【机器人】SG-Nav 分层思维链H-CoT | 在线分层3D场景图 | 目标导航 - 教程
2025-10-18 19:28 tlnshuju 阅读(0) 评论(0) 收藏 举报SG-Nav是一种基于LLM的零样本目标导航框架,其核心设计包括:
构建在线分层3D场景图、采用分层思维链(H-CoT)提示 LLM、引入基于图的重感知机制
该框架已在MP3D、HM3D、RoboTHOR 三大基准数据集上,证明了其在复杂环境中目标探索与导航的有效性。
论文地址:SG-Nav: Online 3D Scene Graph Prompting for LLM-based Zero-shot Object Navigation
代码地址:https://github.com/bagh2178/SG-Nav
下面是示例效果:
参考链接:复现 SG-Nav 具身导航
一、SG-Nav 简介
SG-Nav 是基于LLM的零样本目标导航框架,核心目标是解决现有同类方法的三大痛点:缺乏场景上下文感知、LLM 推理能力未充分发挥、难以高效处理感知误差。
在零样本目标导航任务中,智能体无需针对特定场景训练或微调,仅需依据输入的 RGB-D 数据(含彩色图像与深度信息)和目标类别文本,就能在未知环境中导航至目标物体;任务成功的判定标准为:在规定步数内停在目标物体的指定距离范围内。
为实现这一目标,SG-Nav 利用三大核心设计协同工作:
- 一是构建在线分层 3D 场景图,补足场景上下文;
- 二是采用分层思维链(H-CoT)提示 LLM,充分激活其推理能力;
- 引入基于图的重感知机制,化解感知误差问题。就是三
目前,该框架已在 Matterport3D(MP3D)、Habitat-Matterport 3D(HM3D)、RoboTHOR 三大基准数据集上完成实验验证,证明了其在复杂环境中目标探索与导航的有效性。
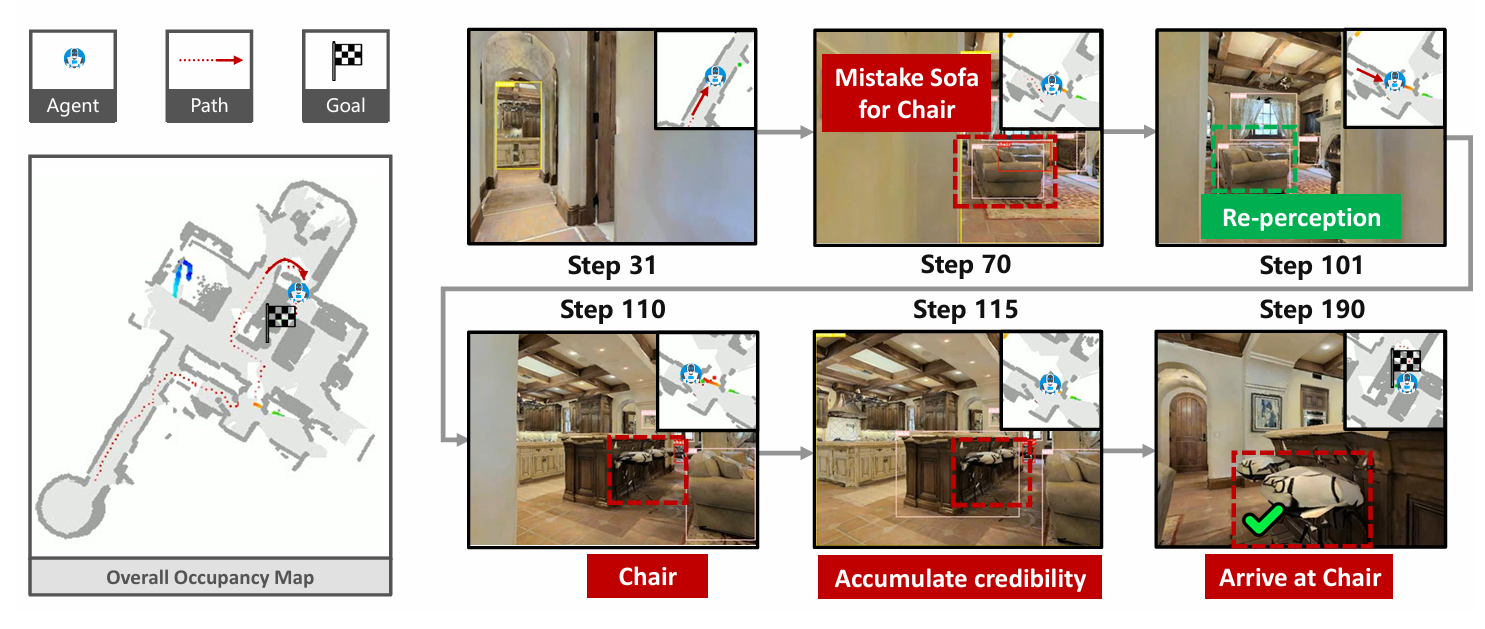
如下图所示,左侧:SG-Nav 的 “结构化场景 + 精准导航”。中间:H-CoT 与子图推理的 “桥梁作用”。右侧:传统智能体的 “碎片化推理与失败导航”
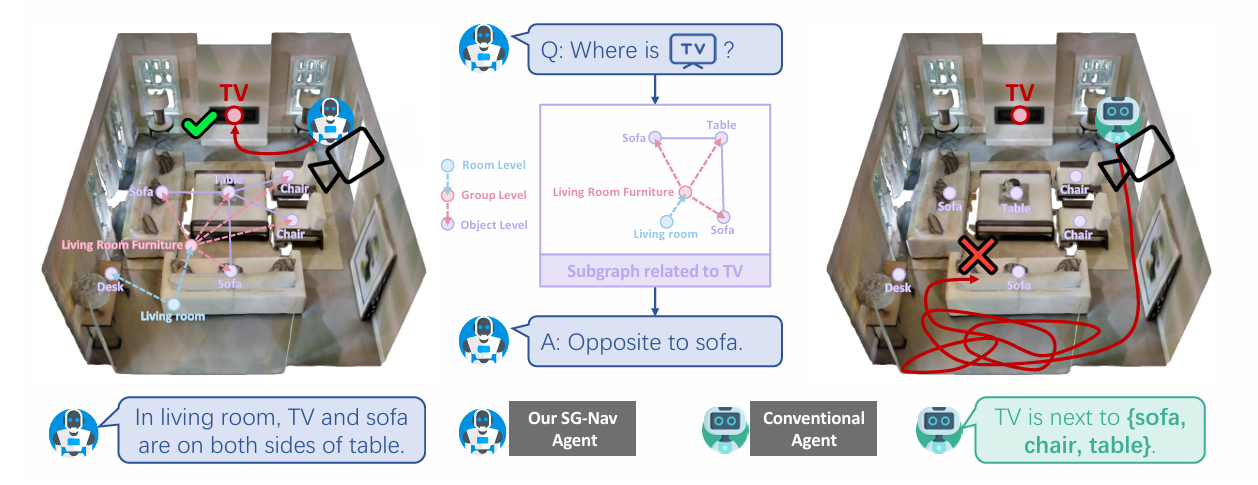
这张图通过对比,核心传达了SG-Nav 的 “分层 3D 场景图 + 层次化链式思维提示(H-CoT)” 技术组合的价值:
- 结构化场景图为 LLM 献出了 “完整、层次化” 的场景上下文,避免传统方法的 “信息碎片化”;
- H-CoT 让 LLM 能基于场景图的结构关系(而非零散物体)进行推理,确保目标定位精准;
- 最终实现 “导航更准确、推理可解释” 的零样本目标导航,超越传统方法的性能瓶颈。
二、SG-Nav 特点分析
2.1. 场景表征:结构化捕捉动态场景信息
分层 3D 场景图:全维度上下文建模
构建包含物体、组、房间三类节点的分层结构,实现从细粒度语义到粗粒度空间的完整场景刻画:
- 物体节点:通过开放词汇 3D 实例分割生成,附带语义类别、置信度等核心属性;
- 组节点:由 LLM 辅助聚合,将机制或空间关联的物体归为一类(如 “客厅家具组”);
- 房间节点:通过房间实例分割直接获取,界定空间归属边界。
这种结构能精准保留物体间的空间与效果关系,例如清晰呈现 “沙发属于客厅家具组,位于客厅中且与桌子相邻” 的关联,为后续推理给予结构化场景知识。
实时更新与精简:高效动态适配
借助双重机制平衡场景覆盖与计算效率:
- 增量更新:新物体节点加入时,采用批量提示 LLM 的方式降低交互频次,避免计算复杂度激增,实现场景图的实时扩展;
- 边缘修剪:依据多维度规则去除冗余连接 —— 短边需经 VLM(如 LLaVA)验证,长边需满足无遮挡、平行于墙且同房间等条件,确保场景图在动态更新中始终保持精简,为 LLM 推理提供高效输入基础。
2.2. LLM 推理:激活深度可解释性推理能力
分层思维链(H-CoT)提示:分步解析场景
创新采用 “子图拆分 + 分层提问” 的提示策略,最大化 LLM 的推理价值:
- 将 3D 场景图拆解为若干子图,以子图为单位输入 LLM;
- 设计递进式问题链:先预测子图与目标的距离,再生成关联问题并解答,最终输出子图含目标的概率;
- 将子图概率插值到探索前沿,得到前沿区域的目标存在概率。
这种方式充分激活 LLM 的常识推理与分步决策能力,且推理过程完全可解释,例如会输出 “沙发在客厅,电视通常与客厅沙发相对,因此该子图有电视的概率较高” 的逻辑依据,满足人机交互对决策透明性的需求。
支持适配不同类型 LLM,兼具开源与闭源方案的兼容性:
- 开源选型:如 LLaMA-7B(对应版本 SG-Nav-LLaMA);
- 闭源选型:如 GPT-4-0613(对应版本 SG-Nav-GPT)。
通过对比不同模型的性能表现,为场景需求提供灵活的模型部署选择,具备较强的扩展性。
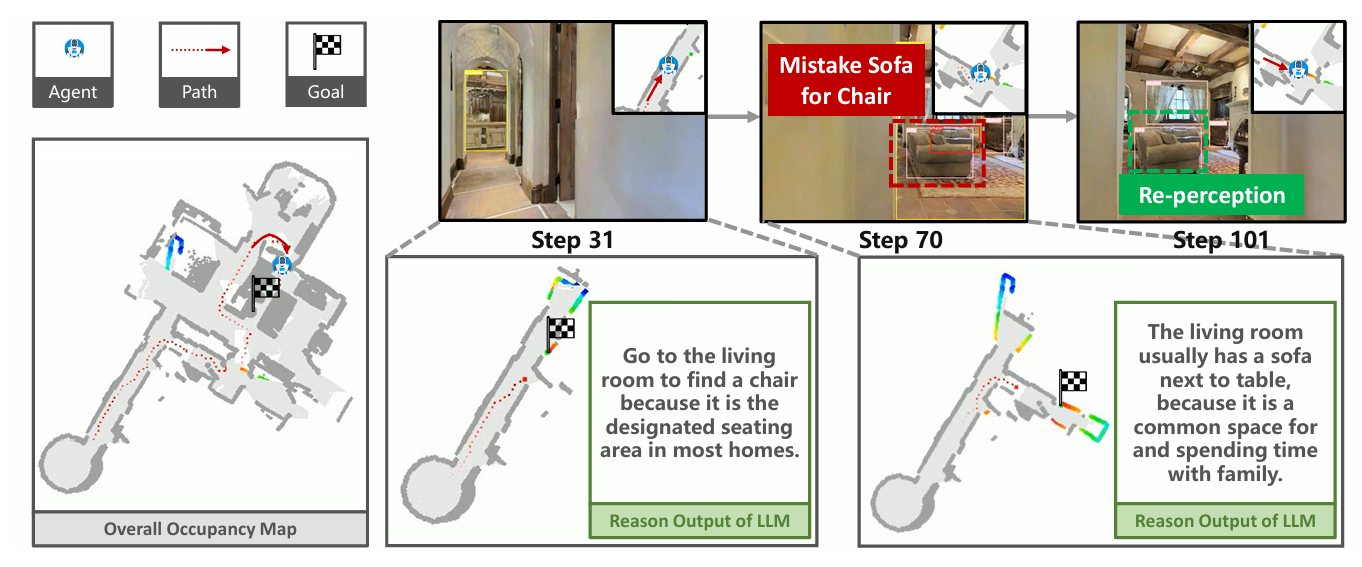
2.3. 应对感知误差:基于图的重感知提升鲁棒性
针对视觉感知中的假阳性问题,设计多视角验证 + 关系校验的重感知机制:
- 触发条件:检测到疑似目标物体时,暂停直接导航;
- 重感知流程:从多个视角重新观测目标区域,结合场景图中的物体关系信息,累积计算目标可信度;
- 判定规则:设定最大观察步数(N_max = 10)与可信度阈值(S_thres = 0.8),若在步数限制内累积可信度达标,则判定为真实目标并导航,否则判定为假阳性并放弃。
该机制从根源上解决了感知误差导致的导航失效挑战,大幅提升智能体在艰难环境中的任务鲁棒性。
2.4. 性能表现:突破现有技巧性能瓶颈
在 MP3D、HM3D、RoboTHOR 三大主流基准材料集上均实现显著突破:
- 在高难度 MP3D 基准中,首次实现零样本方法性能超越有监督途径 —— 传统有监督方法 SemEXP 的 SR 为 36.0,
- 而 SG-Nav(视 LLM 选型)的 SR 可达 40.1 或 40.2,验证了其核心优越性。
在 per-category SR(类别级成功率)对比中,对场景关系依赖度高的目标类别表现尤为突出:
- 针对 fireplace(壁炉)、towel(毛巾)等与其他物体关联紧密的目标,凭借场景图的上下文建模优势,定位精度远超传统方法,展现出对麻烦场景中各类目标的强适配性。
三、模型框架
SG-Nav的模型框架,如下图所示;从 “输入感知” 到 “动作输出与解释”,可分为6 个核心模块,
各模块间通过“素材流动” 实现 “感知 - 建图 - 推理 - 决策 - 解释” 的闭环:
1. 输入与基础建图(左侧模块)
- 输入信息:
Agent Pose(智能体位姿):定位智能体在环境中的位置与朝向;Observation RGB-D(RGB-D 观测):获取环境的彩色图像与深度信息,用于感知物体、空间;Object Goal(目标物体):文本形式的目标(如 “找到电视”),定义导航任务。
- 建图过程:结合
Agent Pose与RGB-D观测,通过Mapping模块生成Occupancy Map(占据栅格图)—— 用栅格表示环境 “已占据 / 未占据” 空间,为后续导航提供基础几何地图。
2. 分层场景图与子图构建(中间左模块)
- 核心作用:将 “几何地图 + 物体感知” 升级为结构化语义表征,保留 “房间 - 组 - 物体” 的层级与关系上下文。
Hierarchical Scene Graph(分层场景图):包含三类节点 ——Room Level(房间,如 “客厅”)、Group Level(物体组,如 “客厅家具组”)、Object Level(物体,如 “沙发”“桌子”),节点间通过边表示空间 / 功能关系(如 “沙发与桌子相邻”)。Subgraphs(子图):将大场景图拆分为多个小的子图(每个子图聚焦部分节点与关系),降低后续 LLM 推理的复杂度,让推理更聚焦。
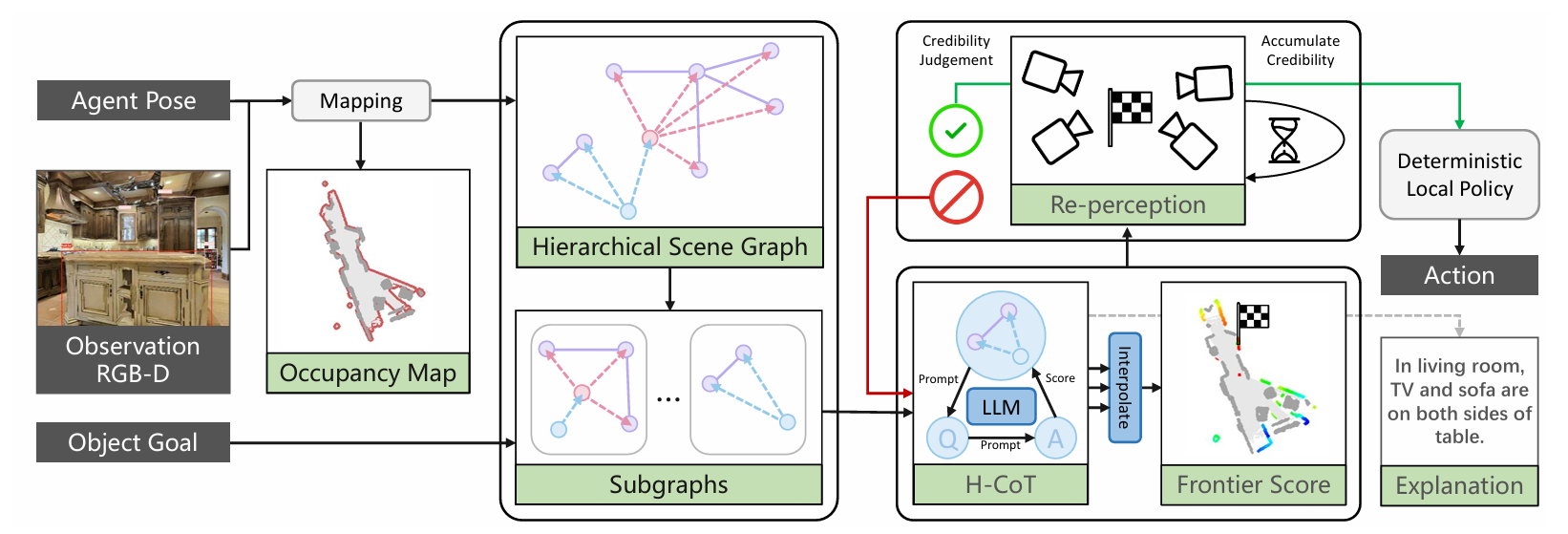
3. LLM 分层思维链(H-CoT)推理(中间右模块)
- 核心作用:激活 LLM 的 “常识推理 + 结构化思考” 能力,为 “前沿区域” 打分。
Prompt(提示词设计):将 “子图 + 目标物体” 转化为自然语言提示(如 “子图中有沙发、桌子,目标是电视,电视可能在哪里?”),输入 LLM;LLM推理:LLM 基于场景图的层级 / 关系(如 “沙发属于客厅家具组”“电视常与沙发相对”),为每个子图与目标的 “相关性” 打分;Interpolate(插值):将 “子图分数” 整合为Frontier Score(前沿区域分数)—— 前沿是 “已探索与未探索区域的边界”,分数越高表示该前沿越可能导向目标。
4. 基于图的基重感知机制(右上模块)
- 核心作用:消除 “感知误差(假阳性目标)” 问题,提升导航鲁棒性。
Re-perception(重感知):当检测到 “疑似目标” 时,智能体从多个视角重新观测该区域;Credibility Judgement(可信度判断):结合多视角观测与场景图关系,计算目标的 “累积可信度”;Accumulate Credibility(累积可信度):若可信度≥阈值(如 0.8),判定为 “真实目标”(绿色对勾);否则判定为 “假阳性”(红色叉号),放弃该目标。
5. 动作生成(右中模块)
Deterministic Local Policy(确定性局部策略):结合两部分信息生成动作:- LLM 推理得到的
Frontier Score(选 “分数最高的前沿” 作为探索方向); - 重感知的
可信度结果(若目标为假阳性,切换到 “继续探索” 模式); - 最终输出
Action(如 “前进”“左转”“停止”)。
- LLM 推理得到的
6. 可解释性输出(右下模块)
Explanation(解释生成):基于 LLM 的推理过程与场景图关系,生成自然语言解释(如 “In living room, TV and sofa are on both sides of table.”),让导航决策 “可解释、透明”,满足人机交互需求。
SG-Nav 通过“分层场景图保留上下文→LLM 推理激活常识→重感知处理感知误差→策略生成动作→解释提升可解释性”的流程,完成 “零样本、鲁棒、可解释” 的目标导航,突破了传统方法 “缺乏上下文、推理黑箱、易受感知误差影响” 的局限。
四、在线3D场景图构建
在线 3D 场景图是 SG-Nav 实现高效零样本目标导航的核心支撑,其核心价值是为后续LLM推理供应结构化、动态化的场景表征。
4.1、构建流程:从节点生成到边优化的全链路
构建流程遵循 “节点生成→边连接→边修剪” 的逻辑,确保场景图既能覆盖完整信息,又能保持精简高效。
1. 三层节点生成:从细粒度物体到粗粒度空间
节点是场景图的基础单元,借助 “物体 - 组 - 房间” 三层结构,构建场景信息的分层刻画:
- 物体节点:基于开放词汇 3D 实例分割技巧,处理智能体获取的 RGB-D 内容,识别环境中的物体。每个节点包含三大核心信息 —— 语义类别(如沙发、桌子)、检测置信度、3D 坐标,精准实现物体的语义与空间定位。
- 组节点:依赖 LLM 的常识推理能力生成。将所有物体节点的类别信息批量提示给 LLM,由 LLM 根据能力或空间关联性聚合物体,例如将 “沙发、茶几、椅子” 归为 “客厅家具组”,完成语义层面的关系抽象。
- 房间节点:通过房间实例分割技术从 RGB-D 数据中提取,明确房间的类别(如客厅、卧室)与 3D 范围,提供粗粒度的空间归属边界,界定物体所在的大空间区域。
2. 边的初始连接:低复杂度实现实时增量更新
边用于表征节点间的关联,初始连接阶段核心应对 “实时扩展” 问题:
- 连接策略:新节点(物体 / 组 / 房间)加入时,先采用 “密集连接” 初步关联所有已有节点;再凭借批量提示 LLM否存在空间 / 机制关系,最终确定有效边。就是的方式,将新节点与旧节点的类别文本打包,让 LLM 一次性判断节点间
- 复杂度优化:该方式将边连接的时间复杂度从O(m(m + n))(m 为新节点数,n 为旧节点数)降至O(m),避免计算量激增,满足场景图的在线增量更新需求。
3. 边的修剪:去除冗余,保证场景图精简有效
修剪阶段通过 “短边 + 长边” 双重规则,筛选无意义连接,确保场景图的有效性:
- 短边修剪:针对同 - RGB-D 帧内物体间的短边,用视觉语言模型(VLM,如 LLaVA)验证。截取两个物体的 2D RGB 图像区域输入 VLM,若 VLM 判定无语义 / 空间关联,则修剪该边。
- 长边修剪:针对远距离节点的长边,需同时满足三个空间规则:① 连线无障碍物遮挡(依据占据栅格图判断);② 边的方向与墙壁平行;③ 连接的节点属于同一房间。不满足任一规则则修剪。
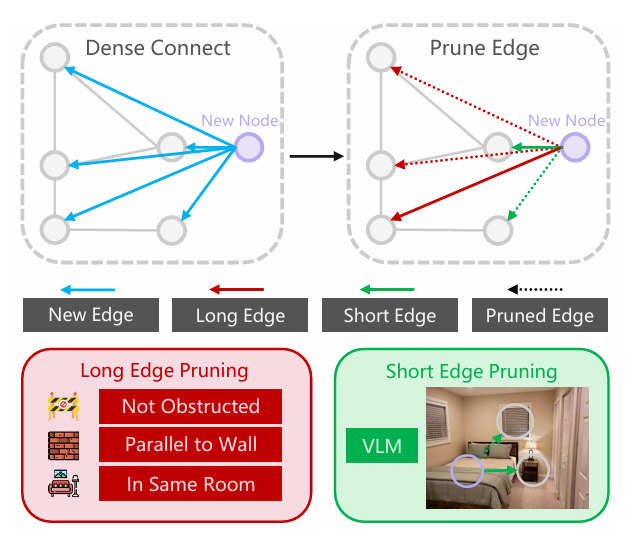
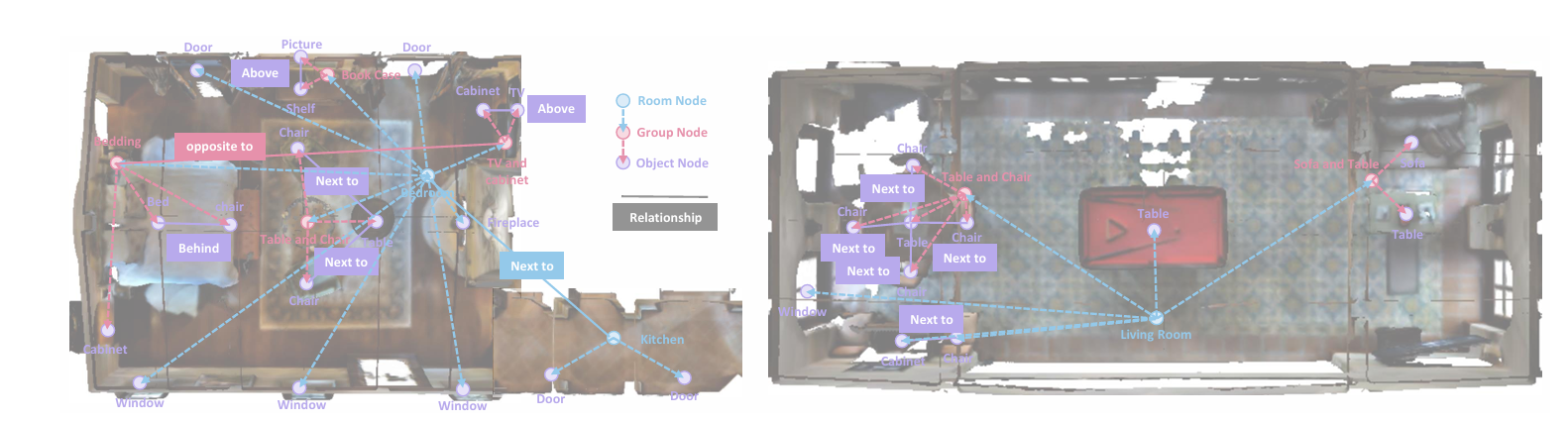
这张示意图直观展示了 SG-Nav 中在线 3D 场景图的 “边连接与修剪” 流程,
核心是通过 “先密集连接、再针对性修剪”,保证场景图的精简性与有效性,为后续 LLM 推理提供高质量的结构化关联。
4.2、构建流程:在线 3D 场景图的价值
1. 为 LLM 推理给予结构化场景上下文
相比传统零样本方法仅用 “目标类别文本” 提示 LLM,场景图提供了更完整的信息:
- 包含物体、物体间关系、空间归属的结构化数据,例如 “沙发与电视相对,沙发在客厅家具组,客厅家具组在客厅”;
- LLM 可基于这些信息做深度推理,大幅提升目标定位的准确性。
2. 支持动态环境适应,保证导航可靠性
经过 “增量更新 + 边修剪” 机制,场景图能动态响应环境变化:
- 智能体探索新区域时,可实时加入新节点、更新边;
- 环境中物体位置变化或连接失效时,可及时修剪无效边,确保场景表征始终准确,为导航决策提供可靠依据。
3. 降低 LLM 推理复杂度,提升决策效率
结构化、精简的场景图,从两方面优化 LLM 推理:
- 避免将大量无序原始数据输入 LLM,减少 LLM 的信息处理负担;
- 清晰的层级与关系让 LLM 推理更高效、逻辑更明确,间接提升智能体导航决策的速度与准确性。
五、层次化链式思维提示决策
在 SG-Nav 框架中,层次化链式思维提示决策(H-CoT)是打通 “3D 场景图结构化表征” 与 “LLM 常识推理能力” 的关键,经过 “子图拆分→分层推理→概率计算→决策解释” 的闭环,解决了传统零样本方法 “LLM 提示碎片化、推理无解释” 的痛点,为导航提供精准且透明的决策依据。
5.1、技术设计逻辑:贴合 3D 场景图,激活 LLM 深度推理
传统链式思维(CoT)多基于 “线性文本” 引导推理,而 H-CoT 针对 3D 场景图 “物体 - 组 - 房间” 的分层结构,设计了 “子图聚焦 + 分层对齐” 的推理逻辑,核心思路有两点:
- 降低 LLM 信息过载:全局 3D 场景图节点 / 边过多,直接输入会干扰 LLM。H-CoT 先将其拆分为 “以单个物体为中心” 的子图(含中心物体、所属组 / 房间、直接连接物体),让 LLM 仅处理 “局部场景上下文”,避免冗余信息干扰;
- 对齐场景与推理分层:3D 场景图的 “物体→组→房间” 层级,天然匹配人类认知逻辑(如 “椅子→客厅家具组→客厅”)。H-CoT 的推理步骤也遵循这一分层 —— 先判断物体关联,再结合组功能、房间属性优化,让 LLM 的常识(如 “电视常与客厅沙发相对”)精准匹配场景,提升推理准确性。
5.2、核心实施步骤:四步完毕 “子图推理→前沿决策”
H-CoT 的核心目标是 “为每个探索前沿计算目标存在概率”,凭借 4 个步骤引导 LLM 输出结构化结果,每步均搭配 “指令 + 示例” 的提示模板:
1. 步骤 1:子图拆分与输入构建 —— 给 LLM “聚焦的场景信息”
- 子图拆分规则:以每个 “物体节点” 为中心,关联其 “父节点(组 / 房间)” 和 “直接连接的物体节点”,形成独立子图。例如 “沙发子图” 包含:沙发(物体)→客厅家具组(组)→客厅(房间),及 “沙发 - 桌子(相邻)”“沙发 - 电视(相对)” 的边;
- 提示词格式:将子图的 “节点类别、层级、边关系” 转化为自然语言,示例:“当前子图:中心物体 [沙发],所属组 [客厅家具组]、房间 [客厅];关联关系 [沙发与桌子相邻、与电视相对]。目标物体 [电视],请完成以下推理。”既保留结构化信息,又避免 LLM 处理图形内容的障碍。
2. 步骤 2:分层推理引导 —— 四阶段激活 LLM 分步思考
不直接让 LLM 输出概率,而是利用 4 个递进阶段补全推理逻辑:
- 阶段 1:物体级距离预测:基于常识预测中心物体与目标的距离,示例提示:“预测 [沙发] 与 [电视] 的最可能距离(米)并说明理由。示例:[桌子 - 椅子]→{‘距离’:0.5,‘理由’:‘椅子紧邻桌子’}”;
- 阶段 2:组 / 房间级问题生成:让 LLM 生成 “补全信息缺口的问题”,示例提示:“基于 [客厅家具组] 和 [客厅] 信息,生成 1 个问题优化距离预测。示例:[冰箱 - 微波炉,厨房电器组]→{‘问题’:‘二者是否同属厨房电器组?’}”;
- 阶段 3:子图信息匹配解答:用子图客观信息回答问题,避免 LLM “幻觉”,示例提示:“已知 [沙发与电视同属客厅家具组、边关系为相对],回答‘二者是否同属一组且有空间关联?’→{‘答案’:‘是’,‘依据’:‘子图呈现同组且相对’}”;
- 阶段 4:距离转子图概率(P_sub):通过公式
(d 为预测距离,ε 避免分母为 0)将距离转化为 0-1 概率,示例提示:“结合推理:沙发与电视距离 2 米、同属客厅家具组且相对→{‘距离’:2.0,‘概率’:0.5,‘总结’:‘概率中等,因同组且相对’}”。
3. 步骤 3:前沿概率插值 —— 将子图概率转化为导航依据
探索前沿(已探索与未探索区域的边界)是智能体的候选探索点,H-CoT 通过 “距离加权” 将子图概率(P_sub)整合为前沿概率(P_fro):
- 核心公式:
- 其中,
是第 i 个前沿的概率,M 是子图总数,
是前沿 i 与子图 j 的欧氏距离;
- 通俗解读:子图越近,对前沿概率的贡献越大(如 “沙发子图距前沿 A1 米,其 0.5 概率的贡献远大于 10 米外的卧室子图”),确保智能体优先探索 “高概率区域附近的前沿”。
4. 步骤 4:决策解释生成 —— 让推理过程透明化
计算出最优前沿(P_fro 最高)后,提示 LLM 总结 “最近 3 个子图的推理过程”,生成自然语言解释,
示例:“选择前沿 A 的原因:1. 距沙发子图 1.2 米(概率 0.5,沙发与电视同组且相对);
电视高频区域),综合概率最高。就是2. 距桌子子图 1.8 米(确认此处为客厅核心区);3. 距客厅子图 2.5 米(客厅
”既解决传统手段 “决策黑箱” 问题,又能在人机交互(如家庭机器人)中提升用户信任。
六、基于图的重新感知机制
在 SG-Nav 框架中,基于图的重新感知机制是攻克零样本目标导航 “感知误差(假阳性目标)” 难题的核心技术。
其通过 “多视角观测→子图可信度加权→累积判定” 的动态闭环,让智能体主动验证疑似目标真实性,彻底摆脱传统方法 “单次误判即导航失败” 的缺陷,为复杂环境下的导航提供关键鲁棒性支撑。
6.1、核心实施流程:四步闭环过滤假阳性目标
该机制仅在 “智能体检测到疑似目标” 时触发,利用 “触发→观测→计算→判定” 四步完成假阳性过滤,每一步均围绕 “提升可信度判断的准确性” 设计:
1. 步骤 1:触发条件 —— 疑似目标触发验证模式
当智能体的 “开放词汇 3D 实例分割模块” 检测到 “类别匹配目标” 的物体(如目标是 “椅子”,检测到标签为 “椅子” 的物体)时,不立即导航触发重新感知机制。此时智能体的任务从 “探索未知区域” 切换为 “围绕疑似目标采集多视角数据”,启动验证流程。就是,而
2. 步骤 2:多视角观测 —— 获取动态感知数据
为避免 “单视角偏见”,智能体会向疑似目标移动,并在移动中从多个视角(正面、侧面、斜上方等)采集 RGB-D 材料,每次观测(记为第 k 次,k=1,2,...,N_{max})同步更新两类关键信息:
- 检测置信度C_k:由 3D 实例分割模块输出,反映该视角下 “物体属于目标类别的概率”(如正面看 “椅子”C_k=0.9,侧面因遮挡降至C_k=0.6);
- 局部子图:将新观测到的物体、关系融入 3D 场景图,生成围绕 “疑似目标” 的局部子图(含疑似目标与周围物体的关联,如 “疑似椅子与桌子相邻”),为后续结合场景关系判断提供依据。
3. 步骤 3:可信度计算 —— 视觉与场景关系加权融合
针对第 k 次观测,机制通过公式计算 “目标可信度S_k”,核心是将单视角视觉置信度与 3D 场景图的子图关系结合,避免仅依赖视觉的片面性。
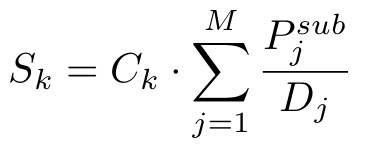


机制的性能依赖两个核心参数的合理设定,同时存在一个隐含约束,确保验证过程既准确又不影响导航效率:
| 参数 | 取值 | 设计依据与约束 |
|---|---|---|
| N_max | 10 | 平衡 “验证精度” 与 “导航效率”:步数过少(如 3 步)可能视角不足误判; 步数过多(如 20 步)会占用总导航步数(500 步上限),导致后续探索时间不足。 10 步是实验验证的最优平衡值。 |
| S_thres | 0.8 | 基于资料集统计设定:MP3D 数据集验证显示, 真实目标的累积可信度普遍≥0.8, 假阳性目标普遍 <0.8, 该阈值能最大化 “真阳性识别率” 与 “假阳性拒绝率” 的平衡。 |
智能体向疑似目标移动时,必须在已探索区域内移动,避免因验证假阳性目标闯入未知区域(增加碰撞风险)。
这一约束经过 “占据栅格图(Occupancy Map)” 的 “已探索区域标记” 建立,确保验证过程安全可控。
七、效果展示
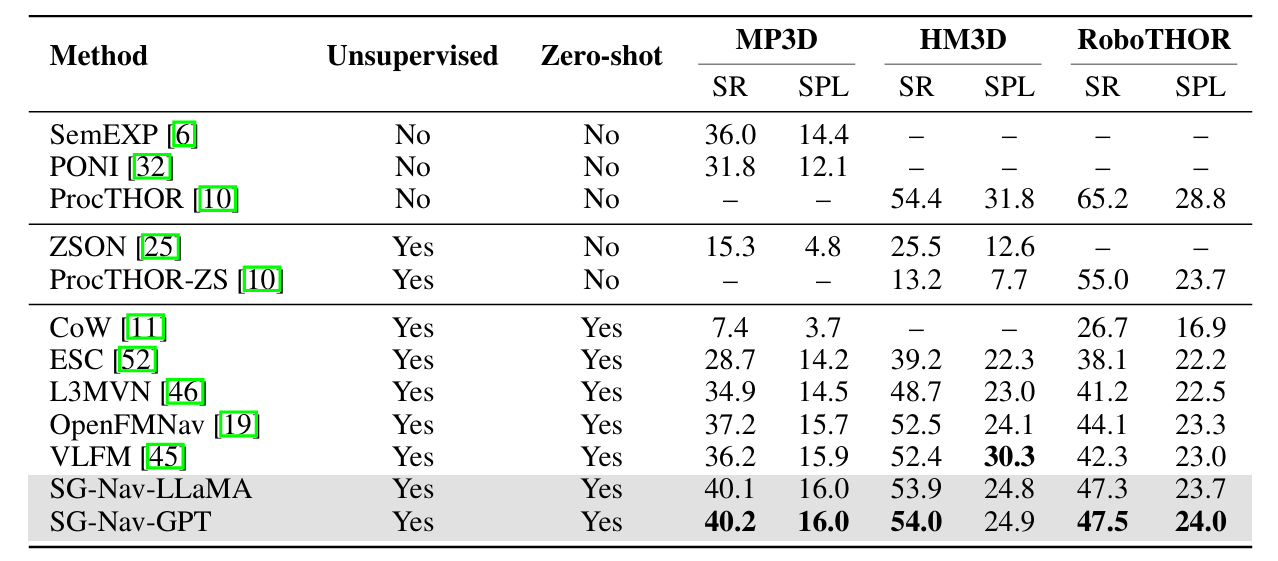
目标导航,在 MP3D、HM3D 和 RoboTHOR 上的结果。
可视化测试示例:
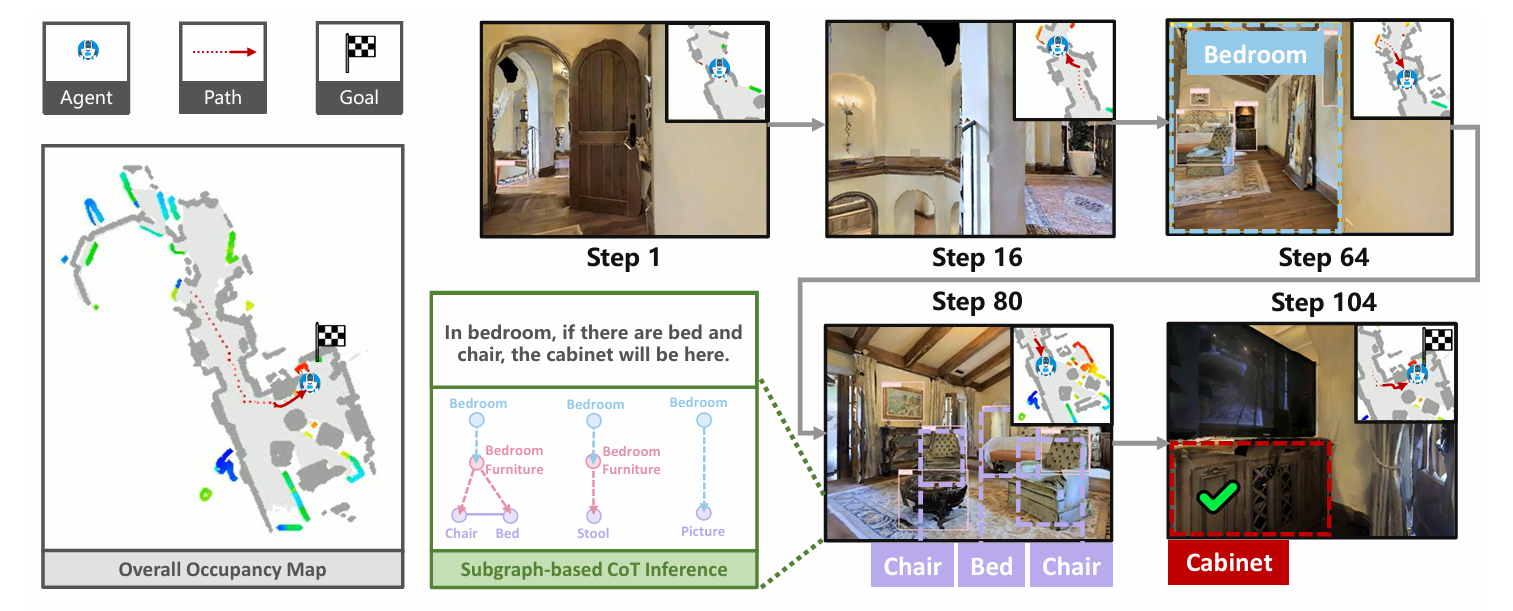
用于 LLM 的前沿评分,推理输出的可视化
- 为前沿区域着色,高分的前沿展示为红色,低分的前沿显现为蓝色
分享完成~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/939735.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

Dr. Jane Goodall

专用硬件神经网络优化技术解析
)
学习逆向的背景知识(自用)
)
Linux-网络安全私房菜(二)

pycharm使用远程的ssh的解释器

Android SSL Pinning检测利器:SSLPinDetect技术解析

AI元人文:社区调解的数字剧场

2025年粉末冶金制品/零件厂家推荐排行榜,专业制造与高品质服务的首选!

详细介绍:【探寻C++之旅】第十六章:unordered系列的认识与模拟实现

Dubbo入门-Dubbo的快速使用



傅里叶变换及DCT点滴

【未完待续】MkDocs 部署安装教程

![[PaperReading] SAIL-Embedding Technical Report: Omni-modal Embedding Foundation Model](http://pic.xiahunao.cn/[PaperReading] SAIL-Embedding Technical Report: Omni-modal Embedding Foundation Model)
[PaperReading] SAIL-Embedding Technical Report: Omni-modal Embedding Foundation Model

How to Practice English Daily for 30 mins


英伟达个人AI超算Spark技术解析
![[buuctf]jarvisoj_level3_x64](http://pic.xiahunao.cn/[buuctf]jarvisoj_level3_x64)