0.配置Autudl
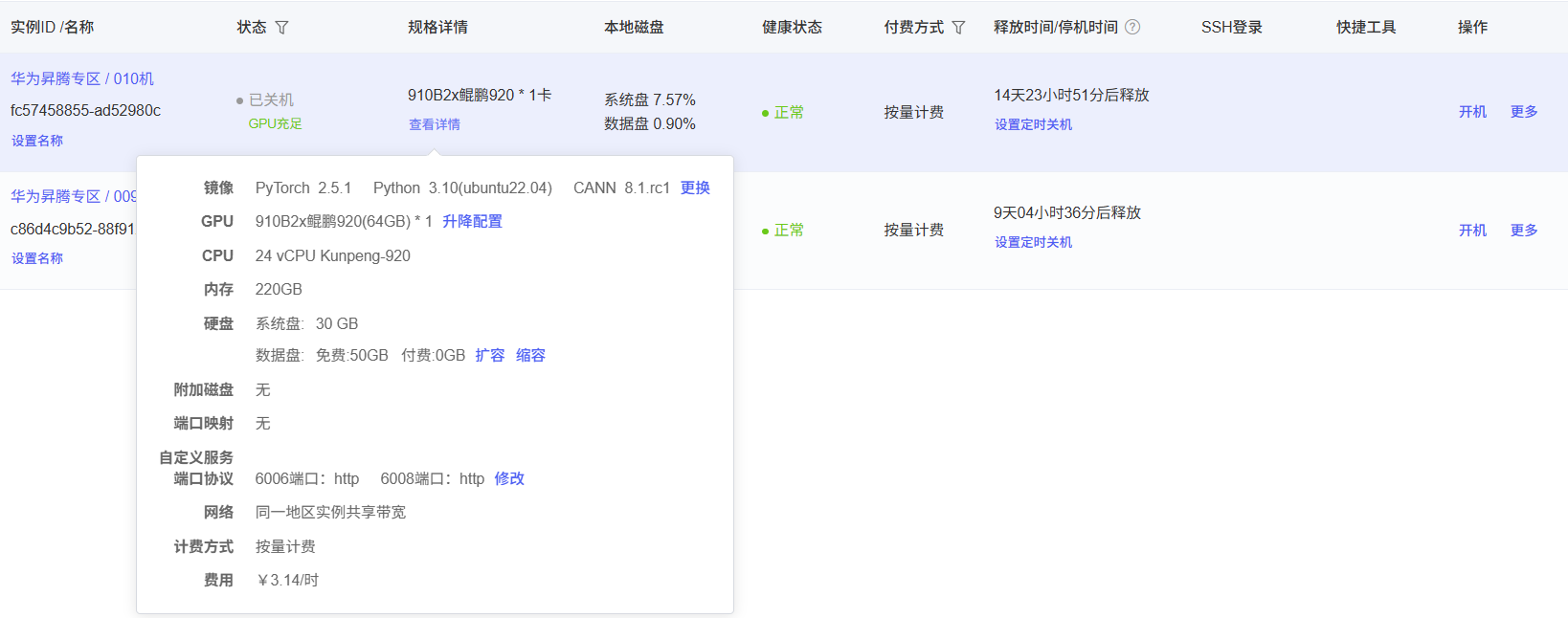
下面图片是我所租的昇腾卡和具体环境版本,太具体的就不说了,有需要的话我单独出一期Autudl租显卡的教程,主要是为了学习昇腾环境如何运行Yolo系列模型。
0.1华为昇腾芯片(Ascend)简介
1.Ascend 310— 边缘推理 SoC
- 在仅 8 W 的功耗下,支持 FP16 达 8 TOPS,INT8 达 16 TOPS
- 支持多通道高清视频处理:最高可实现 16 路 1080p H.264/H.265 解码、1 路 1080p 视频编码,以及 JPEG/PNG 编解码功能
- 内含 2 个 Da Vinci Max AI 核心、8 个 ARM Cortex‑A55 CPU 核心和 8 MB 片上缓存。
2.Ascend 910— 数据中心级训练 NPU
- 于 2019 年发布,代号 Ascend‑Max,基于 Da Vinci 架构,拥有 32 个 Da Vinci Max AI 核心,FP16 达 256 TFLOPS,INT8 达 512 TOPS
- 配备高带宽互联(NoC Mesh 1024 位,HBM2E 带宽 1.2 TB/s,350 W 功耗)
3.Ascend 910C(2025 年主打产品)
- 基于 SMIC 的 7 nm (N+2) 工艺,采用双 910B Die 封装设计,拥有约 53 亿晶体管
- 实现 FP16 约 800 TFLOPS 性能,搭载高达 128 GB 的 HBM3 存储(领先于 NVIDIA H100 的 80 GB)
- 推测性能约为 NVIDIA H100 推理性能的 60%
0.2MindSpore框架
MindSpore 是华为自主研发的全场景 AI 计算框架,覆盖云、边、端多种部署环境。向上支持自然语言处理、计算机视觉、科学计算等多类 AI 应用,向下通过 CANN 对接昇腾 AI 处理器,实现软硬件协同优化。
提供端到端的模型开发能力,包括数据处理、模型构建、训练、推理与部署,内置自动并行、算子融合、混合精度等优化机制,显著提升性能与算力利用率。其功能定位类似于 TensorFlow 或 PyTorch,在昇腾生态中承担核心 AI 框架的角色。
0.3CANN计算架构(Compute Architecture for Neural Networks)
华为面向AI场景推出的异构计算架构 CANN,作为昇腾AI处理器的软件驱动与算子加速平台,向上兼容多种主流AI框架(如 MindSpore、PyTorch、TensorFlow 等),向下对接昇腾系列AI处理器的算子库、运行时与调度层,发挥承上启下的关键作用。CANN 屏蔽了底层硬件差异,使开发者能够在不关心硬件细节的情况下无缝使用主流深度学习框架进行模型开发与部署。
同时,CANN 针对多样化的应用场景提供多层次编程接口(如算子级、图级、应用级),支持用户快速构建和优化基于昇腾平台的AI应用与业务,显著提升模型的执行效率与硬件算力利用率,其功能定位类似于 NVIDIA 的 CUDA 平台。
总结:CANN用来屏蔽底层硬件差异,使得用户能够无缝使用Pytorch等主流深度学习框架进行开发
1.配置环境
1.1创建一个yolo环境并进入
conda create -n yolo11 python=3.10
conda activate yolo111.2.安装yolo所需要的库
pip install ultralytics1.3.安装ais_bench推理工具,和aclruntime
根据自己使用的python、版本系统和架构选择具体的whl文件
https://gitee.com/ascend/tools/tree/master/ais-bench_workload/tool/ais_bench#%E4%B8%8B%E8%BD%BDwhl%E5%8C%85%E5%AE%89%E8%A3%85![]() https://gitee.com/ascend/tools/tree/master/ais-bench_workload/tool/ais_bench#%E4%B8%8B%E8%BD%BDwhl%E5%8C%85%E5%AE%89%E8%A3%85
https://gitee.com/ascend/tools/tree/master/ais-bench_workload/tool/ais_bench#%E4%B8%8B%E8%BD%BDwhl%E5%8C%85%E5%AE%89%E8%A3%85
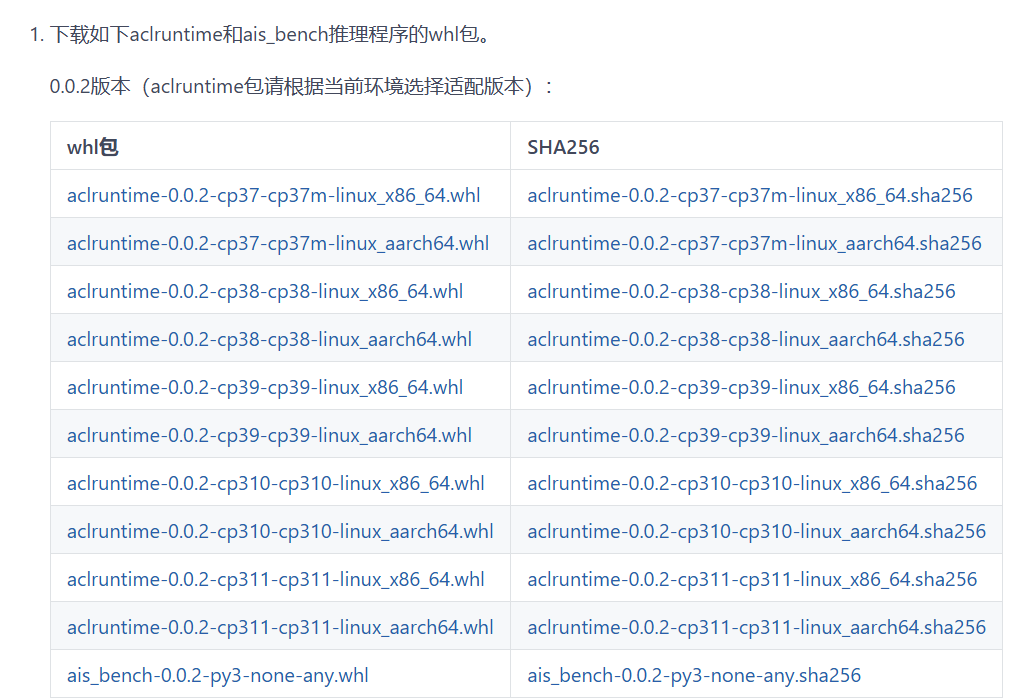
下载到本地后,安装两个whl文件
1.3.1安装ais_bench
pip install ais_bench-0.0.2-py3-none-any.whl -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple1.3.2安装aclruntime
pip install aclruntime-0.0.2-cp310-cp310-linux_aarch64.whl后面启动可能会报一些错误,让ai解决一下,很好解决
NEW_LIB=~/autodl-tmp/libstdcpp_arm64/usr/lib/aarch64-linux-gnu/libstdc++.so.6ln -sf /usr/lib/aarch64-linux-gnu/libstdc++.so.6 /root/miniconda3/lib/libstdc++.so.62.准备源码和模型
模型可以是自己的,也可以从官网上下载
2.1下载源码:
https://github.com/ultralytics/ultralytics
2.2下载模型权重:
https://docs.ultralytics.com/zh/models/yolo11/#performance-metrics
3.转换模型
1.将.pt格式转换为.ONNX格式
from ultralytics import YOLO
# Load a model
model = YOLO(r"/home/ultralytics-main/runs/train/yolo11n/weights/best.pt")
# Export onnx,一定要设置opset=11 不然会报错
model.export(format="onnx",opset=11)2.将.ONNX格式转换为.om格式
atc \--model=/root/autodl-tmp/ultralytics-main/runs/train/exp4/weights/best.onnx \--framework=5 \--output=yolo11s \--input_format=NCHW \--input_shape="images:1,3,640,640" \--soc_version=Ascend910B2参数分别是:
--model 需要转换模型的路径
--framework 框架,ONNX就用5
--output 输出.om文件的名字
--input_shape 模型的输入shape,640 640是训练时图片的大小,根据需要修改
--soc_version NPU的型号
根据下面的指令查询npu型号后,替换910B2
npu-smi info #用这个指令可以查询npu型号4.推理源码
在ultralytics路径下创建run.py
然后将下面代码复制进去,在终端输入下节命令启动。
import argparse
import time
import cv2
import numpy as np
import os
from ais_bench.infer.interface import InferSession
class YOLO:"""YOLO object detection model class for handling inference"""def __init__(self, om_model, imgsz=(640, 640), device_id=0, model_ndtype=np.single, mode="static", postprocess_type="v8", aipp=False):"""Initialization.Args:om_model (str): Path to the om model."""# 构建ais_bench推理引擎self.session = InferSession(device_id=device_id, model_path=om_model)# Numpy dtype: support both FP32(np.single) and FP16(np.half) om modelself.ndtype = model_ndtypeself.mode = modeself.postprocess_type = postprocess_typeself.aipp = aippself.model_height, self.model_width = imgsz[0], imgsz[1] # 图像resize大小def __call__(self, im0, conf_threshold=0.4, iou_threshold=0.45):"""The whole pipeline: pre-process -> inference -> post-process.Args:im0 (Numpy.ndarray): original input image.conf_threshold (float): confidence threshold for filtering predictions.iou_threshold (float): iou threshold for NMS.Returns:boxes (List): list of bounding boxes."""# 前处理Pre-processt1 = time.time()im, ratio, (pad_w, pad_h) = self.preprocess(im0)pre_time = round(time.time() - t1, 3)# 推理 inferencet2 = time.time()preds = self.session.infer([im], mode=self.mode)[0] # mode有动态"dymshape"和静态"static"等det_time = round(time.time() - t2, 3)# 后处理Post-processt3 = time.time()if self.postprocess_type == "v5":boxes = self.postprocess_v5(preds,im0=im0,ratio=ratio,pad_w=pad_w,pad_h=pad_h,conf_threshold=conf_threshold,iou_threshold=iou_threshold,)elif self.postprocess_type == "v8":boxes = self.postprocess_v8(preds,im0=im0,ratio=ratio,pad_w=pad_w,pad_h=pad_h,conf_threshold=conf_threshold,iou_threshold=iou_threshold,)elif self.postprocess_type == "v10":boxes = self.postprocess_v10(preds,im0=im0,ratio=ratio,pad_w=pad_w,pad_h=pad_h,conf_threshold=conf_threshold)else:boxes = []post_time = round(time.time() - t3, 3)return boxes, (pre_time, det_time, post_time)# 前处理,包括:resize, pad, 其中HWC to CHW,BGR to RGB,归一化,增加维度CHW -> BCHW可选择是否开启AIPP加速处理def preprocess(self, img):"""Pre-processes the input image.Args:img (Numpy.ndarray): image about to be processed.Returns:img_process (Numpy.ndarray): image preprocessed for inference.ratio (tuple): width, height ratios in letterbox.pad_w (float): width padding in letterbox.pad_h (float): height padding in letterbox."""# Resize and pad input image using letterbox() (Borrowed from Ultralytics)shape = img.shape[:2] # original image shapenew_shape = (self.model_height, self.model_width)r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])ratio = r, rnew_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))pad_w, pad_h = (new_shape[1] - new_unpad[0]) / 2, (new_shape[0] - new_unpad[1]) / 2 # wh paddingif shape[::-1] != new_unpad: # resizeimg = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)top, bottom = int(round(pad_h - 0.1)), int(round(pad_h + 0.1))left, right = int(round(pad_w - 0.1)), int(round(pad_w + 0.1))img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=(114, 114, 114)) # 填充# 是否开启aipp加速预处理,需atc中完成if self.aipp:return img, ratio, (pad_w, pad_h)# Transforms: HWC to CHW -> BGR to RGB -> div(255) -> contiguous -> add axis(optional)img = np.ascontiguousarray(np.einsum('HWC->CHW', img)[::-1], dtype=self.ndtype) / 255.0img_process = img[None] if len(img.shape) == 3 else imgreturn img_process, ratio, (pad_w, pad_h)# YOLOv5/6/7通用后处理,包括:阈值过滤与NMSdef postprocess_v5(self, preds, im0, ratio, pad_w, pad_h, conf_threshold, iou_threshold):"""Post-process the prediction.Args:preds (Numpy.ndarray): predictions come from ort.session.run().im0 (Numpy.ndarray): [h, w, c] original input image.ratio (tuple): width, height ratios in letterbox.pad_w (float): width padding in letterbox.pad_h (float): height padding in letterbox.conf_threshold (float): conf threshold.iou_threshold (float): iou threshold.Returns:boxes (List): list of bounding boxes."""# (Batch_size, Num_anchors, xywh_score_conf_cls), v5和v6的[..., 4]是置信度分数,v8v9采用类别里面最大的概率作为置信度scorex = preds # outputs: predictions (1, 8400*3, 85)# Predictions filtering by conf-thresholdx = x[x[..., 4] > conf_threshold]# Create a new matrix which merge these(box, score, cls) into one# For more details about `numpy.c_()`: https://numpy.org/doc/1.26/reference/generated/numpy.c_.htmlx = np.c_[x[..., :4], x[..., 4], np.argmax(x[..., 5:], axis=-1)]# NMS filtering# 经过NMS后的值, np.array([[x, y, w, h, conf, cls], ...]), shape=(-1, 4 + 1 + 1)x = x[cv2.dnn.NMSBoxes(x[:, :4], x[:, 4], conf_threshold, iou_threshold)]# 重新缩放边界框,为画图做准备if len(x) > 0:# Bounding boxes format change: cxcywh -> xyxyx[..., [0, 1]] -= x[..., [2, 3]] / 2x[..., [2, 3]] += x[..., [0, 1]]# Rescales bounding boxes from model shape(model_height, model_width) to the shape of original imagex[..., :4] -= [pad_w, pad_h, pad_w, pad_h]x[..., :4] /= min(ratio)# Bounding boxes boundary clampx[..., [0, 2]] = x[:, [0, 2]].clip(0, im0.shape[1])x[..., [1, 3]] = x[:, [1, 3]].clip(0, im0.shape[0])return x[..., :6] # boxeselse:return []# YOLOv8/9/11通用后处理,包括:阈值过滤与NMSdef postprocess_v8(self, preds, im0, ratio, pad_w, pad_h, conf_threshold, iou_threshold):"""Post-process the prediction.Args:preds (Numpy.ndarray): predictions come from ort.session.run().im0 (Numpy.ndarray): [h, w, c] original input image.ratio (tuple): width, height ratios in letterbox.pad_w (float): width padding in letterbox.pad_h (float): height padding in letterbox.conf_threshold (float): conf threshold.iou_threshold (float): iou threshold.Returns:boxes (List): list of bounding boxes."""x = preds # outputs: predictions (1, 84, 8400)# Transpose the first output: (Batch_size, xywh_conf_cls, Num_anchors) -> (Batch_size, Num_anchors, xywh_conf_cls)x = np.einsum('bcn->bnc', x) # (1, 8400, 84)# Predictions filtering by conf-thresholdx = x[np.amax(x[..., 4:], axis=-1) > conf_threshold]# Create a new matrix which merge these(box, score, cls) into one# For more details about `numpy.c_()`: https://numpy.org/doc/1.26/reference/generated/numpy.c_.htmlx = np.c_[x[..., :4], np.amax(x[..., 4:], axis=-1), np.argmax(x[..., 4:], axis=-1)]# NMS filtering# 经过NMS后的值, np.array([[x, y, w, h, conf, cls], ...]), shape=(-1, 4 + 1 + 1)x = x[cv2.dnn.NMSBoxes(x[:, :4], x[:, 4], conf_threshold, iou_threshold)]# 重新缩放边界框,为画图做准备if len(x) > 0:# Bounding boxes format change: cxcywh -> xyxyx[..., [0, 1]] -= x[..., [2, 3]] / 2x[..., [2, 3]] += x[..., [0, 1]]# Rescales bounding boxes from model shape(model_height, model_width) to the shape of original imagex[..., :4] -= [pad_w, pad_h, pad_w, pad_h]x[..., :4] /= min(ratio)# Bounding boxes boundary clampx[..., [0, 2]] = x[:, [0, 2]].clip(0, im0.shape[1])x[..., [1, 3]] = x[:, [1, 3]].clip(0, im0.shape[0])return x[..., :6] # boxeselse:return []# YOLOv10后处理,包括:阈值过滤-无NMSdef postprocess_v10(self, preds, im0, ratio, pad_w, pad_h, conf_threshold):x = preds # outputs: predictions (1, 300, 6) -> (xyxy_conf_cls)# Predictions filtering by conf-thresholdx = x[x[..., 4] > conf_threshold]# 重新缩放边界框,为画图做准备if len(x) > 0:# Rescales bounding boxes from model shape(model_height, model_width) to the shape of original imagex[..., :4] -= [pad_w, pad_h, pad_w, pad_h]x[..., :4] /= min(ratio)# Bounding boxes boundary clampx[..., [0, 2]] = x[:, [0, 2]].clip(0, im0.shape[1])x[..., [1, 3]] = x[:, [1, 3]].clip(0, im0.shape[0])return x # boxeselse:return []
if __name__ == '__main__':# Create an argument parser to handle command-line argumentsparser = argparse.ArgumentParser()parser.add_argument('--det_model', type=str, default=r"yolov8s.om", help='Path to OM model')parser.add_argument('--source', type=str, default=r'images', help='Path to input image')parser.add_argument('--out_path', type=str, default=r'results', help='结果保存文件夹')parser.add_argument('--imgsz_det', type=tuple, default=(640, 640), help='Image input size')parser.add_argument('--classes', nargs='+', default=['obj'])parser.add_argument('--conf', type=float, default=0.25, help='Confidence threshold')parser.add_argument('--iou', type=float, default=0.6, help='NMS IoU threshold')parser.add_argument('--device_id', type=int, default=0, help='device id')parser.add_argument('--mode', default='static', help='om是动态dymshape或静态static')parser.add_argument('--model_ndtype', default=np.single, help='om是fp32或fp16')parser.add_argument('--postprocess_type', type=str, default='v8', help='后处理方式, 对应v5/v8/v10三种后处理')parser.add_argument('--aipp', default=False, action='store_true', help='是否开启aipp加速YOLO预处理, 需atc中完成om集成')args = parser.parse_args()# 创建结果保存文件夹if not os.path.exists(args.out_path):os.mkdir(args.out_path)print('开始运行:')# Build modeldet_model = YOLO(args.det_model, args.imgsz_det, args.device_id, args.model_ndtype, args.mode, args.postprocess_type, args.aipp)color_palette = np.random.uniform(0, 255, size=(len(args.classes), 3)) # 为每个类别生成调色板for i, img_name in enumerate(os.listdir(args.source)):try:t1 = time.time()# Read image by OpenCVimg = cv2.imread(os.path.join(args.source, img_name))# 检测Inferenceboxes, (pre_time, det_time, post_time) = det_model(img, conf_threshold=args.conf, iou_threshold=args.iou)print('{}/{} ==>总耗时间: {:.3f}s, 其中, 预处理: {:.3f}s, 推理: {:.3f}s, 后处理: {:.3f}s, 识别{}个目标'.format(i+1, len(os.listdir(args.source)), time.time() - t1, pre_time, det_time, post_time, len(boxes)))# Draw rectanglesfor (*box, conf, cls_) in boxes:cv2.rectangle(img, (int(box[0]), int(box[1])), (int(box[2]), int(box[3])),color_palette[int(cls_)], 2, cv2.LINE_AA)cv2.putText(img, f'{args.classes[int(cls_)]}: {conf:.3f}', (int(box[0]), int(box[1] - 9)),cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2, cv2.LINE_AA)cv2.imwrite(os.path.join(args.out_path, img_name), img)except Exception as e:print(e)5.启动命令
python ~/autodl-tmp/ultralytics-main/run.py \--det_model /root/autodl-tmp/ultralytics-main/yolo11n-jiejing.om \--source /root/autodl-tmp/ultralytics-main/test \--classes jiejing xiaojiejing \--postprocess_type v8--classes 是模型检测标签名
--source 推理文件所在文件夹
--det_model om模型参数路径
--postprocess_type yolov8 v9 v11都用v8,使用的yolov5的话改为yolov5


)












)



