这是对Twitter 工作原理|架构解析|社交APP逻辑_哔哩哔哩_bilibili的学习,感谢up小凡生一
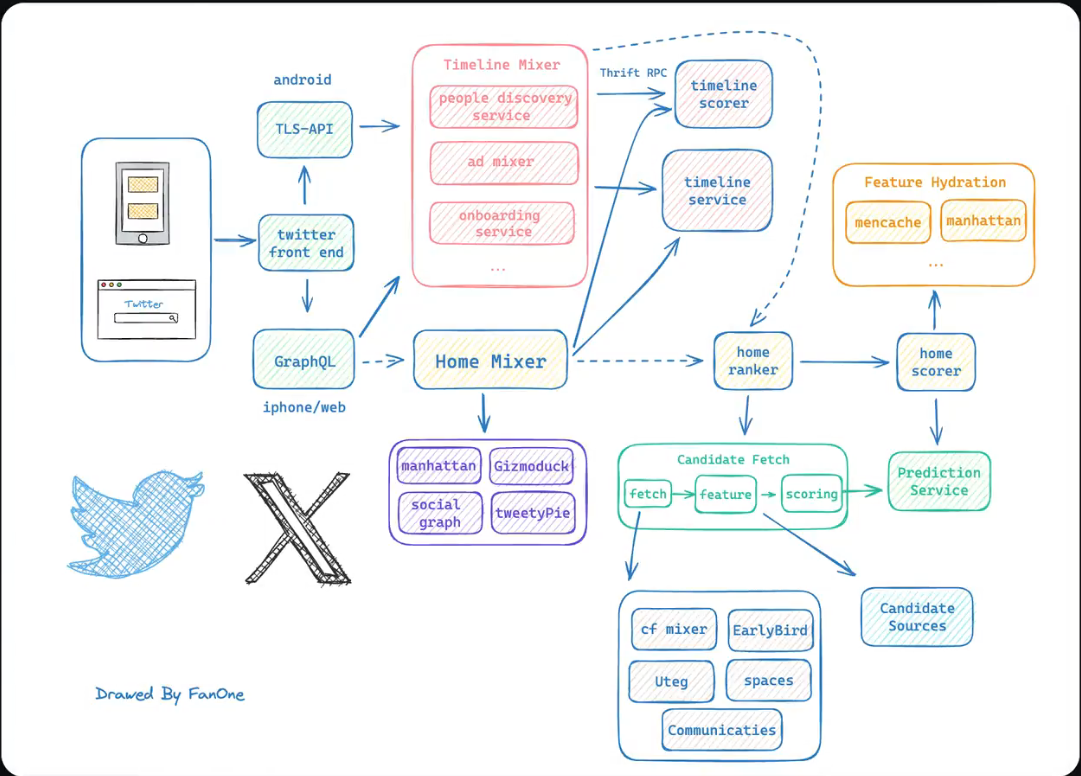
在两年半前,埃隆·马斯克收购了Twitter,并且进行了一系列重大改革。今天我们来解析一下这个全球知名社交平台的架构。首先,我们根据马斯克两年前晒出的草图来绘制一个大体的框架图。按照草图,Twitter的前端页面会根据来源判断,以不同方式向后端发送请求。如果是安卓设备,就通过T2S API请求后端;如果是苹果设备或Web端,就直接基于Web SQL发送请求给后端。Web SQL是一个类似JSON的数据结构。
T2S API有两种解释:一种说法是Twitter的经典传输层,安全的API网关系统,也就是沿用了HTTPS;另一种说法是T2S是Twitter系统的缩写,即Twitter的最初主业务。马斯克曾提到,可能会淘汰T2S API,因为只有当安卓应用程序使用超过一年后,才需要使用这个API。

接下来,我们来看Twitter的两个主要模块:“For you”和“Following”。这两个模块对应着以前的“Home”和“Letters”。“For you”模块根据用户平时浏览的内容推荐相似内容,也会有一些“Following”的内容。这样做的目的是为了提高留存率,因为“For you”大部分是推荐内容,如果推荐的内容不感兴趣,可能会导致点击率低,从而影响留存率。所以在召回时,会召回一些“Following”的内容,以保持留存率,并根据算法推送可能感兴趣的内容,来调整推荐和关注内容的比例。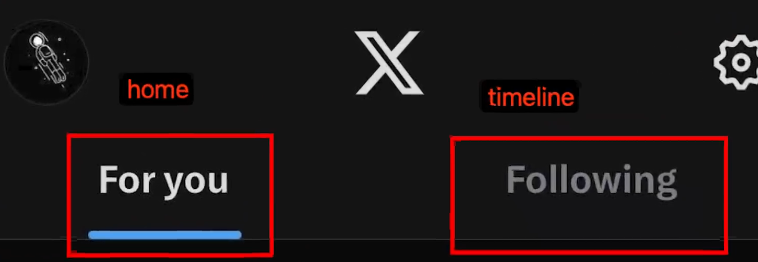
“Following”模块主要是关注的人发布的推文。我们了解了这两个模块后,来分析这两个模块。“Following”是时间轴模块,而时间轴模块是Twitter的核心模块,位于草图中间偏上的位置。时间轴上60%的推文来自于关注的人,推荐内容占20%,广告也占20%,然后基于此进行调整。

我们逐个分析小模块:
-
People discover:关注的人所发推文的服务。
-
Reservers:需要召回的广告,并且是该用户可能感兴趣的广告。这是Twitter主要的变现手段,马斯克也有补充,广告混合器可以大大提高相关性,并且用更少的曝光获取更多的点击。
-
On boring server:基于所关注的人去推荐新内容来扩展内容板块,也就是引流。
-
Ta scholar:对召回的推文广告新内容做打分进行排序,来决定展示在用户面前的顺序。排序非常重要,排在前面意味着有更高的曝光,可能带来更大的收益。
-
这几个小模块之间都是以微服务的形式做调用关系,多个微服务之间用的是Free RPC做RPC调用,主要由阿帕奇社区做维护。
总体来说,Twitter的架构和大部分推荐系统的架构相似。接下来我们来看Home页面,这部分其实和时间线也有类似的召回计算排序,只是召回和计算的重点不一,重点更多的放在了推荐上。不过这部分的计算要比探探模块要快,因为历史原因,导致它耐模块很难做变动,毕竟Home模块是比较新的模块。
接着来介绍一下存储介质:
-
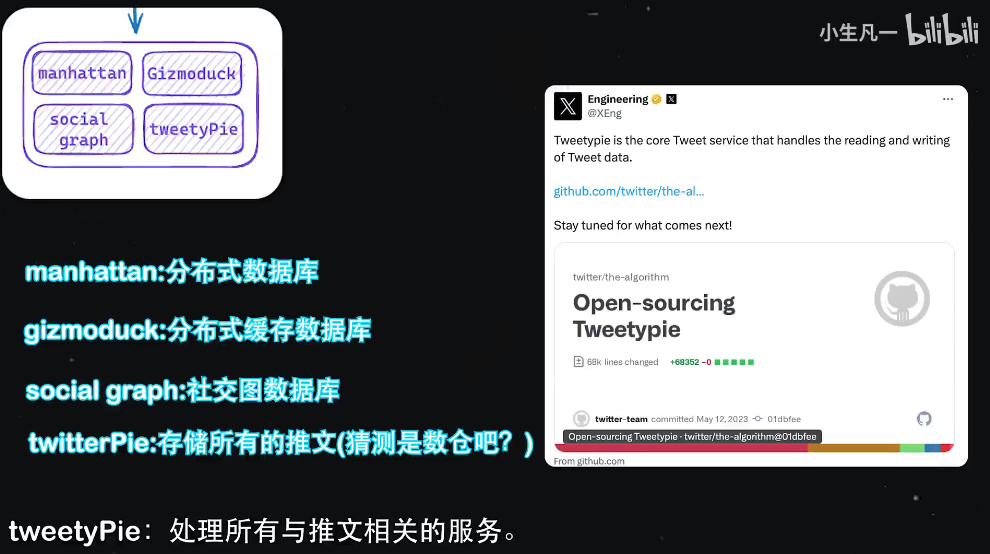
Manhattan:Twitter的分布式数据库,类似于一个分布式的MySQL。
-
GIS:Twitter的分布式缓存,类似于Redis。
-
Show show gap:我猜测是一个存储社交图数据库,存储用户和用户之间的联系,这样就不需要每一次召回的时候都计算一次用户和用户之间的关系了。

Twitter处理所有与推文相关的服务,然后到了推荐模块,这个模块在草图的右下角。推荐模块包括召回动作,尽可能的召回数据,然后进行特征提取,做特征工程,输出的特征是后续推荐系统的输入,也就是推荐系统会推出具备这些特征的内容,而这些内容是符合用户特征的,尽可能的留住用户。这些特征会根据fit的数据来做权重比例,而这个权重比例就会在下一个score环节做计算,来决定最终的排序。
-
Publication service:对用户特征进行预测,预测出可能会对哪一些特征感兴趣。
-
Future hydration:其实就是将用户的特征进行存储,方便快速调用。










))





删边?邻接矩阵/链表/十字链对比)



