作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
通过解析htlm,找到所有<img>标签,爬取所有图片 。
完整代码:
import os import re import requests from bs4 import BeautifulSoup from urllib.parse import urljoin, urlparse from concurrent.futures import ThreadPoolExecutor, as_completed# ========== 配置 ========== START_URL = "http://www.weather.com.cn" SAVE_DIR = "images" THREADS = 10os.makedirs(SAVE_DIR, exist_ok=True) headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ""(KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36" } def get_html(url):try:resp = requests.get(url, headers=headers, timeout=10)resp.encoding = resp.apparent_encodingreturn resp.textexcept Exception as e:print(f"[错误] 无法获取页面:{url},原因:{e}")return ""def get_image_urls(html, base_url):"""提取所有图片URL"""soup = BeautifulSoup(html, "html.parser")img_tags = soup.find_all("img")urls = set()for img in img_tags:src = img.get("src") or img.get("data-src")if src:full_url = urljoin(base_url, src)if re.match(r"^https?://", full_url):# 过滤非图片链接,仅保留常见格式if re.search(r"\.(jpg|jpeg|png|gif|webp|jpgs)(\?|$)", full_url, re.IGNORECASE):urls.add(full_url)return urlsdef get_extension_from_response(resp):"""根据Content-Type判断图片扩展名"""ctype = resp.headers.get("Content-Type", "").lower()if "png" in ctype:return ".png"elif "jpeg" in ctype:return ".jpg"elif "jpg" in ctype:return ".jpg"elif "gif" in ctype:return ".gif"elif "webp" in ctype:return ".webp"return ".jpg"def download_image(url):"""下载单张图片"""try:resp = requests.get(url, headers=headers, timeout=10)if resp.status_code == 200 and "image" in resp.headers.get("Content-Type", ""):filename = os.path.basename(urlparse(url).path)# 如果URL中没有后缀,则用Content-Type推断if not os.path.splitext(filename)[1]:filename += get_extension_from_response(resp)filepath = os.path.join(SAVE_DIR, filename)with open(filepath, "wb") as f:f.write(resp.content)print(f"[下载成功] {url}")else:print(f"[跳过] 非图片链接: {url}")except Exception as e:print(f"[失败] {url} 原因: {e}")# ========== 单线程 ========== def single_thread_crawl(url):print("=== 单线程爬取开始 ===")html = get_html(url)img_urls = get_image_urls(html, url)print(f"共找到 {len(img_urls)} 张图片")for img_url in img_urls:print(f"[URL] {img_url}")download_image(img_url)print("=== 单线程爬取结束 ===")# ========== 多线程 ========== def multi_thread_crawl(url):print("=== 多线程爬取开始 ===")html = get_html(url)img_urls = get_image_urls(html, url)print(f"共找到 {len(img_urls)} 张图片")with ThreadPoolExecutor(max_workers=THREADS) as executor:futures = [executor.submit(download_image, img_url) for img_url in img_urls]for _ in as_completed(futures):passprint("=== 多线程爬取结束 ===")# ========== 主入口 ========== if __name__ == "__main__":print("请选择模式:")print("1. 单线程")print("2. 多线程")choice = input("输入1或2:").strip()if choice == "1":single_thread_crawl(START_URL)else:multi_thread_crawl(START_URL)
运行结果:
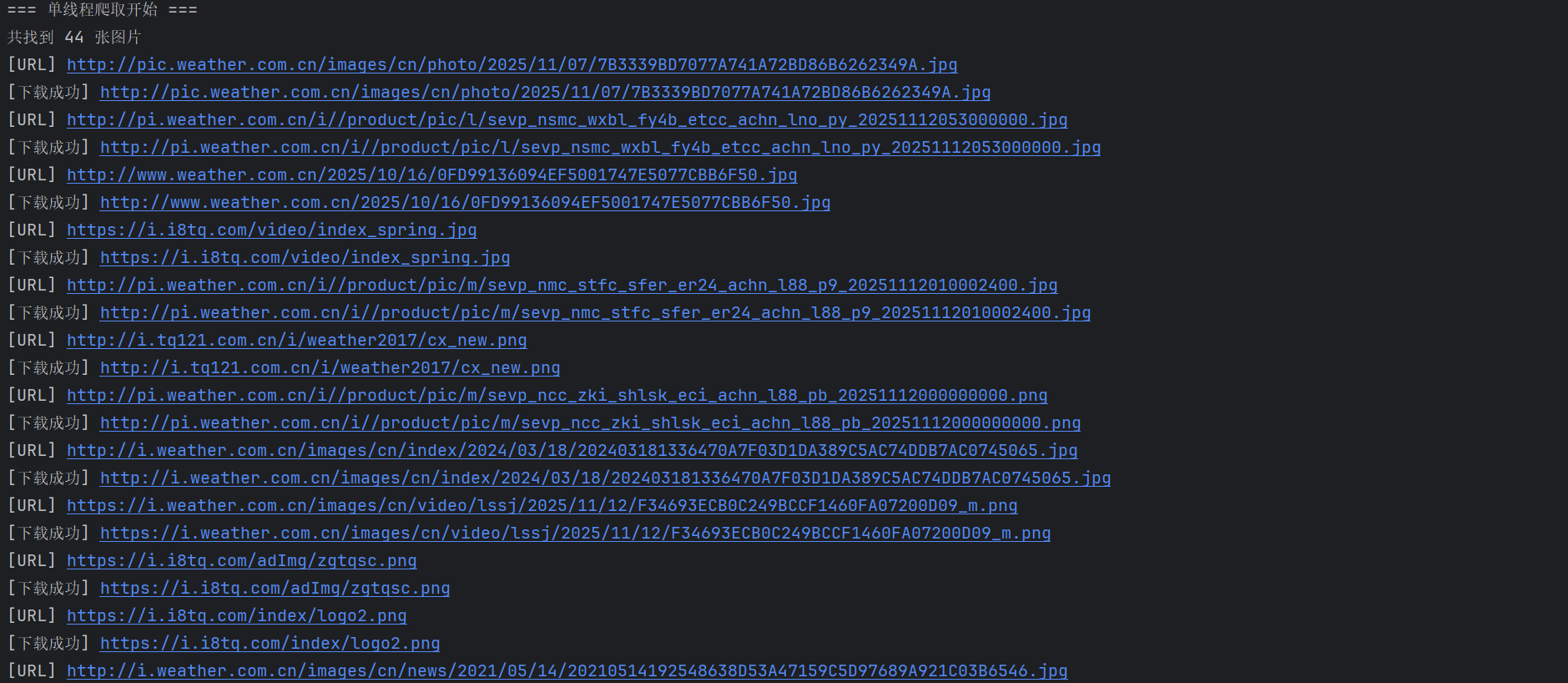
单线程:
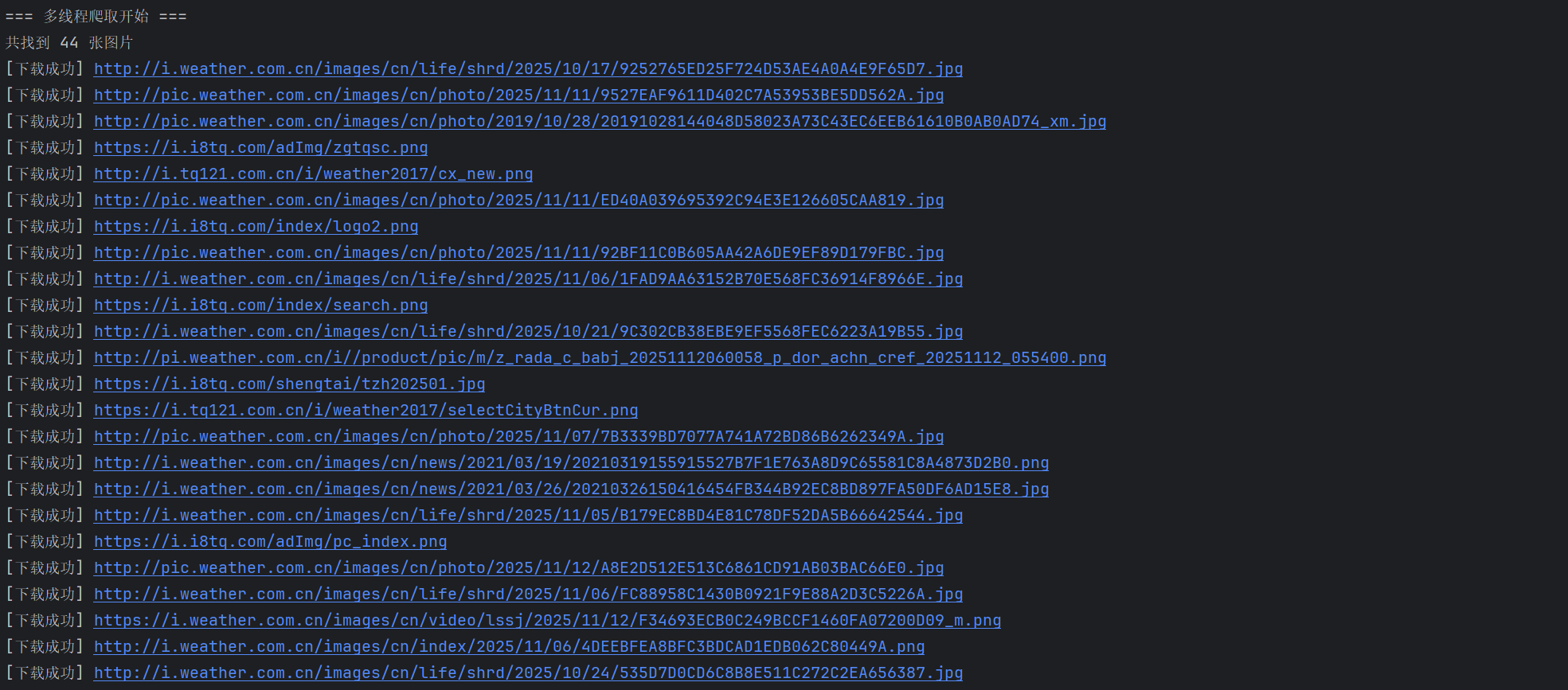
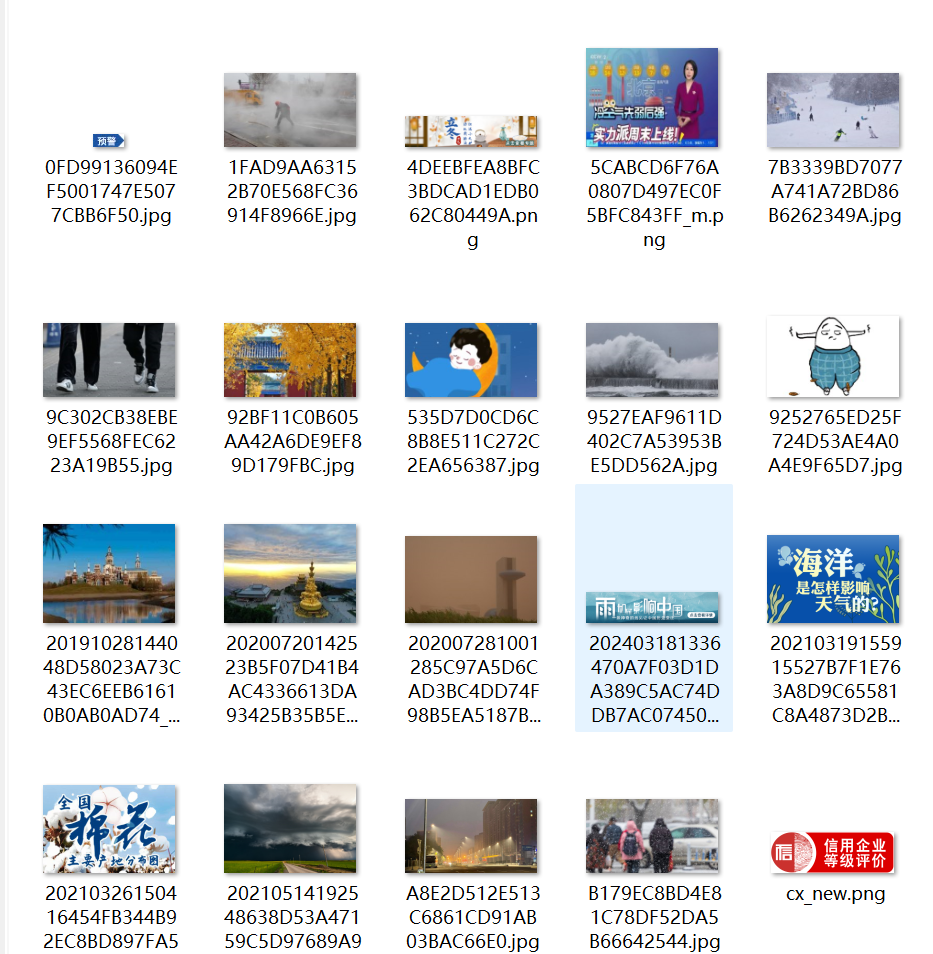
多线程:
心得体会:
通过观察html发现所有图像都在标签<img>中,然后通过url进行下载,在单线程模式下,程序顺序地请求并保存每一张图片,逻辑清晰但效率较低;而在多线程模式中,我使用了 ThreadPoolExecutor 实现并发下载,使得多个图片可以同时被请求和保存,大幅提升了下载速度。通过比较两种模式的运行时间,我深刻体会到并行处理在网络 I/O 密集型任务中的显著优势。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
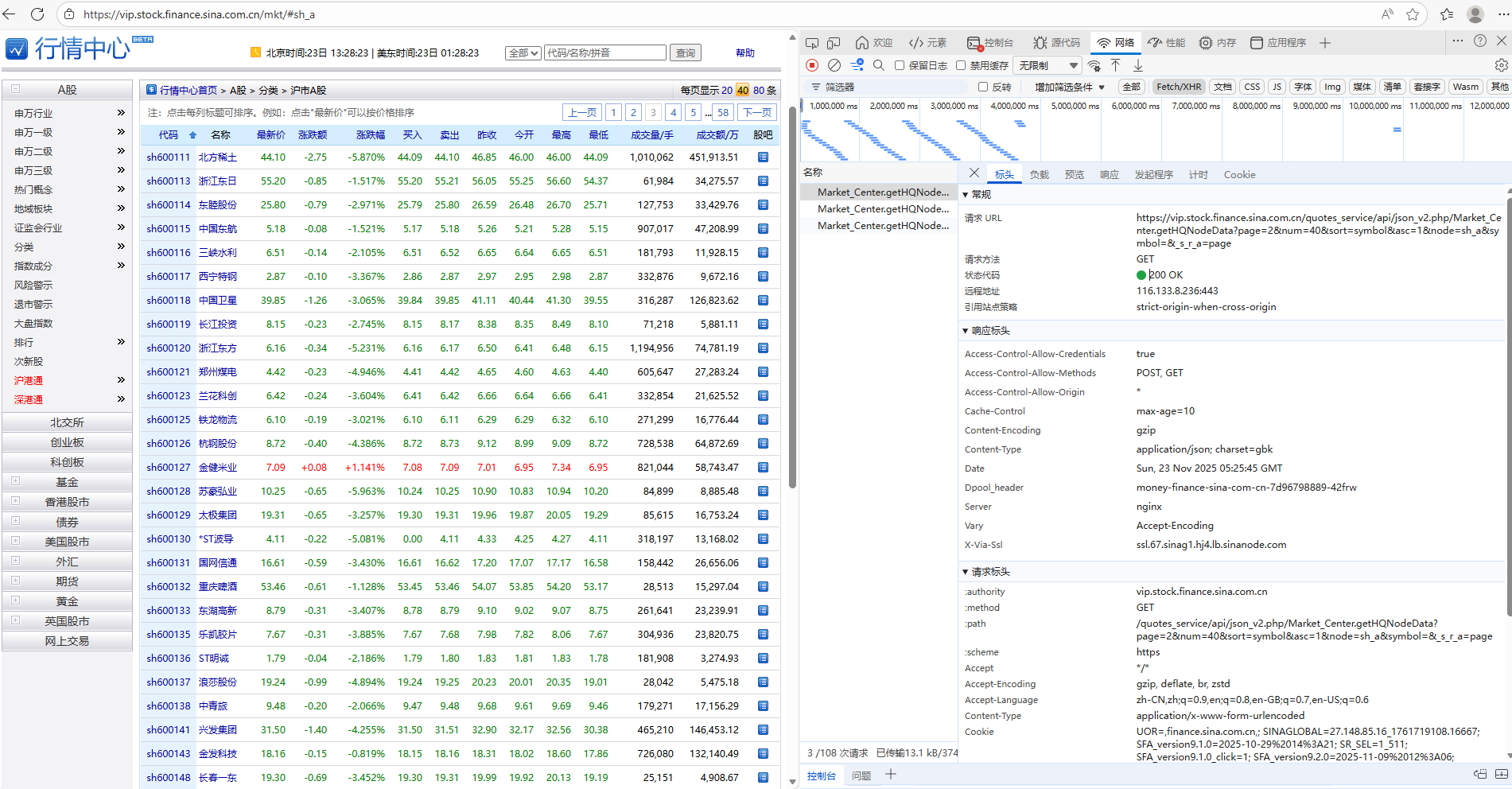
通过抓包方式发现url中的page参数代表着页数,通过改变page参数于是实现了多页爬取。
完整代码:
import scrapy import json from scrapy_stock.items import StockItemclass SinaStockSpider(scrapy.Spider):name = "sinastock"# 起始页start_page = 1max_page = 5 def start_requests(self):url = f"https://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/" \f"Market_Center.getHQNodeData?page={self.start_page}&num=40&sort=symbol&asc=1&node=sh_a&symbol=&_s_r_a=page"yield scrapy.Request(url=url, callback=self.parse, meta={'page': self.start_page})def parse(self, response):page = response.meta['page']try:data_list = json.loads(response.text)except:self.logger.error("JSON 解析失败")returnfor info in data_list:item = StockItem()item["bStockNo"] = info.get("symbol")item["bName"] = info.get("name")item["bPrice"] = info.get("trade")item["bUpDown"] = info.get("pricechange")item["bUpDownRate"] = info.get("changepercent")item["bVolume"] = info.get("volume")item["bAmount"] = info.get("amount")item["bAmplitude"] = info.get("amplitude")item["bHigh"] = info.get("high")item["bLow"] = info.get("low")item["bOpen"] = info.get("open")item["bClose"] = info.get("settlement")yield item# 翻页,递归爬取if page < self.max_page:next_page = page + 1next_url = f"https://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/" \f"Market_Center.getHQNodeData?page={next_page}&num=40&sort=symbol&asc=1&node=sh_a&symbol=&_s_r_a=page"yield scrapy.Request(url=next_url, callback=self.parse, meta={'page': next_page})
运行结果:
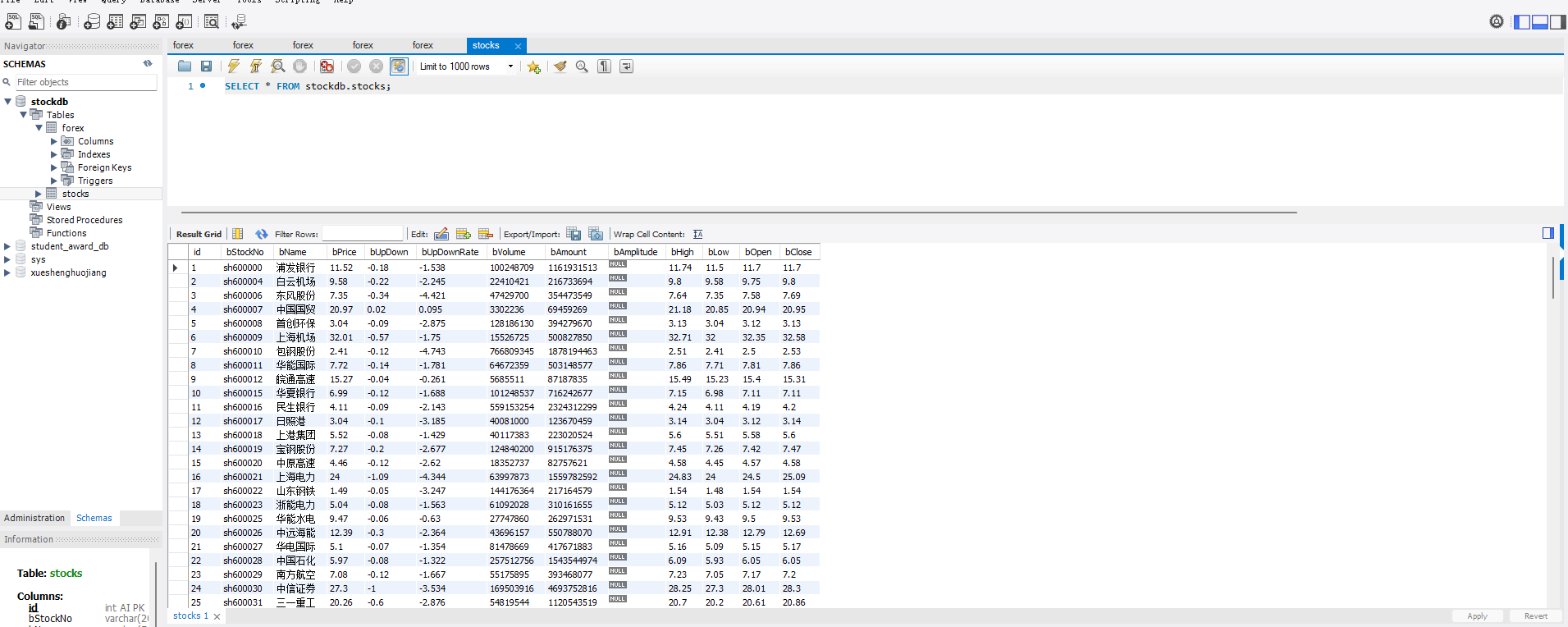
心得体会:
本次实验让我深刻理解了 Scrapy 的数据流、Item 封装与 Pipeline 处理,掌握了 Xpath 数据提取 和 MySQL 持久化 的完整流程,同时提升了对爬虫项目结构化、模块化设计的认识。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
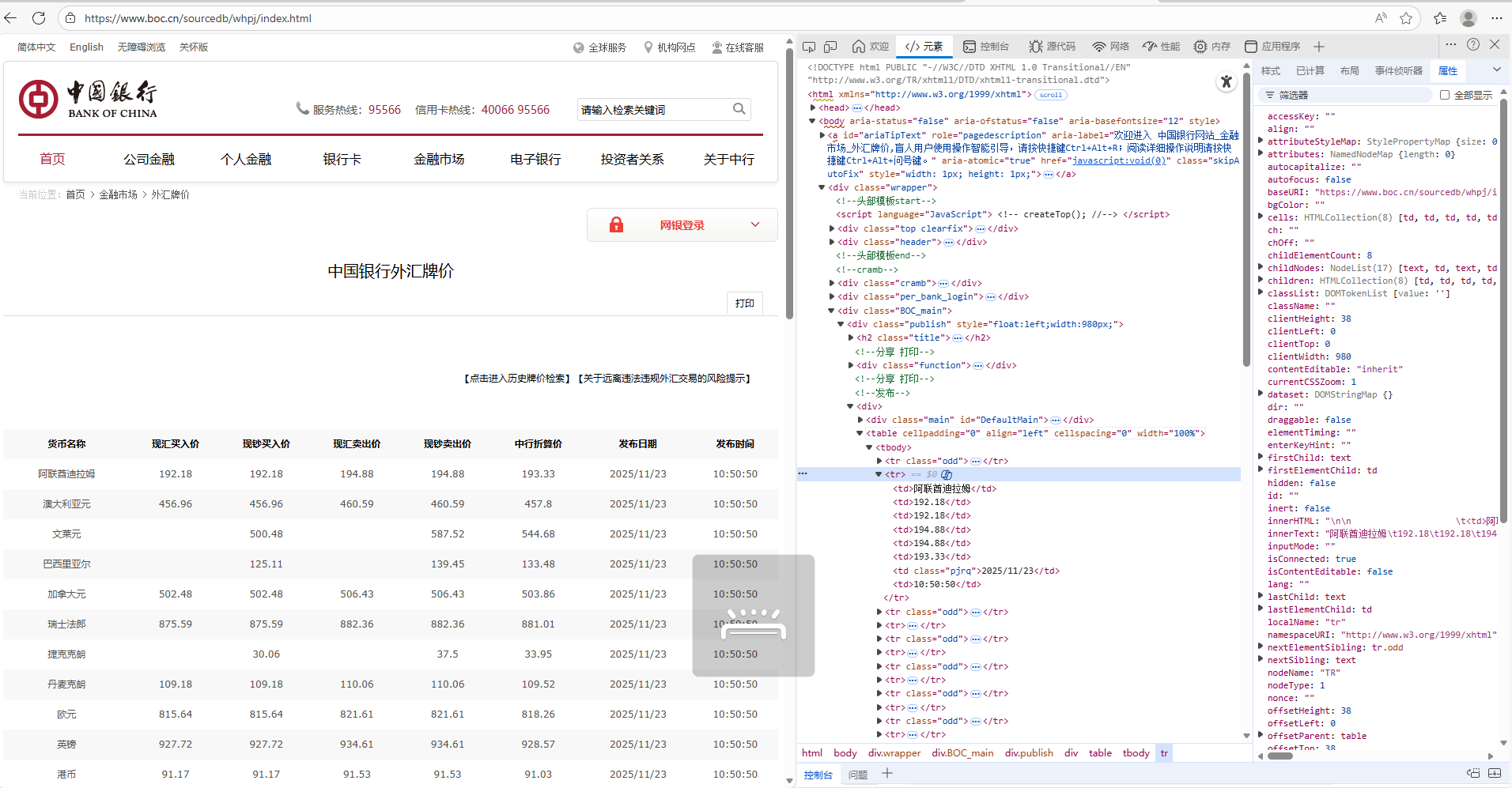
通过观察可以发现,所有数据都在<tbody>里面
完整代码:
import scrapy from scrapy_forex.items import ForexItemclass BocSpider(scrapy.Spider):name = "boc"allowed_domains = ["boc.cn"]start_urls = ["https://www.boc.cn/sourcedb/whpj/"]def parse(self, response):# 直接抓 table 下所有 tr,然后跳过表头rows = response.xpath("//table/tr")[1:] # 第一行是表头 <tr class="odd">for row in rows:tds = row.xpath("./td/text()").getall()tds = [td.strip() for td in tds if td.strip()]if len(tds) < 8:continueitem = ForexItem()item['currency'] = tds[0]item['tbp'] = self.safe(tds[1])item['cbp'] = self.safe(tds[2])item['tsp'] = self.safe(tds[3])item['csp'] = self.safe(tds[4])item['avg'] = self.safe(tds[5])item['date'] = tds[6]item['time'] = tds[7]yield itemdef safe(self, value):"""空值或 '--' 转为 None"""try:return float(value)except:return None
运行结果:
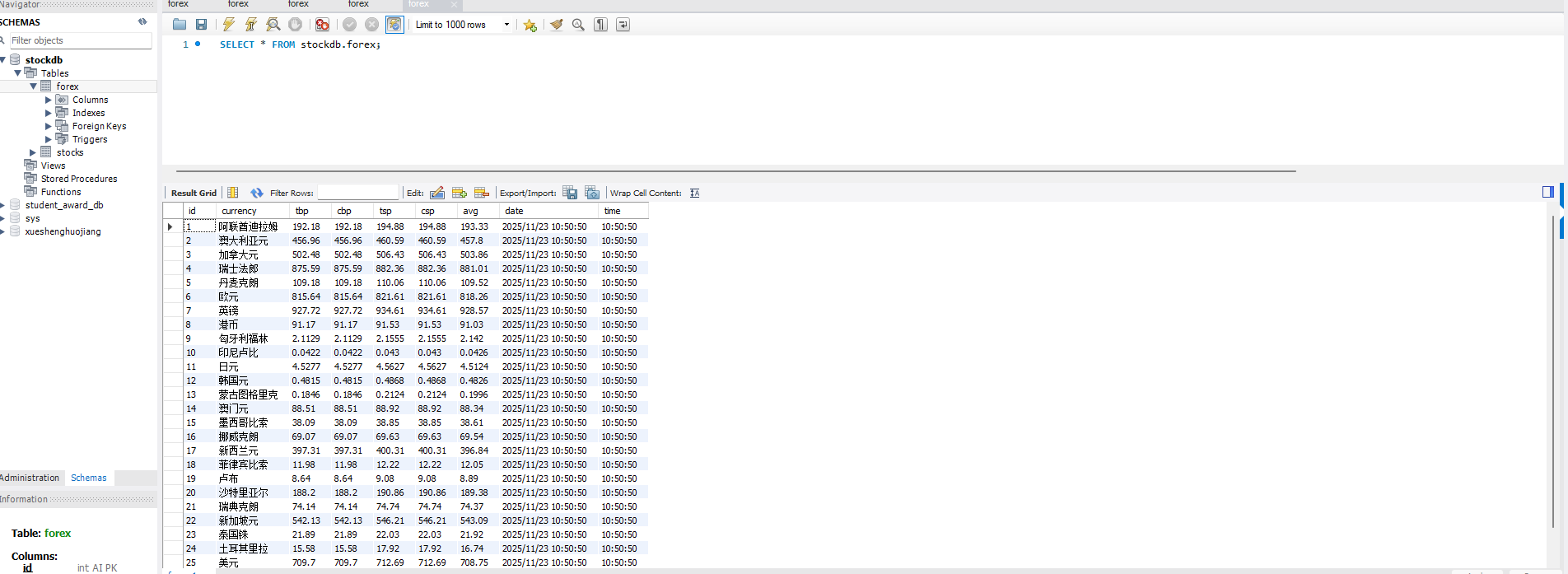
心得体会:
本次实验任务是使用 Scrapy 框架爬取中国银行外汇牌价信息,并将数据通过 Item 封装后,利用 Pipeline 写入 MySQL 数据库,同时实现序列化输出。实验过程中,我首先定义了 ForexItem,字段包括货币名称、现汇买入价、现钞买入价、现汇卖出价、现钞卖出价、中行折算价、发布日期和时间。通过 Xpath 精准定位 <table> 中的 <tr> 和 <td> 节点,实现数据提取。实验初期遇到的问题主要是数据抓取不到。原因在于网页结构复杂,tbody 上层的 table 标签未正确定位。通过本次实验,我掌握了 Scrapy 数据流的完整流程:Spider 抓取、Item 封装、Pipeline 清洗存储,同时加深了对 Xpath 定位和数据库操作的理解,提高了爬虫的稳健性和可用性。
)
)














-mcp调用)


