Qwen3简介:大型语言模型的革命
Qwen系列语言模型的最新发布——Qwen3,标志着人工智能(AI)技术的一次重大飞跃。基于前代版本的成功,Qwen3在架构、推理能力和多项先进功能上都取得了显著提升,正在重新定义大型语言模型(LLM)在各个领域的应用。

在本文中,我们将深入探讨Qwen3的关键特性、性能表现、部署方式,以及如何利用这一强大的模型推动你的项目。
Qwen3的关键特性
1. 多样化的模型配置,满足不同需求
Qwen3提供了稠密(Dense)和专家混合(MoE)两种配置。无论是需要处理小规模任务的用户,还是追求高吞吐量的企业,Qwen3都能够提供适配的解决方案。模型的尺寸范围从小型(0.6B)到超大规模(235B-A22B),满足了不同场景的需求。
2. 无缝切换思维模式
Qwen3的一个亮点特性是能够在思维模式和非思维模式之间无缝切换。在思维模式下,Qwen3擅长复杂的推理任务,如数学计算、代码生成和逻辑推理。而在非思维模式下,Qwen3优化了常规对话和任务处理的效率,能够更快速地进行一般性交流。这种灵活性使得Qwen3能够在不同任务间自如转换,不会牺牲性能。
3. 卓越的推理能力
Qwen3在推理能力上相比前代(如QwQ和Qwen2.5)有了显著的提升。在思维模式和非思维模式下,Qwen3在代码生成、数学推理和常识逻辑推理等领域表现出色,超越了以往的模型,展现了强大的多任务处理能力。
4. 支持多语言
Qwen3支持100多种语言和方言,尤其在多语言指令跟随和翻译任务上表现尤为突出。这使得Qwen3成为全球化应用中处理语言问题的理想选择,能够满足来自不同语言用户的需求。
5. 更好的用户偏好对齐
Qwen3在创意写作、角色扮演、多人对话和指令跟随等任务中表现出色,能够提供更加自然、流畅的对话体验。通过精细的用户偏好对齐,Qwen3在这些领域实现了更高的表现,使其成为极具沉浸感的对话式AI。
Qwen3的性能
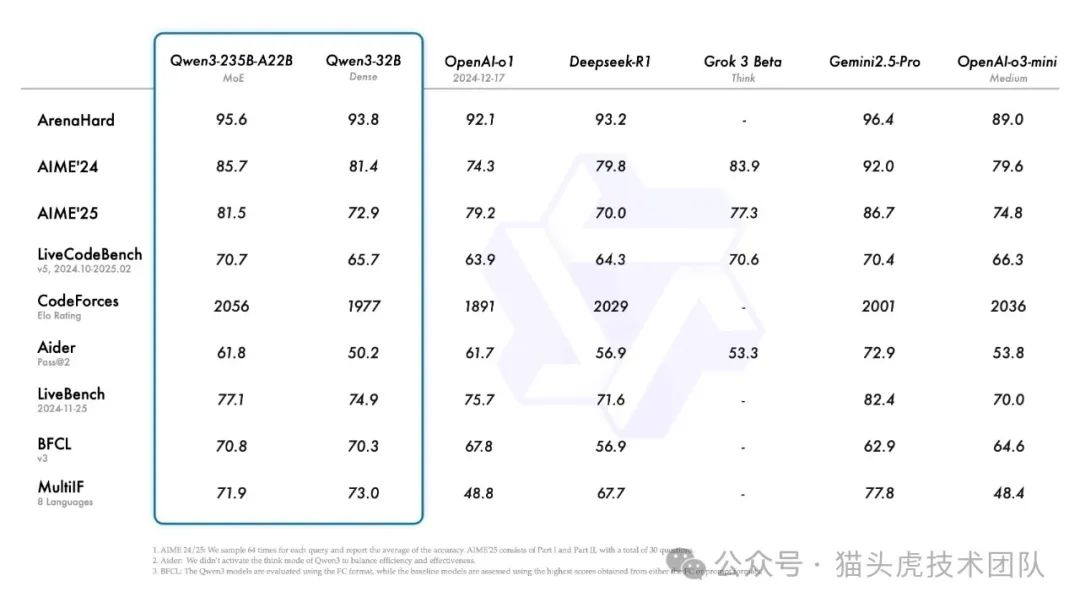
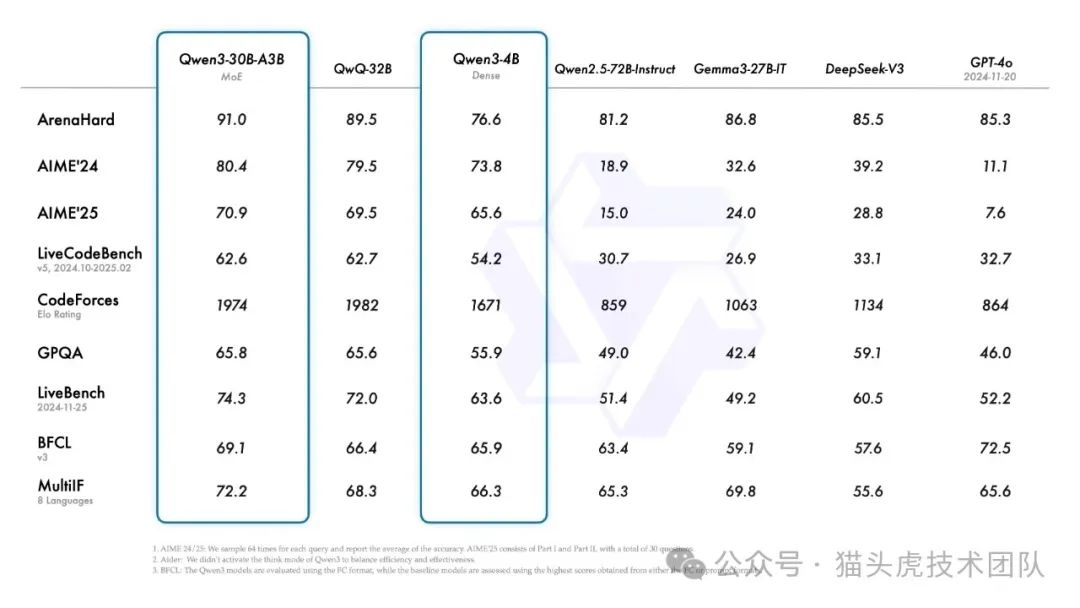
Qwen3在多个领域表现出了强大的性能,无论是在推理效率还是计算能力方面,都展现了卓越的优势。模型支持大规模推理,用户可以根据需求选择不同的计算资源。详细的性能评估结果可以参考官方的博客。
如何运行Qwen3
🤗 使用Transformers
Qwen3兼容流行的Transformers库,允许用户轻松地进行推理和训练。你可以直接使用以下代码示例来生成基于输入的内容。
from transformers import AutoModelForCausalLM, AutoTokenizer# 加载模型和分词器
model_name = "Qwen/Qwen3-8B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")# 准备输入
prompt = "简短介绍一下大型语言模型。"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # 切换思维模式
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)# 执行文本生成
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
print(tokenizer.decode(output_ids, skip_special_tokens=True))
使用ModelScope
对于中国大陆用户,推荐使用ModelScope,它提供类似Transformers的Python API,并解决了下载模型检查点的问题。
使用llama.cpp
llama.cpp能够在各种硬件上进行高效的LLM推理,并且支持Qwen3模型。
部署Qwen3
Qwen3支持多个推理框架,包括SGLang和vLLM,用户可以根据需求选择最适合的框架进行部署。
使用SGLang
SGLang是一个高效的推理框架,支持大规模语言模型。通过简单的命令即可启动一个支持OpenAI兼容API的服务。
python -m sglang.launch_server --model-path Qwen/Qwen3-8B --port 30000 --reasoning-parser qwen3
使用vLLM
vLLM是一个高吞吐量、内存高效的推理引擎,适合大规模LLM的部署。
vllm serve Qwen/Qwen3-8B --port 8000 --enable-reasoning-parser --reasoning-parser deepseek_r1
使用Qwen3进行开发
Qwen3支持工具调用(Tool Use),例如通过Qwen-Agent,可以为API添加额外的工具支持。此外,你还可以通过各种训练框架进行微调,以适应更特定的应用场景。
总结
Qwen3代表了语言模型技术的最新进展,它不仅在推理能力和多语言支持上有所突破,还在用户交互、推理效率和部署方式上提供了更多的选择。无论是在研究、开发还是商业应用中,Qwen3都能够提供强大的支持。
如果你希望在自己的项目中使用Qwen3,或者想要了解更多关于Qwen3的信息,欢迎访问Qwen3官网或查看官方文档。


:PL读写PS DDR(自定义IP核-AXI4接口))


注意力机制(第3/4集),位置编码)




马尔科夫决策过程(MDP))
——LeetCode45.跳跃游戏II763.划分字母区间)





:常见位运算操作总结)

