公式解读
前情提要:什么是相机
相机是虚拟的,实际上,它是指一个数学模型,它定义了我们如何将三维空间的点映射到二维照片上,它包含外参和内参,其中:
(1)外参是指你所站的位置t,和你的朝向R。这个描述了相机在3D世界坐标系中的位置。
(2)内参是指内参矩阵K,它包含了焦距,主点等。外参调整过的点与K相乘后,即可将相机坐标转换至像素坐标。具体如下(fx,fy是焦距,cx,cy是主点,也就是平面中心点)
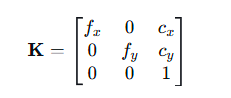
在已知相机的参数、朝向和位置后,我们如何把一个3D点云投影到2D图像上呢,使用的公式如下:
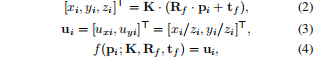
首先第一步是将3D世界坐标变为3D相机坐标:
公式(2)内点R*P+t部分,实际上是进行刚体变换,R*P用于将点P旋转到与相机朝向对齐的坐标系,再加上t则是平移到以相机为原点的坐标系中。这部分变换的结果就是p点的坐标变换成了在3D相机下的坐标。K则是将点从三维相机坐标转置二维像素坐标。
第二步是将2维齐次像素坐标转换为最终像素坐标:
刚刚我们得到的二维像素坐标,实际上是齐次坐标,它虽然是二维的,但是他还有(x,y,z)三个参数,这个时候我们需要进行透视投影,也就是生活中的近大远小,公式(3)使用(x/z,y/z)来进行透视投影,最终得到的ui就是像素坐标
第三步是进行封装:
f(p;k;R,t)=u则是封装了整个投影过程,我们输入3D点,内参和外参,就可以得到这个3D点对应的像素坐标。
流程
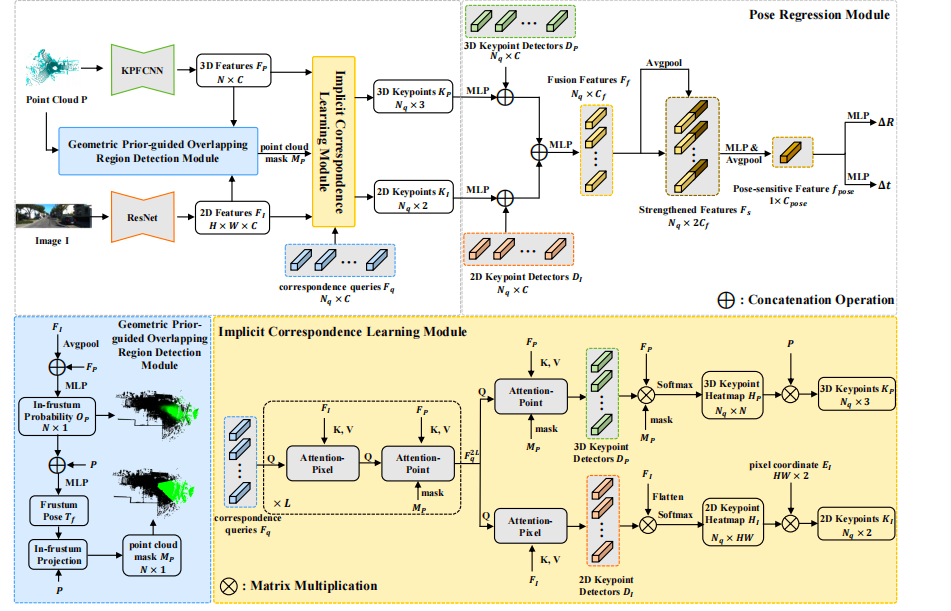
总体框架图如上,分别对点云和图像进行KPFCNN和ResNet网络处理,提取特征,后续则是三个模块,具体如下:
重叠区域检测模块(GPDM)
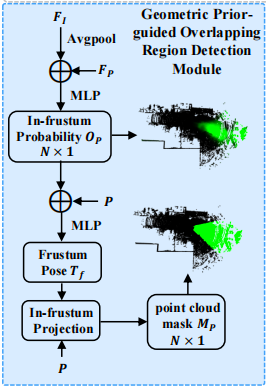
图中区域为GPDM的框架,它的流程分为粗粒度概率估计和精粒度几何估计,首先来看粗粒度概率估计
(1)输入
输入原始图像,进行平均池化得到了全局描述符,然后将这个全局描述符复制N次,与点云特征进行拼接,这样做就使得每个3D点都能够感知到全局的2D图像信息。
(2)概率预测
将融合后的特征送入一个MLP,预测每一个点位于相机视椎体内的初始概率Op
接下来是精粒度几何估计:
(1)MLP处理
将上阶段得到的概率Op与3D点云坐标进行拼接,然后使用两个并行的MLP进行处理,得到相机的参数T_f,其中包含了旋转矩阵R和平移向量t
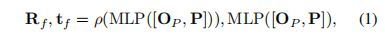
(2)几何投影
输入是T_f和点云P,通过几何投影操作,我们可以将每个3D点云的点投影到2D平面上
(3)点云编码
通过公式判断投影后的点是否落在图像边界内且深度为正,是则编码为1,否则为0。
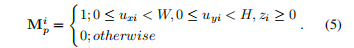
隐式对应学习模块(ICLM)
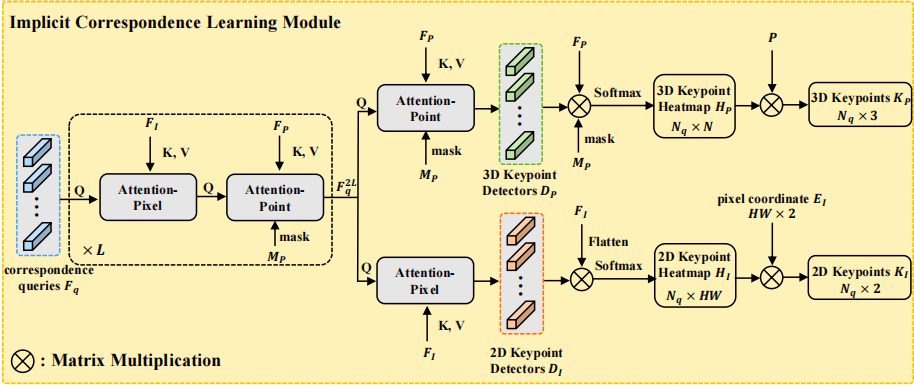
这里首先随机初始化一组查询向量F_q,接下来就是进入了第一步
(1)交替注意力精炼
这里有两个,首先我们看第一个Attention-Pixel
这个操作旨在从二维图像中提取信息,我们输入F_2k_q和Fi,这个Fi是

具体地,Q(查询)、K(键)、V(值)通过线性投影产生
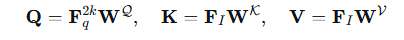
通过缩放点积注意力机制更新查询
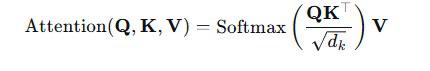
此时更新后的F2k+1已经融合了图像的信息。
第二个是Attention-Point
这个操作旨在从三D点云中提取信息,并利用点云掩码Mp聚焦于重叠区域
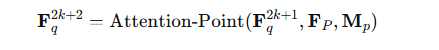
这里与之前类似,唯一的不同点在于他加入了点云掩码,将3D点云中不在图像视椎体内的进行屏蔽。
此时的F2k+2已经融合了点云的信息。
这个F2k+2与F2k+1交替循环L次,得到更新后的查询F2Lq,这个时候它已经对图像和点云都已经有了相当多的信息。
(2)生成关键点
对F2Lq分别进行一次Attention-Point和Attention-Pixel处理,得到在2D图像和3D点云的定位检测器。
接下来生成热力图:
2D热力图H_I生成方式:计算每个2D检测器 D_I 与图像特征 F_I 上每个像素位置的相似度,并通过Softmax得到一个概率分布图。它标示了每个关键点最可能出现在图像上的哪个位置。
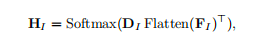
3D热力图H_P生成方式:计算每个3D检测器与点云特征上位置相似度,不同的是在计算时会再次使用掩码 M_p,确保关键点只产生于有效的点云区域。
最终进行关键点坐标的获取
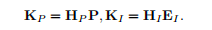
2D坐标获取:K_I = H_I · E_I这里 E_I 是所有像素的坐标矩阵。这个操作是加权平均,用热力图作为权重,计算出亚像素级别的精确2D坐标。
3D坐标获取:K_P = H_P · P。这里 P 是点云的3D坐标矩阵。同样通过加权平均,得到精确的3D坐标。
姿态回归模块
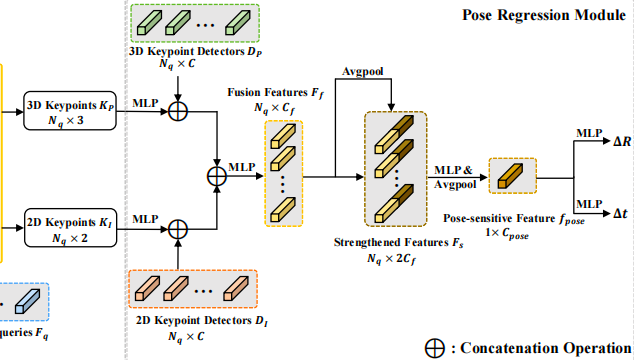
在建立2D-3D对应关系后,我们通过一个学习的网络回归相机位姿。GPDM已经估计了截锥体Tf,不过这是一个粗估计,所以我们以这个为开始,对关键点进行变换。我们将Rt、tf与真实的相机位姿Rgt、tgt的差异估计为:
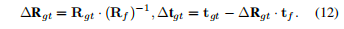
这里首先用多层感知机来提升对应特征并进行配对,融合特征Ff公式如下
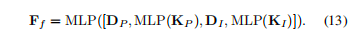
接下来我们对融合过后的Ff进行平均池化,然后再与原来的进行相加,以此实现增强对应关系,其实就是残差网络的实现,最终得到Fs。
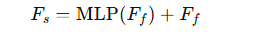
最终我们对所有信息进行平均池化,得到位姿fpose

接下来我们通过分别的两个MLP,就可以得到差异的R和t
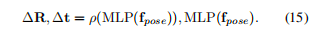
Loss
损失函数包含五个部分,
分别是分类损失L_CLS ,视锥体姿态损失L_fru ,对应关系损失L_corr,多样性损失L_div,相机姿态损失L_cam 。
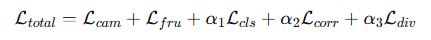
(1)分类损失,公式如下
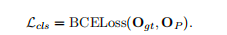
作用于几何先验引导的重叠区域检测模块(GPDM)中第一阶段输出的粗粒度概率 O_P,用于督模型初步判断点云中的哪些点位于相机视锥体内。
真值Ogt的计算:如果一个3D点被投影到图像范围内且深度为正,则其真值为1,否则为0
(2)视椎体损失,公式如下
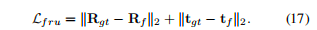
作用于GPDM模块中第二阶段回归出的粗相机姿态 (R_f, t_f),它直接监督模型预测的初始相机姿态,使其尽可能接近真实姿态。
(3)对应关系损失,公式如下
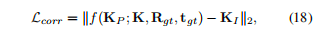
作用对象:隐式对应关系学习模块(ICL)预测出的2D和3D关键点 (K_I, K_P),确保预测的2D-3D关键点对是几何上一致的。
(4)多样性损失,公式如下
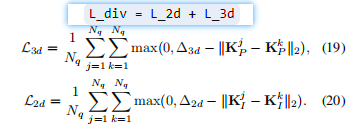
作用于所有的2D和3D点,防止模型预测的所有关键点都聚集在同一个狭小区域,鼓励关键点在2D图像和3D空间中都尽可能分散开。
(5)相机姿态损失,公式如下
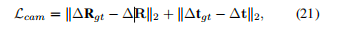
作用对象:姿态回归模块预测出的姿态残差 (ΔR, Δt),这是最直接、最终端的监督信号,确保模型预测的精细姿态修正量是正确的。


















:console控制台命令行交互功能 - 教程)
