前言:
通过之前的学习,我们已经学会了红黑树和map、set。这次我们要实现自己的map和set,对,使用红黑树进行封装!
当然,红黑树内容这里就不在赘述,我们会复用红黑树的代码,所以先将红黑树头文件代码拷贝过来。当然,也需要创建两个新的头文件,我将它们命名为"mymap.h"和"myset.h"。
这里把红黑树中的前中序遍历删除了,因为用不上。
提前声明,RBTree.h中的方法都是大写的,因为要和map和set类区分,这里map和set是按照STL标准实现的。
一:创建头文件
创建"mymap.h"和"myset.h",并包含"RBTree.h"头文件(这个就是我们之前实现的红黑树头文件,大家随意命名),之后为了方便后续操作,我们将它们都封装到一个bit命名空间中去。
这里set只需要K,一个模板参数;而map需要 K,V两个模板参数。其中的私有成员变量是红黑树。
二:修改模板参数
此时我们面临第一个问题,红黑树在其他类中声明,需要传入模板参数,但是set需要一个模板参数;map需要两个模板参数,我们该怎么想RBTree传入参数呢?
此时我们就需要将RBTree的模板参数修改了,其实C++源代码也是这么干的。
但是在此之前,还有一个问题,我们定义树节点的时候也应该修正。我们先来看看RBTree是如何修改的:
template<class K, class T>
class RBTree
{//......
}它将第二个参数修改为了T。
此时你慌了,WTF!这?这后面的代码不都要修改吗?那map和set又是怎么传入参数的?
因为set只存K,所以可以传入两个K;而map存键值对,我们第一个传入K,第二个传入pair<K, V>即可。
map头文件:
#pragma once
#include"RBTree.h"namespace bit
{template<class K, class V>class map{public:private:RBTree<K, pair<K, V>> _t;};
}
set头文件:
#pragma once
#include"RBTree.h"namespace bit
{template<class K>class set{public:private:RBTree<K, K> _t;};
}当然,树节点里面的也不再是只针对K, V存储了,而是存的T。
//定义树节点
template<class T>
struct RBTreeNode
{//让编译器生成默认构造RBTreeNode() = default;//写一个构造RBTreeNode(const T& data): _data(data){}T _data;RBTreeNode* _left = nullptr;RBTreeNode* _right = nullptr;RBTreeNode* _parent = nullptr; //父节点Colour _col = RED; //默认为红色
};看到这里你可能一头雾水,没事,我们画个图你就懂了:
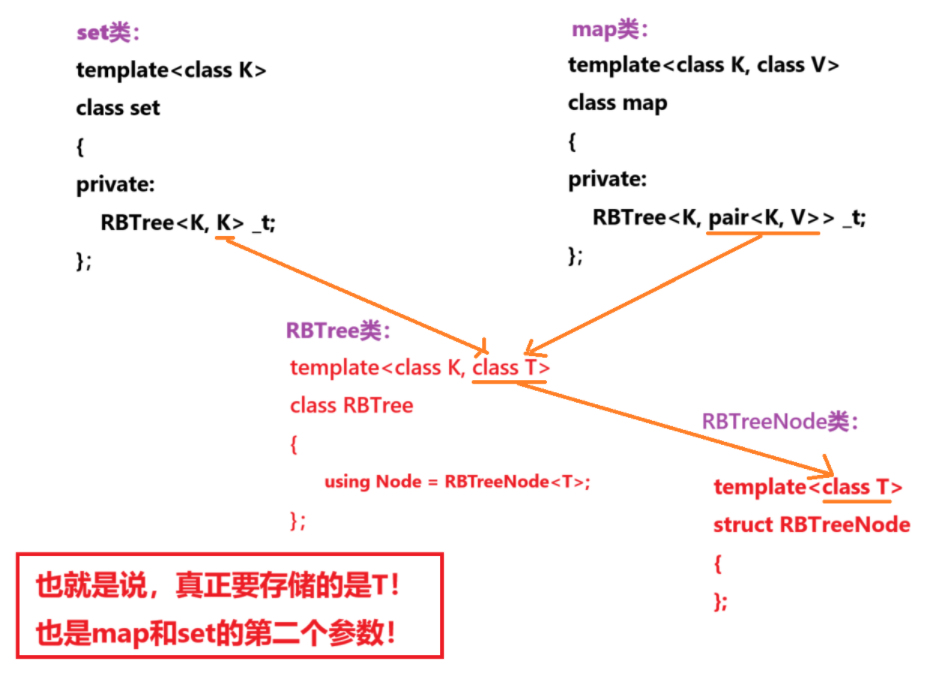
此时你就会想:为啥底层要这样设计?一个参数看起来也可以完成。
对,可以。但是你可曾想过,如果设计为一个参数,是不是每次比较(只和键比较)是不是每次都要再套一层,增加了代码复杂度。而多写一个K作为参数,我们比较的时候就会少些操作,比从pair中提取first更高效。
而且多写一个Key会使查找和比较更加轻松。也更方便解耦。
所以我们每次插入的就不再是pair,而是T类型的data,所以这里修改Insert代码:
//插入
bool Insert(const T& data)
{
}如果是set的insert插入的就是K;map的insert插入的就是pair<K, V>。
三:每个类增加仿函数
此时你兴致勃勃的去修改Insert代码(以下只展示修改部分):
bool Insert(const T& data)
{if (_root == nullptr){Node* newNode = new Node(data); //修改部分_root = newNode;_root->_col = BLACK; //更新根节点 并置为黑色return true;}//... //新建节点cur = new Node(data); //修改部分
}但聪明的你发现,这里的比较会出现问题:
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{if (kv.first > cur->_kv.first){parent = cur;cur = cur->_right;}else if (kv.first < cur->_kv.first){parent = cur;cur = cur->_left;}else{//已经存在该值了 不处理return false;}
}我怎知道到底该比较哪个呢?我又不知道上面传入的到底是set还是map,这可咋办?完犊子了。后面的比较不都歇菜了?
对,你当然不知道,这是由谁传给你你才知道的,也就是谁封装得你,谁知道(就像qsort函数一样)。所以我们应该先让set和map对RBTree这个类传入一个能转换的,之后才能比较。
此时就需要用到仿函数了,大家都知道,仿函数是一个类,里面实质上就是对“()”的重载,所以我们在set和map类中写一个内部类,map的仿函数传入pair<K, V>放回first;set传入K,返回K。
先对map添加仿函数:
template<class K, class V>
class map
{//template<K, V> 此时不需要给内部类加模板参数 因为它知道外部的模板参数struct MapOfK{const K& operator()(const pair<K, V>& kv){return kv.first;}};
public:
private:RBTree<K, pair<K, V>, MapOfK> _t; //传入仿函数
};在对set添加仿函数:
template<class K>
class set
{struct SetOfK{const K& operator()(const K& key){return key;}};public:
private:RBTree<K, K, SetOfK> _t;
};此时注意RBTree的模板参数也需要多一个参数,我们称作:KeyOfT。
//新增模板参数 KeyOfT
template<class K, class T, class KeyOfT>
class RBTree
{//...
};之后我们就可以通过KeyOfT来实现具体比较的是哪个操作对象了,为了方便,因为仿函数是一个类,我们在RBTree类中实例化一个KeyOfT对象命名为kot,只要对T进行比较就转换一下:
template<class K, class T, class KeyOfT>
class RBTree
{
public://对RBTreeNode进行重命名using Node = RBTreeNode<T>;//实例化一个KeyOfT对象KeyOfT kot;//插入bool Insert(const T& data){if (_root == nullptr){Node* newNode = new Node(data);_root = newNode;_root->_col = BLACK; //更新根节点 并置为黑色return true;}Node* parent = nullptr;Node* cur = _root;while (cur){//if (kv.first > cur->_kv.first)if (kot(data) > kot(cur->_data)) //使用kot{parent = cur;cur = cur->_right;}//else if (kv.first < cur->_kv.first)else if (kot(data) < kot(cur->_data)) //使用kot{parent = cur;cur = cur->_left;}else{//已经存在该值了 不处理return false;}}//新建节点cur = new Node(data);//if (kv.first > parent->_kv.first)if (kot(data) > kot(parent->_data)) //使用kot{parent->_right = cur;}else{parent->_left = cur;}cur->_parent = parent; //记得更新父节点//调整树...
}对,后面的调整不会和data比较,无需修改,修改的部分只有这么点。
之后就是修改Find函数了:
bool Find(const K& key)
{Node* cur = _root;while (cur){//if (key > cur->_kv.first)if (kot(data) > kot(cur->_data)) //kot替换{cur = cur->_right;}else if (kot(data) < kot(cur->_data)) //kot替换{cur = cur->_left;}else{return true;}}return false;
}之后不要忘记在set和map中添加对应的insert方法,本质也就是调用红黑树的Insert方法。
map中insert方法:
bool insert(const pair<K, V>& kv)
{return _t.Insert(kv);
}set中insert方法:
bool insert(const K& key)
{return _t.Insert(key);
}这时候不要着急,我们要调试一下代码了。这里给出test.cpp代码:
#include"myset.h"
#include"mymap.h"namespace bit
{void test_set(){set<int> s;int a[] = { 17, 18, 23, 34, 27, 15, 9, 6, 8, 5, 25 };for (auto e : a){cout << e << endl;s.insert(e);}}void test_map(){map<int, int> m;int a[] = { 17, 18, 23, 34, 27, 15, 9, 6, 8, 5, 25 };for (auto e : a){cout << e << endl;m.insert({ e, e });}}
}int main()
{//bit::test_set();bit::test_map();return 0;
}小编这里没有问题,相信大家也是这样(哈哈)。
四:实现迭代器
上面其实都不算很难,本篇最难的是迭代器的实现,这是本篇的核心知识。
我们知道迭代器的本质就是指针,难道说我们直接在红黑树中定义一个名为iterator的节点指针,之后再实现其他方法吗?但是大家都用过迭代器,这里以list举例,一般用法为(当然你可能会说我一般是使用范围for,但是我们一般想控制具体一点会使用如下方法):
int main()
{list<int> l = { 1, 2, 3 };list<int>::iterator it = l.begin();while (it != l.end()){cout << *it << " ";++it;}return 0;
}我们对it做了解引用,可以发现它就是指针,而且可以++。这里我们想对map和set也实现迭代器该怎么办呢?对了,还是对红黑树实现迭代器,而map和set调用红黑树迭代器。
这里我们如何对红黑树实现迭代器呢?在里面定义指针之后实现类似的方法吗?
不,这样做并不好,我们要将其解耦,也就是说,再定义一个类来专门实现迭代器。
问题接踵而至,这个模板参数该是什么呢?既然是一个指针,指针里存放的是树节点,所以T即可。里面的成员变量就是RBTreeNode的指针。为了方便操作,我们将其声明为结构体。
//定义迭代器
template<class T>
struct RBTreeIterator
{//或者使用 typedef RBTreeNode<T> Node; 看个人习惯using Node = RBTreeNode<T>;//为了减少代码量 重命名RBTreeIteratorusing Self = RBTreeIterator;Node* _node = nullptr;
};这里我们迭代器的模型就构建好了,之后我们就要实现++、!=、*、->、--等运算符的重载了。
但是现行暂停,我们思考一下,我们平时是这样赋值迭代器的:
//拿刚才的list举例 l 是list对象
list<int>::iterator it = l.begin();这就说明begin是一个方法,并且在list中已经被定义了。所以这里我们先在红黑树中定义这个begin方法。我们知道,begin返回的就是这个数据结构中第一个数据的位置,此时我们数据结构是红黑树,它的第一个节点位置在哪里?
中序遍历的第一个位置,也就是最小节点;但是我们要用中序递归方式找吗?仔细思考发现它也是树中最左边的节点,这个就很好找,所以我们现在RBTree中将RBTreeIterator重命名为Iterator,之后实现Begin方法。
template<class K, class T, class KeyOfT>
class RBTree
{
public://对RBTreeNode进行重命名using Node = RBTreeNode<T>;//重命名RBTreeIterator 为 Iteratortypedef RBTreeIterator<T> Iterator;//实现Begin方法Iterator Begin(){//找最左边节点Node* leftMost = _root;while (leftMost->_left){leftMost = leftMost->_left;}//返回的是迭代器 需要调用其构造方法return Iterator(leftMost);}//...
};而对于End方法,也非常简单,我们知道是最后一个节点的下一个位置,其实也就是空指针,所以我们补充End方法。
Iterator End()
{return Iterator(nullptr);
}tips:为了将其和set、map区分,这里使用大写来定义该方法。
返回的类型当然是迭代器类型,因为我们一会还有对这个迭代器进行++等操作。但是我们刚才在迭代器中没有写构造方法,所以补充上去:
//定义迭代器
template<class T>
struct RBTreeIterator
{//或者使用 typedef RBTreeNode<T> Node; 看个人习惯using Node = RBTreeNode<T>;//为了减少代码量 重命名RBTreeIteratorusing Self = RBTreeIterator;//构造方法RBTreeIterator(Node* node): _node(node){}Node* _node = nullptr;
};五:实现迭代器运算符的重载
1.++运算符重载
我们是中序遍历,下一个节点时什么?先来考虑最简单的情况,就是当前遍历节点就是中间节点,下一个节点就应该是右子树的最左边节点:
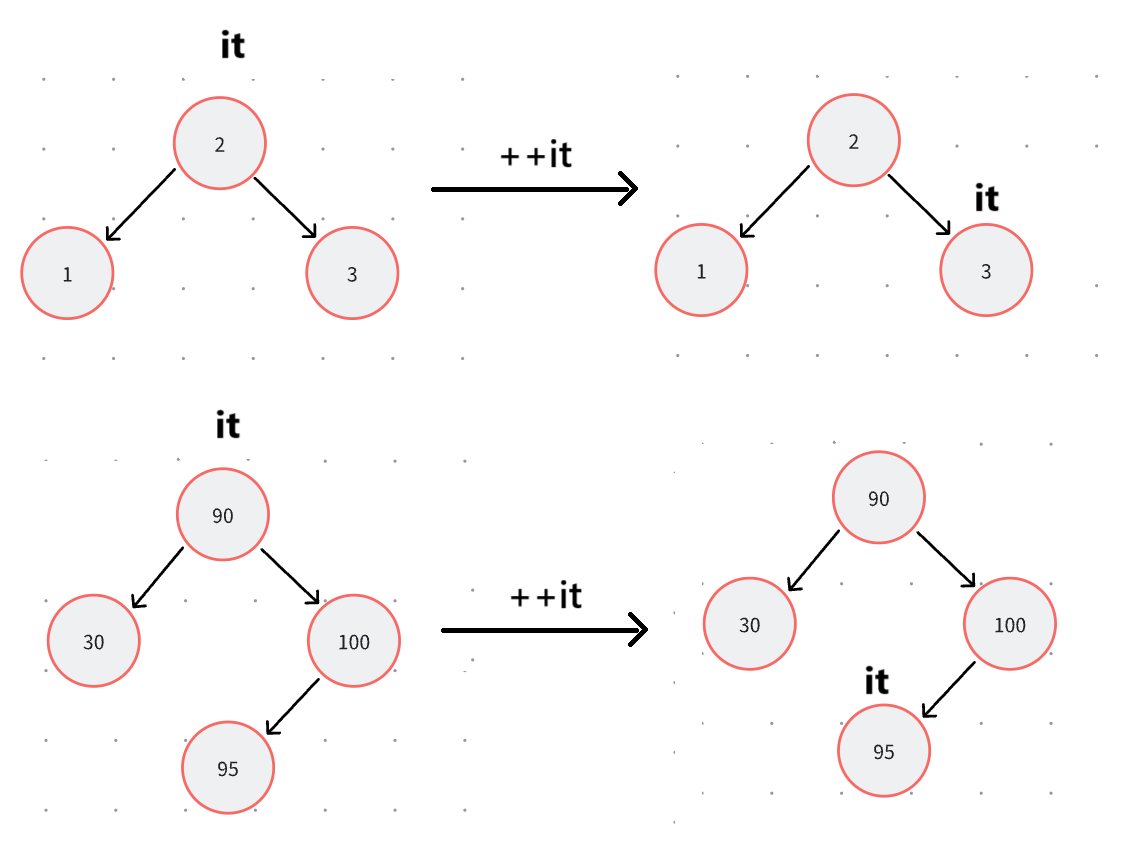
对,上面的情况就这么简单。但是如果右子树为空呢?下图我们只关心如何++,不关心是否为红黑树。
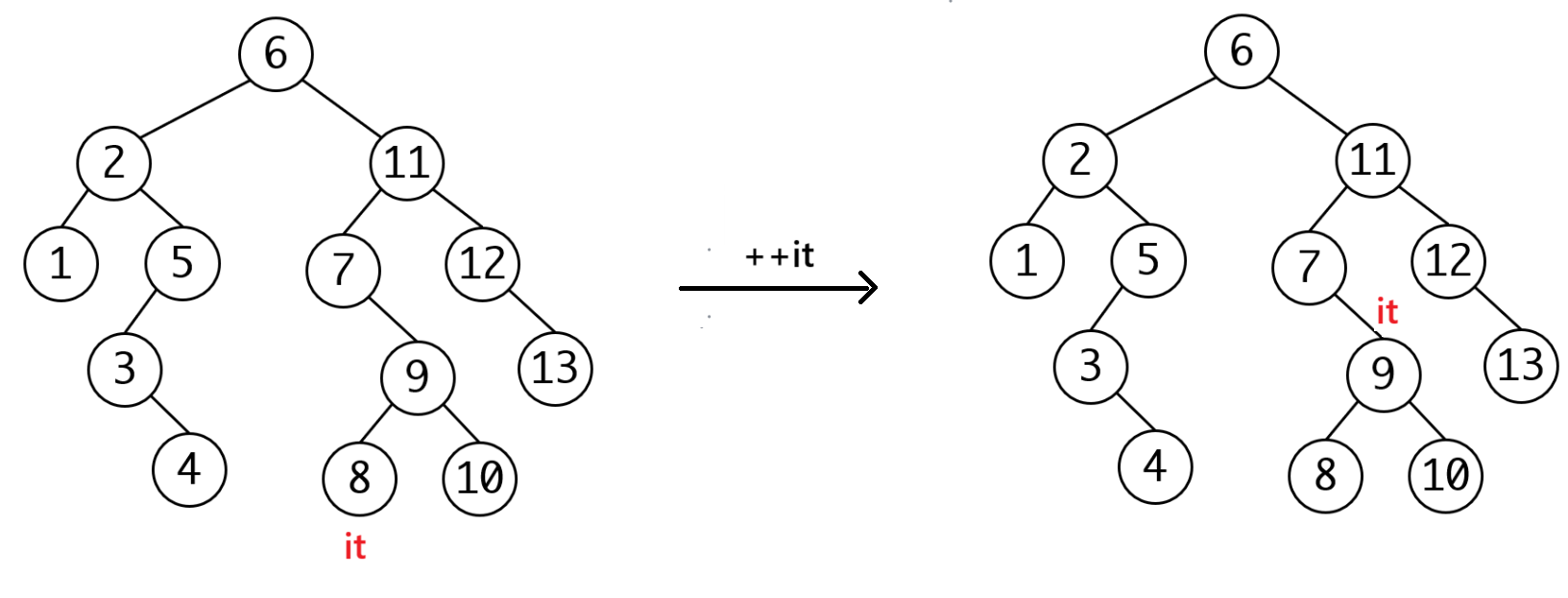
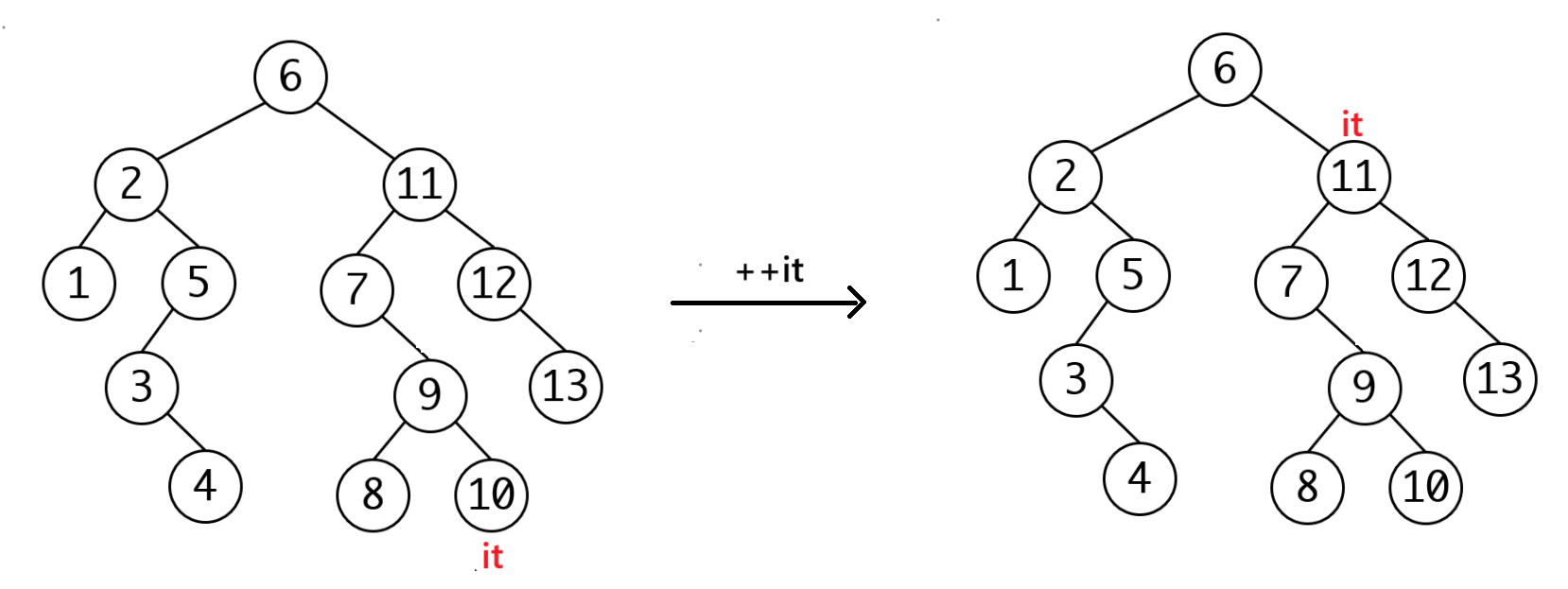
可以发现这其实是一个循环,假设当前it处于cur位置,我们定义一个parent节点(也就是parent = cur->_parent),之后当cur为parent->_left时跳出循环。当然要考虑parent为空的情况。
Self& operator++()
{if (_node->_right){//此时右子树不为空 找右子树最左边节点_node = _node->_right;while (_node->_left){_node = _node->_left;}}else{//右子树为空Node* cur = _node;Node* parent = cur->_parent;//parent可能为空while (parent && cur != parent->_left){cur = parent;parent = cur->_parent;}_node = parent; //记得更改_node 赋值为parent}return *this;
}2.==和!=运算符重载
bool operator!=(const Self& s)
{return _node != s._node;
}bool operator==(const Self& s)
{return _node == s._node;
}3.实现->和*运算符重载
这个也能简单,解引用返回存储类型的引用;->返回类型的地址,也就是指针。
T& operator*()
{return _node->_data;
}T* operator->()
{return &_node->_data;
}到这里先暂停,我们要测试一下代码了,所以去set和map中实现迭代器。
这里先完善set中的迭代器并测试set是否正确。所以在set中添加代码:
typedef RBTree<K, K, SetOfK>::Iterator iterator;//实现begin
iterator begin()
{return _t.Begin();
}//实现end
iterator end()
{return _t.End();
}之后测试代码中测试范围for:
namespace bit
{void test_set(){set<int> s;int a[] = { 17, 18, 23, 34, 27, 15, 9, 6, 8, 5, 25 };for (auto e : a){cout << e << endl;s.insert(e);}for (auto e : s){cout << e << " ";}}
}int main()
{bit::test_set();//bit::test_map();return 0;
}我们避免程序直接崩溃,可以现重新生成解决方案,发现程序崩溃……哈哈,这里确实有一个坑。当我们在一个类中声明其他类时,编译器不知道这个类是静态成员还是类型,所以用typename明确指出这是一个类型。
当然还有另外一个解释:因为此时没有实例化RBTree 不知道是什么类型,编译无法通过。所以加上typename在编译的时候确定类型。
补充(来自AI):
核心机制:
模板的二次编译机制:
模板会经历 第一次语法检查(看到模板定义时)和 第二次实例化检查(具体调用时)。
在第一次检查时,编译器并不知道
T::NestedType是什么(因为T尚未确定),所以需要typename明确告诉编译器:"这是一个类型,你先别报错,等实例化时再确认"。
typename的本质作用:
不是让编译器"先不填充类型",而是解决 语法歧义。
在没有
typename时,T::NestedType可能被误认为是静态成员变量(例如T::value),导致语法解析错误。typename强制声明这是一个类型。
所以此时我们在set中定义迭代器时加上typename即可通过编译:
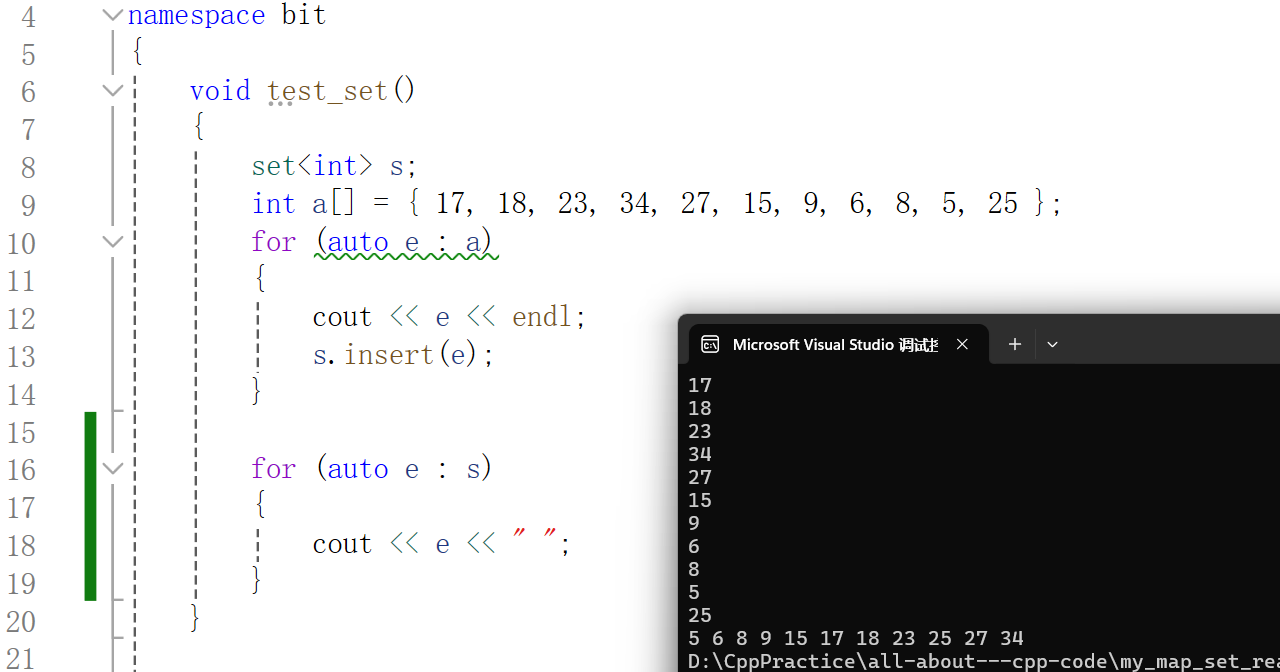
typedef typename RBTree<K, K, SetOfK>::Iterator iterator;此时运行代码输出结果为:
之后就是map的迭代器这里不再赘述。
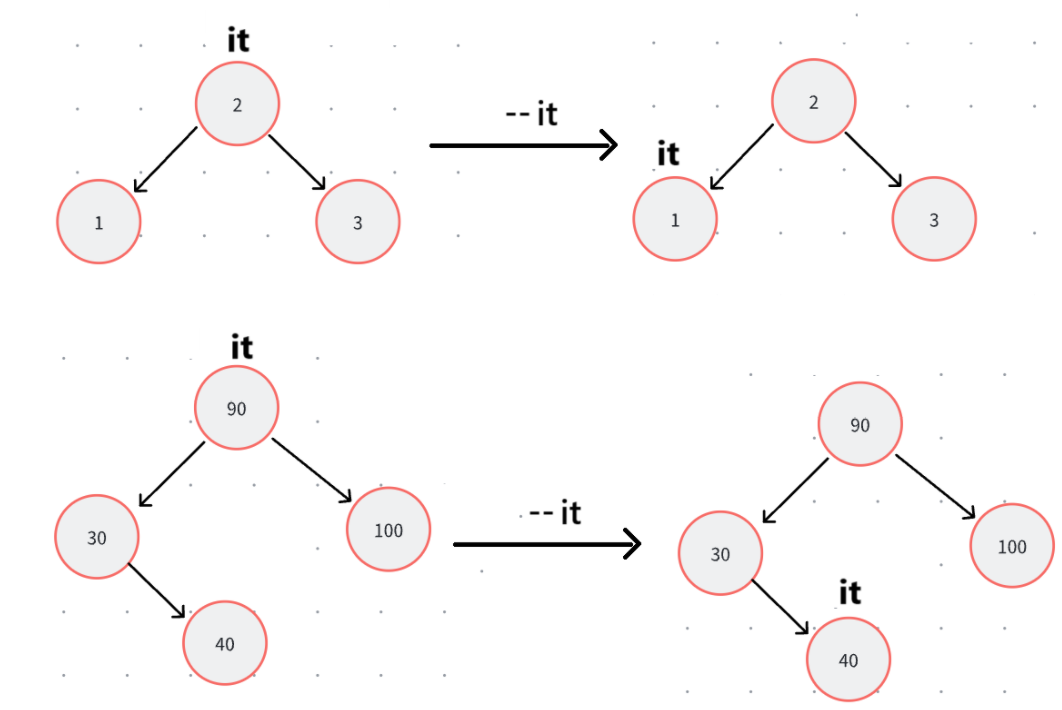
4.--运算符重载
这里我们给自己上上强度,多加一个--运算符重载,说白了就是和++哪里镜像的。但是最开始传入的是End,所以我们要先找最右边节点,也就是判断是否为空,之后赋值。
其他情况,我们先看是否有左子树,有左子树就是左子树最右节点:
当没有左子树的时候,和++一样,找第一个cur == parent->_right:
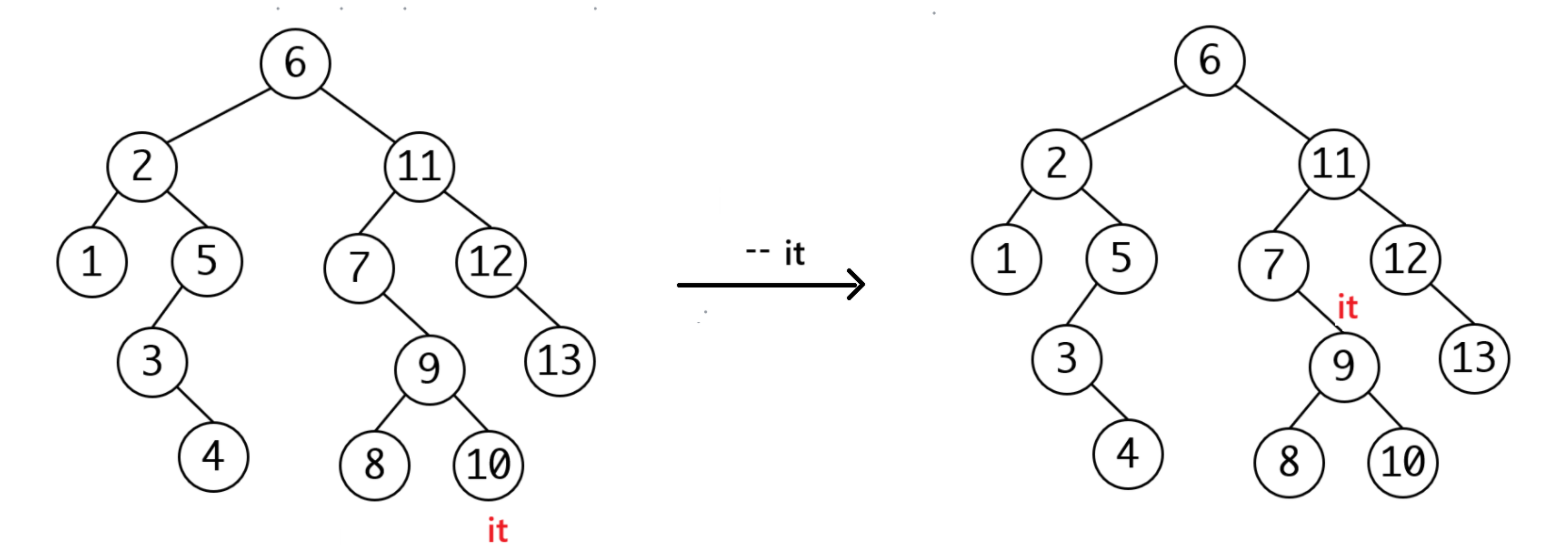
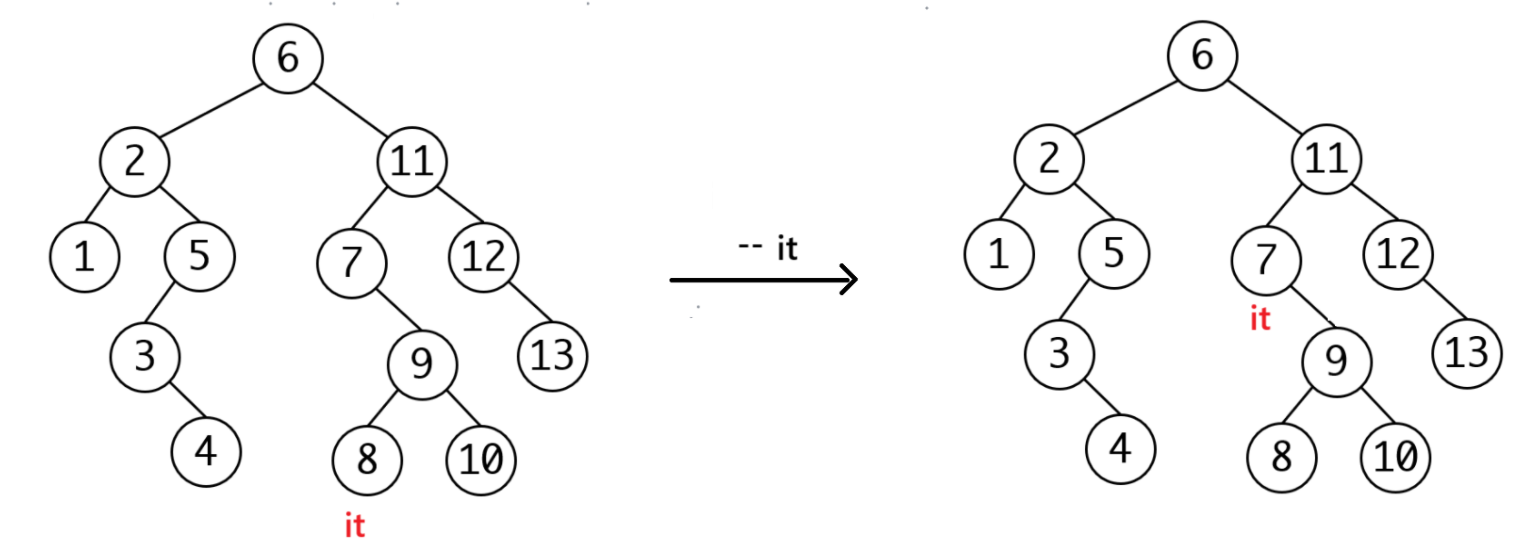
OK,当你开始写--的时候,第一步判空,此时新的问题出现了,我们要找树的根节点,但是我们不知道树的根节点!(没想到吧,我们又要修改参数了,呜呜~~我都要哭了……啊啊啊!)
此时我们应该怎么解决?也就是对RBTreeIterator多增加一个参数,也就是要记录根节点。
//定义迭代器
template<class T>
struct RBTreeIterator
{//...//多定义一个成员 专门记录根节点Node* _root = nullptr;
};所以此时RBTreeIterator的构造方法也要修改。
//定义迭代器
template<class T>
struct RBTreeIterator
{//构造方法 //向构造方法多增加root赋值RBTreeIterator(Node* node, Node* root): _node(node), _root(root){}//...//多定义一个成员 专门记录根节点Node* _root = nullptr;
};那么之前在红黑树中的Begin和End都需要多传入_root参数。
//实现Begin方法
Iterator Begin()
{//找最左边节点Node* leftMost = _root;while (leftMost->_left){leftMost = leftMost->_left;}//返回的是迭代器 需要调用其构造方法return Iterator(leftMost, _root);
}Iterator End()
{return Iterator(nullptr, _root);
}此时我们就可以拿到根节点了,同时也可以开始完善--运算符重载了。根据之前的图像,可以写出以下代码:
Self& operator--()
{if (_node == nullptr){//找最右边节点Node* rightMost = _root;while (rightMost->_right){rightMost = rightMost->_right;}_node = rightMost;}else if (_node->_left) //此时有左子树{//找左子树最右节点Node* rightMost = _node->_left;while (rightMost->_right){rightMost = rightMost->_right;}_node = rightMost;}else{//此时没有右子树Node* cur = _node;Node* parent = cur->_parent; //此时要找第一个cur == parent->_right 且parent存在while (parent && cur != parent->_right){cur = parent;parent = cur->_parent;}_node = parent;}return *this;
}之后我们还拿set来做实验,这次我们倒序遍历,但是注意应该先--it迭代器,因为最开始指向空。
void test_set()
{set<int> s;int a[] = { 17, 18, 23, 34, 27, 15, 9, 6, 8, 5, 25 };for (auto e : a){//cout << e << endl;s.insert(e);}for (auto e : s){cout << e << " ";}cout << endl;//倒着遍历set<int>::iterator it = s.end();while (it != s.begin()){//最开始是 nullptr 所以先----it;cout << *it << " ";}cout << endl;
}测试结果:
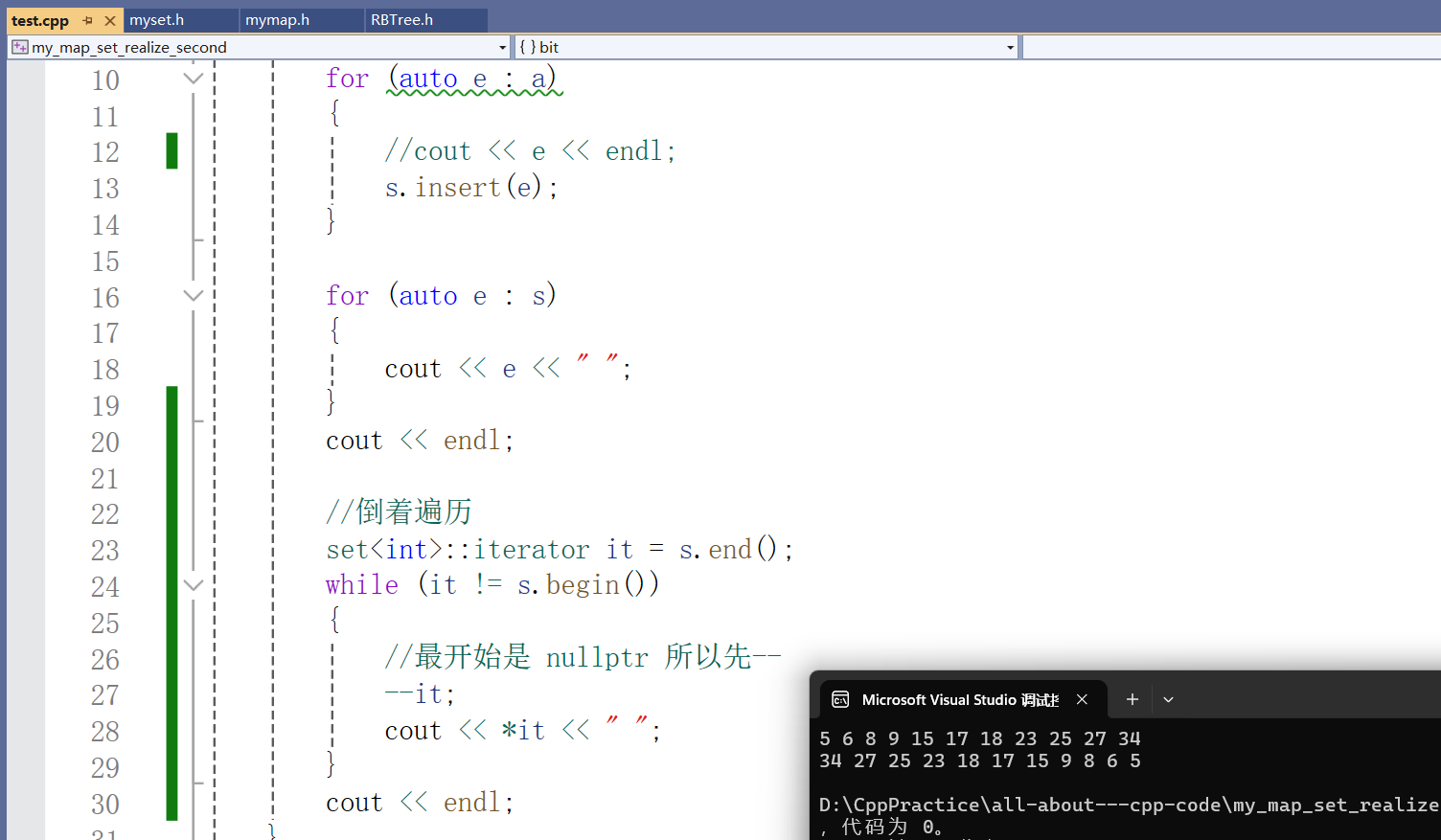
此时我们就几乎实现了所有关于迭代器的基本操作。
六:实现包括const版本的迭代器
注意我上面说的是迭代器基本操作,但是我们知道,底层还存在const_iterator。我们上面实现的迭代器是可以通过解引用来改变里面指向的内容的。但是底层有const_iterator是不允许修改其指向的内容的。
这里我们先区分 int* const 和 const int* 的区别。
- int* const : 指的是指针不能修改,指向的值可以修改。
- const int* : 指的是指针可以修改,指向的值不能修改。
所以 const_iterator 本质上就是 const int*。
这时聪明的你想到了,那么我们在写一个ConstRBTreeIterator类,把里面的模板参数都写成const类型可不可以呢?当然可以,比如:
template<class T>
struct ConstRBTreeIterator
{//... 与RBTreeIterator代码全部相同//唯一不同的是 * -> 的重载const T& operator*(){return _node->_data;}const T* operator->(){return &_node->_data;}
};不对劲,你发现只有两个运算符重载不一样,难道为了碟醋,包一盘饺子?这太冗余了。
我们知道模板参数可以像函数传参一样使用,既然只有这两个参数不一样,那是否可以考虑当传入的时候就告知应该生成谁。这里一个是引用,一个是指针。所以我们可以修改RBTreeIterator参数,多传入两个参数,一个是T的应用,一个是T的指针,这样我们就可以减少代码量了。
//定义迭代器 引用 指针
template<class T, class Ref, class Ptr>
struct RBTreeIterator
{//修改位置Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}
};所以说RBTree中传入的模板参数也要修改,并且多定义一个ConstIterator类型:
template<class K, class T, class KeyOfT>
class RBTree
{
public://对RBTreeNode进行重命名using Node = RBTreeNode<T>;//重命名RBTreeIterator 为 Iteratortypedef RBTreeIterator<T, T&, T*> Iterator;typedef RBTreeIterator<T, const T&, const T*> ConstIterator;//...
};这里你会很迷,什么钩八?看图:
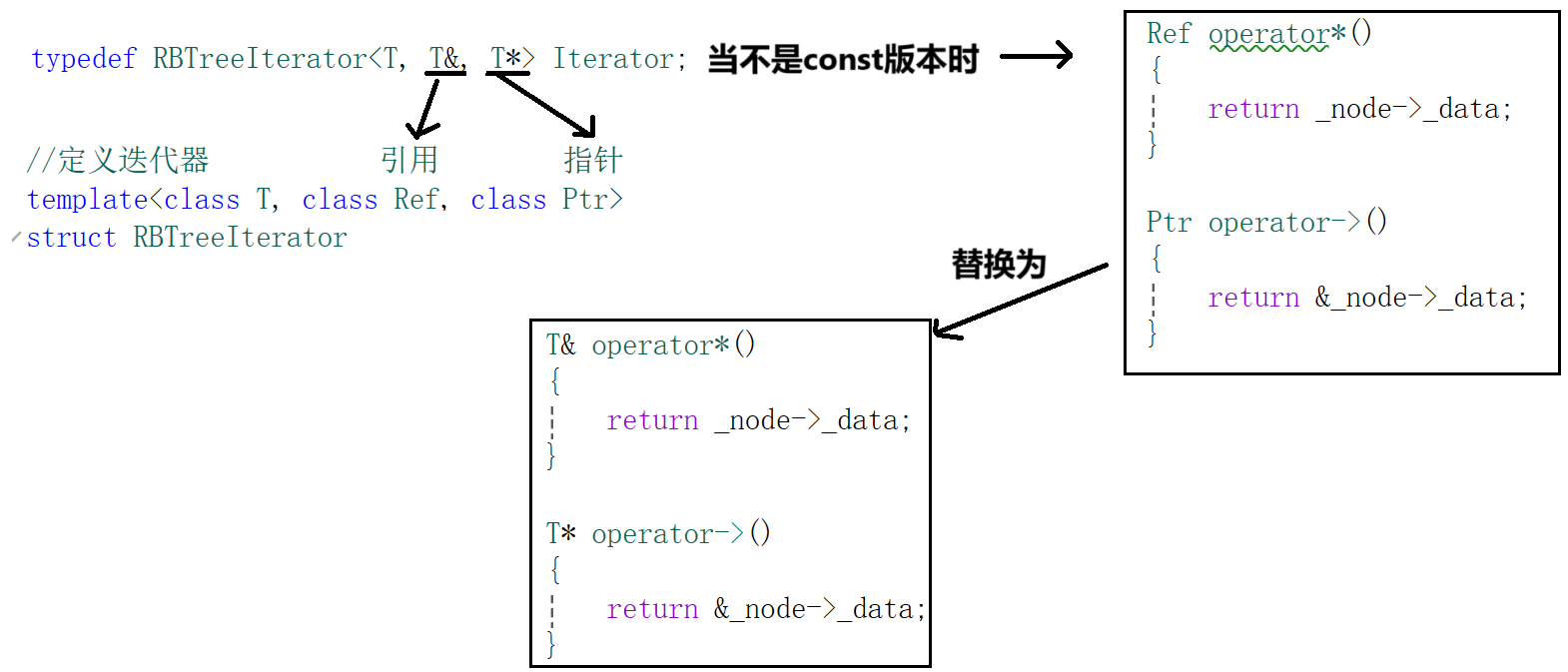
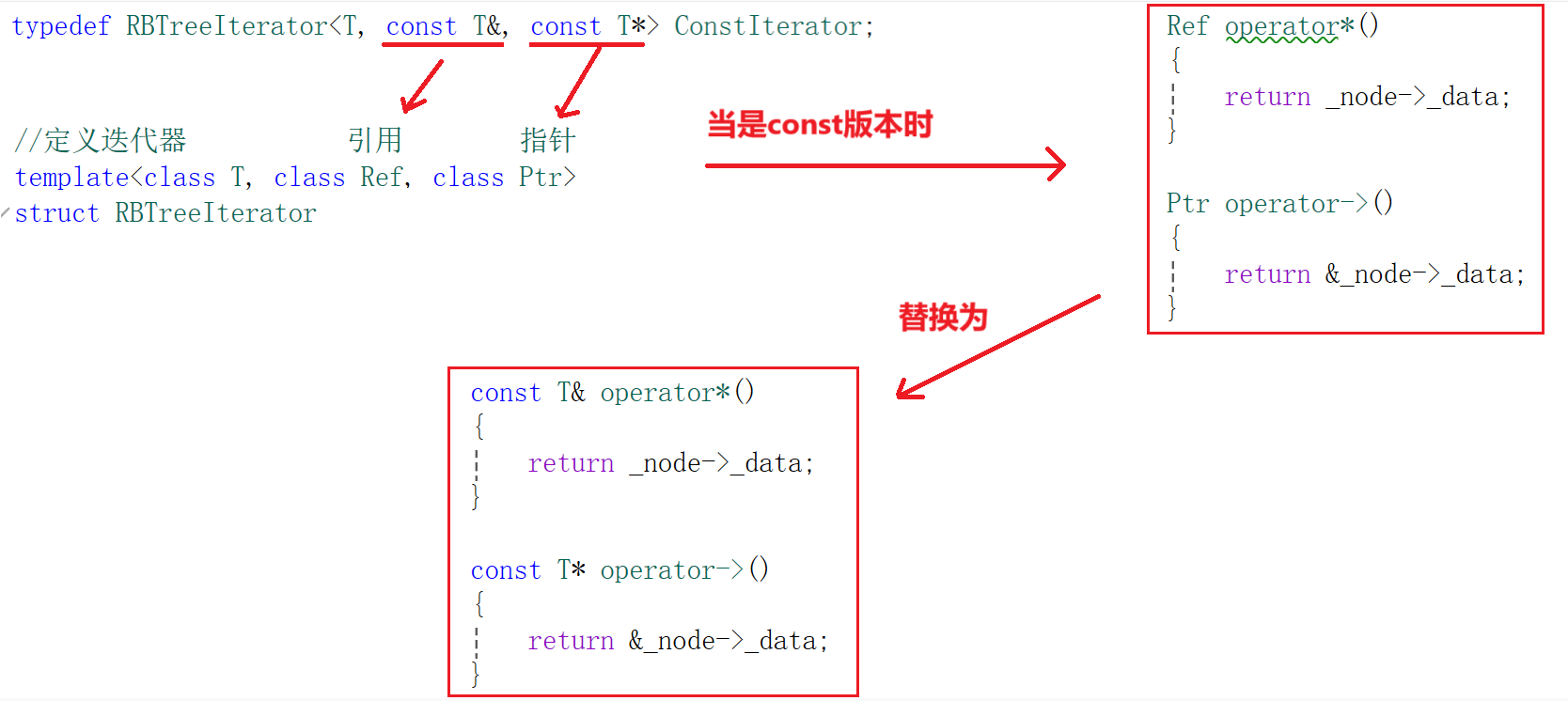
所以我们通过修改传入参数从而实现对const版本和非const版本的操作。此时我们依旧是先实现set中的const_iterator。
template<class K>
class set
{//...
public:typedef typename RBTree<K, K, SetOfK>::Iterator iterator;typedef typename RBTree<K, K, SetOfK>::ConstIterator const_iterator;//实现beginiterator begin(){return _t.Begin();}//实现enditerator end(){return _t.End();}//实现begin const版本const_iterator begin() const{return _t.Begin();}//实现end const版本const_iterator end() const{return _t.End();}//...
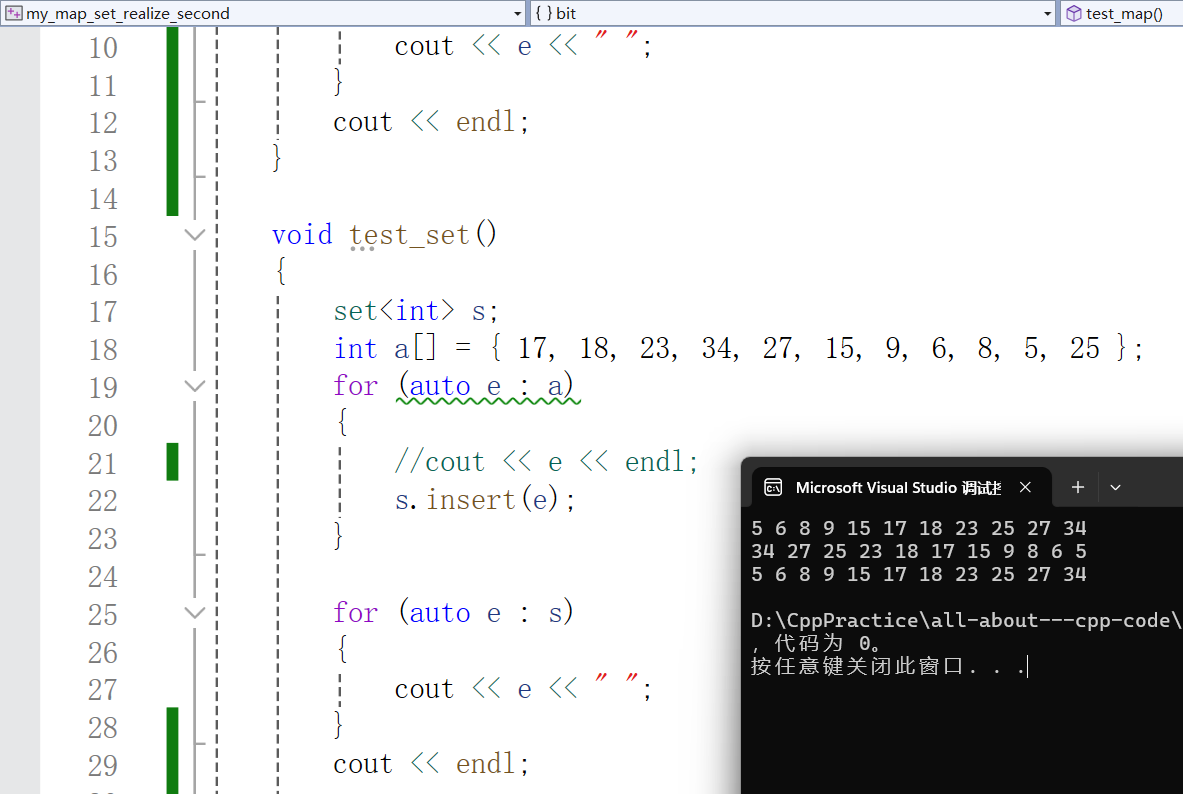
};如何测试呢?我们在bit命名空间中,添加FuncSet函数,它的参数是const set<int>& s即可,这就是常量类型,不可修改。所以如下:
void FuncSet(const set<int>& s)
{for (auto e : s){cout << e << " ";}cout << endl;
}void test_set()
{set<int> s;int a[] = { 17, 18, 23, 34, 27, 15, 9, 6, 8, 5, 25 };for (auto e : a){//cout << e << endl;s.insert(e);}for (auto e : s){cout << e << " ";}cout << endl;//倒着遍历set<int>::iterator it = s.end();while (it != s.begin()){//最开始是 nullptr 所以先----it;cout << *it << " ";}cout << endl;FuncSet(s);
}结果如下:
之后补充map的代码:
template<class K, class V>
class map
{//...
public:typedef typename RBTree<K, pair<K, V>, MapOfK>::Iterator iterator;typedef typename RBTree<K, pair<K, V>, MapOfK>::ConstIterator const_iterator;//实现beginiterator begin(){return _t.Begin();}//实现enditerator end(){return _t.End();}//实现begin const版本const_iterator begin() const{return _t.Begin();}//实现end const版本const_iterator end() const{return _t.End();}//...
};七:修改Insert
之前我们在set和map篇中讲到过,他们的insert方法并不是简单的返回bool。而是一个迭代器,插入节点不存在返回该插入节点的迭代器;存在返回这个位置的迭代器。返回的类型时pair类型(具体细节可以看我的上一篇文章) 。所以我们要修改红色树中的Insert方法。
//插入
pair<Iterator, bool> Insert(const T& data)
{if (_root == nullptr){Node* newNode = new Node(data);_root = newNode;_root->_col = BLACK; //更新根节点 并置为黑色// return true;return make_pair(Iterator(newNode, _root), true);}Node* parent = nullptr;Node* cur = _root;while (cur){//if (kv.first > cur->_kv.first)if (kot(data) > kot(cur->_data)){parent = cur;cur = cur->_right;}//else if (kv.first < cur->_kv.first)else if (kot(data) < kot(cur->_data)){parent = cur;cur = cur->_left;}else{//已经存在该值了 不处理//return false;return make_pair(Iterator(cur, _root), false);}}//新建节点cur = new Node(data);//if (kv.first > parent->_kv.first)if (kot(data) > kot(parent->_data)){parent->_right = cur;}else{parent->_left = cur;}cur->_parent = parent; //记得更新父节点if (parent->_col == BLACK){//return true;return make_pair(Iterator(cur, _root), true);}else{//...}//最后都时 _root->_col = BLACK 即可_root->_col = BLACK;//return true;return make_pair(Iterator(cur, _root), true);
}所以我们也要修改map和set中的insert方法返回值(大家自行修改吧)。
之后再test_map函数中增加以下代码,测试insert函数:
//第一次插入90这个键
cout << "第一次插入90这个键" << endl;
pair<map<int, int>::iterator, bool> p = m.insert({90, 100});
cout << p.first->first << ":" << p.first->second << endl;
cout << p.second << endl;cout << "第二次插入90这个键" << endl;
p = m.insert({ 90, 30 });
cout << p.first->first << ":" << p.first->second << endl;
cout << p.second << endl;运行结果:

八:实现map中[ ]的重载
我们在上一篇讲到了[ ],但是那里没有讲的很清楚,[ ]可以充当insert,也可以查找键对应的值;更可以修改键对应的值,这和它的实现有关,我们先上代码:
V& operator[](const K& key)
{iterator it = insert(make_pair(key, V())).first;return it->second;
}新增test_map1函数:
void test_map1()
{map<std::string, std::string> dict;dict.insert({ "sort", "排序" });dict.insert({ "left", "左边" });dict.insert({ "right", "右边" });dict["left"] = "左边,剩余"; //修改dict["insert"] = "插入"; //插入dict["value"]; //插入 string使用默认构造map<string, string>::iterator it = dict.begin();while (it != dict.end()){cout << it->first << ":" << it->second << endl;++it;}cout << endl;
}运行结果:
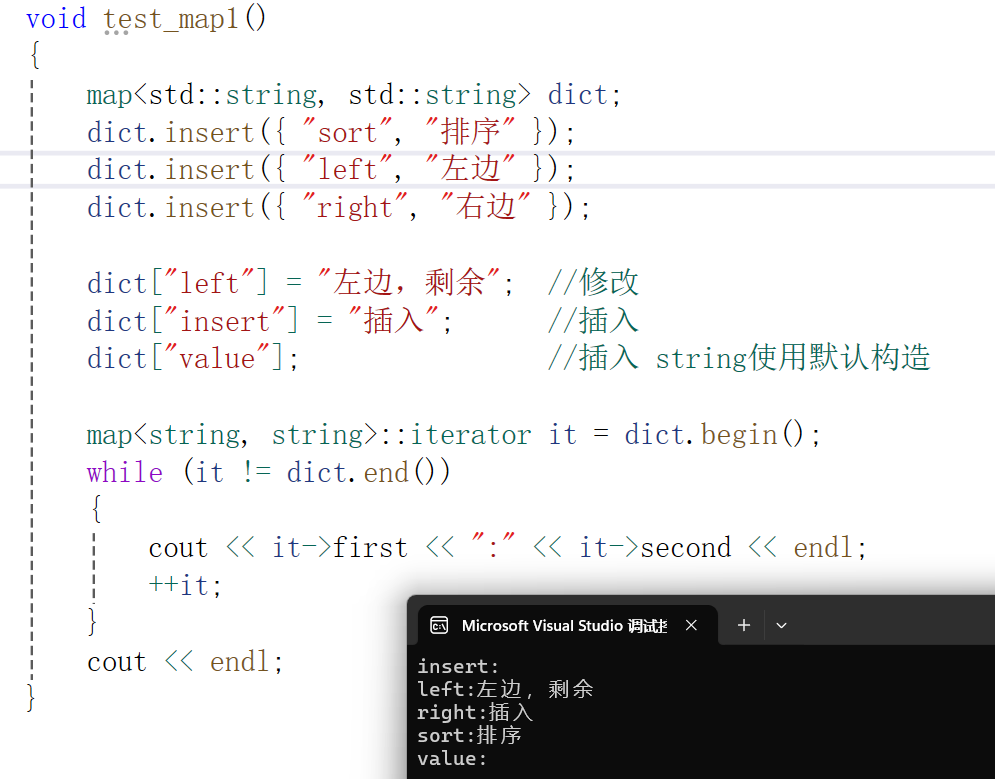
你肯定好奇,为什么能修改对应的值?为什么我们能直接插入。首先我们封装的[ ]里面复用的是insert,我们在insert中传入的参数对应的值是调用的默认构造,之后我们返回的first拿iterator接收,之后通过iterator重载的->拿到对应的值(second),可以看到返回的是引用。以至于在外部使用=可以修改对应的值!

总结:
这一篇内容其实很难,这里算法是基础,语言比算法还要难。大家不要眼高手低,实现了才知道有多难,多有成就感。最初小编实现的时候全是BUG,这个比红黑树好一点,算法的BUG可能一找要找半个小时,而这个也全是BUG,找得快,但是多。多敲两边你会发现你的C++代码能力突飞猛进,这一章包含了很多基础语法和C++特性,大家不要偷懒!


显示模式设置)


)

内部RTC实时时钟及实战含源码)


图像与通道拼接函数-----将 4 个单通道图像矩阵 (GMat) 合并为一个 4 通道的多通道图像矩阵函数merge4())







)
![【原创开发】无印去水印[特殊字符]短视频去水印工具[特殊字符]支持一键批量解析](http://pic.xiahunao.cn/【原创开发】无印去水印[特殊字符]短视频去水印工具[特殊字符]支持一键批量解析)