此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第三课的第二周内容,2.4到2.6的内容。
本周为第三课的第二周内容,本周的内容关于在上周的基础上继续展开,并拓展介绍了几种“学习方法”,可以简单分为误差分析和学习方法两大部分。
其中,对于后者的的理解可能存在一些难度。同样,我会更多地补充基础知识和实例来帮助理解。
本篇的内容关于数据不匹配问题,是对在训练集和测试集的数据分布不同情况下的分析和处理措施。
1. 训练集和测试集分布不同时的数据集划分
学到现在,即便我们已经知道了很多提升模型性能的方法,但当提及这点时,我想第一个出现在我们脑海里的很可能还是增加数据量,尤其是对应神经网络而言。
模型就像一个对输入不断学习的学生,输入数据量就相当于他的”知识量“。因此,在绝大多数情况下,增加数据量都是一个好的选择,即使他带来的成本比其他方法要高。
但也同样如此,如何获取合适的、可用的数据就成了问题,我们以此来展开:
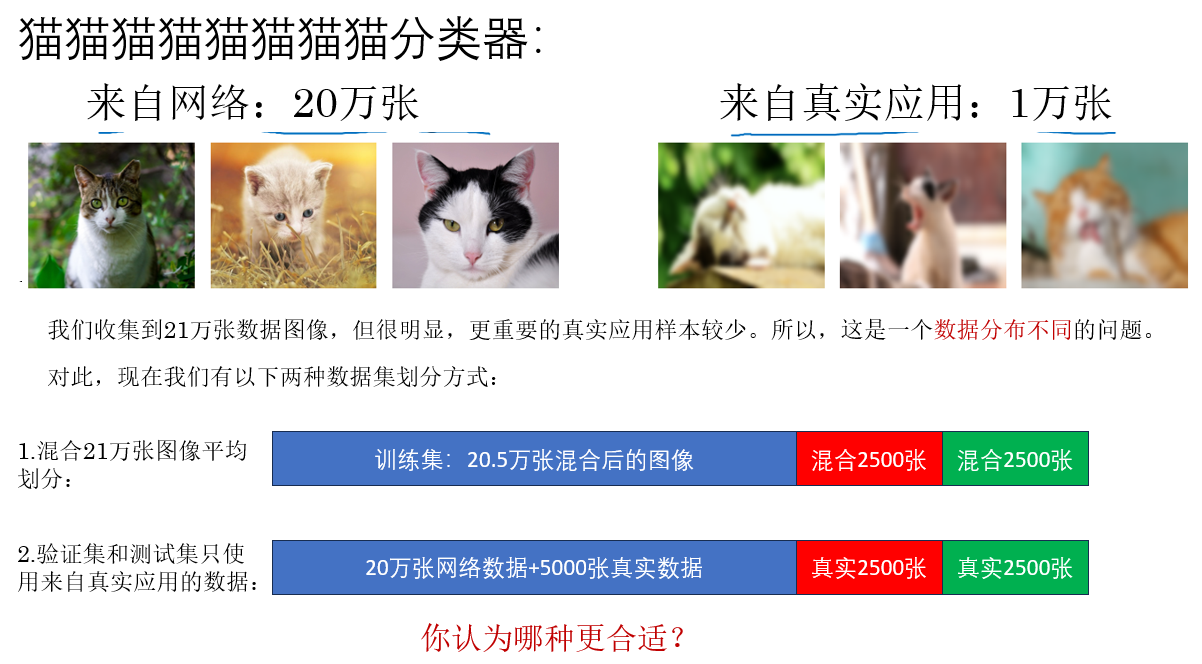
想来这个问题并不难,我们继续:
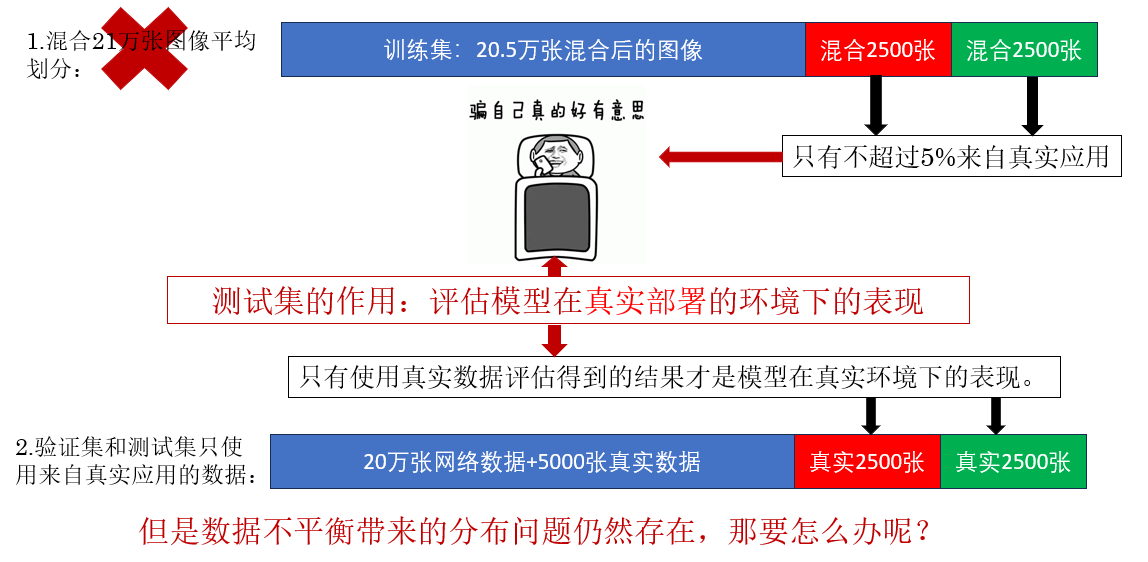
课程里还补充了一个汽车语音识别的例子,但是实际上都是一个意思,就不再重复了,我们来看看如何缓解数据不平衡带来的分布问题。
2.数据不平衡带来的分布问题
使用了较合理的数据集划分后,我们继续看:
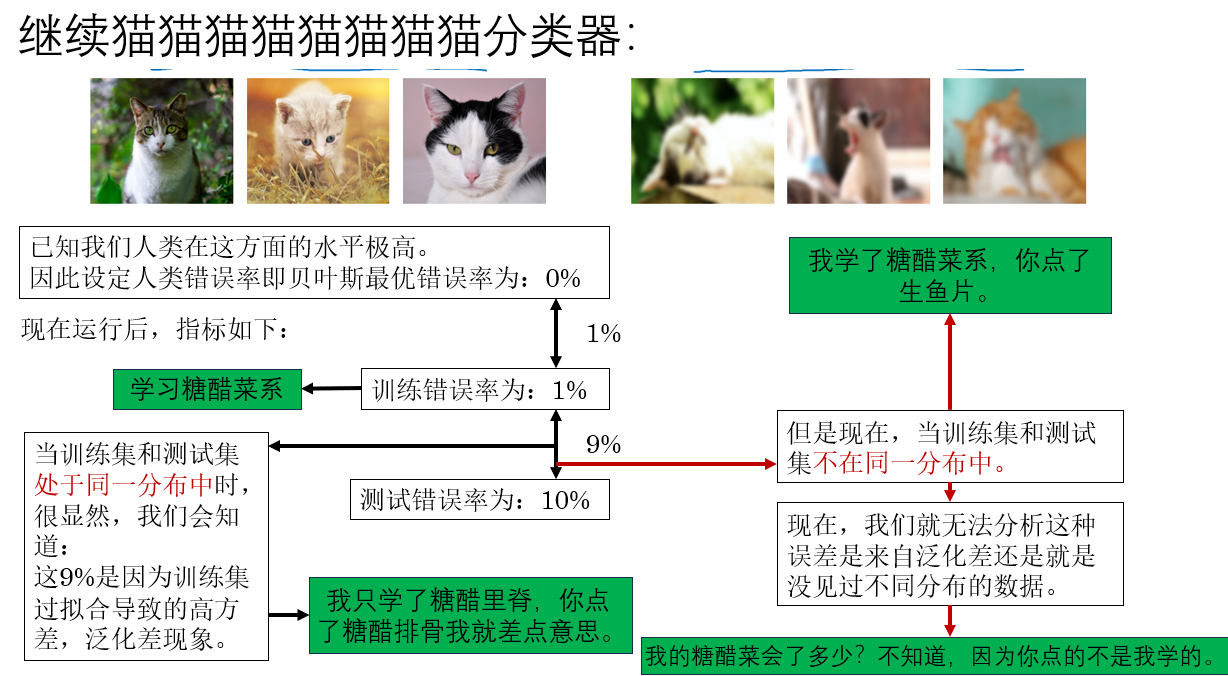
很明显,这种问题让我们无法从指标中分析出明确的优化方向,自然阻碍了我们的任务进程。
如何在这种分布不同的问题下明确我们的优化方向? 就是下面的内容。
3. 训练验证集
直接说做法:再从训练集中划分一部分不用于训练但和训练集处于同一分布的数据,用来评估模型的泛化能力,这就是训练验证集。
来看一组例子如何应用训练验证集:
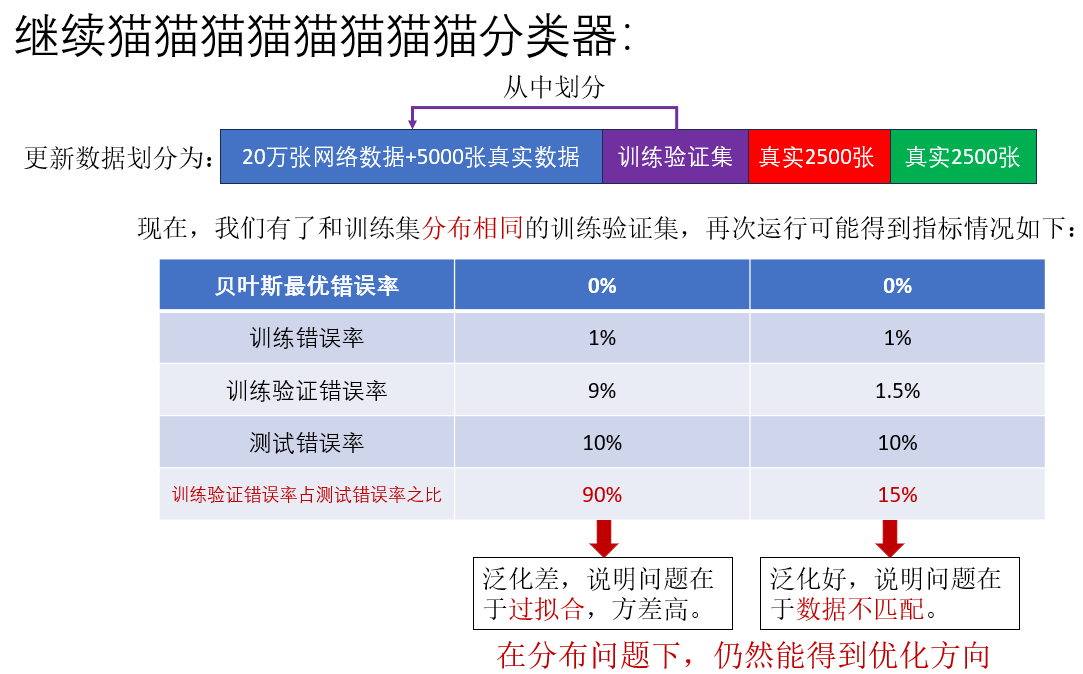
由此,在训练集和测试集的数据分布不同的情况下,我们通过增加训练验证集,仍然实现了对优化方向的误差分析。
我们再看加入训练验证集后几种情况下的误差分析:
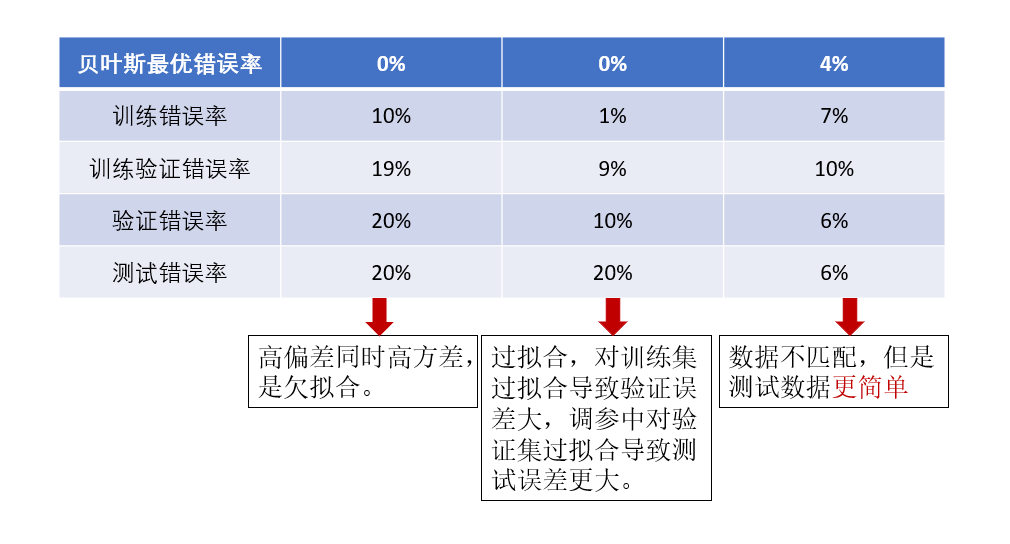
现在,我们已经可以分析出数据不匹配问题了,那怎么缓解数据不匹配问题呢?这就是最后一部分内容。
4. 数据不匹配问题的缓解方法
这种问题的根本还是因为训练集和数据集的分布不同,真实应用获取的数据量较小不足以支撑训练导致的,如果要完全解决这种问题,只能获取更多的真实数据,可是这种问题往往就是因为无法获取更多真实数据导致的。
而如果在不使用这种方法下,一个比较容易想到的思路就是:尽可能缩小训练集和真实应用数据的差异,而如何缩小,还需要根据任务不同而变换。
而这种对原始数据进行处理,合成获取新数据从而解决数据不匹配的逻辑,我们叫人工合成数据。
我们先看一个比较简单的例子:

而这个模糊化处理可以说可以零成本实现,图中就是我进行的处理效果,代码很简单:
from PIL import Image, ImageFilter #核心出装
import matplotlib.pyplot as plt
# 打开图片文件
image_path = "aaa.jpg" # 你的图片路径
image = Image.open(image_path)
# 应用模糊滤镜
blurred_image = image.filter(ImageFilter.GaussianBlur(radius=5)) # radius值越大,模糊效果越强 # 展示对比图
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
axes[0].imshow(image)
axes[0].set_title("Original Image")
axes[0].axis('off')
axes[1].imshow(blurred_image)
axes[1].set_title("Blurred Image")
axes[1].axis('off')
plt.show() # 保存模糊后的图片
#blurred_image.save("blurred_image.jpg")
说到这里扩展一下,你可能会有一点疑惑,那就是模糊化我们之前在数据增强里提过,那数据增强和人工合成数据又有什么区别呢?
其实二者都是一种扩展数据的思路,只是往往用处不同,简单来说:
- 数据增强往往是因为数据不够,我们需要更多数据用于训练。
- 人工合成数据是因为数据不好,我们需要合成数据来缓解数据不匹配。
我们继续,看课程里提到的一个难一些的例子:

因此,人工合成数据只是一种缓解数据不匹配的方法,如果过于依赖它反而会让模型表现出极差的泛化性,无法适应真实应用,因为真实情况远比合成情况要广。
5. 总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 分布不匹配(Distribution Mismatch) | 训练集与真实应用数据的来源或特征不同,导致训练指标无法反映真实表现。 | 你在安静的教室练习口语,但真正考试是在嘈杂的咖啡厅,自然效果会掉。 |
| 训练验证集(Training-Dev Set) | 从训练分布中再划分一部分不参与训练的数据,用来区分“模型能力不足”和“分布不同造成的偏差”。 | 像是给你准备一张“模拟考试卷”,难度、风格都和练习册一样,用来判断你是否真的掌握。 |
| 数据不匹配误差(Data Mismatch Error) | 模型在训练验证集表现良好,但在测试集表现差,这部分差距就是分布不匹配造成的。 | 就像你在训练场能跑 100 米 13 秒,但比赛当天因为风大、路滑,只能跑 14 秒。 |
| 人工合成数据(Synthetic Data) | 对训练集进行修改,让它更接近真实应用分布,从而缓解数据不匹配。 | 为了适应比赛环境,你在训练时故意让跑道变湿、开风扇模拟逆风。 |
| 数据增强(Data Augmentation) | 通过旋转、翻转、缩放等方式扩充训练样本数量,让模型更稳健。 | 拓展练习题数量,让你做更多不同角度但同类型的题目。 |



















