近期,Google Research发布了TimesFM-2.5,这是一个拥有2亿参数的纯解码器时间序列基础模型,具有16K上下文长度并原生支持概率预测。在GIFT-Eval评测中,TimesFM-2.5现在在零样本基础模型中的准确性指标(MASE、CRPS)方面位居榜首。
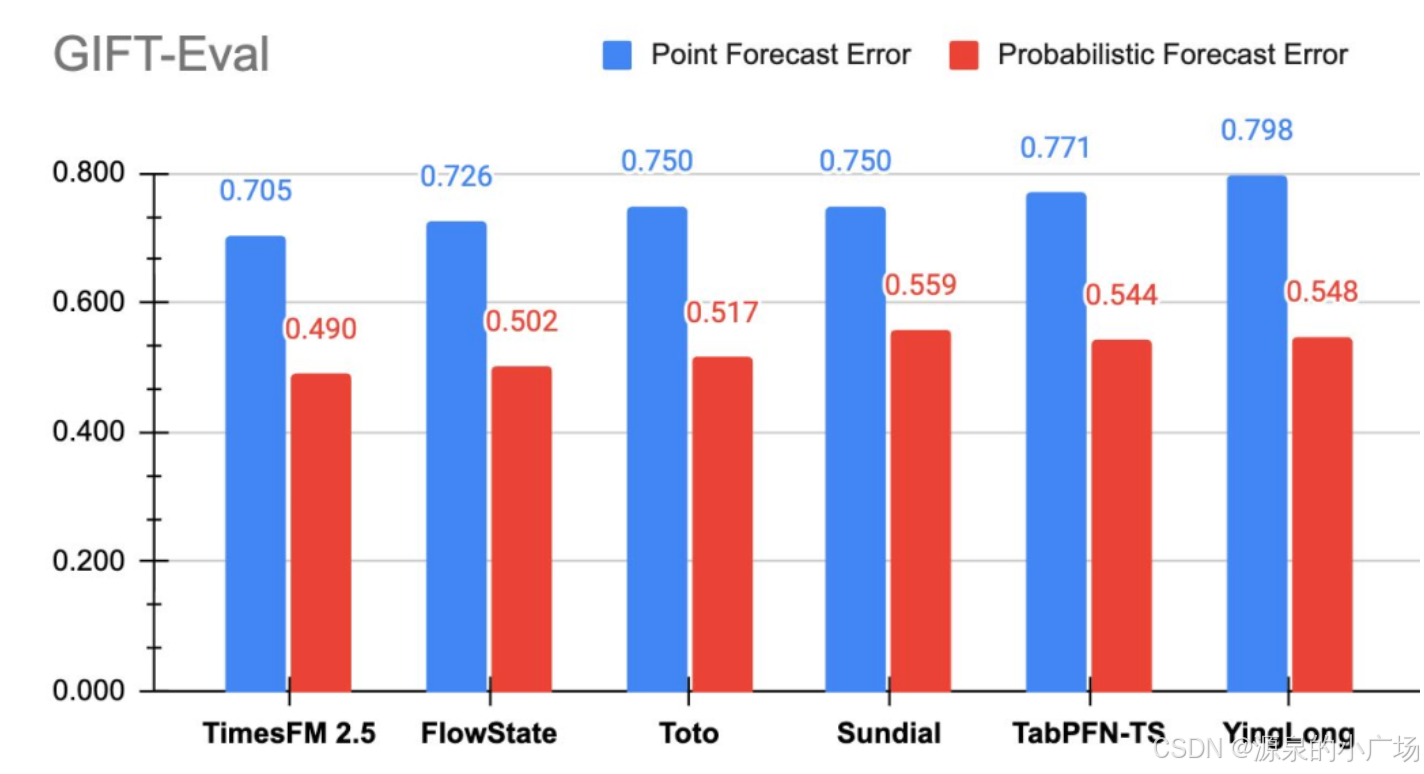
TimesFM-2.5是最新的一个版本,之前其实已经推出了1.0版本的TimesFM ,该算法是一种序列预测模型,预训练于包含1000亿个真实世界时间点的大规模时间序列语料,在来自不同领域与时间粒度的多项公开基准上展现出出色的零样本性能。
时间序列预测广泛应用于零售、金融、制造、医疗与自然科学等领域。以零售为例,提高需求预测的准确性能够显著降低库存成本并提升营收。深度学习(DL)模型因在多种场景中表现优异(例如在 M5 比赛中表现突出),已成为处理丰富的多变量时间序列数据的主流方法。
与此同时,用于自然语言处理(NLP)的超大基础语言模型发展迅猛,广泛应用于翻译、检索增强生成、代码补全等任务。这些模型在来自多源的大规模文本(如 Common Crawl 和开源代码)上训练,能够高效捕捉语言模式,因此具备强大的零样本能力。例如,结合检索技术后,它们可以回答并总结关于时事的问题。
尽管基于 DL 的预测模型整体上优于传统方法,且在训练与推理成本上已有改进,但仍面临挑战:大多数 DL 架构在用户将模型用于一条新时间序列之前,都需要冗长而复杂的训练与验证流程。相比之下,面向时间序列预测的基础模型可以在无需额外训练的情况下,对未见过的数据给出可用的即刻预测,让用户将精力集中在零售需求计划等下游任务的精细化优化上。
为此,google在被 ICML 2024 接收的论文“A decoder-only foundation model for time-series forecasting”中提出了 TimesFM——一个在包含1000亿真实世界时间点的大规模语料上预训练的统一预测模型。与最新的大型语言模型(LLM)相比,TimesFM 规模更小(2亿参数),但即便在这一量级上,它在来自不同领域与时间粒度的多种未见数据集上的零样本表现,已接近那些在相应数据集上专门监督训练的最先进方法。模型可通过我们的 Hugging Face 与 GitHub 仓库获取。
解码器式(decoder-only)的时间序列基础模型 LLM 通常采用仅解码器(decoder-only)的训练范式,包含三步:首先,将文本切分为子词(tokens);然后,将这些 token 输入堆叠的因果 Transformer 层,生成与每个输入 token 对应的输出(只能关注过去,不能看到未来的 token);最后,第 i 个 token 的输出汇总此前所有信息并预测第 i+1 个 token。在推理阶段,LLM 逐 token 生成输出。例如,对于提示“What is the capital of France?”,它可能先生成“The”,再在“What is the capital of France? The”的条件下生成“capital”,依此类推,直到得到完整答案:“The capital of France is Paris”。
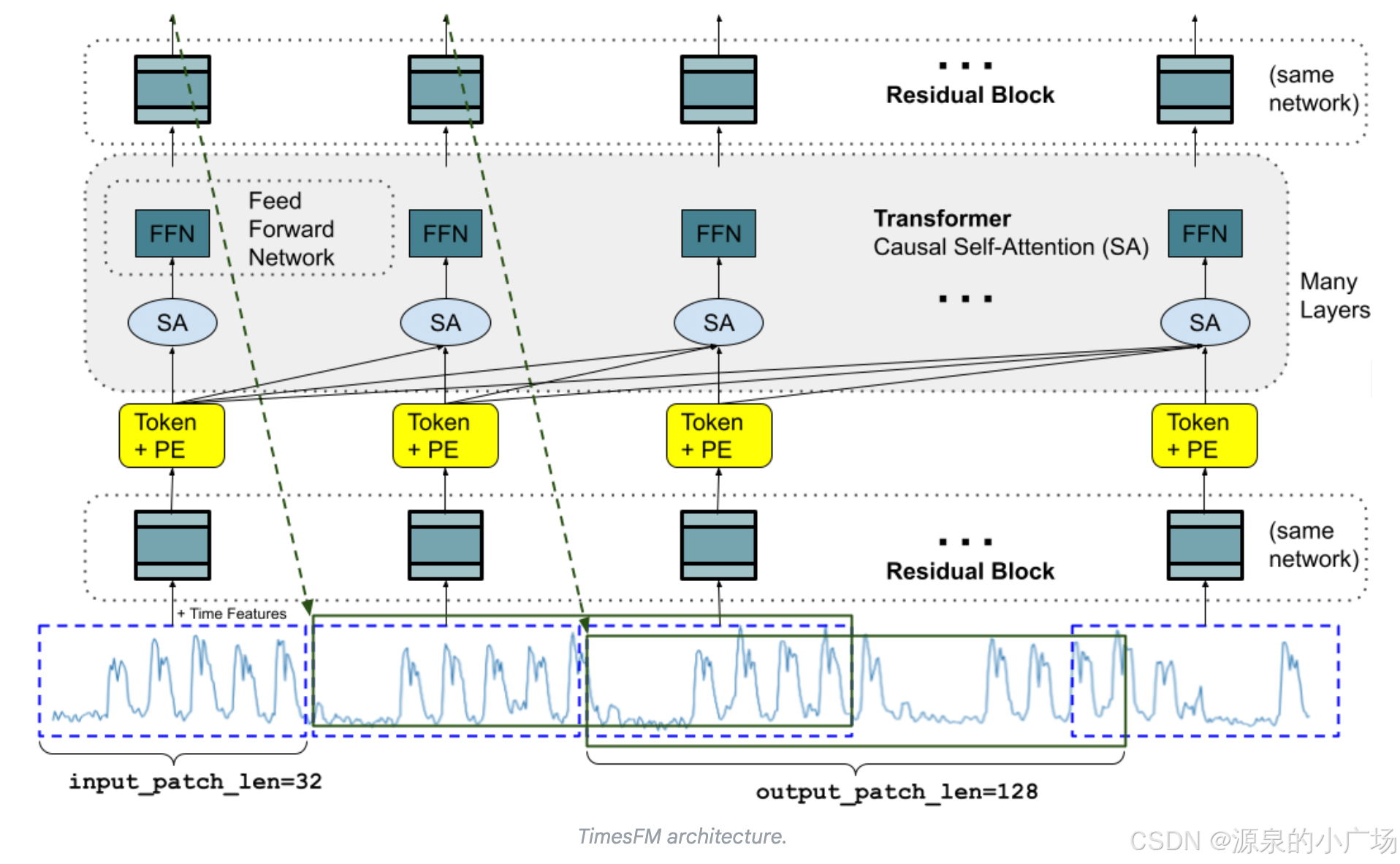
面向时间序列预测的基础模型需要适配可变的上下文长度(观测序列)与预测视野(要求模型预测的长度),同时具备足够容量来编码大规模预训练数据中的模式。与 LLM 类似,TimesFM 采用堆叠的 Transformer 层(自注意力与前馈层)作为核心构件。在时间序列预测场景中,作者将一个补丁(patch,即一段连续时间点的组)视作一个 token,这一做法受到近期长视野预测工作的启发。模型任务是在堆叠 Transformer 层末端,基于第 i 个输出预测第 i+1 个时间点补丁。
但与语言模型也有关键区别。首先,需要带残差连接的多层感知机(MLP)模块,将时间序列补丁转换为可与位置编码(PE)一起输入 Transformer 的 token。为此,采用了与此前长视野预测工作相似的残差模块。其次,在输出端,堆叠 Transformer 产生的一个输出 token 可以预测长度长于输入补丁的后续时间点,即输出补丁长度可以大于输入补丁长度。
举例来说,考虑一条长度为 512 的时间序列,使用输入补丁长度为 32、输出补丁长度为 128 来训练 TimesFM。训练时,模型会同时学习:用前 32 个时间点预测接下来的 128 个点;用前 64 个点预测第 65 到 192 个点;用前 96 个点预测第 97 到 224 个点;以此类推。推理时,若给定一条长度为 256 的新时间序列,并要求向前预测 256 个时间点,模型会先生成第 257 到 384 个时间点,再在最初的 256 点与已生成的结果基础上,生成第 385 到 512 个时间点。相反,如果输出补丁长度等于输入补丁长度(均为 32),完成同一任务就需要 8 次生成步骤而非 2 次,这会显著增加误差累积的风险。因此,在实践中,观察到更长的输出补丁长度能在长视野预测中带来更好的表现。
安装使用:
git clone https://github.com/google-research/timesfm.git
cd timesfm
pip install -e .代码示例:
import numpy as np
import timesfm
model = timesfm.TimesFM_2p5_200M_torch()
model.load_checkpoint()
model.compile(timesfm.ForecastConfig(max_context=1024,max_horizon=256,normalize_inputs=True,use_continuous_quantile_head=True,force_flip_invariance=True,infer_is_positive=True,fix_quantile_crossing=True,)
)
point_forecast, quantile_forecast = model.forecast(horizon=12,inputs=[np.linspace(0, 1, 100),np.sin(np.linspace(0, 20, 67)),], # Two dummy inputs
)
point_forecast.shape # (2, 12)
quantile_forecast.shape # (2, 12, 10): mean, then 10th to 90th quantiles.参考材料:
【1】A DECODER-ONLY FOUNDATION MODEL FOR TIME-SERIES FORECASTING
【2】A decoder-only foundation model for time-series forecasting
【3】https://huggingface.co/google/timesfm-2.5-200m-pytorch

:整合与优化)

















