| 大家好,我是工藤学编程 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之LangChain Output Parser |
前情摘要:
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
9、零基础学AI大模型之Prompt提示词工程
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain链
13、零基础学AI大模型之Stream流式输出实战
14、零基础学AI大模型之LangChain Output Parser
本文章目录
- 一、为什么需要Pydantic解析器?
- 二、PydanticOutputParser实战案例
- 环境准备
- 案例一:大模型信息输出提取
- 代码解析:
- 案例二:电商评论情感分析系统
- 代码解析:
- 三、PydanticOutputParser vs JsonOutputParser
- 四、常见问题与解决方案
- 五、总结
一、为什么需要Pydantic解析器?
在大模型应用开发中,我们经常需要将模型输出的非结构化文本转换为程序可以直接处理的数据结构。这个过程如果手动实现,不仅繁琐易错,还难以保证数据的有效性。
Pydantic解析器主要解决以下几个核心问题:
- 结构化输出:将非结构化文本转为可编程对象,省去手动解析的麻烦
- 数据验证:自动验证字段类型和约束条件,单纯JSON解析器则不会校验
- 开发效率:减少手动解析代码,让开发者专注于业务逻辑
- 错误处理:内置异常捕获与修复机制,提高程序健壮性
想象一下,如果没有结构化解析,我们可能需要写大量的正则表达式或字符串处理代码来提取关键信息,还要手动进行类型转换和验证,这不仅效率低下,而且容易出错。
二、PydanticOutputParser实战案例
环境准备
首先确保安装了必要的库:
pip install langchain langchain-openai pydantic本文将使用本地部署的deepseek-r1:7b模型进行演示,模型部署可以参考我之前的文章《零基础学AI大模型之大模型私有化部署全指南》。
案例一:大模型信息输出提取
这个案例展示如何使用PydanticOutputParser结合Pydantic模型来提取和验证用户信息。
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.output_parsers import PydanticOutputParser
# 定义本地模型
model = ChatOpenAI(
model_name="deepseek-r1:7b",
base_url="http://127.0.0.1:11434/v1",
api_key="none", # 本地模型通常不需要API密钥
temperature=0.3 # 降低随机性,使输出更稳定
)
# Step1: 定义Pydantic模型
class UserInfo(BaseModel):
name: str = Field(description="用户姓名")
age: int = Field(description="用户年龄", gt=0) # gt=0表示年龄必须大于0
hobbies: list[str] = Field(description="兴趣爱好列表")
# Step2: 创建解析器
parser = PydanticOutputParser(pydantic_object=UserInfo)
# Step3: 构建提示模板
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("""
提取用户信息,严格按照格式要求输出,不要添加任何额外内容:
{format_instructions}
输入内容:
{input}
""")
# 注入格式指令
prompt = prompt.partial(
format_instructions=parser.get_format_instructions()
)
# Step4: 组合处理链
chain = prompt | model | parser
# 执行解析
try:
result = chain.invoke({
"input": """
我的名称是张三,年龄是18岁,兴趣爱好有打篮球、看电影。
"""
})
print(f"结果类型: {type(result)}")
print(f"姓名: {result.name}")
print(f"年龄: {result.age}")
print(f"兴趣爱好: {result.hobbies}")
except Exception as e:
print(f"解析出错: {e}")代码解析:
模型定义:我们定义了一个
UserInfo的Pydantic模型,包含name(字符串)、age(整数,且必须大于0)和hobbies(字符串列表)三个字段。解析器创建:通过
PydanticOutputParser创建解析器,并将我们定义的UserInfo模型传入。提示模板:构建提示模板时,我们通过
parser.get_format_instructions()获取格式说明,并将其注入到提示中,告诉模型应该如何输出。处理链:使用LangChain的链(Chain)将提示、模型和解析器组合起来,形成一个完整的处理流程。
执行与结果:调用
invoke方法执行处理链,得到的结果是一个UserInfo对象,我们可以直接通过属性访问其中的数据。
如果模型输出不符合UserInfo模型的定义(例如年龄为负数),解析器会自动抛出异常,这就是Pydantic的数据验证功能在起作用。
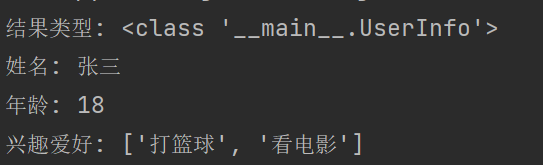
输出
结果类型: <class ‘main.UserInfo’>
姓名: 张三
年龄: 18
兴趣爱好: [‘打篮球’, ‘看电影’]
案例二:电商评论情感分析系统
这个案例展示如何结合JsonOutputParser和Pydantic模型进行电商评论的情感分析。
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
import json
# 定义本地模型
model = ChatOpenAI(
model_name="deepseek-r1:7b",
base_url="http://127.0.0.1:11434/v1",
api_key="none",
temperature=0.3
)
# 定义JSON结构对应的Pydantic模型
class SentimentResult(BaseModel):
sentiment: str = Field(description="情感倾向,只能是positive、negative或neutral")
confidence: float = Field(description="情感分析的置信度,0到1之间的浮点数")
keywords: list[str] = Field(description="评论中的关键词列表")
# 构建处理链
parser = JsonOutputParser(pydantic_object=SentimentResult)
prompt = ChatPromptTemplate.from_template("""
分析以下评论的情感倾向,确定情感是positive(正面)、negative(负面)还是neutral(中性),
计算情感分析的置信度(0到1之间),并提取评论中的关键词。
{input}
按照以下格式要求返回结果,不要添加任何额外内容:
{format_instructions}
""").partial(format_instructions=parser.get_format_instructions())
chain = prompt | model | parser
# 执行分析
try:
result = chain.invoke({"input": "物流很慢,包装破损严重,再也不会买了"})
print(f"情感倾向: {result['sentiment']}")
print(f"置信度: {result['confidence']}")
print(f"关键词: {result['keywords']}")
# 验证结果类型
print(f"\n情感类型验证: {isinstance(result['sentiment'], str)}")
print(f"置信度类型验证: {isinstance(result['confidence'], float)}")
print(f"关键词类型验证: {isinstance(result['keywords'], list)}")
except Exception as e:
print(f"解析出错: {e}")
# 流式调用示例
print("\n===== 流式调用 =====")
try:
for chunk in chain.stream({"input": "商品质量不错,价格合理,但物流有点慢"}):
if chunk: # 过滤空块
print(f"收到 chunk: {json.dumps(chunk, ensure_ascii=False)}")
except Exception as e:
print(f"流式解析出错: {e}")代码解析:
模型定义:我们定义了
SentimentResult模型,用于存储情感分析结果,包括情感倾向、置信度和关键词。解析器选择:这里使用了
JsonOutputParser,并通过pydantic_object参数指定了对应的Pydantic模型,这样既可以得到JSON格式的输出,又能进行数据验证。提示设计:提示中明确要求模型分析情感倾向、计算置信度并提取关键词,使模型输出更符合我们的需求。
流式调用:
JsonOutputParser支持流式处理,可以逐步接收和处理模型的输出,这在需要实时展示结果的场景中非常有用。
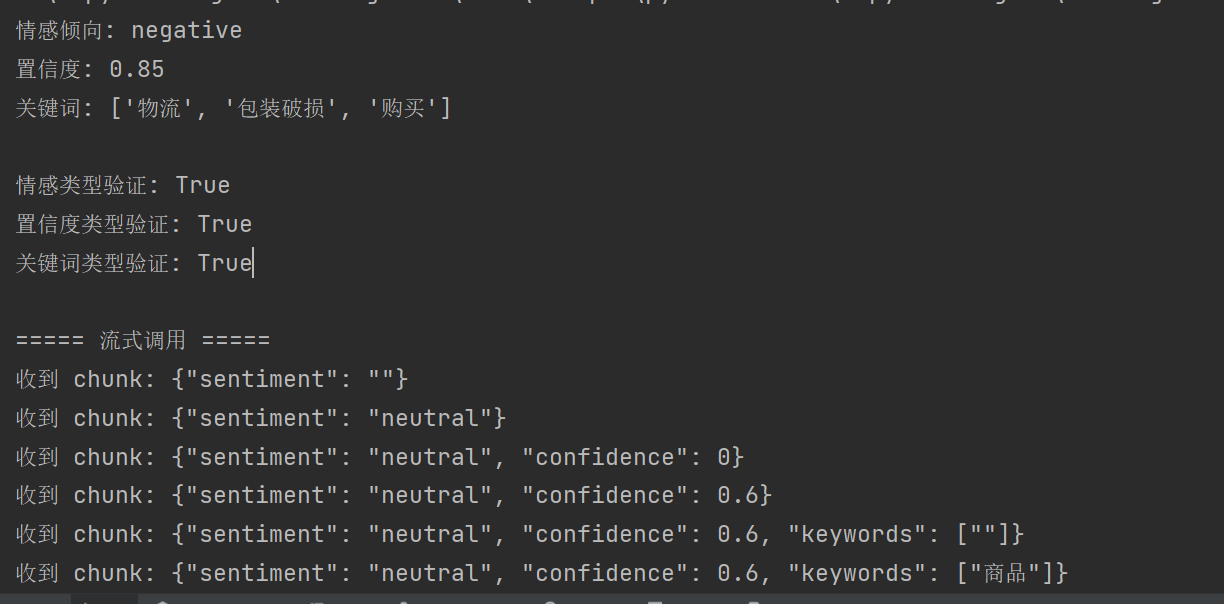
输出
情感倾向: negative
置信度: 0.85
关键词: [‘物流’, ‘包装破损’, ‘购买’]
情感类型验证: True
置信度类型验证: True
关键词类型验证: True
===== 流式调用 =====
收到 chunk: {“sentiment”: “”}
收到 chunk: {“sentiment”: “neutral”}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“”]}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“商品”]}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“商品质量”]}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“商品质量”, “”]}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“商品质量”, “不错”]}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“商品质量”, “不错”, “”]}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“商品质量”, “不错”, “价格”]}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“商品质量”, “不错”, “价格合理”]}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“商品质量”, “不错”, “价格合理”, “”]}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“商品质量”, “不错”, “价格合理”, “物流”]}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“商品质量”, “不错”, “价格合理”, “物流”, “”]}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“商品质量”, “不错”, “价格合理”, “物流”, “有点”]}
收到 chunk: {“sentiment”: “neutral”, “confidence”: 0.6, “keywords”: [“商品质量”, “不错”, “价格合理”, “物流”, “有点慢”]}
三、PydanticOutputParser vs JsonOutputParser
| 特性 | PydanticOutputParser | JsonOutputParser |
|---|---|---|
| 输出类型 | Pydantic模型对象 | 字典(dict) |
| 数据验证 | 强验证,支持复杂约束 | 基础验证,主要检查JSON格式 |
| 类型转换 | 自动转换为指定类型 | 保持JSON原生类型 |
| 流式处理 | 不支持 | 支持 |
| 使用场景 | 需严格验证数据结构的场景 | 需灵活处理或流式输出的场景 |
| 易用性 | 可通过属性访问数据 | 需通过键访问数据 |
在实际开发中,选择哪种解析器取决于具体需求:
- 如果需要严格的数据验证和类型转换,选择
PydanticOutputParser - 如果需要处理流式输出或更灵活的数据结构,选择
JsonOutputParser - 新版LangChain中,
JsonOutputParser也可以通过pydantic_object参数获得类似Pydantic的验证能力
四、常见问题与解决方案
解析失败:
- 检查提示模板是否清晰,是否正确注入了格式说明
- 尝试降低模型的temperature参数,减少输出的随机性
- 增加格式示例,帮助模型理解预期输出
类型验证错误:
- 检查Pydantic模型定义是否合理
- 考虑使用更宽松的验证规则,或在必要时使用
Field的default参数提供默认值 - 对于复杂场景,可以自定义验证器
本地模型兼容性:
- 部分本地模型可能对复杂格式指令支持不佳,需要更明确的提示
- 可以先让模型输出原始JSON,再手动进行解析和验证
五、总结
Pydantic解析器为我们提供了一种简洁高效的方式来处理大模型的输出,无论是PydanticOutputParser还是JsonOutputParser,都能显著提高开发效率并增强程序的健壮性。
通过将非结构化的文本输出转换为结构化的数据,我们可以更方便地对模型输出进行处理、分析和存储,为构建可靠的大模型应用奠定基础。
在实际项目中,建议根据具体需求选择合适的解析器,并充分利用Pydantic的数据验证功能,确保输入数据的有效性,从而提高整个系统的稳定性。
如果觉得本文对你有帮助,欢迎点赞、收藏、关注,你的支持是我持续创作的动力!







:板端部署 RKLLM 并进行大模型推理(以 RK3588 为例))
:加载图片)











