Redis 高可用篇 - 实践
2025-09-28 14:53 tlnshuju 阅读(0) 评论(0) 收藏 举报主从复制是怎么实现的?
- 如果服务器发生了宕机,由于数据恢复是需要点时间,那么这个期间是无法服务新的请求的;
- 如果这台服务器的硬盘出现了故障,可能数据就都丢失了。
要避免这种单点故障,最好的办法是将数据备份到其他服务器上,让这些服务器也可以对外提供服务,这样即使有一台服务器出现了故障,其他服务器依然可以继续提供服务。
主机更新后根据配置和策略,自动同步到备机的mater/slaver机制,Master以写为主,Slave以读为主。
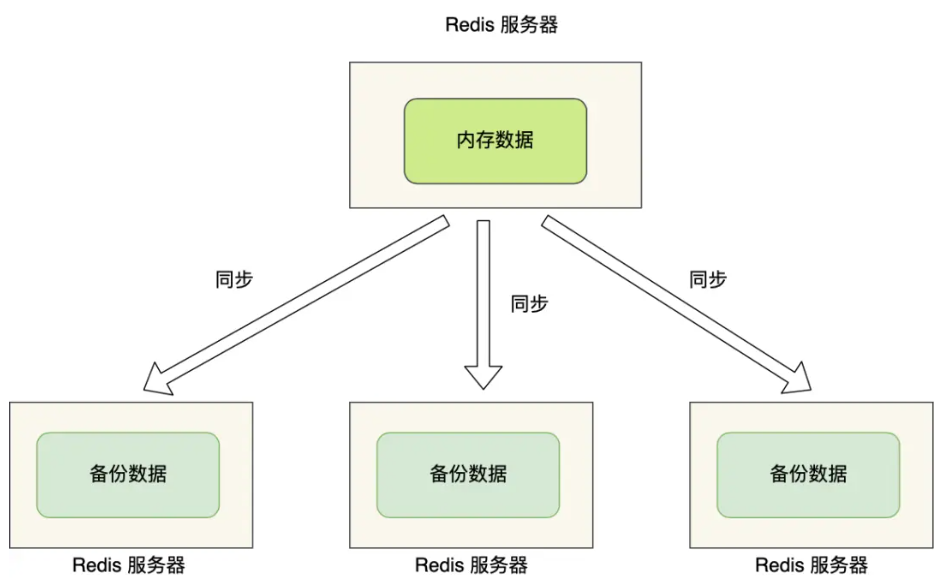
Redis 主从复制的核心价值是解决 “多服务器数据一致性” 与 “读写负载分配” 问题,而第一次同步(全量复制) 是主从数据达成初始一致的关键环节
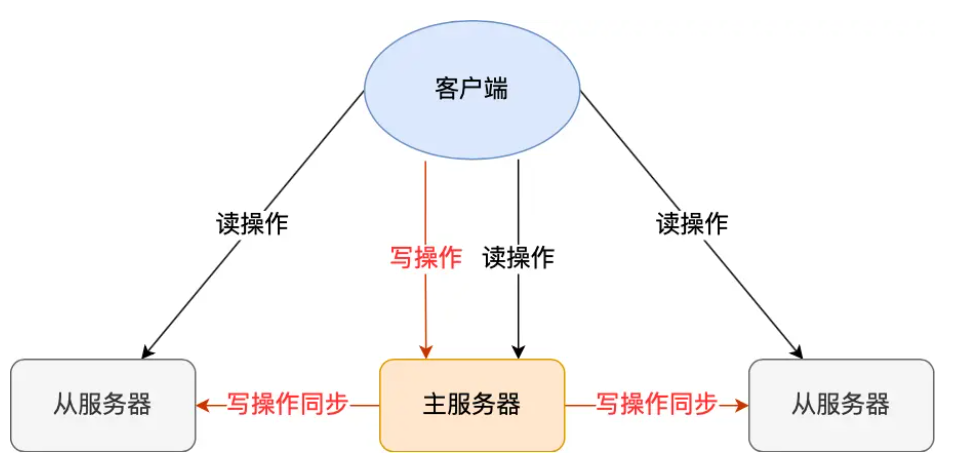
也就是说,所有的数据修改只在主服务器上进行,然后将最新的数据同步给从服务器,这样就使得主从服务器的数据是一致的。
同步这两个字说的简单,但是这个同步过程并没有想象中那么简单,要考虑的事情不是一两个。
我们先来看看,主从服务器间的第一次同步是如何工作的?
第一次同步
多台服务器之间要通过什么方式来确定谁是主服务器,或者谁是从服务器呢?
我们可以使用 replicaof(Redis 5.0 之前使用 slaveof)命令形成主服务器和从服务器的关系。
比如,现在有服务器 A 和 服务器 B,我们在服务器 B 上执行下面这条命令:
# 服务器 B 执行这条命令
replicaof <服务器 A 的 IP 地址> <服务器 A 的 Redis 端口号>接着,服务器 B 就会变成服务器 A 的「从服务器」,然后与主服务器进行第一次同步。
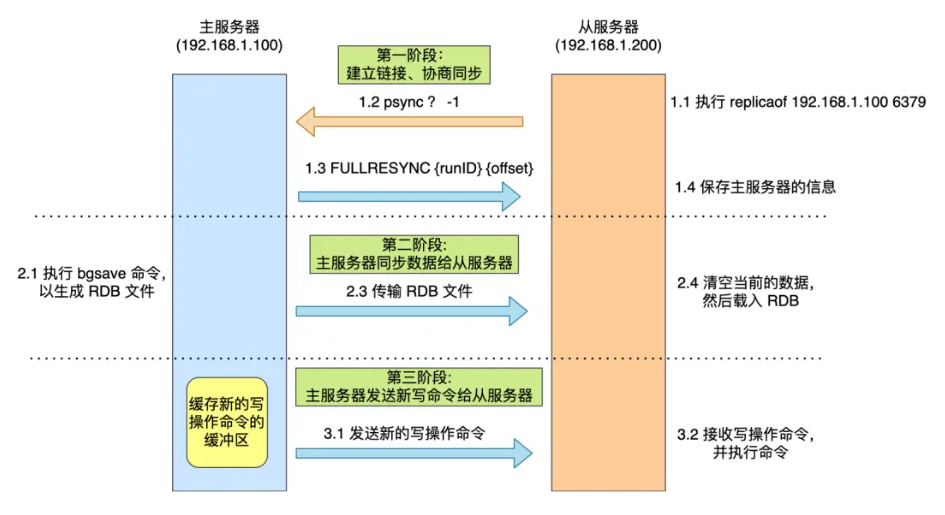
主从服务器间的第一次同步的过程可分为三个阶段:
- 第一阶段是建立连接、协商同步;
- 第二阶段是主服务器同步数据给从服务器;
- 第三阶段是主服务器发送新写操作命令给从服务器。
:::info
第一阶段:建立链接、协商同步
:::
执行了 replicaof 命令后,从服务器就会给主服务器发送 psync 命令,表示要进行数据同步。
psync 命令包含两个参数,分别是主服务器的 runID 和复制进度 offset。
- runID,每个 Redis 服务器在启动时都会自动生产一个随机的 ID 来唯一标识自己。当从服务器和主服务器第一次同步时,因为不知道主服务器的 run ID,所以将其设置为 “?”。
- offset,表示复制的进度,第一次同步时,其值为 -1。
主服务器收到 psync 命令后,会用 FULLRESYNC 作为响应命令返回给对方。
并且这个响应命令会带上两个参数:主服务器的 runID 和主服务器目前的复制进度 offset。从服务器收到响应后,会记录这两个值。
FULLRESYNC 响应命令的意图是采用全量复制的方式,也就是主服务器会把所有的数据都同步给从服务器。
所以,第一阶段的工作时为了全量复制做准备。
:::info
第二阶段:主服务器同步数据给从服务器
:::
- 主服务器异步生成 RDB:主服务器执行
<font style="color:#000000;">bgsave</font>命令,通过子进程异步生成 RDB 文件(不阻塞主线程,可正常处理命令),并将 RDB 发送给从服务器。 - 从服务器加载 RDB 前清空数据:从服务器接收 RDB 后,先删除本地旧数据,再载入 RDB 文件以获取主服务器的基础全量数据。
- 缓冲区解决数据不一致问题:因
<font style="color:#000000;">bgsave</font>生成 RDB、RDB 传输、从服务器加载 RDB 这三个阶段存在时间差,主服务器会将期间收到的所有写操作命令,写入<font style="color:#000000;">replication buffer</font>(复制缓冲区),后续同步给从服务器,确保主从数据最终一致。以下时间差场景:- 主服务器生成 RDB 文件期间;
- 主服务器发送 RDB 文件给从服务器期间;
- 「从服务器」加载 RDB 文件期间;
:::info
第三阶段:主服务器发送新写操作命令给从服务器
:::
- 从服务器处理 RDB:主服务器发送完 RDB 文件后,从服务器先丢弃本地所有旧数据,再将 RDB 数据载入内存,确保基础数据与主服务器一致。
- 从服务器确认加载完成:RDB 载入成功后,从服务器向主服务器发送 “加载完成” 的确认消息。
- 主服务器同步缓冲区命令:主服务器收到确认后,将
<font style="color:#000000;">replication buffer</font>中记录的(RDB 生成、传输及加载期间的)所有写命令,发送给从服务器。 - 从服务器执行命令,完成同步:从服务器按顺序执行这些写命令,数据与主服务器完全对齐,主从第一次同步(全量复制)正式完成。
命令传播
主从服务器在完成第一次同步后,双方之间就会维护一个 TCP 连接。
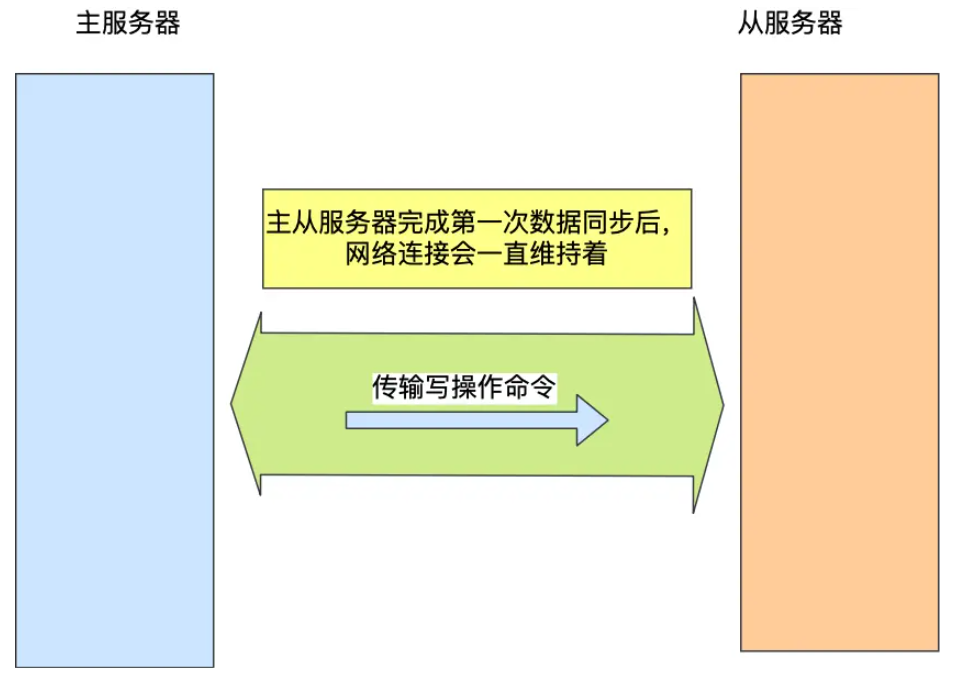
- 长连接维持实时同步:第一次全量同步完成后,主从服务器保持长连接状态,避免频繁 TCP 连接 / 断开的性能损耗。
- 命令传播保障增量一致:主服务器后续执行的所有写操作命令,会通过长连接实时传播给从服务器。
- 从服务器执行命令:从服务器接收命令后立即执行,确保自身数据库状态与主服务器完全一致,实现第一次同步后的持续数据一致性。
这一机制被称为 “基于长连接的命令传播”,是主从日常同步的核心方式。
分摊主服务器的压力
当主服务器从节点过多时,全量同步(生成 / 传输 RDB)会引发主线程阻塞(fork 子进程)和带宽占用问题。Redis 通过 “级联复制” 机制解决,核心逻辑类似 “老板→经理→员工” 的管理架构:
- 架构设计:允许从服务器拥有自己的从服务器(称为 “二级从”)。此时,原从服务器(“一级从”)扮演 “中间主” 角色 —— 既作为从节点接收主服务器的同步数据,又作为主节点向其下属的二级从服务器同步数据。
- 核心价值:
- 减轻主服务器压力:主服务器仅需与少量 “一级从”(中间主)进行全量同步,无需应对所有从节点,避免频繁 fork 子进程阻塞主线程、减少主服务器网络带宽消耗。
- 分散同步负载:“中间主” 负责向其下属二级从服务器生成 / 传输 RDB、传播写命令,将同步压力分散到各级节点。
- 数据一致性保障:二级从服务器的同步流程与普通主从一致 —— 先与 “中间主” 全量同步(RDB + 缓冲区命令),后续通过长连接接收 “中间主” 传播的写命令(“中间主” 会先同步主服务器的命令,再转发给二级从),最终确保全链路数据一致。
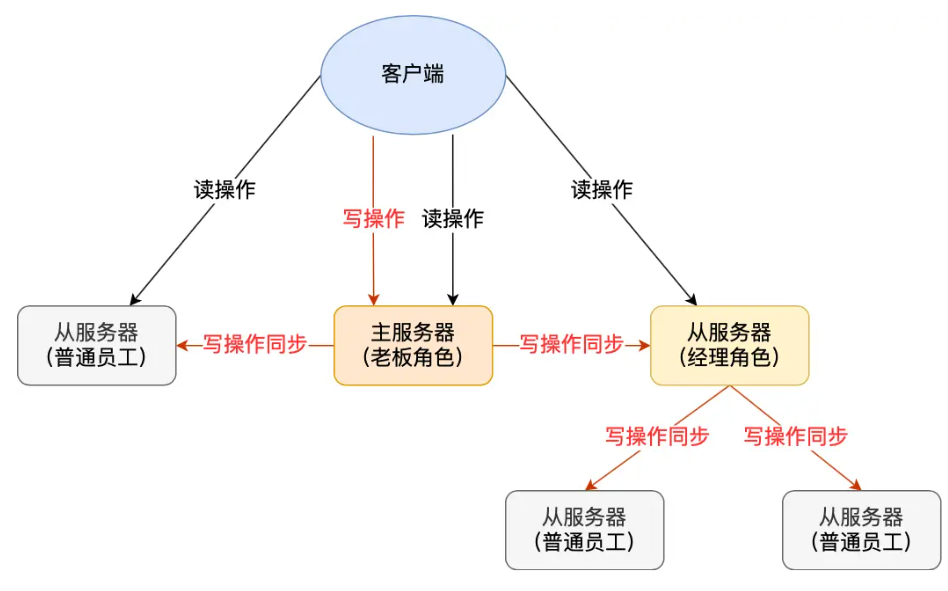
通过这种方式,主服务器生成 RDB 和传输 RDB 的压力可以分摊到充当经理角色的从服务器。
我们在「从服务器」上执行下面这条命令,使其作为目标服务器的从服务器:
replicaof <目标服务器的IP> 6379此时如果目标服务器本身也是「从服务器」,那么该目标服务器就会成为「经理」的角色,不仅可以接受主服务器同步的数据,也会把数据同步给自己旗下的从服务器,从而减轻主服务器的负担。
增量复制
主从第一次同步完成后,依赖长连接进行命令传播(主服务器实时同步写命令给从服务器),但网络异常会直接打破这一机制,导致核心问题:
- 网络异常的直接影响:若主从间网络延迟或断开,主服务器的写命令无法通过长连接传给从服务器,两者数据同步链路中断。
- 数据不一致后果:从服务器无法获取主服务器的最新写操作,数据停留在网络断开前的状态;此时客户端若读取该从服务器,会拿到旧数据,违背数据一致性要求。
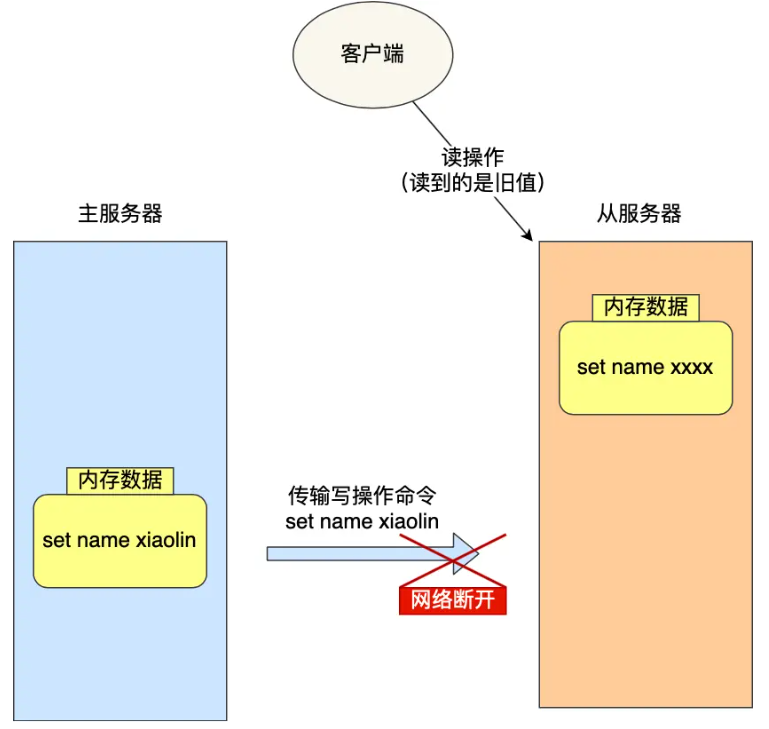
那网络断开恢复后,主从同步无需重复全量复制(2.8 版本前的低效方式),而是通过增量复制高效补全数据,具体逻辑如下:
- 核心优化:用增量复制替代全量复制
网络恢复后,从服务器不会重新请求全量 RDB,而是仅同步 “网络断开期间主服务器接收的写操作命令”,大幅降低 CPU、内存和带宽开销。 - 增量复制的前提
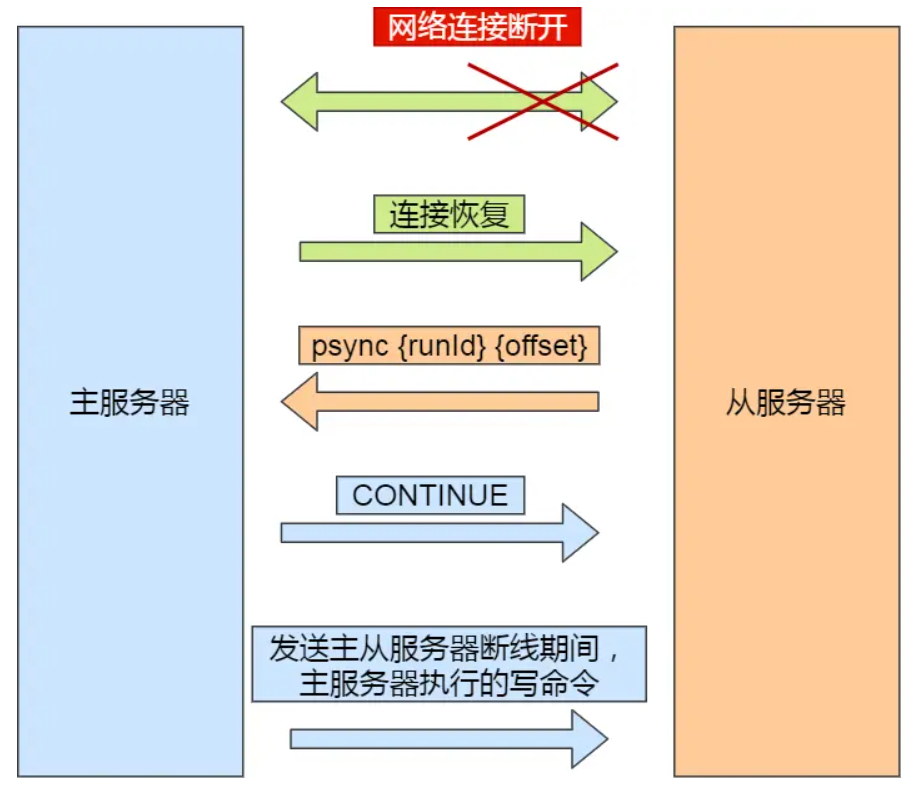
主服务器在运行中会维护一个复制积压缓冲区(环形缓冲区),持续记录自身执行的写命令。网络断开期间的写命令,会被暂存于此缓冲区中。 - 恢复同步的关键步骤
- 从服务器发
<font style="color:#000000;">PSYNC</font>,带主服务器<font style="color:#000000;">runID</font>和断开前的<font style="color:#000000;">offset</font>; - 主服务器校验通过后,仅将
<font style="color:#000000;">offset</font>后(断网期间)的写命令同步给从服务器; - 从服务器执行这些命令,快速恢复数据一致,大幅降低开销。
- 从服务器发
网络恢复后的增量复制过程如下图:
那么关键的问题来了,主服务器怎么知道要将哪些增量数据发送给从服务器呢?
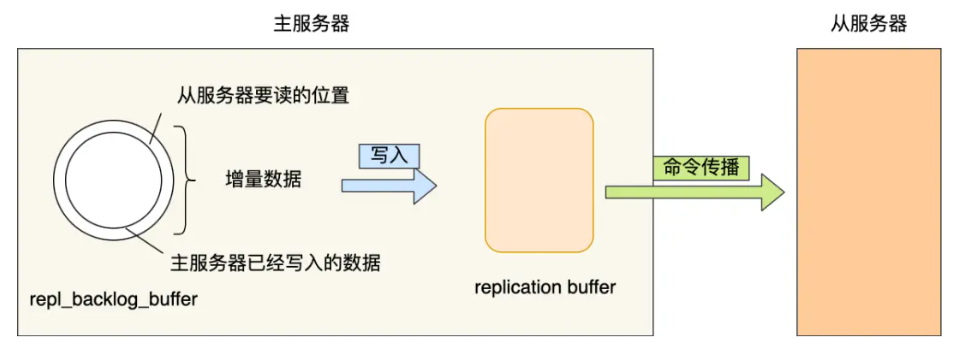
主服务器通过 “<font style="color:#000000;">repl_backlog_buffer</font>环形缓冲区 +<font style="color:#000000;">replication offset</font>偏移量” 精准定位增量数据,具体机制如下:
关键组件作用:
**<font style="color:#000000;">repl_backlog_buffer</font>**:主服务器传播命令时,会同步将写命令写入环形缓冲区,保存最近的写命令**<font style="color:#000000;">replication offset</font>**:- 主服务器用
<font style="color:#000000;">master_repl_offset</font>记 “写进度” - 从服务器用
<font style="color:#000000;">slave_repl_offset</font>记 “读进度”
- 主服务器用
网络恢复后的数据定位:
- 从服务器重连后,通过
<font style="color:#000000;">PSYNC</font>发送自身<font style="color:#000000;">slave_repl_offset</font>; - 主服务器对比
<font style="color:#000000;">master_repl_offset</font>与<font style="color:#000000;">slave_repl_offset</font>:- 若差值内的数据仍在
<font style="color:#000000;">repl_backlog_buffer</font>中,用增量同步(仅传差值部分命令); - 若数据已被缓冲区覆盖,触发全量同步。
- 若差值内的数据仍在
增量数据的传递
- 主服务器找到增量数据后,将其写入
<font style="color:#000000;">replication buffer</font>,再通过连接传给从服务器,从服务器执行后恢复数据一致。
repl_backlog_buffer(环形缓冲区)默认 1M,写满会覆盖旧数据,易导致网络恢复时无法增量同步,需合理调整大小:
- 核心问题:默认 1M 容量小,若主服务器写速快、从服务器断线久,缓冲区数据易被覆盖,网络恢复后只能全量同步(性能损耗大)。
- 核心参数:
- second:从服务器断线后重新连接上主服
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/920748.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

自身网站的建设和推广力度不足做网站在浏览器预览怎么出现了状况

多站点wordpress简数采集器网站建设策划书的主要内容

网站搜索排名高怎么做湖州服装网站建设

大连网站制作.net外贸app网站开发

静态网站如何建设市场推广专员

东南亚日本股票数据API对接文档

企业网站建设规划微企申请网站

基于数据源连接,动态构造JPA上下文EntityManager

做社情网站犯法怎么办网络门店管理系统登录入口

如何做视频播放网站我有域名怎么做网站

Ansible + Docker 部署 MinIO 集群

万用表与电流探头测量电流信号的技术对比分析


WPF Canvas mark triangle, circle, and retangle, then save the whole canvas as jpg file

网站开发毕业设计周志wordpress sae 主题

北京牛鼻子网站建设公司m3u8插件 wordpress


自动遍历测试利器:开源工具AppCrawler 配置全解析

得帆云ETL全新版本升级驱动数据高效流转
