1 Hologres:阿里巴巴版实时数仓产品
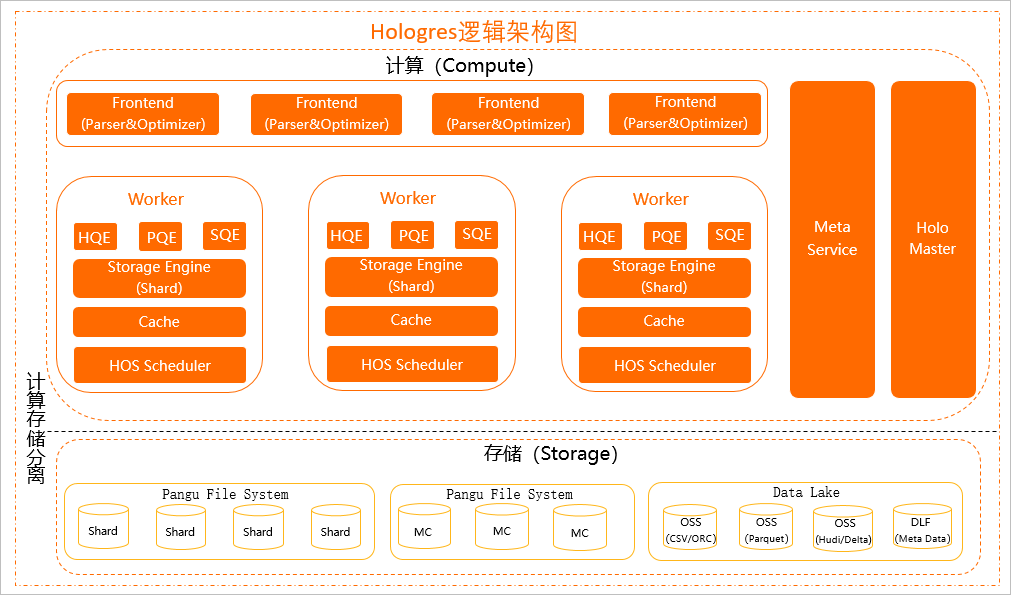
https://help.aliyun.com/zh/hologres/product-overview/architecture
产品定位
Hologres是阿里巴巴自主研发的一站式【实时数仓引擎】(Real-Time Data Warehouse)
- 支持海量数据实时写入、实时更新、实时加工、实时分析
- 支持标准SQL(兼容PostgreSQL协议和语法,支持大部分PostgreSQL函数)
- 支持PB级数据多维分析(OLAP)与即席分析(Ad Hoc)
- 支持高并发低延迟的在线数据服务(Serving)
- 支持多种负载的细粒度隔离与企业级安全能力,与MaxCompute、Flink、DataWorks深度融合,提供企业级离在线一体化全栈数仓解决方案。
Hologres致力于高性能、高可靠、低成本、可扩展的实时数仓引擎研发,为用户提供海量数据的实时数据仓库解决方案和亚秒级交互式查询服务,广泛应用在实时数据中台建设、精细化分析、自助式分析、营销画像、人群圈选、实时风控等场景。
什么是数据仓库? - Aliyun
数据仓库是企业中用于集中存储和管理来自多个源的经过处理和组织的数据的系统。
它为复杂的查询和分析提供了一个优化的环境,使得用户能够执行高级数据分析,以支持商业决策。
数据在进入仓库之前经过清洗、转换和集成,以确保质量和一致性。
这使得企业能够通过商业智能工具和报告软件,对历史和当前数据进行深入分析,以洞察趋势、预测未来并优化战略。
功能特性
- 多场景查询分析
Hologres支持行存、列存、行列共存等多种存储模式和索引类型,同时满足简单查询、复杂查询、即席查询等多样化的分析查询需求。Hologres使用大规模并行处理架构,分布式处理SQL,提高资源利用率,实现海量数据极速分析。
-
亚秒级交互式分析
Hologres采用可扩展的大规模并行处理(MPP)架构全并行计算,通过向量化算子发挥CPU最佳算力,基于AliORC压缩存储,面向SSD存储优化IO吞吐,支持PB级数据亚秒级交互式分析体验。 -
在线高性能主键点查
基于行存表的主键索引和查询引擎的短路径优化,Hologres支持每秒数十万QPS高性能在线点查、前缀扫描,支持高吞吐实时更新,相比开源系统性能提升10倍以上,可用于实时加工链路的维表关联、ID-Mapping等场景。 -
联邦查询,数据湖加速
Hologres无缝对接MaxCompute,支持外部表透明加速查询和元数据自动导入,相比原生MaxCompute访问加速5-10倍,支持冷热数据关联分析,同时支持MaxCompute与Hologres之间百万行每秒高速同步,支持OSS数据湖格式读写,简化数据入湖入仓。 -
半结构数据分析
原生支持半结构化JSON数据类型,支持JSONB列式存储压缩,支持丰富的JSON相关表达算子,使JSON数据存储和分析效率接近原生列存效率。 -
原生实时数仓
针对实时数仓数据更新频繁、数据模型简单和分析场景敏捷的特性,Hologres支持高并发实时写入与更新,支持事务隔离与原子性,数据写入即可查。
- 高吞吐实时写入与更新
Hologres与Flink、Spark等计算框架原生集成,通过内置Connector,支持高通量数据实时写入与更新,支持源表、结果表、维度表多种场景,支持多流合并等复杂操作。
-
所见即所得的开发
数据实时写入即可查询,支持DB、Schema、Table三级体系,支持视图View,原生支持Update/Delete/Upsert,支持关联、嵌套、窗口等丰富表达能力,原生支持半结构化JSON数据分析,支持MySQL等数据库数据整库一键入库,实时同步。 -
全链路事件驱动
支持表更新事件的Binlog透出能力,通过Flink消费Hologres Binlog,实现数仓层次间全链路实时开发,满足分层治理的前提下,缩短数据加工端到端延迟。 -
实时物化视图
支持定义实时物化视图,简化数据加工聚合等开发,数据实时写入,聚合实时更新,完善支持实时加工场景。 -
企业级运维能力
支持计算负载、访问权限等细粒度管控要求,提供丰富的监控和告警指标,支持计算资源弹性扩展,支持系统热升级,满足企业级安全可靠的运维需求。
- 数据安全
支持细粒度访问控制策略,支持BYOK数据存储加密和数据脱敏,支持数据保护伞、IP白名单,支持RAM、STS及独立账号等多种认证体系,通过PCI-DSS安全认证。支持数据备份与恢复。
- 负载隔离
多个计算实例组成一主多从模式,实例间共享一份存储,计算资源隔离,实现写入和读取隔离,查询和服务隔离,实现故障管理,支持故障节点快速自动恢复。无需本地盘,盘古三副本高可靠冗余存储。
- 自运维能力
内置查询历史、元仓表等运维诊断信息,用户可以基于查询历史和表的元数据,快速定位系统瓶颈和风险点,提升自运维能力。
-
生态与可扩展性
兼容PostgreSQL生态,与大数据计算引擎及大数据智能研发平台DataWorks无缝打通。无需额外学习,即可上手开发。 -
兼容PostgreSQL生态
Hologres兼容PostgreSQL生态,提供JDBC/ODBC接口,轻松对接第三方ETL和BI工具,包括Quick BI、DataV、Tableau、帆软等。支持GIS空间数据分析,支持Oracle函数扩展包。 -
DataWorks开发集成
Hologres与DataWorks深度集成,提供图形化、智能化、一站式的数仓搭建和交互式分析服务工具,支持数据资产、数据血缘、数据实时同步、数据服务等企业级能力。 -
Hadoop生态集成
支持Hive/Spark Connector,通过Hadoop平台加工的数据可以高吞吐导入Hologres,并对外提供服务。支持加速读取外部表OSS-HDFS格式存储,支持Hudi、Delta等存储格式。 -
达摩院Proxima向量检索
Hologres与人工智能平台 PAI紧密结合,内置达摩院Proxima向量检索插件,支持在线实时特征存储、实时召回、向量检索。
计算
| 功能 | 功能描述 | 参考文档 |
|---|---|---|
| SQL开发 | 兼容PostgreSQL语法,支持完整的DDL、DML等能力,提供多种数据类型和函数,可标准的SQL开发,上手成本低。 | CREATE TABLE数据类型汇总PostgreSQL兼容函数扩展函数DML(insert/select/update等) |
| 引擎扩展能力 | 提供多种扩展函数,满足流量分析、空间计算、向量计算等多个场景更加低成本的分析计算,包含:PostGIS扩展、Proxima向量计算、Oracle扩展函数、ClickHouse扩展函数、聚合函数、流量分析函数。 | PostGIS地理信息分析Proxima向量计算Oracle兼容函数Clickhouse兼容函数聚合函数 |
| Hologres Binlog | 支持单表级别的Binlog,用于记录表数据的修改记录。通过Hologres Binlog,实现数仓分层间的全链路实时开发,缩短数据端到端加工延迟,同时提升数据开发效率。 | 订阅Hologres Binlog |
| 实时物化视图 | 实时物化视图将对明细表的数据进行预先聚合,存储为物化视图,通过查询物化视图,减少计算量,显著提升查询性能。 | 实时物化视图(Beta) |
| JSON和JSON列存 | 支持JSON和JSONB数据类型、多种JSON函数,满足标签、画像等场景对半结构化数据分析的需求。同时支持JSONB列式存储,实现JSON数据更高的存储压缩,更低的查询延迟。 | 列式JSONBJSONB使用 |
存储
| 功能 | 功能描述 | 参考文档 |
|---|---|---|
| 内表多种存储模式和存储介质 | 1.存储模式上,业务可根据需求选择存储模式,包含:列存、行存、行列共存;行存满足高QPS点查场景、列存支持高性能多维分析、行列共存支持行存和列存的混合查询场景。 2.存储介质上:支持按需将数据进行冷热分层存储,实现更加低成本的数据存储,包含:冷热分层存储。 | 表存储格式:列存、行存、行列共存数据分层存储 |
| -------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 数据湖等外表存储 | 可直接访问存储MaxCompute、OSS上的数据,实现离线数据加速,数据湖数据加速,包含:OSS存储、MaxCompute存储。 | OSS数据湖加速通过创建外部表加速查询MaxCompute数据 |
开发工具和分析工具
| 功能 | 功能描述 | 参考文档 |
|---|---|---|
| HoloWeb | Holoweb是基于Hologres引擎的可视化数据库管理和开发一站式平台,灵活适用于数据库管理、数据库接入、数据开发、数据分析、性能分析和诊断等用户场景。 | 连接HoloWeb |
| ----------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| DataWorks | DataWorks是阿里云的一站式开发平台,提供数据开发、数据集成、数据服务、数据地图等能力,Hologres与DataWorks深度集成,可以直接绑定Hologres实例进行一站式实时数仓开发,满足业务的不同场景开发和管理需求。 | DataWorks数仓开发概述 |
| Hologres Client | HoloClient是在JDBC基础上自研的开发接口,可实现自动攒批、自动路由分区、消费Binlog等功能,满足业务的高性能大批量数据写入、高QPS点查和维表关联场景。 | 通过Holo Client读写数据 |
| JDBC/ODBC | Hologres提供标准JDBC/ODBC接口,可实现应用低成本直连Hologres。 | JDBC |
| PSQL/PGAdmin客户端 | Hologres兼容PostgreSQL,可以直接连接PG标准客户端,如PSQL、PGAdmin等客户端。 | PSQL客户端 |
| Flink、Spark等Connector | Hologres提供多种数据写入Connector,与Flink、Spark等计算框架原生集成,通过内置Connector,支持大数据实时写入与更新。 | 数据同步概述 |
| BI分析工具 | 可与多种BI工具如Quick BI、Tableau、Datav等无缝对接,实现数据的高性能分析。 | BI分析及可视化概述 |
数据同步
| 功能 | 功能描述 | 参考文档 |
|---|---|---|
| Flink实时写入与读取 | 1.Hologres作为Flink结果表,实现直接实时写入、(整行、局部)更新写入Hologres;2.Hologres作为Flink维表,实现高性能Flink维表关联查询。3.Hologres可作为Flink源表,实现CDC读取、全增量读等。满足一站式实时数仓建设。 | BI分析及可视化概述结果表示例宽表Merge和局部更新功能维表示例源表示例 |
| ------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| Kafka实时写入 | 提供多种方式将Kafka数据投递至Hologres,包括Flink写入、DataWorks数据集成写入以及Hologres Connector等。 | Kafka通过DataWorks实时同步 |
| MySQL、PostgreSQL等数据库整库实时同步 | 通过DataWorks数据集成可以实现MySQL、PostgreSQL等数据库的数据全量离线以及增量实时同步至Hologres。 | MySQL分库分表实践 |
| Spark写入Hologres | 可以通过Hologres Connector实现Spark写入Hologres,以及读取Hologres,完整数仓开发链路。 | Spark的数据写入至Hologres |
| SLS日志数据实时写入Hologres | 可以通过Flink、DataWorks数据集成等方式将SLS日志服务的数据实时写入Hologres。 | 日志服务数据同步至Hologres |
| MySQL等数据库数据离线写入 | 可以通过DataWorks数据集成将MySQL等数据库数据离线单表、整库同步到Hologres。 | 数据库中的数据离线同步至Hologres |
| 本地文件 | 可以通过COPY命令行将本地数据一键写入Hologres。 | 使用COPY命令导入或导出本地数据 |
| OSS数据湖 | 在Hologres中可以创建OSS外表,实现OSS数据湖数据加速,也可以将OSS数据导入到Hologres进一步分析,实现湖仓一体。 | OSS数据湖加速 |
| MaxCompute | 在Hologres中可以创建MaxCompute外表,加速离线数据查询,也可以通过SQL方式将MaxCompute数据离线导入至Hologres,实现进一步的数仓快速查询,满足BI分析等业务。 | 通过创建外部表加速查询MaxCompute数据 |
| Holo shipper | 提供实例、表级别的数据同步至Hologres。 | 迁移工具Holo Shipper |
安全&合规
| 功能 | 功能描述 | 参考文档 |
|---|---|---|
| RAM权限管理 | 提供RAM账号的授权与访问控制。 | 授予RAM用户权限 |
| ------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 专家和简单权限模型 | 支持专家、简单权限模型,满足企业对表、库以及实例的多重细粒度权限控制。 | Hologres权限模型 |
| 数据脱敏 | 可实现对指定用户、指定表按照一定的规则脱敏,满足对数据的高度保护。 | 数据脱敏 |
| IP白名单 | 可设置指定IP指定用户访问实例,提升实例的安全性。 | IP白名单 |
| 数据存储加密和读取MaxCompute加密数据 | Hologres支持通过密钥管理服务KMS对数据进行加密存储,提供数据静态保护能力,满足企业监管和安全合规需求。 也支持读取Maxcompute加密数据。 | 数据加密 |
| 传输加密 | 可通过SSL在传输层对网络连接进行加密,提升通信的安全性和完整性。 | 传输加密(Beta) |
| 数据血缘 | Hologres通过DataWorks,可以基于解析调度作业等真实数据的流转情况,得出表、字段之间的血缘关系,满足数据治理需求。 | 数据血缘(Beta) |
| 数据地图 | 可以通过DataWorks数据地图提供企业数据目录的管理功能,支持元数据详情查看、数据类目管理等。 | 数据地图(Beta) |
| 操作事件日志 | Hologres支持通过阿里云操作审计ActionTrail的控制台、OpenAPI、开发者工具等,查询90天内的实例操作事件日志,以完成对事件的审计和问题回溯分析等。 | 查询事件日志 |
管理&运维
| 功能 | 功能描述 | 参考文档 |
|---|---|---|
| 自助升级 | 用户可以在管控台实现自助升级,提升运维操作方便性。 | 实例升级 |
| ------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 云监控 | 提供数十种监控指标,对接云监控,全面了解实例资源使用、业务运行等情况,及时收到异常告警并响应,保证业务持续正常运行。 | 云监控 |
| 慢Query日志Query Log | 慢Query的查询与分析可以帮助您对系统中发生的慢Query或失败Query进行诊断、分析和采取优化措施。 | 慢Query日志查看与分析 |
| 表统计信息日志Table info | 提供表统计信息日志系统表table_info按日收集实例内表的统计信息,帮助对实例中的表信息进行查看、分析,以便根据这些信息采取优化措施。 | 表统计信息查看与分析 |
| 备份与恢复 | 支持自动周期备份和手动备份,以便您在某些场景下,例如数据误操作时,恢复历史数据。 | 备份与恢复 |
数据湖加速分析
| 功能 | 功能描述 | 参考文档 |
|---|---|---|
| 通过DLF读取OSS数据 | Hologres通过与DLF、OSS无缝集成,以外部表的方式,无需移动数据(外表只做字段映射,不真正存储数据),就能直接加速读写存储于OSS上的各种格式类型的数据,降低开发运维成本,打破数据孤岛,实现业务洞察。 | OSS数据湖加速 |
| ---------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 基于OSS-HDFS构建数据湖 | 对于存储在OSS-HDFS上的数据,Hologres通过DLF实现元数据管理,通过JindoSDK实现数据的直接访问以及回写,回写目前仅支持ORC、Parquet、CSV及SequenceFile格式的表。 | 基于OSS-HDFS构建数据湖 |
高可用部署
| 功能 | 功能描述 | 参考文档 |
|---|---|---|
| 单实例Shard级多副本 | 提供实例内部的Shard级多副本能力,通过设置Table Group副本数的方式来提高某个Table Group查询并发能力和可用性。 | 单实例Shard级多副本 |
| ---------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 主从实例读写分离(共享存储) | 针对线上生产环境高可用的场景,提供了共享存储的主从多实例部署方式,在该模式下支持故障隔离,负载隔离,有效支撑了高可用场景。 | 主从实例读写分离部署(共享存储) |
| 计算组实例 | 计算组实例是主从实例的升级模式,支持将计算资源分解为不同的计算组(Virtual Warehouse),计算组独立弹性可扩展(弹性分配、按需创建),计算组之间共享数据、元数据,通过计算组可同时支撑读写分离、资源隔离、业务隔离等诸多场景,对用户提供资源隔离、弹性等核心能力。 | 计算组实例快速入门 |
产品优势
-
Hologres兼容PostgreSQL生态,支持快速查询分析MaxCompute的数据、实时查询实时写入的数据、联邦分析实时数据与离线数据,帮助您快速搭建企业实时数据仓库。
-
Hologres专注实时数仓需求,从以下几个方面创新,提高数仓开发效率,降低应用门槛。
-
专注实时场景
数据实时写入、实时更新,无需批处理,写入即可见。Hologres与Flink、Spark原生集成,支持高吞吐、低延时、有模型、高质量的实时数仓开发,满足业务洞察实时性需求。 -
亚秒级交互式分析
Hologres支持海量数据亚秒级交互式分析,无需预计算,支持多维分析、即席分析、探索式分析、MaxCompute加速分析,满足所见即所得式数据分析。Hologres采用向量化计算和智能索引优化技术,性能和并发能力大幅提升。 -
统一数据服务出口
一个引擎支持多维分析、高性能点查、数据检索等多样化的场景,同时支持负载隔离,简化数据架构,统一数据访问接口与安全策略。 -
开放生态
标准SQL接口,兼容PostgreSQL 11协议,无缝对接主流BI和SQL开发框架,支持19+款主流BI工具,无需应用重写,无额外学习成本。支持数据湖场景,支持JSON等半结构化数据,OSS、DLF简易入湖入仓。 -
MaxCompute查询加速
快速查询分析MaxCompute的数据,Hologres与MaxCompute无缝连接,您无需导入导出即可查询MaxCompute表的数据,快速获取查询结果。支持MaxCompute对接BI工具,支持交互式分析场景。 -
计算存储分离架构
采用计算与存储分离的云原生架构,存储资源和计算资源分离部署并独立扩展。
支持动态升降配,您可以根据业务需求灵活地扩容或缩容Hologres资源。资源越多,查询的并发数量越大。
应用场景
-
Hologres兼容PostgreSQL生态,是新一代的阿里云实时数仓产品,与大数据生态无缝连接,支持实时与离线数据,对接第三方BI工具,实现可视化分析业务。本文为您介绍基于Hologres核心功能的典型应用场景。
-
Hologres的典型应用场景如下:
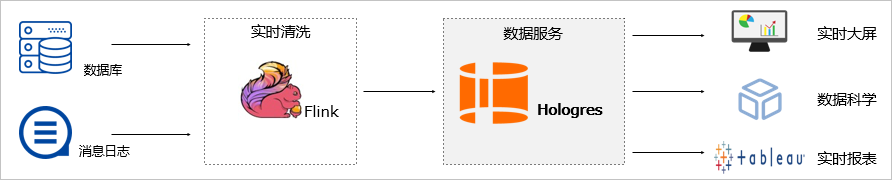
搭建实时数仓
- 实时写入业务数据至实时计算后,使用ETL(Extract Transformation Load)方式清洗、转换及整理数据。您可以通过Hologres实时查询并输出数据至第三方分析工具进行实时分析。典型应用场景如下:
- 数据部门搭建阿里云实时数仓产品、展示实时大屏和分析实时Reporting报表。
- 运维和数据应用部门执行实时监控、实时异常检测预警与实时调试。
- 业务部门进行实时风控、实时推荐、实时效果分析和实时训练。
MaxCompute加速查询
- 写入业务数据至离线数据仓库MaxCompute,通过Hologres直接加速查询或导入数据至Hologres查询,并对接BI分析工具,实现实时分析离线数据。典型应用场景如下:
- 实时查询MaxCompute离线数据。
- 分析MaxCompute离线数据报表。
- 输出MaxCompute离线数据的在线应用,例如RESTful API的使用。

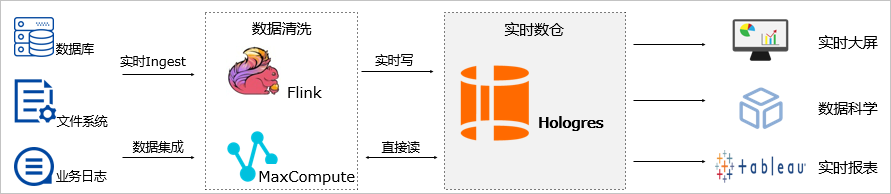
联邦分析实时数据和离线数据
- 业务数据分为冷数据和热数据,冷数据存储在离线数据仓库
MaxCompute中,热数据存储在Hologres中。
Hologres可以联邦分析实时数据和离线数据,对接BI分析工具,快速响应简单查询与复杂查询的业务需求。
X 参考文献
- Hologres - Aliyun

![[Flink/Hologres/汽车] 零跑汽车:Flink+Hologres 驱动零跑科技实时计算的应用与实践 [转]](http://pic.xiahunao.cn/[Flink/Hologres/汽车] 零跑汽车:Flink+Hologres 驱动零跑科技实时计算的应用与实践 [转])
![[Flink/Hologres/汽车] 理想汽车:基于 Hologres + Flink 构建万亿级车联网信号实时分析平台 [转]](http://pic.xiahunao.cn/[Flink/Hologres/汽车] 理想汽车:基于 Hologres + Flink 构建万亿级车联网信号实时分析平台 [转])

![[Flink/Hologres/汽车] 骋在数据洪流上:Flink+Hologres驱动零跑科技实时计算的应用与实践 [转]](http://pic.xiahunao.cn/[Flink/Hologres/汽车] 骋在数据洪流上:Flink+Hologres驱动零跑科技实时计算的应用与实践 [转])


:从概念到RAG实战,这套方法论让我从0到1落地企业级AI应用)

,从获取安装包到成功启动)






:控制台与调试 Sinks(.net8))
)
)

