- 作业1
1)用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
代码与运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup
import warnings
warnings.filterwarnings("ignore")def crawl_university_ranking():url = "http://www.shanghairanking.cn/rankings/bcur/2020"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"}try:response = requests.get(url, headers=headers, verify=False)response.raise_for_status()response.encoding = response.apparent_encodingsoup = BeautifulSoup(response.text, "lxml")table = soup.find("table", class_="rk-table")rows = table.find_all("tr")[1:]print("=" * 60)print(f"{'排名':<4}{'学校名称':<12}{'省市':<6}{'学校类型':<8}{'总分':<6}")print("-" * 60)for row in rows:cols = row.find_all("td")if len(cols) < 5:continuerank = cols[0].text.strip()name = cols[1].text.strip()province = cols[2].text.strip()type_ = cols[3].text.strip()score = cols[4].text.strip()print(f"{rank:<4}{name:<12}{province:<6}{type_:<8}{score:<6}")print("=" * 60)except Exception as e:print(f"爬取失败,错误原因:{str(e)}")
if __name__ == "__main__":crawl_university_ranking()

2)作业心得
本次爬取大学排名的核心是定位 HTML 表格结构:通过 BeautifulSoup 的find("table", class_="rk-table")快速找到排名表格,再遍历和标签提取数据。过程中遇到两个问题:一是网页 SSL 证书警告,通过verify=False解决;二是部分学校名称含空格,用strip()去除后格式更整齐。此外,模拟浏览器的User-Agent请求头是避免被反爬拦截的关键,后续爬取其他网站需注意保留该设置。
- 作业2
1)用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
代码与运行结果
点击查看代码
import urllib.request
import redef dangdang_bookbag_crawler():url = "https://search.dangdang.com/?key=%CA%E9%B0%FC&category_id=10009684#J_tab"try:response = urllib.request.urlopen(url, timeout=3)html = response.read().decode('gb2312')li_pattern = re.compile(r'<li[^>]*?>(.*?)</li>', re.S)lis = li_pattern.findall(html)name_pattern = re.compile(r'<a\s*?title="\s*([^"]*?)"', re.S)price_pattern = re.compile(r'<span class="price_n">(.*?)</span>', re.S)valid_count = 0print("当当网“书包”商品爬取结果:")print(f"{'序号':<4}{'价格':<10}{'商品名'}")print("-" * 80)for idx, li in enumerate(lis, start=1):name_list = name_pattern.findall(li)price_list = price_pattern.findall(li)if name_list and price_list:product_name = name_list[0].strip()product_price = price_list[0].strip().replace('¥', '¥')print(f"{idx:<4}{product_price:<10}{product_name}")valid_count += 1print("-" * 80)print(f"共爬取到 {valid_count} 件有效商品")except urllib.error.HTTPError as e:print(f"请求错误:HTTP状态码 {e.code}(可能是反爬拦截,建议添加请求头)")if __name__ == "__main__":print("开始爬取当当网“书包”商品数据...\n")dangdang_bookbag_crawler()print("\n爬取任务结束!")
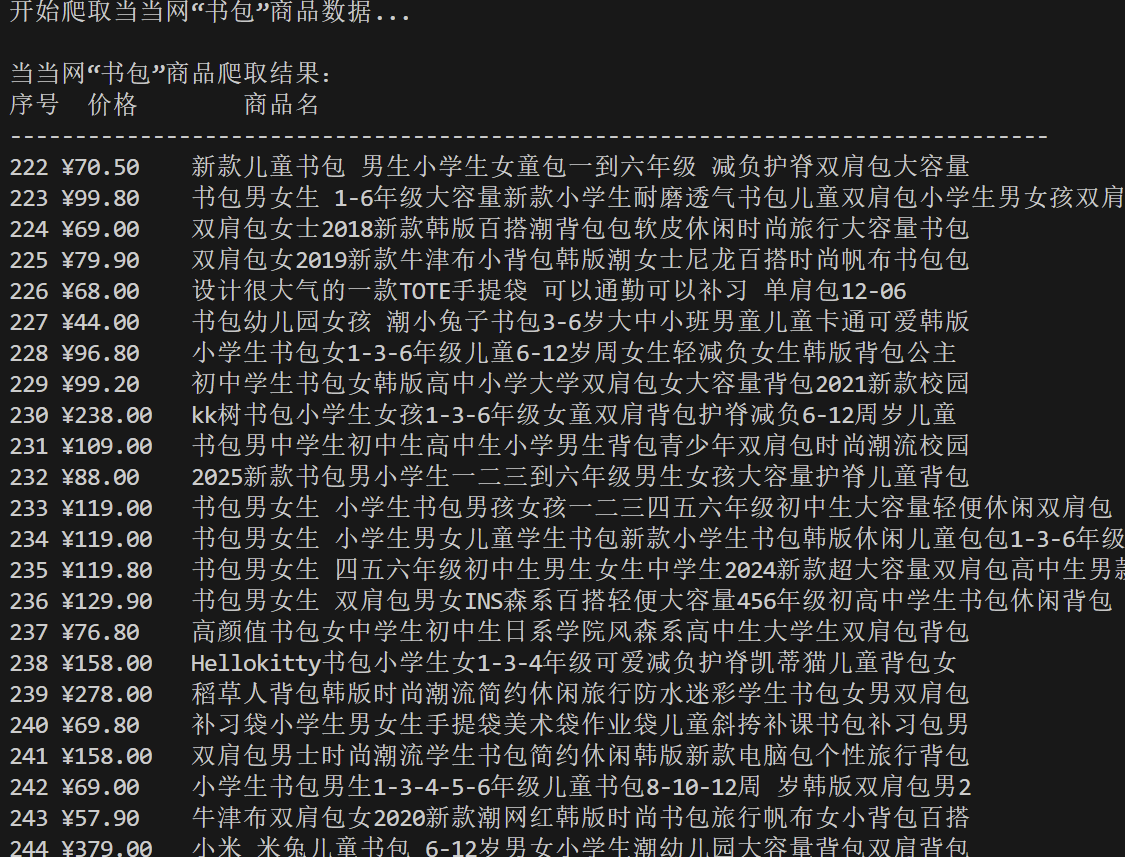
2)作业心得
通过本次调试,深刻理解Cookie在反爬中的核心作用:当当网会通过Cookie识别用户身份,若请求中缺少有效Cookie,服务器会返回 “无商品数据” 的空页面(即使User-Agent正确)。因此,爬取前必须从浏览器复制真实Cookie,这是突破基础反爬的必要步骤。
- 作业3
1)爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
代码与运行结果
点击查看代码
import re
import urllib.request
import os
from colorama import Fore, Style, initinit(autoreset=True)# ------------------------------
# 1. 定义函数:下载网页
# ------------------------------
def get_html(url):headers = {"User-Agent": "Mozilla/5.0"}req = urllib.request.Request(url, headers=headers)with urllib.request.urlopen(req) as response:html = response.read().decode("utf-8", errors="ignore")return html# ------------------------------
# 2. 定义函数:从HTML中提取jpg图片链接
# ------------------------------
def get_jpg_links(html, base_url):# 匹配 .jpg 文件链接pattern = re.compile(r'src="([^"]+?\.jpg)"', re.IGNORECASE)links = pattern.findall(html)domain = re.match(r"(https?://[^/]+)", base_url).group(1)full_links = []for link in links:if link.startswith("http"):full_links.append(link)elif link.startswith("/"):full_links.append(domain + link)else:full_links.append(base_url.rsplit("/", 1)[0] + "/" + link)return list(set(full_links))# ------------------------------
# 3. 定义函数:下载图片
# ------------------------------
def download_images(links, folder="images"):if not os.path.exists(folder):os.makedirs(folder)for i, url in enumerate(links, start=1):try:filename = os.path.join(folder, f"img_{i}.jpg")urllib.request.urlretrieve(url, filename)print(Fore.GREEN + f"下载成功: {filename}")except Exception as e:print(Fore.RED + f"下载失败: {url} ({e})")# ------------------------------
# 4. 主程序:多页面爬取
# ------------------------------
if __name__ == "__main__":base_pages = ["https://news.fzu.edu.cn/yxfd.htm","https://news.fzu.edu.cn/yxfd/1.htm","https://news.fzu.edu.cn/yxfd/2.htm","https://news.fzu.edu.cn/yxfd/3.htm","https://news.fzu.edu.cn/yxfd/4.htm","https://news.fzu.edu.cn/yxfd/5.htm",]all_links = []for page in base_pages:print(f"\n正在爬取页面: {page}")html = get_html(page)links = get_jpg_links(html, page)print(f" 找到 {len(links)} 张图片")all_links.extend(links)# 去重all_links = list(set(all_links))print(f"\n共提取 {len(all_links)} 张图片,开始下载...\n")download_images(all_links)print("\n 所有图片下载完成!")
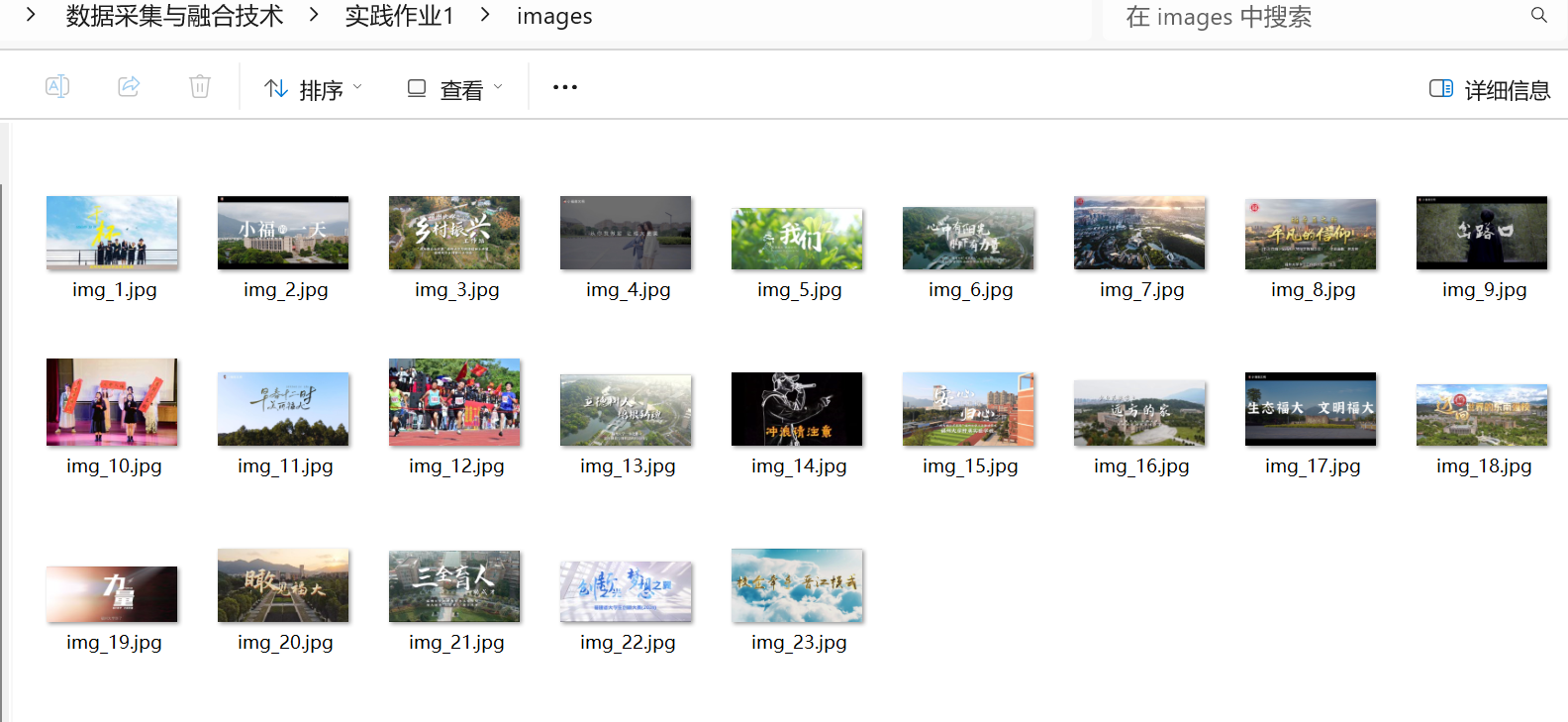
2)作业心得
先通过urllib.request结合请求头获取网页源码,再用正则表达式精准匹配标签的图片链接,尤其学会了处理不同路径类型 —— 绝对路径直接使用、根相对路径拼接域名、相对路径拼接页面基础路径,避免了链接无效的问题;同时通过set去重和os.makedirs创建文件夹,实现了图片的批量、有序保存,还通过异常捕获处理了 URL 失效、网络波动等问题,确保爬取流程稳定。










![Codechef Painting Tree 题解 [ 蓝 ] [ 树形 DP ] [ 概率期望 ] [ 分类讨论 ]](http://pic.xiahunao.cn/Codechef Painting Tree 题解 [ 蓝 ] [ 树形 DP ] [ 概率期望 ] [ 分类讨论 ])

)
 :Control Flow Management in Modern GPUs)


![[题解]P7074 [CSP-J 2020] 方格取数](http://pic.xiahunao.cn/[题解]P7074 [CSP-J 2020] 方格取数)


