第30章 标准库概观(Standard-Library Overview)
目录
30.1 引言
30.1.1 标准库设施
30.1.2 设计约束
30.1.3 描述风格
30.2 头文件
30.3 语言支持
30.3.1 对initializer_list的支持
30.3.2 对范围for的支持
30.4 异常处理
30.4.1 异常
30.4.1.1 标准 exception的层级结构
30.4.1.2 异常的传递(Exception Propagation)
30.4.1.3 terminate() 函数
30.4.2 断言(Assertions)
30.4.3 system_error
30.4.3.1 错误代码
30.4.3.2 错误分类
30.4.3.3 异常 system_error
30.4.3.4 异常潜在的可移植错误条件(Potentially Portable Error Conditions)
30.4.3.5 映射错误代码(Mapping Error Codes)
30.4.3.6 errc错误代码
30.4.3.7 future_errc错误代码
30.4.3.8 io_errc错误代码
30.5 建议
30.1 引言
标准库是 ISO C++ 标准指定的组件集,每个 C++ 实现都具有相同的行为(模数性能)。为了实现可移植性和长期可维护性,我强烈建议尽可能使用标准库。也许你可以为你的应用程序设计和实现更好的替代方案,但是:
• 未来的维护者学习该替代设计有多容易?
• 十年后,该替代方案在未知平台上可用的可能性有多大?
• 该替代方案对未来应用程序有用的可能性有多大?
• 你的替代方案与使用标准库编写的代码互操作的可能性有多大?
• 你花费与标准库一样多的精力来优化和测试你的替代方案的可能性有多大?
当然,如果你使用了替代方案,你(或你的组织)将“永远”负责该替代方案的维护和发展。总的来说:尽量不要重新发明轮子。
标准库相当大:ISO C++标准中的标准库有785页。这还没有描述ISO C标准库,它是C++标准库的一部分(另外139页)。相比之下,C++语言规范有398页。在这里,我总结了一下,主要依靠表格,并给出了几个例子。详细信息可以在其他地方找到,包括标准的在线副本、完整的在线实现文档,以及(如果你喜欢阅读代码)开源实现。完整的详细信息请参阅对标准的引用。
标准库章节不宜按其呈现顺序阅读。每个章节和每个主要小节通常都可以单独阅读。如果遇到不明之处,请依靠交叉引用和索引。
30.1.1 标准库设施
标准 C++ 库中应该包含什么?一种理想情况是,程序员能够在库中找到每个有趣、重要且相当通用的类、函数、模板等。然而,这里的问题不是“某个库中应该包含什么?”而是“标准库中应该包含什么?”“一切!”是对前一个问题的合理初步近似回答,但不是后一个问题。标准库是每个实现者都必须提供的东西,以便每个程序员都可以依赖它。
C++ 标准库提供:
• 支持语言功能,例如内存管理(§11.2)、范围for 语句
(§9.5.1)和运行时类型信息(§22.2)
• 有关语言实现定义方面的信息,例如最大有限浮点值(§40.2)
• 语言本身无法轻松或高效实现的原操作,例如 is_polymorphic、is_scalar 和 is_nothrow_constructible(§35.4.1)
• 底层(“无锁”)并发编程设施(§41.3)
• 支持基于线程的并发(§5.3,§42.2)
• 对基于任务的并发的最低限度支持,例如 Future 和 async()(§42.4)
• 大多数程序员无法轻松实现最佳和可移植的函数,例如 uninitialized_fill()(§32.5)和 memmove()(§43.5)
•对未使用内存回收(垃圾收集)的最低限度支持(可选),例如 declare_reachable()(§34.5)
• 程序员可以依赖的非原基础设施,以实现可移植性,例如list(§31.4)、map(§31.4.3)、sort()(§32.6)和 I/O 流(第 38 章)
• 用于扩展其提供的设施的框架,例如约定和支持设施允许用户以内置类型的 I/O(第 38 章)和 STL(第 31 章)的样式提供用户定义类型的 I/O 。
标准库提供的一些功能仅仅是因为这样做很常规而且有用。例如标准数学函数,如 sqrt() (§40.3)、随机数生成器 (§40.7)、complex算术 (§40.4) 和正则表达式 (第 37 章)。
标准库旨在成为其他库的共同基础。具体来说,其功能的组合使标准库能够发挥三种支持作用:
• 可移植性的基础
• 一组紧凑而高效的组件,可用作性能敏感型库和应用程序的基础
• 一组支持库内通信的组件
库的设计主要由这三个角色决定。这些角色密切相关。例如,可移植性通常是专用库的重要设计标准,而list和map等常见容器类型对于单独开发的库之间的便捷通信至关重要。
从设计角度来看,最后一个角色尤其重要,因为它有助于限制标准库的范围并限制其功能。例如,标准库中提供了字符串和列表功能。如果没有,单独开发的库只能通过使用内置类型进行通信。但是,没有提供高级线性代数和图形功能。这些功能显然用途广泛,但它们很少直接参与单独开发的库之间的通信。
除非需要某种工具来支持这些角色,否则可以将其留给标准之外的某个库。无论好坏,将某些东西排除在标准库之外都会为不同的库提供机会,让它们提供想法的竞争性实现。一旦某个库证明自己在各种计算环境和应用领域中广泛有用,它就会成为标准库的候选。正则表达式库(第 37 章)就是一个例子。
精简的标准库可用于独立实现,即在最少或没有操作系统支持的情况下运行的实现(§6.1.1)。
30.1.2 设计约束
标准库的角色对其设计施加了一些约束。C++ 标准库提供的功能旨在:
• 对几乎每一位学生和专业程序员(包括其他库的构建者)来说都是有价值且负担得起的。
• 每位程序员都可以直接或间接地使用该库范围内的所有内容。
• 足够高效,可以在进一步实现库时提供手工编码函数、类和模板的真正替代方案。
• 要么不包含策略,要么可以选择将策略作为参数提供。
• 从数学意义上讲是原始的。也就是说,与设计为仅执行单一角色的单个组件相比,服务于两个弱相关角色的组件几乎肯定会承受开销。
• 对于常见用途来说,方便、高效且相当安全。
• 功能齐全。标准库可能会将主要功能留给其他库,但如果它承担一项任务,它必须提供足够的功能,以便单个用户或实施者无需替换它即可完成基本工作。
• 易于使用,具有内置类型和操作。
• 默认情况下类型安全,因此原则上可以在运行时检查。
• 支持普遍接受的编程风格。
• 可扩展以处理用户定义类型,处理方式类似于处理内置类型和标准库类型。
例如,将比较标准构建到排序函数中是不可接受的,因为相同的数据可以根据不同的标准进行排序。这就是为什么 C 标准库 qsort() 将比较函数作为参数,而不是依赖于某些固定的东西,例如 < 运算符(§12.5)。另一方面,每次比较的函数调用所带来的开销损害了qsort() 作为进一步构建库的构建块。对于几乎所有数据类型,都很容易进行比较,而无需施加函数调用的开销。
这种开销严重吗?在大多数情况下,可能不是。但是,函数调用开销可能会占据某些算法的执行时间,并导致用户寻求替代方案。§25.2.3 中描述的通过模板参数提供比较标准的技术解决了 sort() 和许多其他标准库算法的这个问题。sort 示例说明了效率和通用性之间的矛盾。它也是解决这种矛盾的一个例子。标准库不仅需要执行其任务。它还必须如此高效地执行这些任务,以至于用户不会倾向于提供标准提供的替代方案。否则,更高级功能的实现者将被迫绕过标准库以保持竞争力。这会给库开发人员增加负担,并严重复杂化希望保持平台独立性或使用多个单独开发的库的用户的生活。
“原始性(primitiveness)”和“常见用途的便利性”的要求可能会发生冲突。前者要求不允许专门针对常见情况优化标准库。但是,除了原设施之外,标准库中还可以包含满足常见但非原需求的组件,而不是作为替代品。正交性狂热者不应妨碍我们为新手和普通用户提供便利。它也不应导致我们让组件的默认行为变得模糊或危险。
30.1.3 描述风格
即使是一个简单的标准库操作(例如构造函数或算法)的完整描述也可能需要几页纸。因此,我使用了一种极其简洁的演示风格。相关操作集通常以表格形式呈现:
| 某些操作 | |
| p=op(b,e,x) | op对范围 [b,e)和x做某事,返回给p |
| foo(x) | foo对x做某事,但不返回结果 |
| bar(b,e,x) | x 和 [b,e) 有关系吗? |
在选择标识符时,我尽量做到易记,因此 b 和 e 将是指定范围的迭代器,p 是指针或迭代器,x 是某个值,具体含义取决于上下文。在这种表示法中,只有注释无法区分结果和布尔值结果,所以如果你用力过猛,很容易混淆它们。对于返回布尔值的操作,解释通常以问号结尾。如果算法遵循通常的模式,返回输入序列的结尾来指示“失败”、“未找到”等(§4.5.1,§33.1.1),我就不会明确提及这一点。
通常,这种简短的描述会附带 ISO C++ 标准的参考、一些进一步的解释和示例。
30.2 头文件
标准库的功能定义在 std 命名空间中,并以一组头文件的形式呈现。这些头文件标识了库的主要部分。因此,列出这些头文件可以概览库的构成。
本小节的其余部分是按功能分组的头文件列表,并附有简短说明,并附有讨论这些头文件的参考文献。分组方式的选择与标准的组织结构相符。
名称以字母 c 开头的标准头文件相当于 C 标准库中的头文件。对于全局命名空间和命名空间 std 中每一个定义 C 标准库部分的头文件 <X.h>(译注:即在C中定义的标准库头文件,在C++环境中加前缀c),都有一个定义相同名称的头文件 <cX>。理想情况下,<cX> 头文件中的名称不会污染全局命名空间(§15.2.4),但遗憾的是(由于维护多语言、多操作系统环境的复杂性),大多数头文件都会污染全局命名空间。
| 容器 | ||
| <vector> | 一维伸缩数组 | §31.4.2 |
| <deque> | 双端队列 | §31.4.2 |
| <forward_list> | 单向链表 | §31.4.2 |
| <list> | 双向链表 | §31.4.2 |
| <map> | 关联数组 | §31.4.3 |
| <set> | 集合 | §31.4.3 |
| <unordered_map> | 哈希关联数组 | §31.4.3.2 |
| <unordered_set> | 哈希集合 | §31.4.3.2 |
| <queue> | 队列 | §31.5.2 |
| <stanck> | 栈 | §31.5.1 |
| <array> | 一维定长数组 | §34.2.1 |
| <bitset>(位集) | bool数组 | §34.2.2 |
关联容器 multimap 和 multiset 分别在 <map> 和 <set> 中声明。priority_queue (§31.5.3) 在 <queue> 中声明。
| 通用工具 | ||
| <utility> | 运算符和对(pairs) | §35.5, §34.2.4.1 |
| <tuple> | 三元组 | §34.2.4.2 |
| <type_traits> | 类型trait | §35.4.1 |
| <typeindex> | 使用一个 type_info 作为key或哈希 code | §35.5.4 |
| <functional> | 函数对象 | §33.4 |
| <memory> | 资源管理指针 | §33.3 |
| <scoped_allocator> | 作用域分配器 | §34.4.4 |
| <ratio> | 编译时比率(有理)运算 | §35.3 |
| <chrono> | 时间工具 | §33.2 |
| <ctime> | C风格时期和时间 | §43.6 |
| <iterator> | 迭代器和迭代器支持 | §33.1 |
迭代器提供了使标准算法通用的机制(§3.4.2,§33.1.4)。
| 算法 | ||
| <algorithm> | 通用算法 | §32.2 |
| <cstdlib> | bsearch(), qsort() | §43.7 |
典型的通用算法可以应用于任意元素类型的任意序列(§3.4.2,§32.2)。C 标准库函数 bsearch() 和 qsort() 仅适用于元素类型不包含用户定义复制构造函数和析构函数的内置数组(§12.5)。
| 算法 | ||
| <exception> | 异常类 | §30.4.1.1 |
| <stdexcept> | 标准异常 | §30.4.1.1 |
| <cassert> | 断言宏 | §30.4.2 |
| <cerrno> | C风格错误处理 | §13.1.2 |
| <system_error> | 系统错误支持 | §30.4.3 |
使用异常的断言在§13.4 中描述。
| 字符串和字符 | ||
| <string> | T字符串 | 第36章 |
| <cctype> | 字符分类 | §36.2.1 |
| <cwctype> | 宽字符分类 | §36.2.1 |
| <cstring> | C风格字符串函数 | §43.4 |
| <cwchar> | C风格宽字符串函数 | §36.2.1 |
| <cstdlib> | C风格分配函数 | §43.5 |
| <cuchar> | C风格多字符 | |
| <regex> | 正则表达匹配 | 第37章 |
<cstring> 头文件声明了 strlen() ,strcpy() 等函数系列。<cstdlib> 声明了 atof() 和 atoi(),它们可以将 C 风格的字符串转换为数值。
| 输入/输出 | ||
| <iosfwd> | I/O 设施的前向声明 | §38.1 |
| <iostream> | 标准iostream对象和操作 | §38.1 |
| <ios> | Iostream基类 | §38.4.4 |
| <streambuf> | 流缓冲区 | §38.6 |
| <istream> | 输入流模板 | §38.4.1 |
| <ostream> | 输出流模板 | §38.4.2 |
| <iomanip> | 操纵器 | §38.4.5.2 |
| <sstream> | 至/源自字符串的流 | §38.2.2 |
| <cctype> | 字符分类函数 | §36.2.1 |
| <fstream> | 至/源自文件的流 | §38.2.1 |
| <cstdio> | I/O的printf族 | §43.3 |
| <cwchar> | 宽字符的I/O的printf类型 | §43.3 |
操纵器是用于操纵流状态的对象(§38.4.5.2)。
| 本土化 | ||
| <locale> | 表示文化差异 | 第37章 |
| <clocale> | 表示C风格的文化差异 | §43.7 |
| <codecvt> | 代码约定facet | §39.4.6 |
一个locale设置本地化差异,例如日期的输出格式、用于表示货币的符号以及不同自然语言和文化之间不同的字符串排序标准。
| 语言支持 | ||
| <limits> | 数的极限 | §40.2 |
| <climits> | 表示C风格的文化差异 | §40.2 |
| <cfloat> | C风格数值标量极限宏 | §40.2 |
| <cstdint> | 标准整数类型名 | §43.7 |
| <new> | 动态内存管理 | §11.2.3 |
| <typeinfo> | 运行时类型识别支持 | §22.5 |
| <exception> | 异常处理支持 | §30.4.1.1 |
| <initializer_list> | initializ er_list | §30.3.1 |
| <cstddef> | C库语言支持 | §10.3.1 |
| <cstdarg> | 可变长度函数参数列表 | §12.2.4 |
| <csetjmp> | C 风格堆栈展开 | |
| <cstdlib> | 程序中止 | §15.4.3 |
| <ctime> | 系统时钟 | §43.6 |
| <csignal> | C 风格信号处理 | |
<cstddef> 头文件定义了 sizeof() 返回值的类型 size_t、指针减法结果和数组下标的类型 ptrdiff_t (§10.3.1),以及臭名昭著的 NULL 宏(§7.2.2)。
C 风格的堆栈展开(使用 <csetjmp> 中的 setjmp 和 longjmp)与析构函数的使用以及异常处理(第 13 章 §30.4)不兼容,最好避免使用。本书不讨论 C 风格的堆栈展开和信号。
| 数值 | ||
| <complex> | 复数及其相关操作 | §40.4 |
| <valarray> | 数值向量及其相关操作 | §40.5 |
| <numeric> | 广义数值操作 | §40.6 |
| <cmath> | 标准数学函数 | §40.3 |
| <cstdlib> | C风格随机数 | §40.7 |
| <random> | 随机数生成器 | §40.7 |
由于历史原因,abs() 和 div() 位于 <cstdlib> 中,而不是与其余数学函数一起位于 <cmath> 中(§40.3)。
| 并发 | ||
| <atomic> | 原子类型及其相关操作 | §41.3 |
| <condition_variable> | 条件变量(等待一个操作) | §42.3.4 |
| <future> | 异步任务 | §42.4.4 |
| <mutex> | 互斥类 | §42.3.1 |
| <thread> | 线程相关操作 | §42.2 |
C 语言为 C++ 程序员提供了各种相关的标准库功能。C++ 标准库提供了对以下所有功能的访问:
| 对C的兼容性 | |
| <cinttypes> | 通用整数类型的别名 |
| <cstdbool> | C bool |
| <ccomplex> | <complex> |
| <cfenv> | 浮点环境 |
| <cstdalign> | C字节对齐 |
| <ctgmath> | C “类型泛型数学”:<complex>和<cmath> |
<cstdbool> 头文件不会定义宏 bool,true 或 false。<cstdalign> 头文件不会定义宏 alignas。<cstdbool>, <ccomplex>, <calign> 和 <ctgmath> 的 .h 等效文件类似于 C++ 的 C 功能。请尽量避免使用它们。
<cfenv> 头文件提供类型(例如 fenv_t 和 fexcept_t),浮点状态标志和描述实现的浮点环境的控制模式。
用户或库实现者不得在标准头文件中添加或删除声明。也不允许通过定义宏来更改头文件的内容,从而改变头文件中声明的含义(§15.2.3)。任何玩弄此类把戏的程序或实现都不符合标准,依赖此类技巧的程序不可移植。即使它们现在能够正常工作,实现中任何部分的下一个版本都可能破坏它们。请避免此类伎俩。
要使用标准库工具,必须包含其头文件。自己编写相关声明并非符合标准的做法。原因是,某些实现会根据标准头文件的包含来优化编译,而另一些实现则会提供由头文件触发的标准库工具的优化实现。通常,实现者会以程序员无法预测且不应知晓的方式使用标准头文件。
然而,程序员可以专门为非标准库、用户定义类型设计实用程序模板,例如 swap() (§35.5.2)。
30.3 语言支持
标准库的一个小但必不可少的部分是语言支持,即程序运行必须具备的功能,因为语言特性依赖于它们。
| 库支持的语言特征 | ||
| <new> | new和delete | §11.2 |
| <typeinfo> | typeid()和type_info | §22.5 |
| <iterator> | 范围for | §30.3.2 |
| <initializer_list> | initializer_list | §30.3.1 |
30.3.1 对initializer_list的支持
根据§11.3中描述的规则,{} 列表 会被转换为 std::initializer_list<X> 类型的对象。在 <initializer_list> 中,我们找到 initializer_list:
template<typename T>
class initializer_list { // §iso.18.9
public:
using value_type = T;
using reference = const T&; // 注意 const:initializer_list 元素是不可变的
using const_reference = const T&;
using size_type = size_t;
using iterator = const T∗;
using const_iterator = const T∗;
initializer_list() noexcept;
size_t siz e() const noexcept; // number of elements
const T∗ begin() const noexcept; // first element
const T∗ end() const noexcept; // one-past-last element
};
template<typename T>
const T∗ begin(initializer_list<T> lst) noexcept { return lst.begin(); }
template<typename T>
const T∗ end(initializer_list<T> lst) noexcept { return lst.end(); }
遗憾的是,initializer_list 不提供下标运算符。如果要使用 [] 而不是 ∗,请对指针取下标:
void f(initializer_list<int> lst)
{
for(int i=0; i<lst.size(); ++i)
cout << lst[i] << '\n'; // error
const int∗ p = lst.begin();
for(int i=0; i<lst.size(); ++i)
cout << p[i] << '\n'; // OK
}
当然,initializer_list 也可以用于范围for 语句。例如:
void f2(initializer_list<int> lst)
{
for (auto x : lst)
cout << x << '\n';
}
30.3.2 对范围for的支持
按照§9.5.1 中的描述,使用迭代器将范围for 语句映射到 for 语句。
在 <iterator> 中,标准库为内置数组和提供成员 begin() 和 end() 的每种类型提供了 std::begin() 和 std::end() 函数;参见 §33.3。
所有标准库容器(例如,vector 和 unordered_map)和字符串都支持使用范围for 进行迭代;容器适配器(例如,stack 和 prioritize_queue)则不支持。容器头文件(例如,<vector>)包含 <initializer_list>,因此用户很少需要直接执行此操作。
30.4 异常处理
标准库包含近 40 年来开发的组件。因此,它们的风格和错误处理方法并不一致:
• C 语言库包含许多函数,其中许多函数会设置 errno 来指示发生了错误;参见 §13.1.2 和 §40.3。
• 许多对元素序列进行操作的算法会返回一个指向倒数第二个元素的迭代器,以指示“未找到”或“失败”;参见 §33.1.1。
• I/O 流库依赖于每个流中的状态来反映错误,并且可能(如果用户要求)抛出异常来指示错误;参见 §38.3。
• 一些标准库组件(例如 vector,string 和 bitset)会抛出异常来指示错误。
标准库的设计使得所有功能都遵循“基本保证”(§13.2);也就是说,即使抛出异常,也不会泄漏任何资源(例如内存),也不会破坏标准库类的不变量。
30.4.1 异常
一些标准库工具通过抛出异常来报告错误:
| 标准库异常 | |
| bitset | 抛出异常 invalid_argument, out_of_range, overflow_error |
| iostream | 若开启了异常则会抛出异常 ios_base::failure |
| regex | 抛出异常regex_error |
| string | 抛出异常length_error, out_of_range |
| vector | 抛出异常out_of_range |
| new T | 若不能为T分配内存则抛出异常bad_alloc |
| dynamic_cast<T>(r) | 若不能将一个引用r类型转换为一个T ,则抛出异常bad_cast |
| typeid() | 若不能提供一个type_info则抛出异常bad_typeid |
| thread | 抛出异常system_error |
| call_once() | 抛出异常system_error |
| mutex | 抛出异常system_error |
| condition_variable | 抛出异常system_error |
| async() | 抛出异常system_error |
| packaged_task | 抛出异常system_error |
| future 和 promise | 抛出异常future _error |
任何直接或间接使用这些功能的代码都可能遇到这些异常。此外,任何操作可能引发异常的对象的操作都必须被假定会引发该异常,除非已采取预防措施。例如,如果 packaged_task 需要执行的函数引发了异常,它也会引发异常。
除非您知道任何工具的使用方式都可能引发异常,否则最好始终在某个地方(§13.5.2.3)捕获标准库异常层次结构的根类之一(例如exception)以及任何异常(...),例如在 main() 中。
30.4.1.1 标准 exception的层级结构
不要抛出内置类型,例如 int 和 C 语言风格的字符串。相反,应该抛出专门定义为异常类型的对象。
标准异常类的层级结构提供了异常的分类:
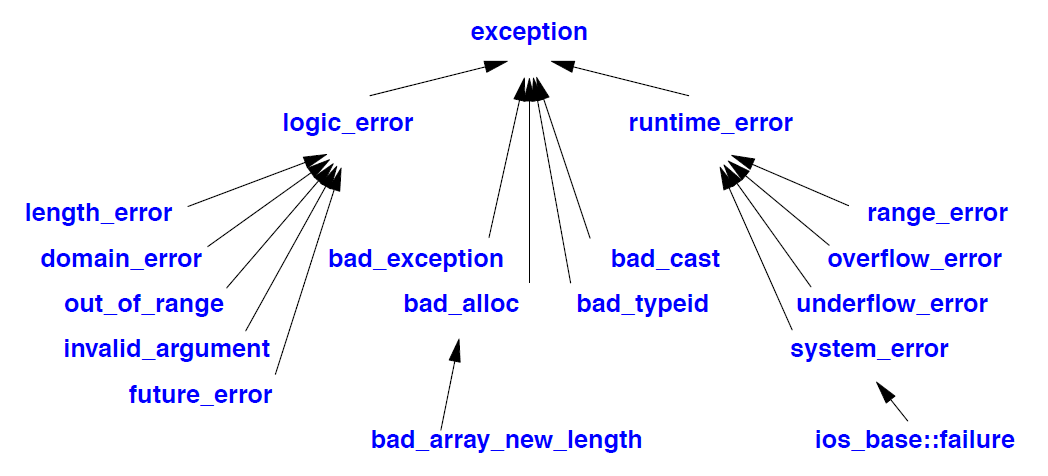
此层级结构旨在为标准库定义的异常提供一个框架。逻辑错误原则上可以在程序开始执行之前捕获,也可以通过函数和构造函数的参数测试捕获。运行时错误是所有其他错误。system_error 在§30.4.3.3中描述。
标准库异常层级结构以 exception 为基类:
class exception {
public:
exception();
exception(const exception&);
exception& operator=(const exception&);
virtual ˜exception();
virtual const char∗ what() const;
};
what() 函数可用于获取一个字符串,该字符串应该指示有关导致异常的错误的信息。
程序员可以通过从标准库异常类派生来定义异常,如下所示:
struct My_error : runtime_error {
My_error(int x) :runtime_error{"My_error"}, interesting_value{x} { }
int interesting_value;
};
并非所有异常都属于标准库异常层级结构。但是,标准库抛出的所有异常都来自该异常层次结构。
除非你知道任何工具的使用方式都可能引发异常,否则最好在某个地方捕获所有异常。例如:
int main()
try {
// ...
}
catch (My_error& me) { // My_error 异常发生
// 我们可以使用 me.interesting_value 和me.what()
}
catch (runtime_error& re) { // runtine_error 异常发生
// 我们可以使用 re.what()
}
catch (exception& e) { // 某个标准库异常发生
// 我们可以使用 e.what()
}
catch (...) { // 某个前面没有捕捉到的异常发生
// 我们可以做局部清理
}
对于函数参数,我们使用引用来避免分片(§17.5.1.4)。
30.4.1.2 异常的传递(Exception Propagation)
在 <exception> 中,标准库提供了使程序员可以访问异常传递的功能:
| 某些操作 | |
| exception_ptr | 用于指向异常的未指定类型 |
| ep=current_exception() | ep 是一个指向当前异常的 exception_ptr,如果当前没有活动异常,则指向没有异常;函数声明为noexcept |
| rethrow_exception(ep) | 重新抛出由ep所指向的异常 |
| ep=make_exception_ptr(e) | ep 所包含的指针不能为 nullptr;noreturn (§12.1.7) ep=make_exception_ptr(e) ep 是指向异常 e 的 exception_ptr;函数声明为 noexcept |
exception_ptr 可以指向任何异常,而不仅仅是异常层级结构中的异常。可以将 exception_ptr 视为一个智能指针(类似于 shared_ptr),只要 exception_ptr 指向它,它就会保持异常有效。这样,我们可以将 exception_pointer 传递给捕获异常的函数之外的异常,并在其他地方重新抛出。具体来说,exception_ptr 可用于实现在与捕获异常的线程不同的其它线程中重新抛出异常。这正是 promise 和 future(§42.4)所依赖的。在 exception_ptr 上使用 rethrow_exception()(来自不同的线程)不会引发数据竞争。
make_exception_ptr() 可以实现为:
template<typename E>
exception_ptr make_exception_ptr(E e) noexcept;
try {
throw e;
}
catch(...) {
return current_exception();
}
nested_exception 是一个存储了通过调用 current_exception() 获得的 exception_ptr 的类:
| nested_exception (§iso.18.8.6) | |
| nested_exception ne {}; | 默认构造函数:ne存储一个指向 current_exception() 的 exception_ptr 指针;标为 noexcept 。 |
| nested_exception ne {ne2}; | 复制构造函数:ne和ne2分别存储一个指向存储异常的exception_ptr指针。 |
| ne2=ne | 复制赋值:ne和ne2分别存储一个指向存储异常的exception_ptr指针。 |
| ne.˜nested_exception() | 析构函数; 声明为virtual 。 |
| ne.rethrow_nested() | 重新抛出ne存储的异常;如果其中没有存储异常,则调用 terminate();此函数声明为noreturn。 |
| ep=ne.nested_ptr() | ep 是一个 exception_ptr指针,指向 ne 存储的异常;声明为noexcept 。 |
| throw_with_nested(e) | 抛出一个基类型派生于 nested_exception 的异常以及e的类型的异常,e 不能从 nested_exception 派生;声明为 noreturn 。 |
| rethrow_if_nested(e) | dynamic_cast<const nested_exception&>(e).rethrow_nested(); e 的类型必须派生自 nested_exception 。 |
nested_exception 的预期用途是作为异常处理程序使用的类的基类,用于将一些关于错误的本地上下文的信息以及一个 exception_ptr 指针传递给导致调用它的异常。例如:
struct My_error : runtime_error {
My_error(const string&);
// ...
};
void my_code()
{
try {
// ...
}
catch (...) {
My_error err {"something went wrong in my_code()"};
// ...
throw_with_nested(err);
}
}
现在,My_error 信息与包含指向捕获到的异常的 exception_ptr 的 nested_exception 一起传递(重新抛出)。
沿着调用链往上走,我们可能需要查看嵌套异常:
void user()
{
try {
my_code();
}
catch(My_error& err) {
// ... clear up My_error problems ...
try {
rethrow_if_nested(err); // 重新抛出嵌套异常(如果有的话)
}
catch (Some_error& err2) {
// ... 清除 Some_error 问题 ...
}
}
}
这假设我们知道 some_error 可能与 My_error 嵌套。
异常不能从 noexcept 函数中传递出去(§13.5.1.1)。
30.4.1.3 terminate() 函数
在 <exception> 中,标准库提供了处理意外异常的功能:
| terminate() (§iso.18.8.3, §iso.18.8.4) | |
| h=get_terminate() | h是当前终止句柄;声明为 noexcept。 |
| h2=set_terminate(h) | h 成为当前终止句柄。是h2 前一个终止句柄。声明为 noexcept 。 |
| terminate() | 终止当前程序;声明为 noreturn,noexcept |
| uncaught_exception() | 当前线程是否抛出了异常,但尚未捕获?声明为noexcept 。 |
避免使用这些函数,除非极少数情况下使用 set_terminate() 和 terminate()。调用terminate()会通过调用由 set_terminate() 设置的终止处理程序来终止程序。默认设置(几乎总是正确的)是立即终止程序。出于操作系统的基本原因,在调用terminate() 时是否调用本地对象的析构函数由实现定义。如果由于 noexcept 违规而调用terminate(),则系统允许进行(重要的)优化,这意味着堆栈甚至可能被部分展开(§iso.15.5.1)。
有时人们声称 uncaught_exception() 可以用来编写析构函数,使其根据函数是正常退出还是异常退出而行为不同。然而,在捕获初始异常后,在堆栈展开(§13.5.1)期间,uncaught_exception() 也同样有效。我认为 uncaught_exception() 过于隐晦,不适合实际使用。
30.4.2 断言(Assertions)
标准库提供了断言:
| 断言(§iso.7) | |
| static_assert(e,s) | 编译时计算e ;若 !e 为真,则给出s为编译器错误消息。 |
| assert(e) | 若宏 NDBUG 未定义,在运行时计算e ,而若!e 为真,向 cerr 写入一条信息并调用 abort();若NDBUG 已定义,则不做任何操作。 |
例如:
template<typename T>
void draw_all(vector<T∗>& v)
{
static_assert(Is_base_of<Shape,T>(),"non−Shape type for draw_all()");
for (auto p : v) {
assert(p!=nullptr);
// ...
}
}
assert() 是 <cassert> 中的一个宏。assert() 生成的错误消息由实现定义,但应包含源文件名 (__FILE__) 以及包含 assert() 的源代码行号 (__LINE__)。
断言在生产代码中的使用频率比在小型说明性教科书中的示例中更高(正如它们应该的那样)。
函数名称 (__func__) 也可能包含在消息中。如果假设 assert() 会被求值,而实际上并没有,那么这可能是一个严重的错误。例如,在通常的编译器设置下,assert(p!=nullptr) 会在调试期间捕获错误,但在最终发布的产品中不会捕获错误。
对于管理断言的方法,请参阅§13.4。
30.4.3 system_error
在 <system_error> 中,标准库提供了一个用于报告来自操作系统和底层系统组件的错误框架。例如,我们可以编写一个函数来检查文件名,然后像这样打开一个文件:
ostream& open_file(const string& path)
{
auto dn = split_into_directory_and_name(path); // 拆分成 {path,name}
error_code err {does_directory_exist(dn.first)}; //询问 "系统" 有关路径事项
if (err) { // err!=0 意味着错误
// ... 看看可否做某事 ...
if (cannot_handle_err)
throw system_error(err);
}
// ...
return ofstream{path};
}
假设“系统”不知道 C++ 异常,我们就别无选择是否处理错误代码;唯一的问题是“在哪里?”和“如何处理?”。在 <system_error> 中,标准库提供了对错误代码进行分类、将系统特定的错误代码映射到更可移植的错误代码以及将错误代码映射到异常的功能:
| 系统错误类型 | |
| error_code | 保存一个标识错误和错误类别的值;系统特定(§30.4.3.1)。 |
| error_category | 用于识别特定类型(类别)错误代码的来源和编码的类型的基类(§30.4.3.2)。 |
| system_error | 包含 error_code 的运行时错误异常(§30.4.3.3)。 |
| error_condition | 保存一个标识错误和错误类别的值;可能具有可移植性(§30.4.3.4)。 |
| errc | enum class,包含来自 <cerrno> (§40.3) 的错误代码枚举器;基本为 POSIX 错误代码。 |
| future_errc | 带有来自 <future> 的错误代码枚举器的enum class (§42.4.4)。 |
| io_errc | 带有来自 <ios> 的错误代码枚举器的enum class (§38.4.4)。 |
30.4.3.1 错误代码
当错误以错误代码的形式从较低层级“冒泡”时,我们必须处理它所代表的错误,或者将其转换为异常。但首先我们必须对其进行分类:不同的系统对同一问题使用不同的错误代码,而不同的系统只是存在不同类型的错误。
| error_code (§iso.19.5.2) | |
| error_code ec {}; | 默认构造函数:ec={0,&generic_category}; 声明为 noexcept 。 |
| error_code ec {n,cat}; | ec={n,cat}; cat 是一个 error_category类型;并且 n 是一个 int,表示 cat 中的错误;noexcept 。 |
| error_code ec {n}; | n 表示错误;n 是 EE 类型的值,其 is_error_code_enum<EE>::value==true;声明为noexcept。 |
| ec.assign(n,cat) | ec={and,cat}; cat 是一个错误类别;n 表示错误;n 是 EE 类型的值,且 is_error_code_enum<EE>::value==true;声明为noexcept 。 |
| ec=n | ec={n,&generic_category}:ec=make_error_code(n); n 表示错误;n 是 EE 类型的值,其中 is_error_code_enum<EE>::value==true;声明为noexcept 。 |
| ec.clear() | ec={0,&generic_categor y()}; 声明为noexcept 。 |
| n=ec.value() | n是 ec 的存储值;声明为noexcept 。 |
| cat=ec.category() | cat 是对 ec 存储类别的引用;声明为noexcept 。 |
| s=ec.message() | sis 表示 ec 的字符串,可能用作错误消息:ec.category().message(ec.value()) 。 |
| bool b {ec}; | 将 ec 转换为 bool;如果 ec 表示错误,则 b 为 true;也就是说,b==false 表示“无错误”;声明为explicit 。 |
| ec==ec2 | ec 和 ec2 中的一个或两个都可以是 error_code;要比较相等,ec 和 ec2 必须具有等效的 category() 和等效的值;如果 ec 和 ec2 属于同一类型,则等效性由 == 定义;如果不是,则等效性由 category().equivalent() 定义。 |
| ec!=ec2 | !(ec==ec2) |
| ec<ec2 | 顺序 ec.category()<ec2.category() || (ec.category()==ec2.category() && ec.value()<ec2.value()) |
| e=ec.default_error_condition() | e 是对 error_condition 的引用: e=ec.category().default_error_condition(ec.value()) 。 |
| os<<ec | 将 ec.name() 写入 ostream os |
| ec=make_error_code(e) | e 是一个错误; ec=error_code(static_cast<int>(e),&generic_category()) |
对于表示简单错误代码的类型,error_code 提供了许多成员。它基本上是一个从整数到指向 error_category 的指针的简单映射:
class error_code {
public:
// representation: {value,categor y} of type {int,const error_category*}
};
error_category 是指向其派生类对象的接口。因此,error_category 通过引用传递,并以指针形式存储。每个单独的 error_category 都由一个唯一的对象表示。
再次考虑 open_file() 这个例子:
ostream& open_file(const string& path)
{
auto dn = split_into_directory_and_name(path); // split into {path,name}
if (error_code err {does_directory_exist(dn.first)}) { // ask "the system" about the path
if (err==errc::permission_denied) {
// ...
}
else if (err==errc::not_a_director y) {
// ...
}
throw system_error(err); // can’t do anything locally
}
// ...
return ofstream{path};
}
errc 错误代码在 §30.4.3.6 中描述。请注意,我使用了 if-then-else 语句链,而不是更明显的 switch 语句。原因是 == 是根据等价关系定义的,同时考虑了错误类别 () 和错误值 ()。
对 error_code 的操作是系统特定的。在某些情况下,可以使用 §30.4.3.5 中描述的机制将 error_code 映射到 error_conditions (§30.4.3.4)。使用 default_error_condition() 从 error_code 中提取 error_condition。error_condition 通常包含的信息比 error_code 少,因此通常最好保留 error_code,并仅在需要时提取其 error_condition。
操作 error_codes 不会改变 errno 的值(§13.1.2,§40.3)。标准库保留其他库提供的错误状态不变。
30.4.3.2 错误分类
error_category 表示错误的分类。具体错误由从 error_category 类派生的类表示:
class error_categor y {
public:
// ... 从 error_category 派生的特定类别的接口 ...
};
| error_category(§iso.19.5.1.1) | |
| cat.˜error_categor y() | 析构函数;声明为 virtual, noexcept 。 |
| s=cat.name() | s是cat的名称;s是C风格字符串;声明为 virtual, noexcept 。 |
| ec=cat.default_error_condition(n) | 对于cat中的n,ec是一个error_condition,声明为 virtual, noexcept 。 |
| cat.equivalent(n,ec) | ec.category()==cat 且 ec.value()==n 吗?ec是一个error_condition,声明为 virtual, noexcept 。 |
| cat.equivalent(ec,n) | ec.category()==cat 且 ec.value()==n 吗?ec是一个error_code,声明为 virtual, noexcept 。 |
| s=cat.message(n) | s是一个cat中描述n的string 。声明为 virtual 。 |
| cat==cat2 | cat与cat2的分类相同吗?声明为noexcept 。 |
| cat!=cat2 | !(cat==cat2); 声明为noexcept 。 |
| cat<cat2 | cat<cat2 是否按照基于错误类别的顺序排列?地址:std::less<const error_categor y∗>()(cat, cat2)? 声明为noexcept 。 |
由于 error_category 被设计为基类,因此不提供复制或移动操作。通过指针或引用访问 error_category。
有四个命名的标准库类别:
| 标准库错误类别 | |
| ec=generic_category() | ec.name()=="generic"; ec是一个指向 error_category 的引用。 |
| ec=system_category() | ec.name()=="system" ;ec是一个指向 error_category 的引用;表示系统错误:如果 ec对应于 POSIX 错误,则 ec.value() 等于该错误的 errno 。 |
| ec=future_category() | ec.name()=="future"; ec是一个指向 error_category 的引用。 |
| ostream_category() | ec.name()=="iostream"; ec是一个指向 error_category 的引用;表示自库 iostream 的错误。 |
这些类别是必要的,因为一个简单的整数错误代码在不同的上下文中可能具有不同的含义(categorys)。例如,1 在 POSIX 中表示“操作不允许”(EPERM),对于 iostream 错误来说,它是所有错误的通用代码(state),而对于 future 错误来说,它表示“未来已检索”(future_already_retrieved)。
30.4.3.3 异常 system_error
system_error 用于报告最终源自标准库中与操作系统相关的部分的错误。它会传递一个 error_code 和一个可选的错误消息字符串:
class system_error : public runtime_error {
public:
// ...
};
| system_error (§iso.19.5.6) | |
| system_error se {ec,s}; | se 存储 {ec,s};ec 是错误代码;s 是字符串或 C 风格字符串,作为错误消息的一部分 。 |
| system_error se {ec}; | se 存储 {ec};ec 是一个error_code 。 |
| system_error se {n,cat,s}; | se 存储 {error_code{n,cat},s};cat 是一个 error_category 变量,n 是表示 cat 中错误的 int 值;s 是字符串或 C 风格字符串,用作错误消息的一部分。 |
| system_error se {n,cat}; | ec.name()=="iostream"; ec是一个指向 error_category 的引用;表示自库 iostream 的错误。 |
| ec=se.code() | ec 是对 se 的 error_code 的引用;声明为noexcept 。 |
| p=se.what() | p 是 se 错误字符串的 C 风格字符串版本;声明为noexcept 。 |
捕获system_error的代码会返回其对应的error_code。例如:
try {
// something
}
catch (system_error& err) {
cout << "caught system_error " << err.what() <<'\n'; // error message
auto ec = err.code();
cout << "category: " << ec.category().what() <<'\n';
cout << "value: " << ec.value() <<'\n';
cout << "message: " << ec.message() <<'\n';
}
当然,非标准库代码也可以使用 system_error。此时会传递系统特定的 error_code,而不是可移植的 error_condition (§30.4.3.4)。要从 error_code 获取 error_condition,请使用 default_error_condition() (§30.4.3.1)。
30.4.3.4 异常潜在的可移植错误条件(Potentially Portable Error Conditions)
潜在可移植错误代码(error_condition)的表示方式与系统特定的error_code几乎相同:
class error_condition { // potentially portable (§iso.19.5.3)
public:
// like error_code but
// no output operator (<<) and
// no default_error_condition()
};
一般的思想是,每个系统都有一组特定的(“本机”)代码,这些代码被映射到潜在的可移植代码中,以方便需要在多个平台上工作的程序(通常是库)的程序员。
30.4.3.5 映射错误代码(Mapping Error Codes)
要创建一个包含一组 error_code 和至少一个 error_condition 的 error_category ,首先要定义一个枚举,其中包含所需的 error_code 值。例如:
enum class future_errc {
broken_promise = 1,
future_already_retrieved,
promise_already_satisfied,
no_state
};
这些值的含义完全是特定于类别的。这些枚举器的整数值是由实现定义的。
future的错误类别是标准的一部分,因此读者可以在标准库中找到它。具体细节可能与我描述的有所不同。
接下来,我们需要为我们的错误代码定义一个合适的类别:
class future_cat : error_category { // 从 future_category() 返回
public:
const char∗ name() const noexcept override { return "future"; }
string message(int ec) const override;
};
const error_categor y& future_categor y() noexcept
{
static future_cat obj;
return &obj;
}
从整数值到错误消息字符串的映射有点繁琐。我们必须设计一组对程序员来说可能有意义的消息。在这里,我并不是想耍小聪明:
string future_error::message(int ec) const
{
switch (ec) {
default: return "bad future_error code";
future_errc::broken_promise: return "future_error: broken promise";
future_errc::future_already_retrieved: return "future_error: future already retrieved";
future_errc::promise_already_satisfied: return "future_error: promise already satisfied";
future_errc::no_state: return "future_error: no state";
}
}
现在我们可以从future_errc 生成一个 error_code :
error_code make_error_code(future_errc e) noexcept
{
return error_code{int(e),future_categor y()};
}
对于接受单个错误值的error_code构造函数和赋值操作,要求参数的类型应与错误类别相匹配。例如,一个旨在成为future_category()的error_code的value()必须是future_errc。特别是,我们不能随便使用任何整数。例如:
error_code ec1 {7}; // error
error_code ec2 {future_errc::no_state}; // OK
ec1 = 9; // error
ec2 = future_errc::promise_already_satisfied; // OK
ec2 = errc::broken_pipe; // error : wrong error category
为了帮助 error_code 的实现者,我们为我们的枚举专门设计了特征 is_error_code_enum:
template<>
struct is_error_code_enum<future_errc> : public true_type { };
标准已经提供了通用模板:
template<typename>
struct is_error_code_enum : public false_type { };
这说明任何我们认为不是错误代码的值都不是错误代码。为了使 error_condition 适用于我们的类别,我们必须重复对 error_code 所做的操作。例如:
error_condition make_error_condition(future_errc e) noexcept;
template<>
struct is_error_condition_enum<future_errc> : public true_type { };
为了实现更有趣的设计,我们可以为 error_condition 使用一个单独的枚举,并让 make_error_condition() 实现从 future_errc 到该枚举的映射。
30.4.3.6 errc错误代码
system_category() 的标准错误代码由枚举类 errc 定义,其值等同于 POSIX 派生的 <cerrno> 内容:



这些代码适用于“系统”类别:system_category()。对于支持类 POSIX 设施的系统,它们也适用于“通用”类别:generic_category()。
POSIX 宏是整数,而 errc 枚举器是 errc 类型。例如:
void problem(errc e)
{
if (e==EPIPE) { // error : 不存在从errc 到 int的转换
// ...
}
if (e==broken_pipe) { // error : broken_pipe 不在作用域内
// ...
}
if (e==errc::broken_pipe) { // OK
// ...
}
}
30.4.3.7 future_errc错误代码
future_category() 的标准错误代码由枚举类 future_errc 定义:

这些代码对于“future”类别有效:future_category()。
30.4.3.8 io_errc错误代码
iostream_category() 的标准错误代码由枚举类 io_errc 定义:

此代码对“iostream”类别有效:iostream_category()。
30.5 建议
[1] 使用标准库工具来保持可移植性;§30.1,§30.1.1。
[2] 使用标准库工具来最小化维护成本;§30.1。
[3] 使用标准库工具作为更广泛、更专业的库的基础;§30.1.1。
[4] 使用标准库工具作为灵活、广泛使用的软件的模型;§30.1.1。
[5] 标准库工具在命名空间 std 中定义,并可在标准库头文件中找到;§30.2。
[6] C 标准库头文件 X.h 在 <cX> 中作为 C++ 标准库头文件呈现;§30.2。
[7] 请勿在未 #include 其头文件的情况下尝试使用标准库工具;§30.2。
[8] 要在内置数组上使用范围for,请 #include<iterator>;§30.3.2。
[9] 优先使用基于异常的错误处理,而不是基于返回码的错误处理;§30.4。
[10] 始终捕获 exception& (用于标准库和语言支持异常)和 ...(用于意外异常);§30.4.1。
[11] 标准库异常层次结构可以(但不是必须)用于用户自己的异常;§30.4.1.1。
[12] 出现严重问题时调用 terminate();§30.4.1.3。
[13] 广泛使用 static_assert() 和 assert();§30.4.2。
[14] 不要假设 assert() 总是被求值;§30.4.2。
[15] 如果不能使用异常,请考虑 <system_error>;§30.4.3。
内容来源:
<<The C++ Programming Language >> 第4版,作者 Bjarne Stroustrup


 —— How LVGL works from top to down)








)


)

通过自定义 MAVLink 消息与 QGroundControl (QGC) 通信)

)
