如何衡量代码的好坏?
评价代码的好坏我们使用算法效率来判断,而算法效率分两种:
算法效率:
第一种是时间效率,第二种是空间效率,时间效率被称为时间复杂度,⽽空间效率被称作空间复杂度。 时间复杂度主要衡量的是⼀个算法的运⾏速度,⽽空间复杂度主要衡量⼀个算法所需要的额外空间,现在我们计算机的储存容量已经很高了,所以我们更加注重时间复杂度。
1.时间复杂度的概念
在 Java 中,时间复杂度是用来衡量一个算法运行所消耗时间的概念。但它并不是精确计算算法实际运行的时间,因为算法实际运行时间会受运行环境(如机器性能)、测试数据规模等因素影响。时间复杂度采用大 O 符号表示法,⼀个算法所花费的时间与其中语句的执⾏次数成正⽐例,算法中的基本操作的执⾏次数,为算法的时间复杂度。
2.解析几个常见的时间复杂度类型。
在实际中⼀般情况关注的是算法的最坏运⾏情况。
O (n) - 常数时间复杂度
import java.util.Scanner;public class TEXT {public static void main(String[] args) {int count=0;Scanner scan=new Scanner(System.in);//输入nint n= scan.nextInt();for(int i=0;i<n;i++){//复杂度为ncount++;}System.out.println(count);}
}
O (n²) - 平方时间复杂度
import java.util.Scanner;public class TEXT {public static void main(String[] args) {int count=0;Scanner scan=new Scanner(System.in);int n= scan.nextInt();for(int i=0;i<n;i++){//n*n平方复杂度for (int j=0;j<n;j++){count++;}}System.out.println(count);}
3.O(M+N)复杂度
import java.util.Scanner;public class TEXT {public static void main(String[] args) {int count=0;Scanner scan=new Scanner(System.in);int m= scan.nextInt();int n= scan.nextInt();for(int i=0;i<m;i++){//m一个O(M)复杂度count++;}for(int j=0;j<n;j++){//n一个O(N)复杂度count++;}System.out.println(count);}
4. O (log n) - 对数时间复杂度
典型的就是二分查找:
在这段代码中,每执行一次循环体,查找范围就会缩小一半。比如初始数组长度为 n ,第一次循环后查找范围变为约 n /2,第二次变为约 n/4 ,以此类推。假设最多需要 k 次循环就能找到目标元素或者确定目标元素不存在,那么就有 n/2'k=1 ,解这个等式可得 k=log2n,
根据时间复杂度的计算规则,总的时间复杂度就是 O(logn)
import java.util.Scanner;public class TEXT {public static int boo(int[] arr,int tag){int left=0;int right= arr.length-1;while (left<=right){int mid=left+(right-left)/2;if(arr[mid]<tag){left=mid+1;} else if (arr[mid]==tag) {return mid;}else{right=mid-1;}}return -1;}public static void main(String[] args) {int[] arr={1,3,5,7,9};System.out.println(boo(arr,5));}
5. O (n log n) - 线性对数时间复杂度
二.包装类
包装类的作用:方便在泛型中使用,泛型只能引用类型,包装类包含许多实用方法
JAVA中8种基本数据类型进行封装,处理int的Integer和char的Character其他的包装类都为自己首字母大写后的模样
基本数据类型------------->包装类类型
boolean--------------------->Boolean(true,false)byte------------------------->Byte(-128,127)
short------------------------->Short(-128,127)
long-------------------------->Long(-128,127)
float-------------------------->Float(-128,127)
double------------------------>Double(-128,127)
int----------------------------->Integer(-128,127)
char--------------------------->Character(0~127)
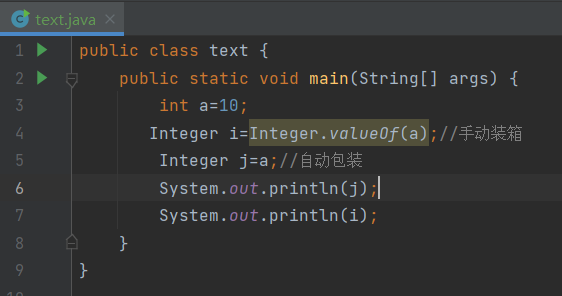
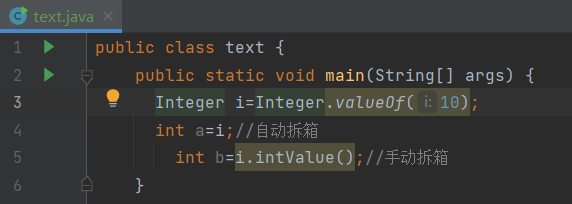
装箱拆箱
装箱分为自动装箱和手动装箱,拆箱也同样分为自动和手动。
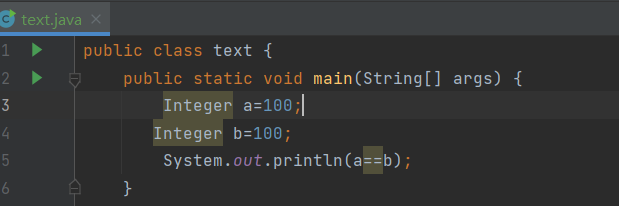
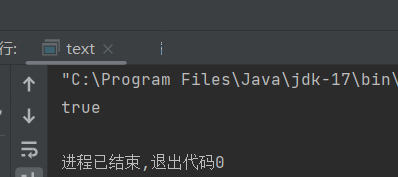
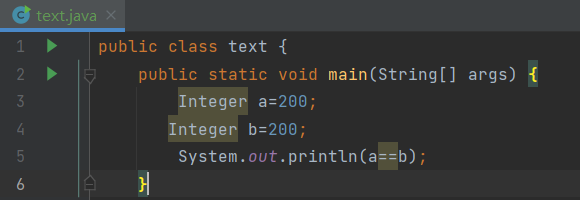
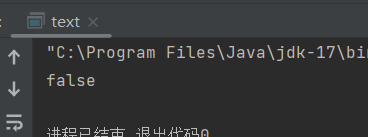
看下面这组a,b为100时代码a==b返回true,而当我们将a,b变为200时返回false。这个原因是因为对于 Integer 类型,当值在 -128 到 127 之间时,Java 会对其进行缓存,以提高性能和节省内存。a 和 b 的值是 200,不在 -128 到 127 这个缓存范围内。因此,Java 会为 a 和 b 分别创建新的 Integer 对象。a 和 b 引用的是不同的对象,所以 a == b 的比较结果为 false。
泛型
为实现可应用于各种类型的代码而生
概念:泛型即参数化类型,也就是把类型当作参数传递。借助泛型,在定义类、接口或者方法时,能使用类型参数来替代具体的类型。在使用时再指定具体的类型,这样就能让同一个类、接口或方法处理不同类型的数据。
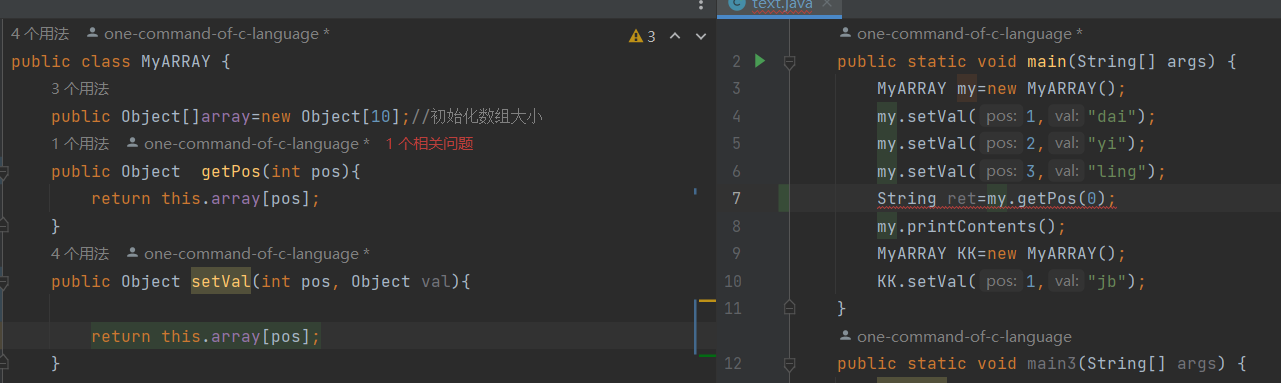
下面的代码,当我们不使用泛型时,我们在将数组内容交给ret时会显得比较鸡肋,因为我们object是父类String是子类,父类内容交给子类要强制类型转换,当我们使用时会不方便,当我们需要多组数据时,我们还要去查看需要的是什么类型的。所以这个时候我们引入了泛型类型,它可以实现各种类型代码的应用。
我们看下面两组代码:
1组未使用泛型
2.组使用了泛型
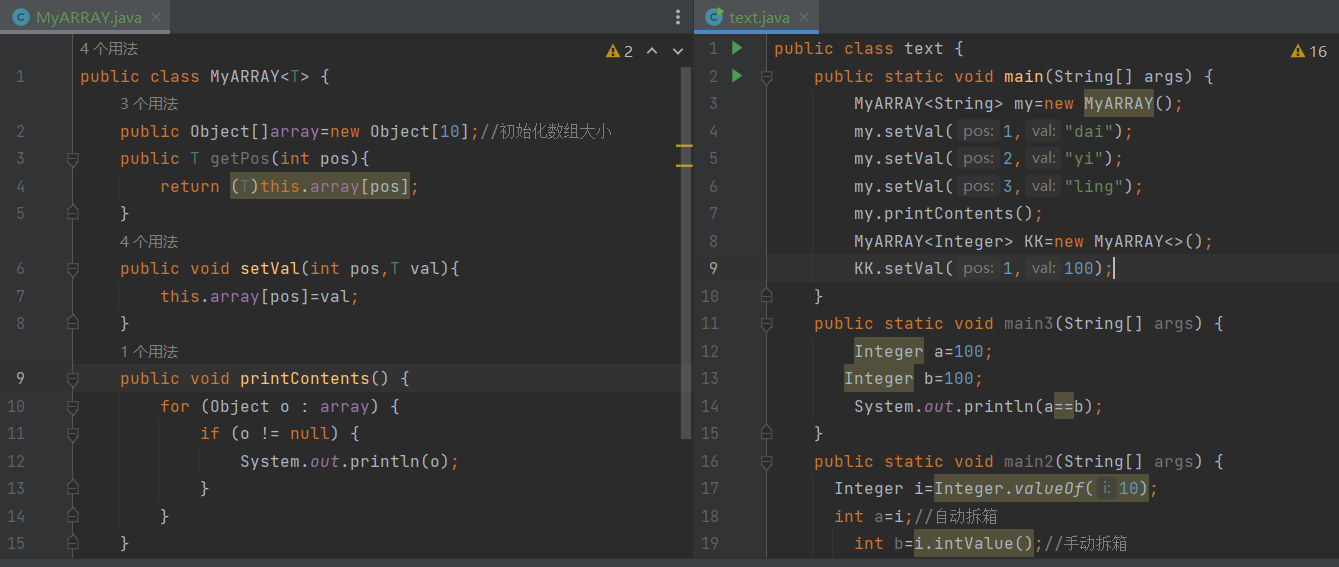
使用了泛型后当我们需要调用String类型时,直接在<>内添加我们需要的类型如<Interger><Double>注意:这里面只能是包装类不能是基本类型如int这样。
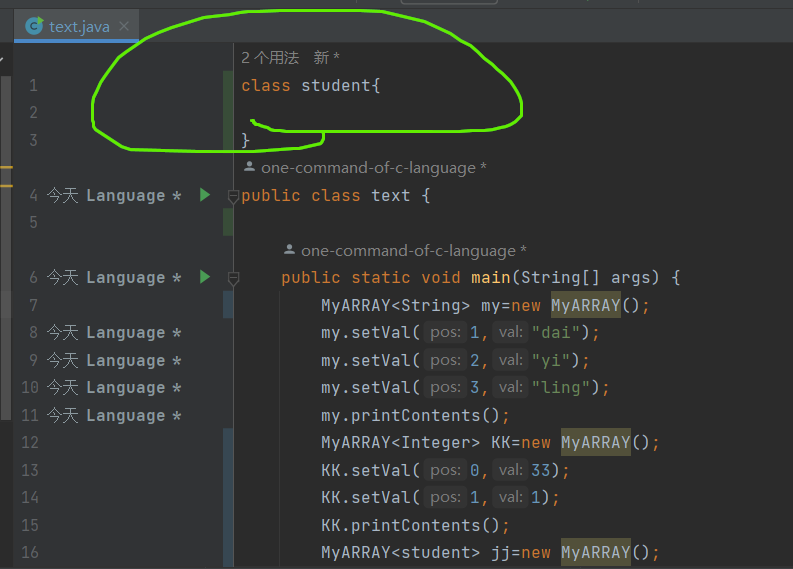
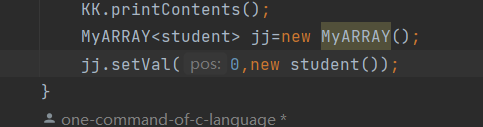
这里我们自定义一个student类型,我们可以通过使用我们student类型来new student储存到jj中
泛型擦除机制
概念:在编译时,java编译器会把泛型的信息从泛型中移除,这就是泛型的擦除机制。
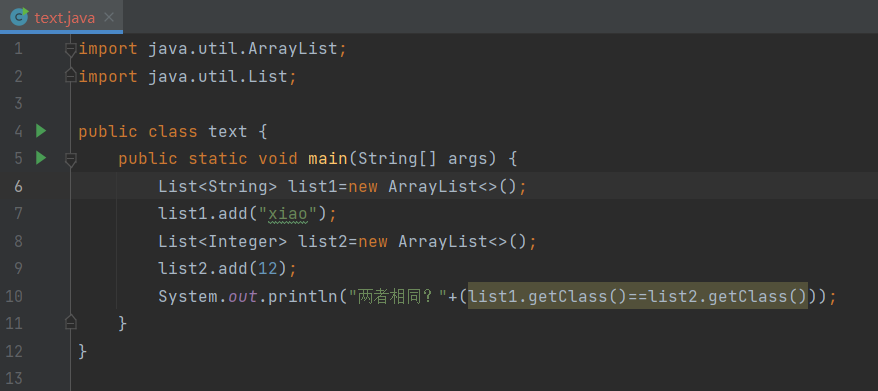
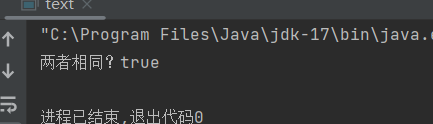
观察上面这段代码我们可以发现即使我们的两个list使用的泛型类型不同,在编译运行时我们还是可以返回true,这就是因为我们泛型类型的擦除效果。下面我们去看看他们的原始类型是什么:

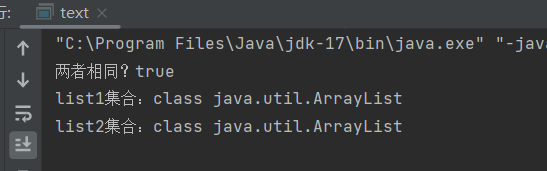
我们通过代码的运行发现我们list1和list2原始类型都为ArrayList并没有携带具体的储存数据类型,而我们泛型擦除后大多数情况将泛型替换成边界或Object。
泛型的上界
泛型是没下界的,我们泛型在定义时有时候需要对传入的数据变量做一定的约束,我们就会用到泛型的边界约束。
class qq<t extends Number>像这样就是一种约束,我们泛型继承了Number,t是Number的子类,也可以是Number。
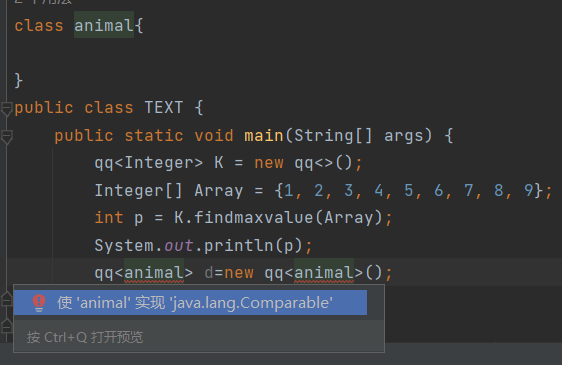
我们创建了一个找最大数的代码类qq,我们的qq继承了Comparable接口,当我们再创建animal类时,我们qq去使用了这个animal类会出现提醒让我们去实现Comparable接口,因为qq的泛型是继承了Comparable的。这也就进行了约束作用。
class qq<t extends Comparable<t>> {public t findmaxvalue(t[] Array) {t max = Array[0];for (int i = 1; i < Array.length; i++) {if (max.compareTo(Array[i]) < 0) {max = Array[i];}}return max;}
}
class animal{}
public class TEXT {public static void main(String[] args) {qq<Integer> K = new qq<>();Integer[] Array = {1, 2, 3, 4, 5, 6, 7, 8, 9};int p = K.findmaxvalue(Array);System.out.println(p);qq<animal> d=new qq<animal>();}
}
完


)





)










