Phi-4-reasoning-plus 技术解读
一、模型概述
Phi-4-reasoning-plus 是微软研究院开发的一种前沿开源推理模型,基于 Phi-4 通过监督微调和强化学习进一步训练而成。该模型专注于高质量和高级推理能力的培养,旨在为小型高效模型提供强大的推理性能。其训练数据融合了合成提示和从公共领域网站筛选的优质数据,涵盖数学、科学和编程技能,并包含安全性和负责任 AI 的对齐数据。
二、模型架构与训练
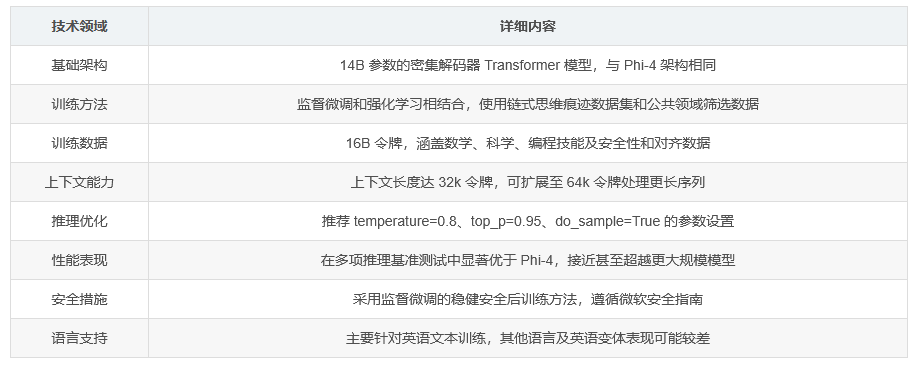
Phi-4-reasoning-plus 与此前发布的 Phi-4 基础架构相同,拥有 14B 参数,采用密集解码器的 Transformer 模型。其输入形式为文本,特别适合聊天格式的提示,上下文长度可达 32k 令牌。模型在 32 个 H100-80G GPU 上训练,耗时 2.5 天,训练数据包含 16B 令牌,约 8.3B 独特令牌。
三、推理参数与使用建议
推理时建议采用 temperature=0.8、top_p=0.95 且 do_sample=True 的参数设置。对于复杂查询,可将最大令牌数设置为 32k 以支持更长的思维链。此外,还可将最大令牌数扩展至 64k,以处理更长序列并保持连贯性和逻辑一致性。推理时应使用 ChatML 模板,并包含系统提示。
四、性能评估与基准测试
Phi-4-reasoning-plus 在多项推理密集型任务上表现出色。在 AIME、GPQA-Diamond、OmniMath、LiveCodeBench 等基准测试中均取得了优异成绩。与 Phi-4 相比,在多数任务上性能均有显著提升。例如,在 AIME 2025 中准确率从 62.9% 提升至 78.0%,在 OmniMath 中从 76.6% 提升至 81.9%。
五、安全性和负责任 AI 考量
Phi-4-reasoning-plus 采用监督微调的稳健安全后训练方法,遵循严格的微软安全指南。通过与独立 AI 红队合作,对模型在普通用户和对抗性用户场景下的安全风险进行评估。尽管如此,该模型仍可能存在不公平、不可靠或冒犯性行为。开发者应考虑模型的常见限制,在特定下游用例中评估和缓解准确性、安全性和公平性问题,并遵循适用的法律法规。
六、核心技术总结



)















)