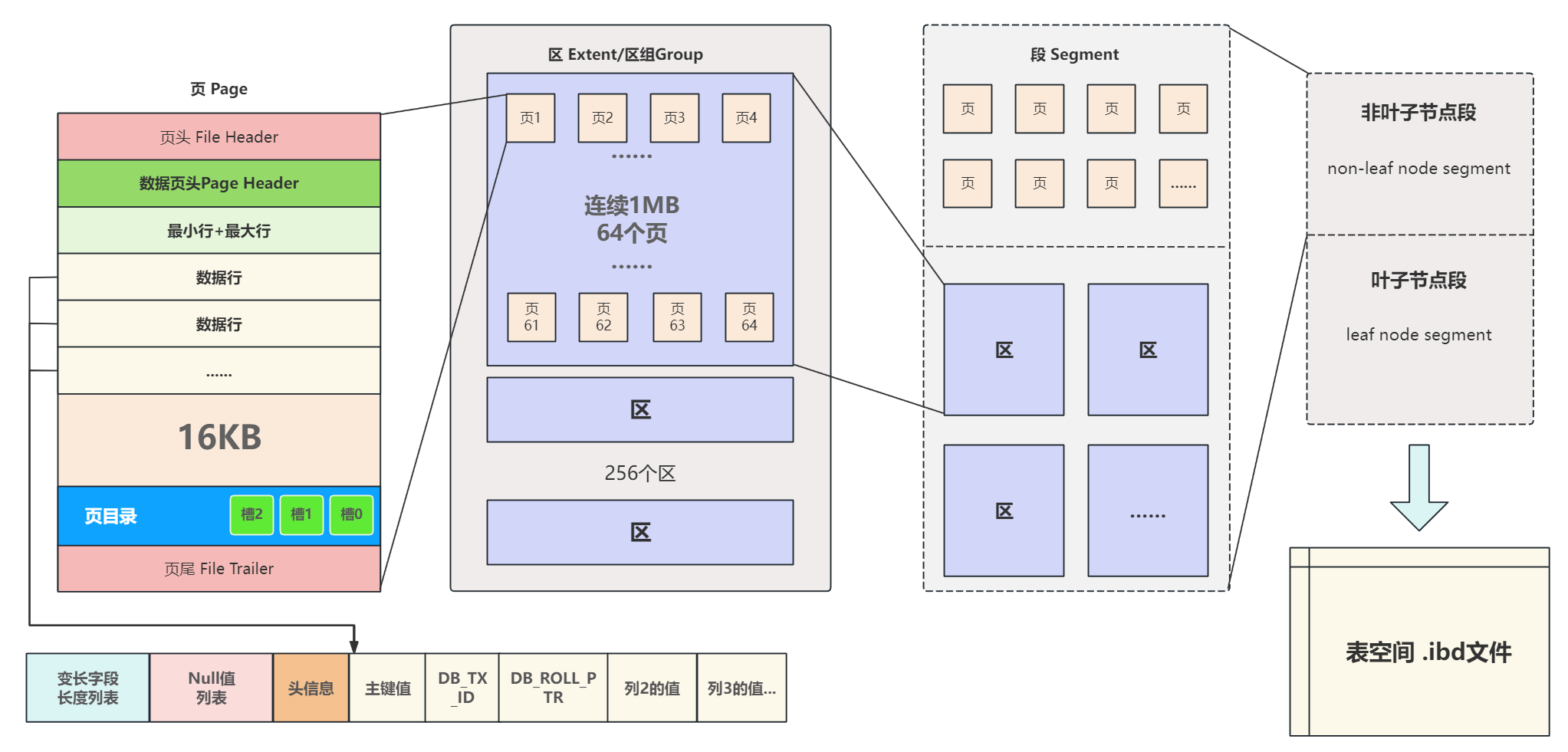
真实的数据在表空间以数据行的形式存储,也就是说每一条数据都对应着表中的一行,数据行在页中的位置如下图所示:
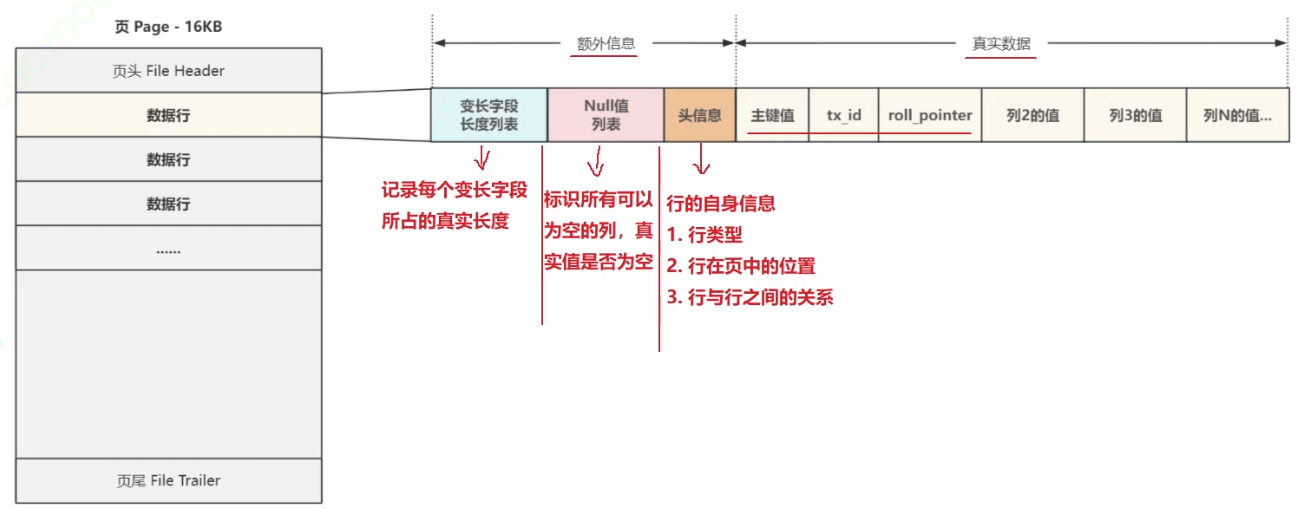
🏳️🌈一、InnoDB支持的数据行格式都有哪些?
InnoDB 支持四种行格式,分别是: REDUNDANT 冗余格式,COMPACT 紧凑格式,DYNAMIC 动态格式 和 COMPRESSED 压缩格式
默认是 DYNAMIC 格式。
1.1 如何查看当前数据库或表应用了哪种行格式?
# 查看系统变量中设置的⾏格式
mysql> SHOW VARIABLES LIKE 'innodb_default_row_format';
+---------------------------+---------+
| Variable_name | Value |
+---------------------------+---------+
| innodb_default_row_format | dynamic |
+---------------------------+---------+
1 row in set (0.00 sec)
# 使⽤SHOW table STATUS查看数据库中的所有表
mysql> SHOW TABLE STATUS IN test_db\G
*************************** 1. row ***************************Name: classesEngine: InnoDBVersion: 10Row_format: Dynamic # 指定数据库使⽤的⾏格式Rows: 3Avg_row_length: 5461Data_length: 16384
Max_data_length: 0Index_length: 0Data_free: 0Auto_increment: 4Create_time: 2025-05-02 19:14:14Update_time: NULLCheck_time: NULLCollation: utf8mb4_general_ciChecksum: NULLCreate_options: row_format=DYNAMICComment:
*************************** 2. row ***************************Name: courseEngine: InnoDBVersion: 10Row_format: DynamicRows: 6Avg_row_length: 2730Data_length: 16384
Max_data_length: 0Index_length: 0Data_free: 0Auto_increment: 7Create_time: 2025-05-02 19:14:14Update_time: NULLCheck_time: NULLCollation: utf8mb4_general_ciChecksum: NULLCreate_options: row_format=DYNAMICComment:
*************************** 3. row ***************************Name: scoreEngine: InnoDBVersion: 10Row_format: DynamicRows: 15Avg_row_length: 1092Data_length: 16384
Max_data_length: 0Index_length: 0Data_free: 0Auto_increment: NULLCreate_time: 2025-05-02 19:14:14Update_time: NULLCheck_time: NULLCollation: utf8mb4_general_ciChecksum: NULLCreate_options: row_format=DYNAMICComment:
# ... 省略
16 rows in set (0.06 sec)
1.2 如何指定行格式?
- 可以通过
全局变量设置行格式 - 也可以在创建表中通过
ROW_FORMAT子句指定行格式:
# 通过全局变量设置
SET GLOBAL innodb_default_row_format=DYNAMIC;# 在创建表时明确的指定⾏格式
CREATE TABLE t1 (c1 INT) ROW_FORMAT=DYNAMIC;
1.3 DYNAMIC 格式由哪些部分组成?
一个 DYNAMIC 格式的数据行会被分为两部分
- 一部分是存储
真实数据的区域 - 一部分是存储
额外信息的区域
在页结构的小节已经对行做了简单介绍,下面来详细讲解一下行的组成结构
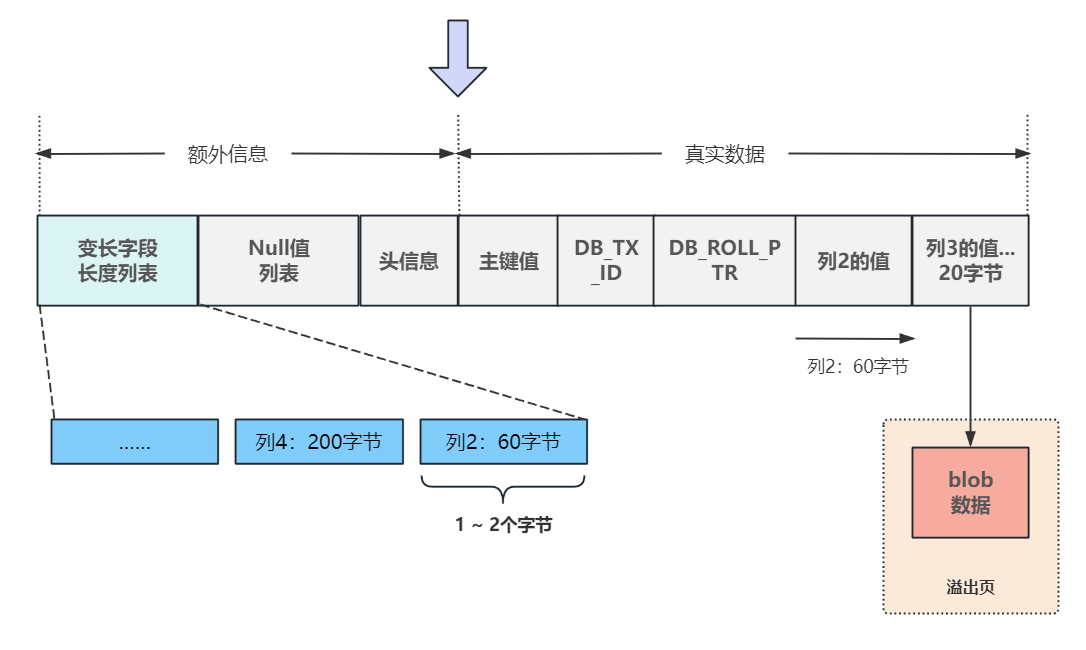
🏳️🌈二、数据区是怎么存储真实数据的?
数据区在数据行中的位置如下图所示:

从分隔线向右第一个字段存储真实数据的主键值,对于 主键值 有以下几种情况:
- 如果表中定义了
主键,则直接存储主键的值;。 - 如果是
复合主键会根据列定义的顺序依次排列在这里; - 如果
没有主键,会优先使用第一个不允许为 NULL 的 UNIQUE 唯一列作为主键; - 如果
既没有主键也没有唯一键,那么InnoDB会构建一个6字节的字段DB_ROW_ID作为行的唯一标识,存储在真实数据的头部
紧接着是在事务运行中两个非常重要的固定字段
- 6字节的事务ID字段
DB_TXID,记录创建或最后一次修改该记录的事务ID - 7字节的回滚指针字段
DB_ROLL_PTR,如果在事务中这条记录被修改,指向这条记录的上一个版本
接下来就是除了 主键 和 值为NULL 的列之外,其他列的真实数据,按照顺序从左到右依次排列
至于为什么不存储NULL值,原因很简单,就是为了节少空间,所有允许为NULL的列都会在行额外信息区的NULL值列表中进行标识 ,后面我们会详细详解,以上就是数据行对真实数据的存储方式。
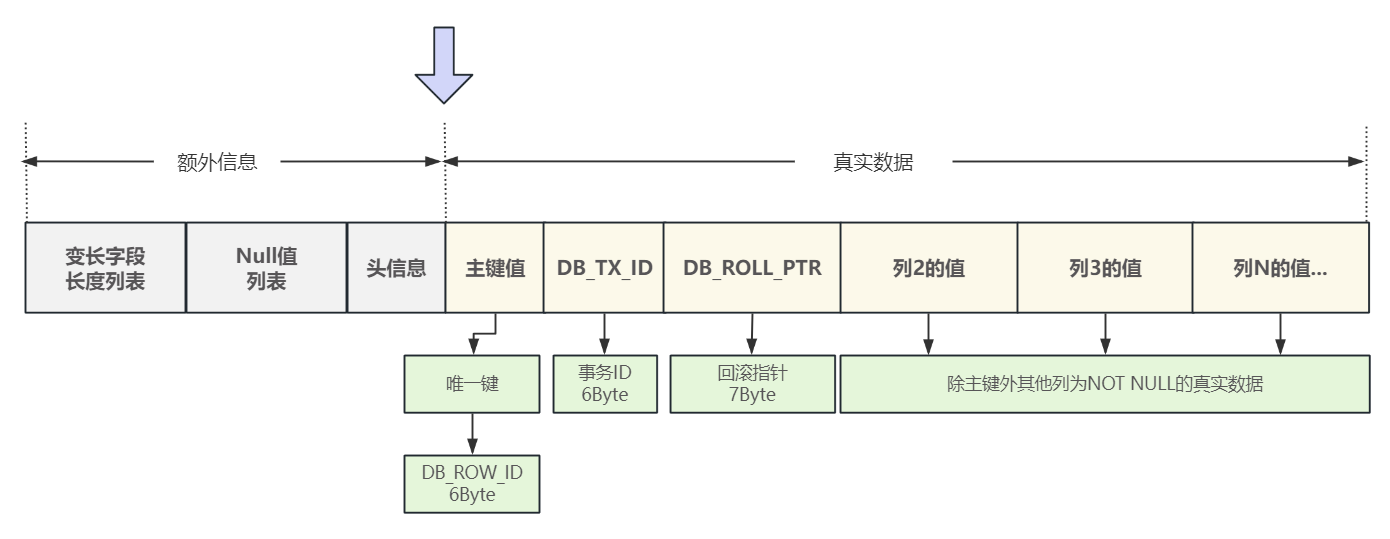
🏳️🌈三、额外(管理)信息区包含了关于行的哪些信息?

额外信息区从右向左分别为: 头信息,NuI值列表,变长字段列表。
🏳️🌈四、头信息区域包含了哪些信息?
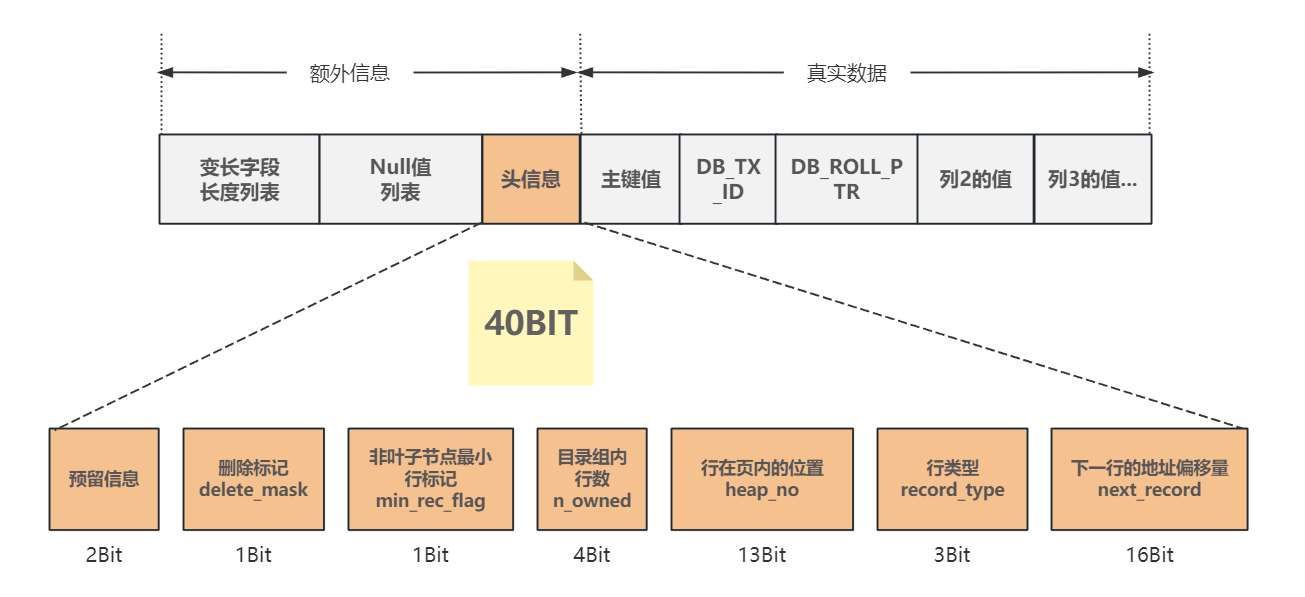
- 下一行地址偏移量:
next_record占16bit,通过这个信息将所有的行链接成一个单向链表 - 行类型:
record_type占3bit,包括四种类型:- 0: 普通数据行
- 1: 索引目录行
- 2: 页内最小行
infimun - 3: 页内最大行
supremun
- 行在整个页中的位置:
heap_no占13bit; - 分组的行数:
n_owned占4bit,只在该行是分组最后一行才有值,这样就可以快速查询行数,而不用一条条的累加了 - B+树索引树每层最小值标记:
min_rec_flag占lbit,如果当前行的类型是目录行也就是record_type=1,同时也是B+索引树某层的最小值,则会置为1,会在索引查询时用到,后面我们讲索引时再介绍 - 删除标记:
delete_mask占1bit,从页中删除数据行时,并不会直接移除,而是修改这个删除标记为 - 预留区: 占2bit
4.1 删除一行记录时在InnoDB内部执行了哪些操作?
从页中删除数据行时,并不会直接移除,而是修改 delete_mask 这个删除标记为1,并将 next_record 改为0,同时将 上一行的 next_record 指向后续的行,从而把该行从链表中断开
如果执行事务提交后,则将这行的 next_record 指向一个被称为垃圾链表的区域,这个链表会被用在事务回滚中,后续在事务中详细介绍
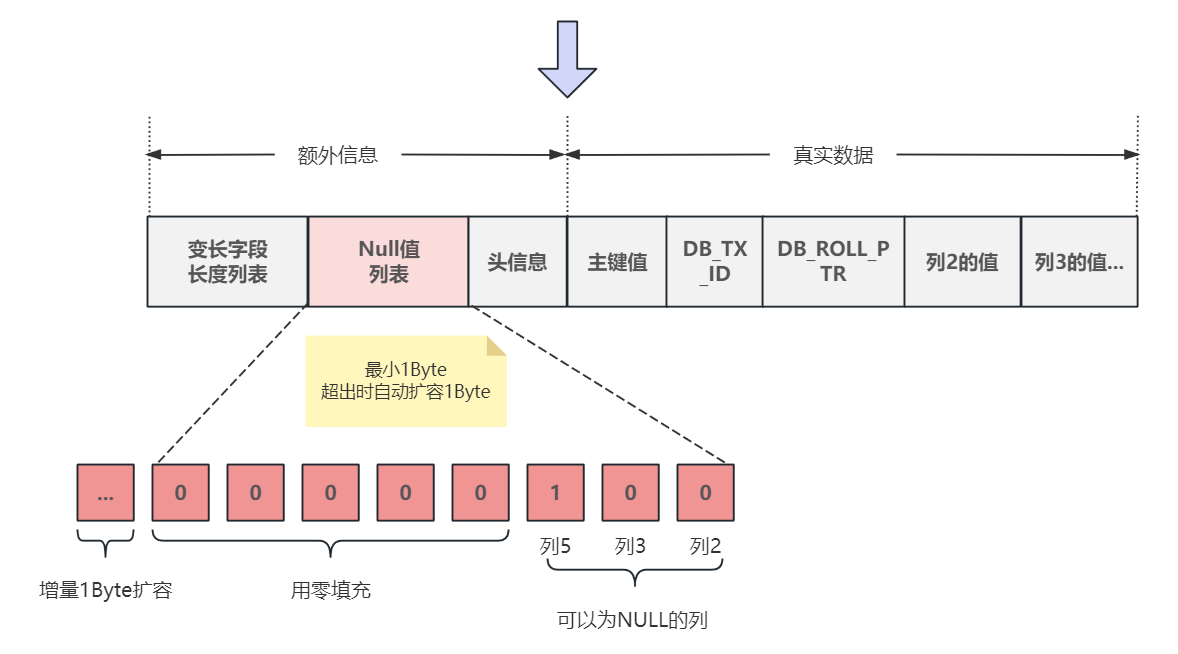
🏳️🌈五、NuIl列表有啥作用? 列表中的值是什么?
- 头信息区再向右就是
NULL值列表的可变区域,用来存储数据行中所有列允许为Null的值从而节省空间,具体的实现方式是,用1BIT的大小来表示行中某一列是否为空,这样空列就不需要记录在真实数据区域中了 - 为每个没有定义
NOT NULL约束也就是可以为NULL的列在NULL值列表中都安排了一个bit位,按列序号从小到大的顺序从右至左依序安排,这就是常说的逆序排列,NULL值列表最小1字节即8bit,如果没有那么多可以为NULL的列,则会用0补满8bit,如果为值为NULL的列超过8个,则新开辟1字节的空间,依此类推: - 如果某列为空,则NULL值列表中对应的bit设置为1,这样只用了一bit就存储了NULL列,非常节省空间
🏳️🌈六、变长字段列表有啥作用?列表中的值是什么?
查看编码集所占的字节数
mysql> show charset;
+----------+---------------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+---------------------------------+---------------------+--------+
| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 |
| ascii | US ASCII | ascii_general_ci | 1 |
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| binary | Binary pseudo charset | binary | 1 |
| cp1250 | Windows Central European | cp1250_general_ci | 1 |
| cp1251 | Windows Cyrillic | cp1251_general_ci | 1 |
| cp1256 | Windows Arabic | cp1256_general_ci | 1 |
| cp1257 | Windows Baltic | cp1257_general_ci | 1 |
| cp850 | DOS West European | cp850_general_ci | 1 |
| cp852 | DOS Central European | cp852_general_ci | 1 |
| cp866 | DOS Russian | cp866_general_ci | 1 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
| euckr | EUC-KR Korean | euckr_korean_ci | 2 |
| gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
| geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 |
| greek | ISO 8859-7 Greek | greek_general_ci | 1 |
| hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 |
| hp8 | HP West European | hp8_english_ci | 1 |
| keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
| koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
| macce | Mac Central European | macce_general_ci | 1 |
| macroman | Mac West European | macroman_general_ci | 1 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
| tis620 | TIS620 Thai | tis620_thai_ci | 1 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
| utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 |
| utf32 | UTF-32 Unicode | utf32_general_ci | 4 |
| utf8mb3 | UTF-8 Unicode | utf8mb3_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |
+----------+---------------------------------+---------------------+--------+
41 rows in set (0.00 sec)

以下是⼀个建表的SQL语句
mysql> CREATE TABLE test_student (-> `id` bigint NOT NULL AUTO_INCREMENT,-> `sn` char(10) NOT NULL,-> `name` varchar(50) NOT NULL,-> `age` int NOT NULL,-> `mail` varchar(100) NOT NULL,-> `remark` varchar(255) NULL,-> PRIMARY KEY (`id`)-> );
Query OK, 0 rows affected (0.09 sec)
- 行结构的最左侧是变长字段列表,也叫可变字段长度列表,在这个列表中记录了数据行中所有变长字段的实际长度,这样做的目的,是为了在真实数据区域,可以根据列的长度进行列与列之间的分割;
- 需要记录的变长字段类型常见的有varchar、varbinary、text、blob,以及当使用了例如utf-8、gbk等变长字符集的char类型,当char类型的字节数可能超过768个字节时,比如使用utf8mb4字符集时定义了char(255),这个字段的最大字节数是4*255=1020
- 每个变长字段分配1~2个字节来存放这些字段的真实大小,放置顺序也是按表中字段的顺序从右至左逆序排列;
mysql> CREATE TABLE test_varchar (-> `id` bigint NOT NULL AUTO_INCREMENT,-> `name` varchar(20000) NULL,-> PRIMARY KEY (`id`)-> );
ERROR 1074 (42000): Column length too big for column 'name' (max = 16383); use BLOB or TEXT instead
- 2个字节最大可以表示65535个字节,按照最大长度字符串,比如 utf8mb4,一个字符占用最多4个字节计算,2个字节最多可以表示65535/4=16383个字符,列数据类型varchar的长度上限16383就是根据这个计算来的;
- 需要特别说明的是,如果text、blob存储的内容过大,一个页已经不够放了,就会把这个列放入一个叫"溢出页"的独立空间中,在这个数据行对应的真实数据处,只使用20个字节来标记这个溢出页的位置信息
6.1 如何记录变长字段的实际长度?
不同的字符集在处理字符对应的最大字节长度不同,以如 ascii 最大1个字节, utf8mb3 最大3个字节,utf8mb4 最大4个字节,如下所示
| ascii | US ASCII | ascii_general_ci | 1 |
| utf8mb3 | UTF-8 Unicode | utf8mb3_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |
当使用 varchar(M ) 指定一个字段的最大字符数时,该字段真实使用的字节数与建表时指定的字符集有关,如果指定的字符集单个字符最大占 w个字节,从理论上讲,该列最多使用的字节数 M *如果 M *W<= 255 则用一个字节记录这个变长字段的长度就足够了
如果 M *W> 255 可能分为两种情况,假设当前变长字段实现占用了L个字节:
6.2 读取长度时如何处理粘包问题?
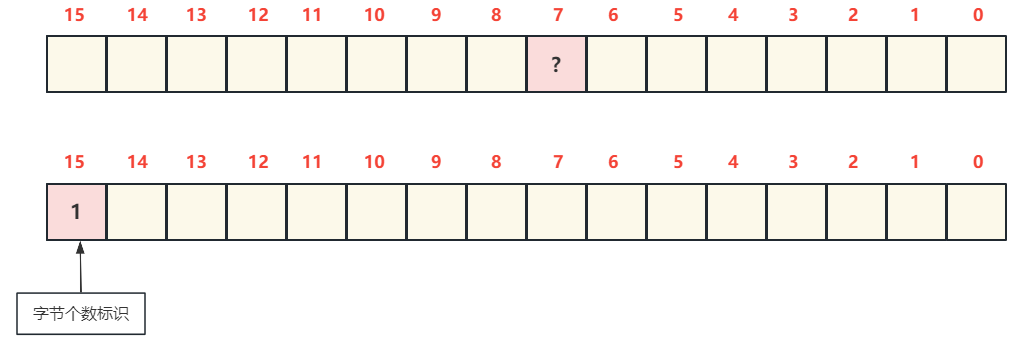
- 也就是说在读取变长字段长度时,如何确定读取一个字节还是两个字节?
- 在任何时候都是先读一个字节,然后判断这个字节的高位是否为0,如果是0则表示当前用一个字节表示长度,如果是1则表示当前用两个字节表示长度
- 为1时再读一个字节,然后合并在一起进行解析得到该字段真实的使用的字节数,而且第二个BIT位表示是否使用溢出页
默认数据页大小为16KB,数据页中一个数据行的大小最大为8KB
🏳️🌈七、其他的行格式与 DYNAMIC 有什么区别?
7.1 REDUNDANT 冗余格式
已被淘汰,之所以存在是为了与旧版本 MySQL兼容,不建议使用,这里不再讨论。
7.2 COMPRESSED 压缩格式
行结构与 DYNAMIC 完全相同,只是会对数据进行压缩,以减少对空间的占用。
7.3 COMPACT 紧凑格式
在结构上与 DYNAMIC 相同,只是对超长字段的处理上有些区别,它不会把所有超长数据都放在溢出页中,而是会在本行中保留前768个字节的数据,多出的部分放在溢出页中,溢出页的地址额外用20个字节表示,那么在本行的列中就会占用768+20个字节。
👥总结
本篇博文对 【MySQL】行结构详解:InnoDb支持格式、如何存储、头信息区域、Null列表、变长字段以及与其他格式的对比 做了一个较为详细的介绍,不知道对你有没有帮助呢
觉得博主写得还不错的三连支持下吧!会继续努力的~







)











