每周五篇博客:(3/5)
碎碎念
其实不是我想多水一篇博客,本来这篇是欧拉序的博客,结果dfs序也是可以O1求lca的,而且常数更优,结果就变成这样了。。。
前置知识
[算法学习]——dfs序
思想
分类讨论
对于查询的两个节点 u , v u, v u,v ,称两个节点的最近公共祖先为 l c a lca lca ,首先我们先确保 d f n u ≤ d f n v dfn_u \le dfn_v dfnu≤dfnv (这里的 d f n u dfn_u dfnu 表示 u u u 的dfs序,也是前置知识中的 l u l_u lu),如果 d f n u > d f n v dfn_u > dfn_v dfnu>dfnv 的话我们swap一下就可以
如果 u u u 是 v v v 的祖先节点的话,那么 l c a lca lca 一定是 u u u ,只需要判断下是否满足 d f n u ≤ d f n v dfn_u \le dfn_v dfnu≤dfnv(相当于 l u ≤ l v l_u \le l_v lu≤lv) 并且 r u ≥ r v r_u \ge r_v ru≥rv 即可
如果 u u u 不是 v v v 的祖先节点,并且我们保证了 d f n u ≤ d f n v dfn_u \le dfn_v dfnu≤dfnv 所以 u , v u, v u,v 一定在不同的子树中,例如
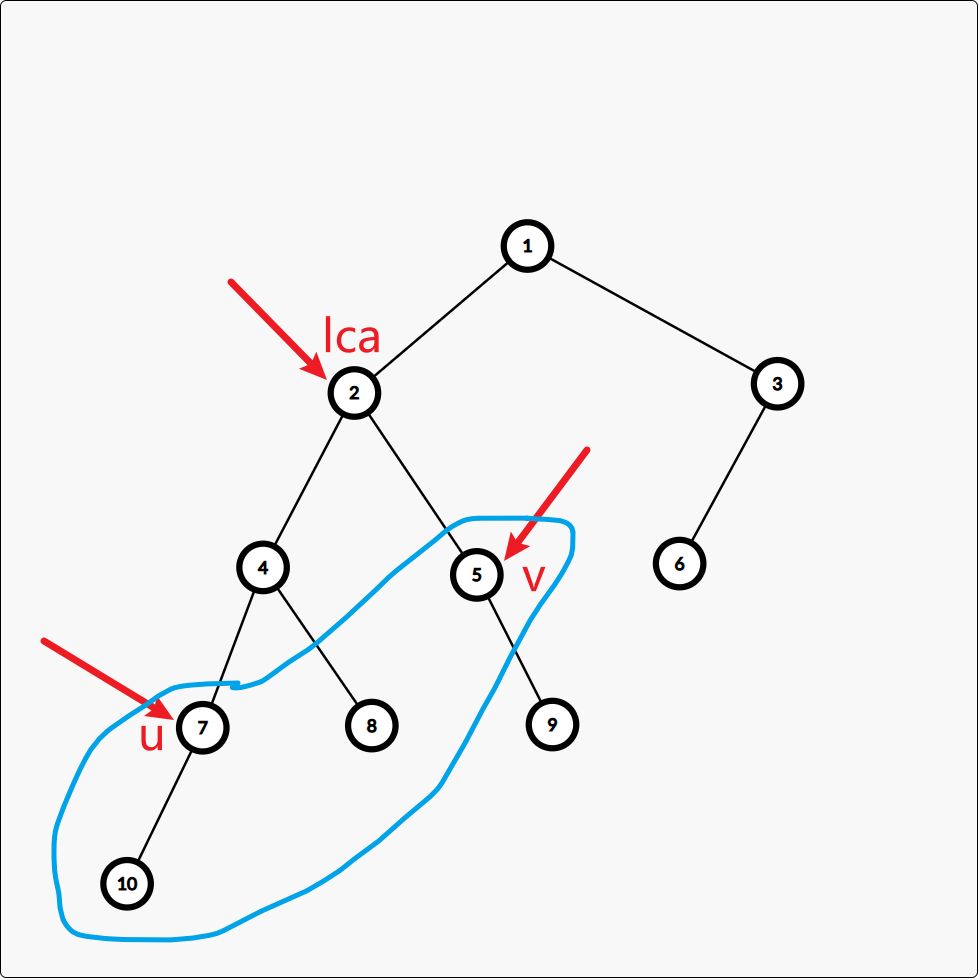
蓝色圈内的节点其实是dfs序处于 [ d f n u , d f n v ] [dfn_u, dfn_v] [dfnu,dfnv] 内的所有节点
这于欧拉序不同的地方在于这个区间内并不包含 l c a lca lca 节点,但是却包含了 l c a lca lca 的儿子节点,事实上在dfs序处于区间 [ d f n u , d f n v ] [dfn_u, dfn_v] [dfnu,dfnv] 中至少存在一个 l c a lca lca 的儿子节点。我们设这个 l c a lca lca 的儿子节点为 w w w ,由于 u , v u, v u,v 不在同一子树中,在dfs遍历完 u u u 子树后会返回到 l c a lca lca 节点接着去遍历 u u u 子树之后的其他子树,当遍历到 v v v 节点所在的子树时,这个子树的顶点便是 w w w ( v , w v, w v,w 有可能是同一个节点),因为遍历 w w w 在遍历 v v v,所以有 d f n w ≤ d f n v dfn_w \le dfn_v dfnw≤dfnv,那么 d f n w dfn_w dfnw 也就处于区间 [ d f n u , d f n v ] [dfn_u, dfn_v] [dfnu,dfnv] 了
而这个 w w w 一定是区间 [ d f n u , d f n v ] [dfn_u, dfn_v] [dfnu,dfnv] 中深度最小的节点,因为其父亲节点是 l c a lca lca ,而且区间 [ d f n u , d f n v ] [dfn_u, dfn_v] [dfnu,dfnv] 只会包含 l c a lca lca 子树内部的节点(不包含 l c a lca lca),所以 l c a lca lca 的儿子节点就是深度最小的节点
所以我们只需要查询到区间 [ d f n u , d f n v ] [dfn_u, dfn_v] [dfnu,dfnv] 最小的节点的父亲,就可以找到 l c a lca lca 了
关于区间查询,因为是静态查询并不涉及到修改操作,所以我们可以使用RMQ算法来实现 O ( n log n ) O(n\log n) O(nlogn) 的预处理以及 O ( 1 ) O(1) O(1) 的单次查询
而关于维护RMQ的预处理,我们定义 m i n j , i min_{j, i} minj,i 表示dfs序中 [ i , i + 2 j ] [i, i + 2^j] [i,i+2j] 区间内深度最浅的节点的编号,所以初始化有 m i n 0 , i = i d i min_{0, i} = id_i min0,i=idi (这里的 i d i id_i idi 表示dfs序为 i i i 所对应的节点的编号),关于维护 m i n j , i min_{j,i} minj,i 数组,我们比较两个区间中深度最浅的节点哪个区间更浅就可以了,这里可以单独写一个比较函数,关于查询和普通的RMQ一样,不过需要配合刚刚的比较函数
代码
例题:P3379 【模板】最近公共祖先(LCA)
int min[21][N];std::vector<int> go[N];
int l[N], r[N], id[N], tot, dep[N], f[N];
void dfs(int u, int fa) {f[u] = fa;l[u] = ++ tot;id[tot] = u;dep[u] = dep[fa] + 1;for (auto v : go[u]) {if (v == fa) continue;dfs(v, u);}r[u] = tot;
}int update(int x, int y) {if (dep[x] < dep[y]) return x;return y;
}void rmq(int n) {for (int i = 1; i <= n; i ++) min[0][i] = id[i];for (int j = 1; j <= std::__lg(n); j ++)for (int i = 1; i + (1 << j) - 1 <= n; i ++)min[j][i] = update(min[j - 1][i], min[j - 1][i + (1 << (j - 1))]);
}int lca(int u, int v) {if (l[u] > l[v]) std::swap(u, v);if (l[u] <= l[v] && r[u] >= r[v]) return u;u = l[u], v = l[v];int k = std::__lg(v - u + 1);return f[update(min[k][u], min[k][v - (1 << k) + 1])];
}void solve() {int n, q, root;std::cin >> n >> q >> root;for (int i = 1; i < n; i ++) {int u, v;std::cin >> u >> v;go[u].push_back(v);go[v].push_back(u);}dfs(root, 0);rmq(n);while (q --) {int u, v;std::cin >> u >> v;std::cout << lca(u, v) << "\n";}
}板子
其实这个板子是我AC后让gpt给我封装的
struct LCA {int n, LOG;std::vector<int> l, r, id, dep, parent, lg;std::vector<std::vector<int>> st;const std::vector<std::vector<int>>& adj;int tot = 0;// 构造函数:传入节点数 n(假设节点编号 1..n)、邻接表 adj、根节点 rootLCA(int _n, const std::vector<std::vector<int>>& _adj, int root): n(_n), adj(_adj){LOG = 32 - __builtin_clz(n); // ⌊log2(n)⌋ 的上界l.assign(n+1, 0);r.assign(n+1, 0);id.assign(n+1, 0);dep.assign(n+1, 0);parent.assign(n+1, 0);lg.assign(n+2, 0);// 预处理对数for (int i = 2; i <= n; i++)lg[i] = lg[i>>1] + 1;// 1) 建立 dfs 序,记录 l[u], r[u], id[]dfs(root, 0);// 2) 构建 ST 表用于 RMQst.assign(LOG+1, std::vector<int>(n+2));// 第一层直接存序列上的节点编号for (int i = 1; i <= n; i++)st[0][i] = id[i];// 其余层for (int j = 1; j <= LOG; j++) {for (int i = 1; i + (1<<j) - 1 <= n; i++) {int x = st[j-1][i];int y = st[j-1][i + (1<<(j-1))];// 取深度更小(即在树上更靠近根)的那个st[j][i] = (dep[x] < dep[y] ? x : y);}}}// 返回节点 u 在序列中的位置 l[u], 以及构造 parent, depvoid dfs(int u, int p) {parent[u] = p;dep[u] = dep[p] + 1;l[u] = ++tot;id[tot] = u;for (int v : adj[u]) {if (v == p) continue;dfs(v, u);}r[u] = tot;}// O(1) 查询 LCAint lca(int u, int v) const {// 如果 u 是 v 的祖先,直接返回 u;反之同理if (l[u] <= l[v] && r[u] >= r[v]) return u;if (l[v] <= l[u] && r[v] >= r[u]) return v;// 保证 l[u] < l[v]if (l[u] > l[v]) std::swap(u, v);// 在序列 [l[u]..l[v]] 上做 RMQ,找到深度最小的节点 xint L = l[u], R = l[v];int k = lg[R-L+1];int x1 = st[k][L], x2 = st[k][R - (1<<k) + 1];int x = (dep[x1] < dep[x2] ? x1 : x2);// 这个 x 一定是 u 到 v 路径上,且最靠近根的那个孩子节点,// 它的 parent 就是 LCAreturn parent[x];}
};
使用方法:
void solve() {int n, q, root;std::cin >> n >> q >> root;std::vector go(n + 1, std::vector<int>());for (int i = 1; i < n; i ++) {int u, v;std::cin >> u >> v;go[u].push_back(v);go[v].push_back(u);}LCA lca(n, go, root);while (q --) {int u, v;std::cin >> u >> v;std::cout << lca.lca(u, v) << "\n";}
}

)



显示模式设置)


)

内部RTC实时时钟及实战含源码)


图像与通道拼接函数-----将 4 个单通道图像矩阵 (GMat) 合并为一个 4 通道的多通道图像矩阵函数merge4())





