InstructGPT 论文略读:三步走,让大模型真正听懂人话
InstructGPT 论文略读:三步走,让大模型真正听懂人话
摘要 (Introduction)
大语言模型(LLM),如 GPT-3,无疑开启了自然语言处理的新纪元。它们强大的零样本和少样本学习能力,让我们看到了通用人工智能的一丝曙光。然而,任何与 GPT-3 有过深入“交流”的开发者或研究员都会发现一个问题:它虽然博学,但并不总是“乐于助人”或“听话”。
大型语言模型的输出可能是不真实的、有毒的,或者根本对用户没有帮助。问题的根源在于,LLM 的训练目标——在庞大的语料库上“预测下一个词”——与我们希望它拥有的能力——“有用、诚实、无害地遵循用户指令”——之间存在着天然的偏差。这种现象,我们称之为“对齐(Alignment)”问题。
为了解决这一核心矛盾,OpenAI 提出了 InstructGPT 模型。其背后的技术是“基于人类反馈的强化学习”(Reinforcement Learning from Human Feedback, RLHF),旨在将语言模型的能力与人类的意图和价值观对齐。这项工作取得了惊人的成果:在人类偏好评估中,一个仅有13亿参数的 InstructGPT 模型,其输出质量竟然超越了1750亿参数的 GPT-3。本文将深入解读这篇开创性的论文,为您详细拆解其背后的技术原理、训练流程和核心洞见。同时非常推荐李沐老师关于这篇论文的精读。
第一部分:核心方法论 - RLHF 三部曲
InstructGPT 的训练流程并非单一模型的一蹴而就,而是一个包含三个关键步骤、环环相扣的系统工程。我们可以通过论文中的核心图示来宏观理解这个过程:
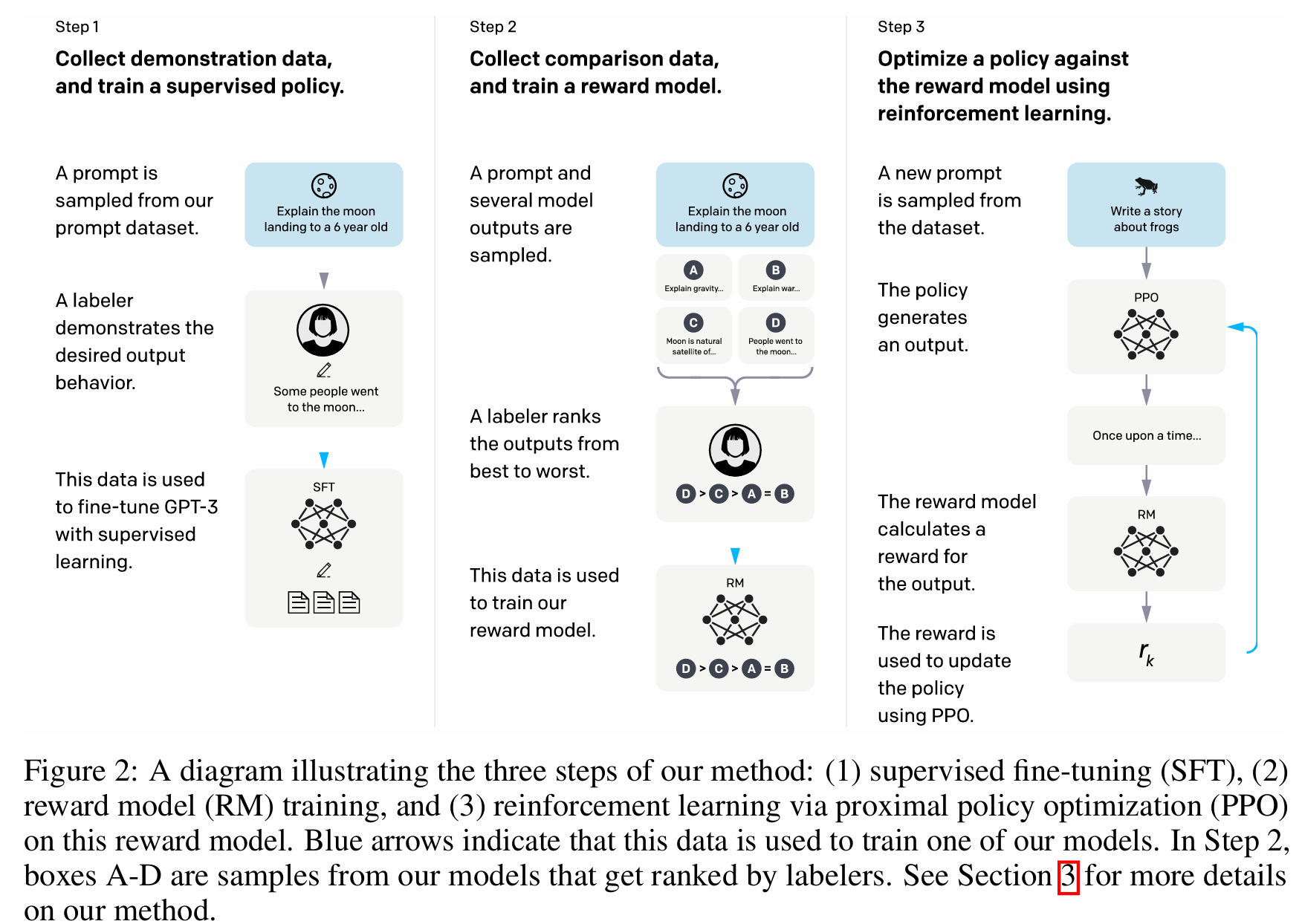
第一步:监督微调 (SFT - Supervised Fine-Tuning)
- 目标: 对预训练的 LLM 进行“启蒙”,让它初步具备理解并遵循指令格式的能力,模仿高质量的回答范例。
- 实现方式: OpenAI 雇佣了约40名标注员,构建了一个包含约1.3万个样本的高质量“指令-示范答案”数据集。这些指令来源广泛,一部分由标注员亲自撰写,另一部分则来自向早期 InstructGPT 模型提交的真实用户请求。
- 具体实现: 这一步是标准的监督学习。模型以“指令”为输入,以“示范答案”为目标输出,通过最小化交叉熵损失(Cross-Entropy Loss)来更新 GPT-3 模型的参数。简单来说,就是让模型学习“在看到这样的问题时,应该生成那样的答案”。SFT 赋予了模型遵循指令的基本形态,使其能够生成符合格式要求的、有意义的回答,为后续的优化步骤打下坚实的基础。
SFT的局限性:为什么需要第二步和第三步?
看到这里,很多人会问:既然已经有了高质量的人工示范数据,为什么不一直做 SFT,而是要引入更复杂的奖励模型和强化学习呢?原因主要有三点:
- 标注成本高昂: 撰写一个高质量、详细的示范答案(SFT数据)需要耗费标注员大量的时间和精力,成本极高。相比之下,让人类去“裁判”——从模型生成的多个答案中选出最好的一个(RM数据)——要容易得多,成本也更低。因此,收集排序数据的扩展性远超SFT数据。
- 探索空间有限: SFT 本质上是模仿学习,模型的输出被限制在人类标注员给出的范例分布内。它很难生成超越标注员知识范围或更具创造性的优质答案。
- 对齐目标模糊: 人类的偏好是一个复杂、模糊且难以用单一最优答案来定义的概念。SFT 试图拟合一个“正确答案”,而 RLHF 的目标是拟合一个“偏好模型”。后者更能捕捉到人类对于“好”答案的直觉和权衡,例如在“有趣但略有不准”和“准确但枯燥”之间的选择。
因此,为了以更低的成本、更广的探索空间来更好地对齐复杂的人类偏好,引入第二步和第三步是必然的选择。
第二步:训练奖励模型 (RM - Reward Model)
-
目标: 训练一个“人类偏好裁判”(即奖励模型),使其能够模拟人类的价值观,为任何一个模型输出进行质量打分,从而量化人类偏好。
-
实现方式:
- 数据收集: 针对同一个指令,使用第一步训练好的 SFT 模型生成4到9个不同的回答。
- 人类排序: 标注员根据回答的质量,对这些生成的回答进行从最好到最差的排序。这个过程收集了约3.3万个训练样本。
-
原理与模型更新:
这个排序数据(例如,A>B>C>D)被转换成多组成对的比较数据,如 \((A,B), (A,C), (A,D), (B,C)\) 等。然后,我们训练一个奖励模型(RM),其输入是“指令+一个回答”,输出是一个代表质量的标量分数。RM 的参数 \(\theta\) 通过最小化以下的成对排序损失函数(Pairwise Ranking Loss)来更新:
\[loss(\theta) = -\frac{1}{\binom{K}{2}} E_{(x, y_w, y_l) \sim D} [\log(\sigma(r_\theta(x, y_w) - r_\theta(x, y_l)))]\]公式直观解读:
- \(r_\theta(x, y_w)\) 和 \(r_\theta(x, y_l)\) 分别是 RM 对“更好”的回答 (\(y_w\)) 和“更差”的回答 (\(y_l\)) 的打分。
- 我们的核心目标是让 \(r_\theta(x, y_w)\) 的分数远大于 \(r_\theta(x, y_l)\),即最大化二者之差 \((r_\theta(x, y_w) - r_\theta(x, y_l))\)。
- \(\sigma\) 是 Sigmoid 函数,它将这个分数差映射到 (0, 1) 区间,可以看作是“模型认为 \(y_w\) 比 \(y_l\) 更好”的概率。
- 通过对这个概率取对数并加上负号(即标准的交叉熵损失形式),当模型预测正确(即分数差很大,概率接近1)时,损失接近0;当模型预测错误(即分数差很小或为负,概率接近0.5或更低)时,损失会变得很大。
- 通过最小化这个损失,RM 被迫学习到一种打分策略,使其打分结果与人类标注员的排序尽可能一致。最终,我们得到了一个能够代替人类进行初步打分的“代理裁判”。
第三步:基于 PPO 的强化学习 (Reinforcement Learning with PPO)
- 目标: 将 SFT 模型视为一个需要优化的“策略(Policy)”,在 RM 这个“代理裁判”的指导下,通过强化学习进行探索和优化,使其能自主生成更符合人类偏好的内容。
- 强化学习与大模型的结合:
- 智能体 (Agent): 正在被优化的 LLM(由 SFT 模型初始化)。
- 环境 (Environment): 一个随机返回用户指令的流程。
- 状态 (State): 当前环境给出的指令(Prompt)。
- 行动 (Action): LLM 根据指令生成的回答(Response)。
- 奖励 (Reward): 由第二步训练好的 RM 对 LLM 生成的“指令-回答”对的打分。
- 原理与模型更新:
此阶段是整个流程的核心。策略模型(Policy)的参数 \(\phi\) 被更新,而 RM 和 SFT 模型的参数是冻结的。最终 PPO-ptx 版本的优化目标函数如下:\[\text{objective}(\phi) = E_{(x,y)\sim D_{\pi_{\phi}^{RL}}} [r_\theta(x,y) - \beta \log(\pi_{\phi}^{RL}(y|x) / \pi^{SFT}(y|x))] + \gamma E_{x\sim D_{pretrain}}[\log(\pi_{\phi}^{RL}(x))] \]公式直观解读:
这个复杂的公式可以看作是智能体在优化时需要权衡的三个目标:- 奖励项 \(r_\theta(x,y)\):由 RM 提供,是优化的主要驱动力。最大化这一项,意味着让模型(智能体)学会生成能获得 RM 高分(即更符合人类偏好)的回答。这是智能体行动的根本目标。
- KL 惩罚项 \(-\beta \log(\pi_{\phi}^{RL}(y|x) / \pi^{SFT}(y|x))\):这一项计算了当前策略模型与初始 SFT 模型的输出分布之间的 KL 散度。它像一根“缰绳”,防止模型为了片面追求高奖励而“走火入魔”,生成一些在 RM 看来分数很高但语言上不通顺或怪异的文本。它确保了模型的探索是在一个合理、安全的范围内进行的。
- 预训练分布混合项 \(\gamma E_{x\sim D_{pretrain}}[\log(\pi_{\phi}^{RL}(x))]\):这是 PPO-ptx 模型特有的“回炉重造”项。在更新时,额外引入一部分原始预训练数据(即 GPT-3 的训练数据)的梯度。其目的是缓解“对齐税(Alignment Tax)”——即防止模型在学习遵循指令这个“专业技能”后,忘记了从海量数据中学到的广泛“通识知识”,从而导致在一些传统的 NLP 公开数据集上的性能下降。
第二部分:关键实验结果与分析
核心发现:对齐效果与模型大小的关系
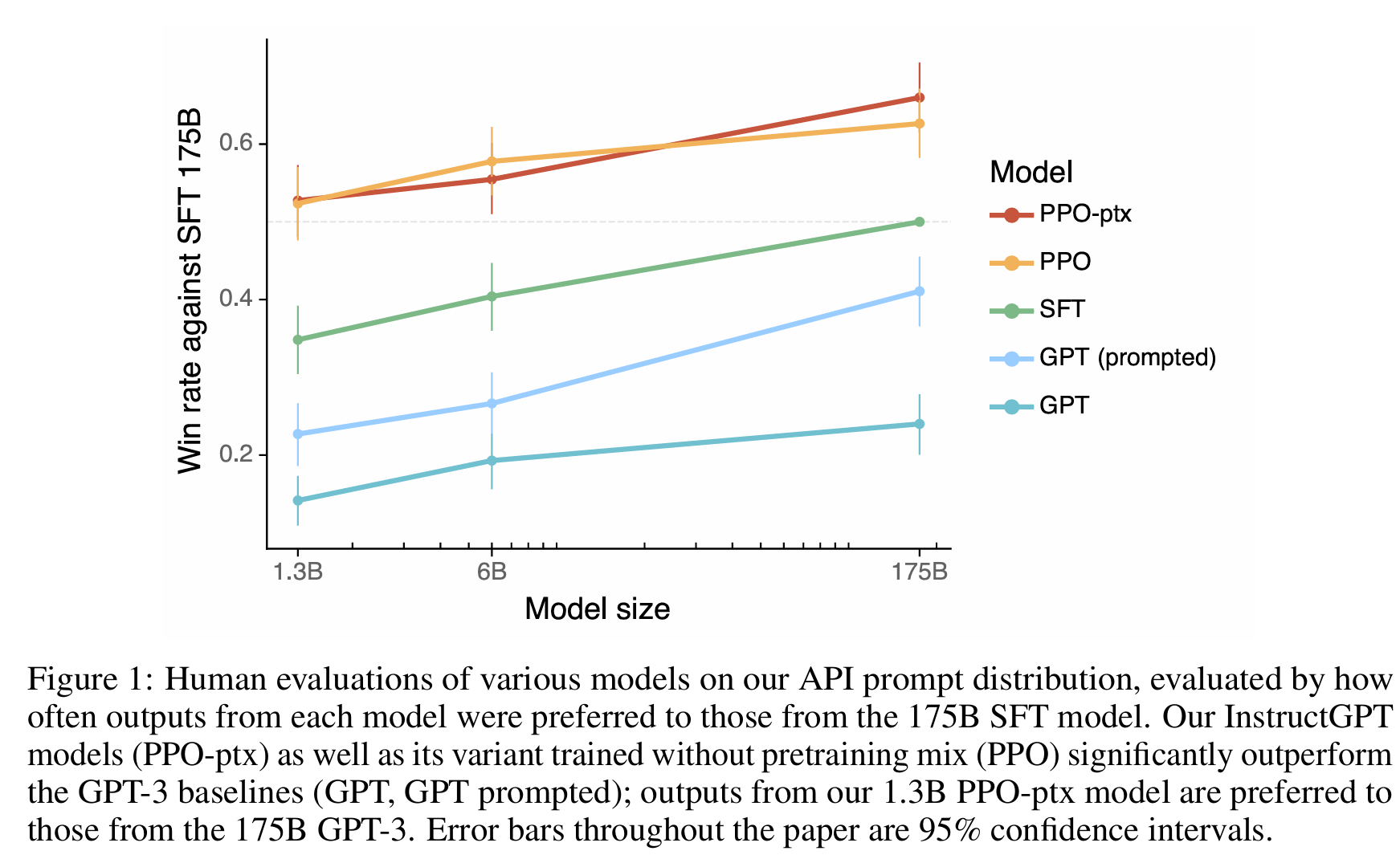
- 人类偏好评估: 实验结果清晰地表明,标注员在绝大多数情况下都更喜欢 InstructGPT 的输出。最引人注目的结论是,1.3B 的 InstructGPT 模型生成的回答,其受青睐程度超过了 175B 的原始 GPT-3 模型。这证明了通过 RLHF 进行对齐是一种比单纯增大模型规模更有效、更具性价比的提升模型“可用性”的途径。
- 真实性与安全性: 相比于 GPT-3,InstructGPT 在真实性方面表现更好,它在封闭领域任务(如摘要)中捏造事实(即“幻觉”)的频率大约是 GPT-3 的一半。同时,在被提示需要生成尊重他人的内容时,InstructGPT 产生有毒输出的比例也比 GPT-3 低约25%。
模型的泛化性与局限性
- 泛化能力: InstructGPT 展现了优秀的泛化能力。即使在训练数据中占比极低的非英语指令和代码相关指令上,它也能更好地遵循用户的意图,这表明模型不仅仅是记住了训练任务,而是在一定程度上学会了“如何遵循指令”这个元技能。
- “对齐税”问题: 论文敏锐地发现,经过 RLHF 对齐后的模型,在一些传统的 NLP 基准测试(如 DROP, SQUADv2)上出现了性能下降的现象,这就是所谓的“对齐税”。通过在 PPO 训练中混合预训练梯度的 PPO-ptx 策略,这一问题得到了极大缓解,且没有牺牲人类的偏好分数。
- 缺点与不足: 尽管 InstructGPT 进步巨大,但它远非完美。
- 它仍然会犯一些简单的错误,比如当指令中包含一个错误的假设时,模型有时会顺着这个错误的假设进行回答。
- 在 Winogender 和 CrowSPairs 等衡量偏见的数据集上,InstructGPT 相较于 GPT-3 并未表现出显著改善。
- 当用户明确指示模型生成有害内容时,它仍然会遵循指令。
第三部分:总结与思考
InstructGPT 的工作是大型语言模型发展史上的一个里程碑。它清晰地证明了:
- 技术价值: RLHF 是解决大模型与人类意图对齐问题的有效且高性价比的路径。它将模糊的人类偏好,通过“SFT -> RM -> PPO”这套流程,成功转化为了可优化的数学目标。
- 核心洞察: “对齐”本身就是一个需要精心设计和权衡的过程。模型需要在“乐于助人(Helpful)”、“诚实(Honest)”和“无害(Harmless)”这三个维度之间找到平衡。例如,过于追求“无害”可能会让模型拒绝回答很多正常问题,变得不再“乐于助人”。
- 开放性问题: 这篇论文也为我们带来了更深层次的思考——我们究竟在将模型与“谁”的价值观对齐?目前,这个标准是由少数的标注员和 OpenAI 的研究人员定义的。如何设计一个更具包容性、代表性、公平且透明的对齐流程,是整个 AI 领域未来需要面对和解决的关键挑战。
总而言之,InstructGPT 不仅为我们提供了一个更“听话”的模型,更重要的是,它为如何让越来越强大的 AI 系统与人类社会更好地协同,提供了一套切实可行的工程范式和深刻的研究启示。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/929183.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!
![luogu P1020 [NOIP 1999 提高组] 导弹拦截](http://pic.xiahunao.cn/luogu P1020 [NOIP 1999 提高组] 导弹拦截)

















