本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
本文 的 原文 地址
尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题:
-
频繁 fullgc,如何排查?
-
GC 毛刺见过吗, 如何排查?
-
线程池耗尽 , cpu打满,如何排查?
最近有小伙伴在面试 阿里、希音等大厂,又遇到了相关的面试题。
小伙伴 没系统梳理, 支支吾吾的说了几句,面试官不满意, 挂了。
接下来,尼恩结合互联网上的一些实际案例, 针对上面的面试题, 大家做一下系统化、体系化的梳理。
总结出一个 尼恩 e2e JVM性能调优方法论 。
使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
尼恩 e2e JVM性能调优方法论
尼恩为大家 整合出一套清晰、可落地的、e2e JVM性能调优方法论。
其核心工作流可以概括为下图:
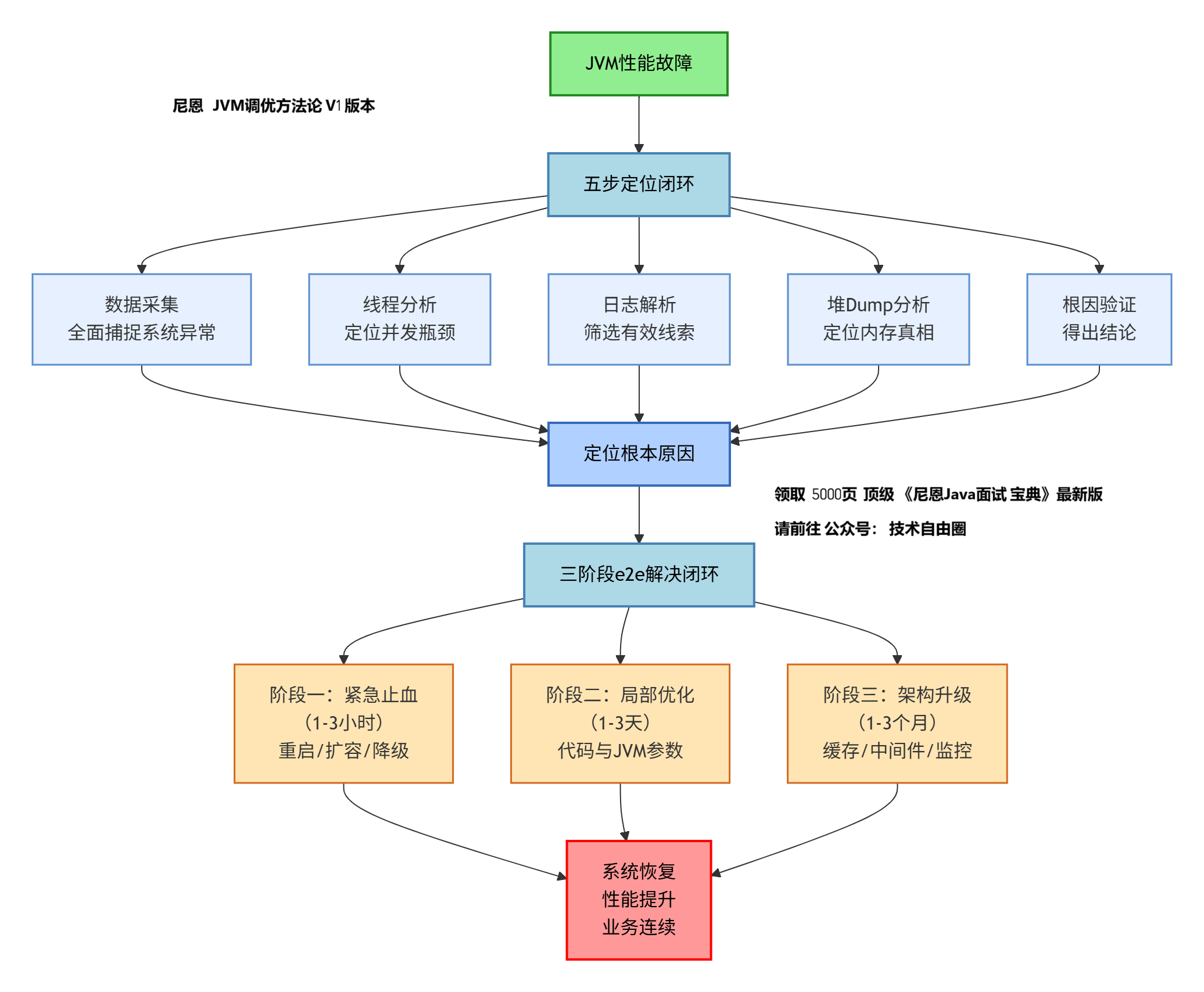
五步定位闭环:从现象到根因的系统化诊断
这套方法的核心在于用数据说话,避免盲目猜测,形成从现象到根因的完整证据链。
第一步:数据采集——全面捕捉系统异常
当系统出现异常(如CPU飙升、响应变慢、OOM)时,需要立即采集以下数据以保留“案发现场”:
- GC日志:通过JVM参数
-Xloggc:gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps开启。关键看Full GC频率、单次GC耗时、GC前后内存回收效果。 - 堆内存快照(Heap Dump):用于分析内存中到底存放了什么对象。可以通过命令
jmap -dump:format=b,file=heap.hprof <pid>主动生成,或设置参数-XX:+HeapDumpOnOutOfMemoryError让JVM在OOM时自动生成。 - 线程快照(Thread Dump):用于分析CPU飙升、死锁、线程阻塞问题。使用命令
jstack <pid> > thread.txt获取。建议间隔5-10秒连续采集多次,以便观察线程状态的变化。 - 实时运行时数据:使用
jstat -gcutil <pid> 1000每秒打印一次各内存区域使用率和GC情况,快速评估GC压力。
第二步:线程分析——定位并发瓶颈
线程问题是高并发场景下性能瓶颈的常见根源。采集到线程快照后,需要分析:
-
线程状态统计:统计各状态线程数量,重点关注
BLOCKED、WAITING状态的线程。# 统计线程状态分布 $ grep "java.lang.Thread.State" thread_dump.txt | sort | uniq -c15 java.lang.Thread.State: BLOCKED (on object monitor)32 java.lang.Thread.State: RUNNABLE8 java.lang.Thread.State: WAITING (on object monitor) -
死锁检测:使用
jstack <pid> | grep -i deadlock或工具自动检测死锁。 -
热点线程分析:结合
top -H -p <pid>找到高CPU线程ID,转换为16进制后在线程快照中查找对应线程栈,定位正在执行的热点方法。
第三步:日志解析——筛选有效线索
- 分析业务日志:从文本日志中提取根因线索,排除无关干扰
- 分析GC日志:重点关注Full GC是否频繁,以及每次GC的停顿时间。如果Full GC后老年代使用率依然很高,可能存在内存泄漏。同时关注GC的触发原因,如
Allocation Failure(分配失败)或Metadata GC Threshold(元空间阈值)。 - 分析线程快照:搜索关键字“deadlock”来快速排查死锁。查看大量线程是否阻塞在同一个锁或资源上。
- 初步查看堆快照:使用
jmap -histo:live <pid> | head -n 20查看当前存活对象中,哪些类的实例数量最多、总大小最大,快速锁定嫌疑对象。
第四步:堆Dump分析——定位内存真相
如果怀疑内存泄漏,堆Dump是最有力的证据。
使用MAT(Memory Analyzer Tool) 或 JVisualVM 打开堆Dump文件。
- 查看支配树(Dominator Tree):直接列出在内存中占据最大空间的对象,并显示其引用链。
- 查找内存泄漏疑点:工具通常会提供Leak Suspects Report,它会自动分析可能的内存泄漏点。重点检查 全局性的集合类(如静态Map)、未关闭的连接(如数据库连接、文件流) 以及线程局部变量(ThreadLocal)是否未及时清理。
第五步:根因验证——得出结论
将前四步的线索串联起来,形成完整的证据链。例如:
- 线索1(GC日志):Full GC频繁,且每次回收后老年代可用空间增长很小。
- 线索2(线程分析):大量线程阻塞在同一个缓存操作上。
- 线索3(堆Dump分析):一个静态的
HashMap占据了80%的堆内存,且其中的缓存条目没有有效的过期机制。 - 结论:由于全局缓存未设置过期策略导致内存泄漏。
三阶段e2e解决闭环:从紧急止血到彻底根治
定位到根本原因后,按照“先止血、再局部优化、后架构升级”的层次推进解决,确保问题彻底根治。
阶段一:紧急止血(目标:1-3小时内恢复服务)
目标是快速恢复服务,避免业务长时间中断。
- 服务重启与隔离:重启是最快的临时解决方案。如果可能,先将故障实例从负载均衡中摘除再重启,避免流量冲击。在K8s环境中,可标记Pod为不可调度并驱逐。
- 弹性扩容:紧急扩容实例,用“人海战术”分担负载,为后续排查争取时间。
- 流量降级与限流:关闭非核心功能或对异常接口实施限流,保障核心链路可用。
阶段二:局部优化(目标:1-3天内优化性能瓶颈)
目标是解决直接痛点,优化性能瓶颈,防止问题复发。
-
代码优化(根本之策) 修复内存泄漏:
例如,将无界缓存改为有界缓存(如Caffeine),并设置合理的过期时间或大小限制。确保资源(如数据库连接、文件流)使用
try-with-resources正确关闭。例如,避免在循环内创建大对象:如JSON序列化、日志拼接等。将大对象的创建移出循环。
例如,优化数据结构与算法:选择正确的集合类,设置合理的初始大小避免频繁扩容。
-
JVM参数调优(辅助手段) 设置堆大小:
-Xms和-Xmx设置为相同值,避免动态调整的开销。根据系统总内存和监控数据设定。 -
选择垃圾回收器: G1 GC(JDK9+):适用于大多数需要平衡吞吐量和延迟的服务端应用。
-
参数示例:
-XX:+UseG1GC -XX:MaxGCPauseMillis=200。 -
ZGC(JDK11+):适用于追求极致低延迟(停顿<10ms)且堆内存非常大的场景。
-
调整新生代:通过
-Xmn显式设置新生代大小。对象创建频繁的应用可适当调大。
阶段三:架构升级(目标:1-3个月内构建长效机制)
目标是构建长效机制,从根本上提升系统韧性,支持业务未来增长。
- 引入更健壮的中间件:例如,用Redis等分布式缓存替代JVM本地缓存,彻底解决JVM内存管理问题。
- 完善监控告警体系:搭建Prometheus + Grafana监控平台,对JVM核心指标(GC次数、耗时、内存使用率)进行持续监控和告警。建立代码块级耗时监控。
- 建立性能压测与故障演练流程:在大促或重大变更前,进行全链路压测,提前发现性能瓶颈。定期进行故障注入演练,验证应急预案有效性。
- 代码规范与评审:将“避免内存泄漏的编码规范”纳入代码评审环节,从源头杜绝问题。
接下来,结合 尼恩 e2e JVM性能调优方法论 ,分析一下 一个大厂的 线程池耗尽、频繁fullgc的事故现场。
注意,下面的文章,来自互联网。
尼恩也只是拿了给大家学习, 学习交流。
由于没有联系原作者,如果原作者不同意尼恩的分析和学习,就只能从尼恩的公众号取下来。
事故现场: 线程池耗尽, 一个 TODO 把整个 大促部门抬走
事故 来自一个头部电商平台, 正为一个S级的“会员闪促”活动做最后的护航,它将在零点准时生效。
作战室里灯火通明,所有人都盯着大盘,期待着活动上线后,GMV曲线能像火箭一样发射。
然而, 刚过0点, 出事故了
告警群里的消息开始疯狂刷屏,声音急促得像是防空警报:
[严重] promotion-marketing集群 - 应用可用度 < 10%
[严重] promotion-marketing集群 - HSF线程池活跃线程数 > 95%
[紧急] promotion-marketing集群 - CPU Load > 8.0立马打开 监控系统——整个promotion-marketing集群,上百台机器,像被病毒感染了一样,CPU和Load曲线集体垂直拉升,整整齐齐。
这意味着,作为促销中枢的服务已经事实性瘫痪。
所有促销页面上,为大会员准备的活动入口,都因服务超时而被降级——活动,上线即“失踪”。
一场精心筹备的S级大促,在上线的第一秒,就“出师未捷身先死”了。
第一幕:无效的挣扎
故障排查。
1. 第一步,看日志。
首先 发现一个NPE(空指针异常),并且 NPE 数量有点多。
但仔细一看,NPE 来自一个非常边缘的富客户端jar包,跟核心链路无关。
NPE 排除。
这个动作, 对应到尼恩jvm调优方法论的具体步骤是: 问题定位方法 - 3. 日志解析
关联原因:日志解析的核心目标是 “从文本日志中提取根因线索,排除无关干扰”。
通过分析业务日志, 筛选关键异常、结合业务链路判断关联性,最终剔除干扰项,避免定位方向走偏。
2. 第二步,怀疑死锁。
HSF线程池全部耗尽,是线程“罢工”的典型症状。
立刻拉取线程快照,用jstack分析,却没有发现任何死锁迹象。
再次排除。
这个动作, 对应到尼恩jvm调优方法论的具体步骤是: 问题定位方法 - 2. 线程分析
线程分析的核心目标是 “排查线程级问题(死锁、线程池耗尽、锁竞争等)”,核心动作是 “用
jstack采集线程快照、识别线程异常状态”。“拉取线程快照” 分析 “排查死锁并排除”,完全符合线程分析的操作逻辑 —— 针对 “线程池耗尽” 的现象,优先验证常见诱因(死锁),排除后进一步缩小根因范围
3. 第三步,重启大法 。
挑了几台负载最高的机器进行重启。
起初两分钟确实有效,但只要新流量一进来,CPU和Load就像脱缰的野马,再次冲顶。
这个动作, 对应到尼恩jvm调优方法论的具体步骤是: 问题解决方法 - 1. 紧急止血(1-3 小时)
紧急止血的核心目标是 “1-3 小时内快速缓解业务中断,为后续定位争取时间”,重启属于典型的临时止血措施 —— 通过重启释放临时占用的线程、内存资源,短暂恢复服务可用性。
虽未根治问题(流量进来后复发),但符合 “优先止损” 的紧急止血原则。
4. 第四步,扩容。
既然单机扛不住,那就用“人海战术”。
紧急扩容了20台机器。
但新机器就像冲入火场的士兵,没坚持几分钟,就同样陷入了高负载、疯狂GC的泥潭。
此时,距离故障爆发已经过去了18分钟。
作战室里的气氛已经从紧张变成了压抑。
这个动作, 对应到尼恩jvm调优方法论的具体步骤是: 问题解决方法 - 1. 紧急止血(1-3 小时)
扩容是紧急止血阶段的 “资源扩容类措施”,核心逻辑是 “通过增加实例数量分散流量压力”。
“紧急扩容 20 台机器” 虽未解决根本问题(新机器同样高负载),但属于 1-3 小时时间窗口内的临时应对动作,目的是尝试缓解集群压力,符合紧急止血 “不追求根治、仅求临时止损” 的目标。
第二幕:深入“肌体”
常规手段全部失效,唯一的办法,就是深入到JVM的“肌体”内部,看看它的“细胞”到底出了什么问题。
我保留了一台故障机作为“案发现场”,然后dump了它的堆内存和线程栈。
这个动作, 对应到尼恩jvm调优方法论的具体步骤是: 问题定位方法 - 2. 线程分析(线程栈采集) + 4. 堆 dump 分析(堆内存采集)
关联原因:线程分析和堆 dump 分析的前提是 “获取完整的线程 / 内存数据”。
“保留故障机” 避免数据丢失,“dump 堆内存 + 线程栈” 是两个定位步骤的核心数据采集动作 —— 线程栈为后续分析线程状态打基础,堆内存为排查内存异常(如老年代高占用)提供数据支撑。
分析堆内存,我发现老年代(Old Gen)的使用率居高不下,CMS回收的效果非常差,导致了频繁且耗时的Full GC,这完美解释了为什么CPU会飙升。
同时, 内存里驻留了大量char[]数组,内容都指向一个和“万豪活动配置”相关的字符串常量。
这说明,有一个巨大的活动配置对象,像一个幽灵,赖在内存里不走。
这个动作, 对应到尼恩jvm调优方法论的具体步骤是: 问题定位方法 - 4. 堆 dump 分析
堆 dump 分析的核心目标是 “排查内存泄漏、大对象占用、分区异常等问题”。
“分析老年代高使用率(CMS 回收差→频繁 Full GC)”“定位大量
char[]数组(关联万豪活动配置大对象)”,完全匹配堆 dump 分析的核心动作 —— 通过内存分区、对象类型分析,解释了 “CPU 飙升” 的底层诱因(Full GC 占用 CPU),并锁定 “大对象驻留内存” 的关键线索。
接着, 开始分析线程栈快照。
用grep简单统计了一下:
# 查看等待的线程
$ sgrep 'TIMED_WAITING' HSF_JStack.log | wc -l336# 查看正在运行的线程
$ sgrep 'RUNNABLE' HSF_JStack.log | wc -l246三百多个线程在等待,两百多个在运行。 问题大概率就出在这两百多个RUNNABLE的线程上。
一个熟悉的身影,反复出现在 屏幕上:
at com.alibaba.fastjson.toJSONString(...)大量的线程,都卡在了FastJSON的序列化操作上!
这个动作, 对应到尼恩jvm调优方法论的具体步骤是: 问题定位方法 - 2. 线程分析
关联原因:线程分析的进阶动作是 “统计线程状态分布、锁定异常活跃线程”。
“用
grep统计 TIMED_WAITING/RUNNABLE 线程数”“判断问题出在 RUNNABLE 线程”,属于线程分析的关键环节 —— 通过状态分布排除 “线程等待过多” 的问题,聚焦 “活跃线程的资源占用”,为后续定位卡点方法打基础“过滤 RUNNABLE 线程堆栈”“发现大量线程卡在 FastJSON 序列化”,完全符合线程分析的深度操作 —— 通过调用链定位具体耗时方法,将 “线程池耗尽” 与 “序列化操作” 直接关联,为根因推导提供关键依据。
结合堆内存里那个巨大的“万豪配置”字符串,一个大胆的猜测浮现在我脑海里:
有一个巨大的对象,正在被疯狂地、反复地序列化,这个CPU密集型操作,耗尽了线程资源,拖垮了整个集群!
这个动作, 对应到尼恩jvm调优方法论的具体步骤是: 问题定位方法 - 5. 根因验证(初步推导)
根因验证的前置动作是 “结合多维度数据(内存 + 线程)推导根因”。
“结合堆内存大对象(万豪配置)+ 线程卡点(FastJSON 序列化)”,推导出 “反复序列化大对象耗尽线程资源” 的结论,属于根因验证的核心逻辑 —— 通过多定位步骤的结果交叉验证,形成初步根因假设。
第三幕:“一行好代码”
顺着线程栈的指引, 很快定位到了代码里的“犯罪现场”:
XxxxxCacheManager.java
在这段代码上方,还留着一行几个月前同事留下的、刺眼的注释:
// TODO: 此处有性能风险,大促前需优化。
正是这个被所有人遗忘的TODO,在今晚,变成了捅向我们所有人的那把尖刀。
这是一个从缓存(Redis)里获取活动玩法数据的工具类。
而 写入缓存的方法,则 让人 大开眼界:
// ... 省略部分代码
// 从缓存(Redis)里获取活动玩法数据的工具类
public void updateActivityXxxCache(Long sellerId, List<XxxDO> xxxDOList) {try {if (CollectionUtils.isEmpty(xxxDOList)) {xxxDOList = new ArrayList<>();}.....// TODO: 此处有性能风险,大促前需优化// 为了防止单Key读压力过大,设计了20个散列Keyfor (int index = 0; index < XXX_CACHE_PARTITION_NUMBER; index++) {// 致命问题:将序列化操作放在了循环体内!RedisCache.put(String.format(ACTIVITY_PLAY_KEY, xxxId, index), JSON.toJSONString(xxxDOList), // 就是这行代码,序列化了20次!EXPIRE_TIME);}} catch (Exception e) {log.warn("update cache exception occur", e);}
}看着这段代码,问题特大。
这个动作, 对应到尼恩jvm调优方法论的具体步骤是: 问题定位方法 - 5. 根因验证(根因确认)
根因验证的最终目标是 “找到代码级具体根因”。
“顺着线程栈定位代码文件”“发现循环体内重复序列化大对象(20 次)”,验证了之前的根因假设,属于根因验证的关键闭环动作 —— 将抽象的 “序列化问题” 落地到具体代码逻辑,明确 “循环内重复序列化” 是根本诱因。
这个代码 解决的是 缓存击穿 : 零点活动生效,缓存里没有数据,发生了缓存击穿,这很正常。
为了防止单Key读压力过大,作者设计了20个散列Key来分散读流量。
解决 缓存击穿 , 这思路也没问题。
但致命的是,在写入缓存时,序列化的操作,竟然被放在了for循环内部!
序列化 的是一个 巨大对象(约1-2MB),而且要循环 20次。
这意味着,每一次缓存击穿后的回写,都会将一个1MB的巨大对象,连续不断地、在同一个线程里,序列化整整20次!
这已经不是代码了,这是一台CPU绞肉机。
而更要命的是,我们的缓存中间件Redis LDB本身性能脆弱,被这放大了20倍的写流量(20 x 1MB)瞬间打爆,触发了限流。
Redis被限流后,写入耗时急剧增加,从几十毫秒飙升到几秒。这导致“CPU绞肉机”的操作时间被进一步拉长。
最终,HSF线程池被这些“又慢又能吃”的线程全部占满,服务雪崩。
修改的代码如下:
// ... 省略部分代码
// 从缓存(Redis)里获取活动玩法数据的工具类
public void updateActivityXxxCache(Long sellerId, List<XxxDO> xxxDOList) {try {if (CollectionUtils.isEmpty(xxxDOList)) {xxxDOList = new ArrayList<>();}.....//代码优化String json= JSON.toJSONString(xxxDOList);//序列化移动到循环外部// 为了防止单Key读压力过大,设计了20个散列Keyfor (int index = 0; index < XXX_CACHE_PARTITION_NUMBER; index++) {// 致命问题:将序列化操作放在了循环体内!RedisCache.put(String.format(ACTIVITY_PLAY_KEY, xxxId, index), json, // 就是这行代码,序列化了20次!EXPIRE_TIME);}} catch (Exception e) {log.warn("update cache exception occur", e);}
}这个动作, 对应到尼恩jvm调优方法论的具体步骤是: 问题解决方法 - 2. 局部代码优化(1-3 天)(优化方向推导)
原因:局部代码优化的核心目标是 “针对代码级根因做修复,避免问题复发”。
“指出序列化应移到循环体外(仅序列化 1 次)”,是典型的局部代码优化方向 —— 针对 “循环内重复序列化” 的根因,修改代码逻辑消除性能瓶颈,且该优化可在 1-3 天内完成(代码修改 + 测试 + 发布),符合局部优化的时间窗口与操作范围。
第四幕:真相与反思
故障的根因已经水落出。
我们紧急回滚了这段“循环序列化”的代码,集群在凌晨0点30分左右,终于恢复了平静。
30分钟,生死时速。
在事后的复盘会上,我分享了 的“改进的三法则”:
法则一:任何脱离了容量评估的“优化”,都是在“耍流氓”。
这次故障的始作俑者,就是一段为了解决“读压力”而设计的“好代码”。
但好的优化是锦上添花,坏的优化是“画蛇添足”。
敬畏之心,比奇技淫巧更重要。
法则二:监控的终点,是“代码块耗时”。
我们有机器、接口、中间件等各种监控,但唯独缺少对“代码块耗 plataformas”的精细化监控。
如果APM工具能第一时间告诉我们90%的耗时都在XxxxxCacheManager的update方法里,排查效率至少能提高一倍。
这个动作, 对应到尼恩jvm调优方法论的具体步骤是:问题解决方法 - 3. 架构升级(1-3 个月)(监控架构优化方向)
原因:架构升级的核心目标是 “解决系统性瓶颈,支撑长期稳定”。
“缺少代码块级 APM 监控” 属于系统性监控缺失,需通过架构升级补全 —— 引入支持 “代码块耗时” 的 APM 工具(如 SkyWalking),实现精细化监控,该动作需 1-3 个月(工具选型 + 部署 + 埋点),符合架构升级的时间窗口。
法则三:技术债,总会在你最想不到的时候“爆炸”。
TODO 技术债务 , 一定要做重点review。
技术债就像家里的蟑螂,你平时可能看不到它,但它总会在最关键、最要命的时候,从角落里爬出来,给你致命一击。
那天凌晨一点,我走在杭州空无一人的大街上,吹着冷风,脑子里却异常地清醒。
因为在那场惊心动魄的“雪崩”里,在那一串串冰冷的线程堆栈中,我再次确认了一个朴素的道理:
所有宏大的系统,最终都是由一行行具体的代码组成的。而魔鬼,恰恰就藏在其中。
JVM调优圣经系列文章
希音面试:频繁 fullgc,如何排查?
听说你是高手?说说你的 JVM调优方法论 吧?(美团面试,问的贼细)
《cms圣经:cms 底层原理和调优实战》
《G1圣经:G1 底层原理和调优实战》
《ZGC 圣经:ZGC 底层原理和调优实战》
《分代 ZGC 圣经:分代ZGC 底层原理和 大厂实战案例学习》




)




AI大模型学习路线,收藏这一篇就够了!)









