垃圾收集器ParNew&CMS与底层三色标记算法详解
一、垃圾收集算法:分代理论下的三大核心实现
分代收集理论是基础,核心逻辑是按对象存活周期将堆分为新生代(存活短)和老年代(存活长),针对不同年代选择效率最优的算法。
| 算法名称 | 核心逻辑 | 适用年代 | 优点 | 缺点 |
|---|---|---|---|---|
| 复制算法 | 内存分为大小相等两块,用满一块后复制存活对象到另一块,清理原块 | 新生代 | 无内存碎片,效率高 | 内存利用率低(仅用 50%) |
| 标记 - 清除算法 | 1. 标记(存活 / 待回收对象);2. 清除待回收对象 | 老年代 | 无需移动对象,简单 | 1. 效率低(标记对象多);2. 产生大量碎片 |
| 标记 - 整理算法 | 1. 标记存活对象;2. 存活对象移至内存一端;3. 清理边界外内存 | 老年代 | 无内存碎片 | 需移动对象,效率低于标记 - 清除 |
二、垃圾收集器:不同场景的实现选择
收集器是算法的落地,需根据 “吞吐量优先” 或 “低停顿优先” 选择,无 “最优” 仅 “适配”。
1. 新生代收集器对比
| 收集器名称 | 线程数 | 核心特性 | 算法 | 关键参数 | 适用场景 |
|---|---|---|---|---|---|
| Serial | 单线程 | STW(暂停所有用户线程),无线程交互开销,单线程效率高 | 复制算法 | -XX:+UseSerialGC | 单 CPU 环境、客户端应用 |
| Parallel Scavenge | 多线程 | 关注吞吐量(用户代码时间 / 总时间),可自动优化内存 | 复制算法 | -XX:+UseParallelGC-XX:ParallelGCThreads=N(默认 = CPU 核数) | 服务器环境、吞吐量优先(如后台计算) |
| ParNew | 多线程 | 与 CMS 收集器兼容(唯一能配合 CMS 的新生代收集器) | 复制算法 | -XX:+UseParNewGC | 服务器环境、低停顿优先(如 Web 应用) |
2. 老年代收集器对比
| 收集器名称 | 线程数 | 核心特性 | 算法 | 关键参数 | 适用场景 |
|---|---|---|---|---|---|
| Serial Old | 单线程 | STW,Serial/Parallel Scavenge 的后备收集器 | 标记 - 整理算法 | -XX:+UseSerialOldGC | 单 CPU 环境、CMS 失败后的后备 |
| Parallel Old | 多线程 | 关注吞吐量,Parallel Scavenge 的老年代版本 | 标记 - 整理算法 | -XX:+UseParallelOldGC | 服务器环境、吞吐量优先(如大数据计算) |
| CMS | 并发(多线程) | 目标最短停顿时间,首次实现 GC 线程与用户线程并发运行 | 标记 - 清除算法 | -XX:+UseConcMarkSweepGC | 服务器环境、低停顿优先(如电商订单系统) |
3. CMS 收集器核心细节
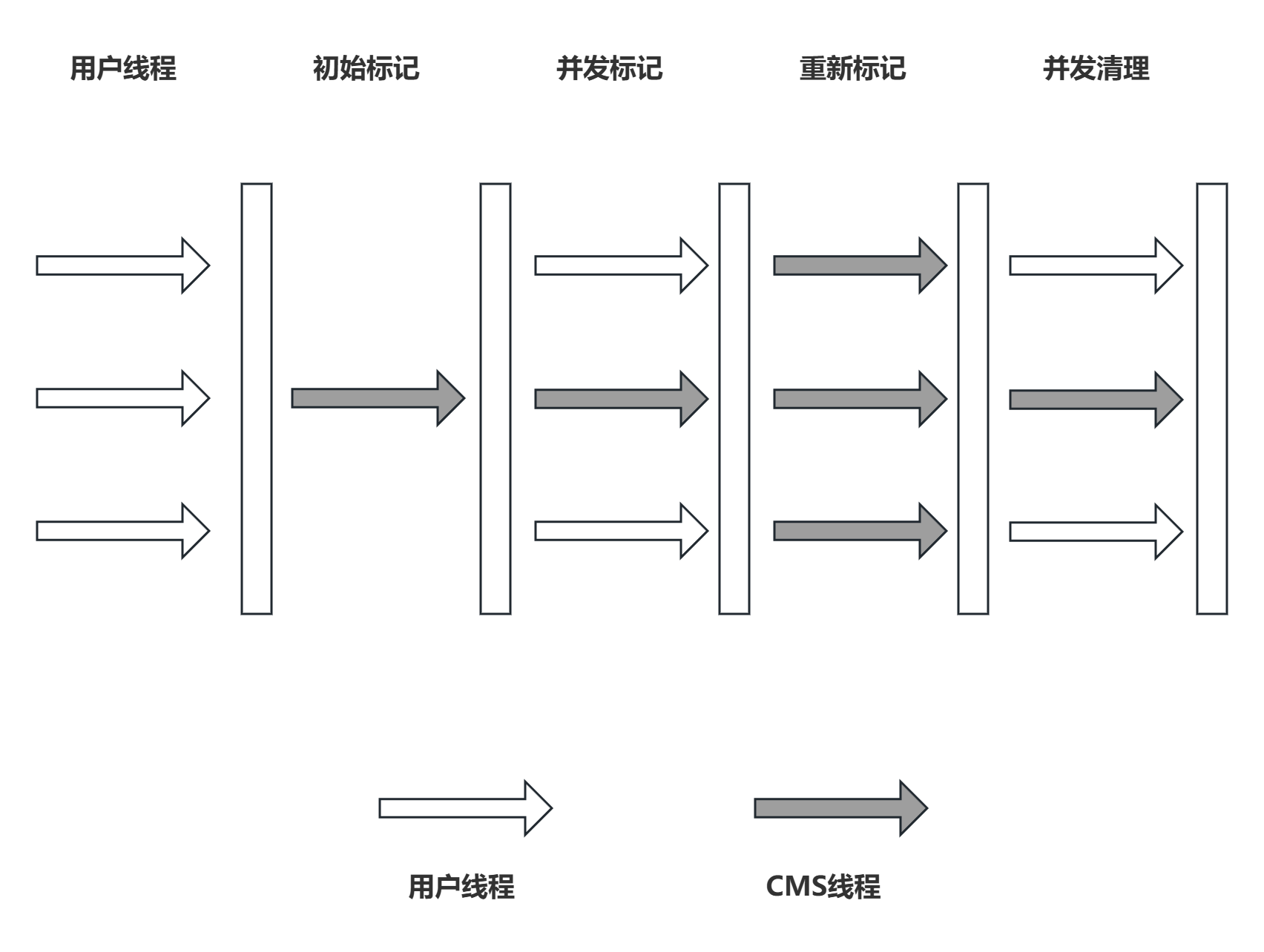
-
四步执行流程(关键,决定低停顿特性):
- 初始标记:STW,标记 GC Roots 直接引用的对象,耗时极短(毫秒级)。
- 并发标记:无 STW,遍历对象图,耗时久但与用户线程并发。
- 重新标记:STW,修正并发标记的漏标(用增量更新),耗时短于并发标记。
- 并发清理:无 STW,清理未标记对象,与用户线程并发;新增对象标记为黑色(浮动垃圾)。
-
三大缺点:
- CPU 敏感:并发阶段占用 CPU 资源,影响用户线程响应。
- 浮动垃圾:并发清理阶段产生的垃圾,需下一轮 GC 回收。
- 内存碎片:标记 - 清除算法导致,可通过
-XX:+UseCMSCompactAtFullCollection在 FullGC 后整理。
-
核心参数:
参数名称 作用 默认值 -XX:ConcGCThreads 设置并发 GC 线程数 约 CPU 核数 1/4 -XX:CMSInitiatingOccupancyFraction 老年代使用率达该比例触发 FullGC 92(百分比) -XX:CMSFullGCsBeforeCompaction 多少次 FullGC 后执行碎片整理 0(每次都整理) -XX:+CMSScavengeBeforeRemark CMS GC 前触发 Minor GC,减少标记开销 未开启
三、底层关键技术:保障并发标记的正确性
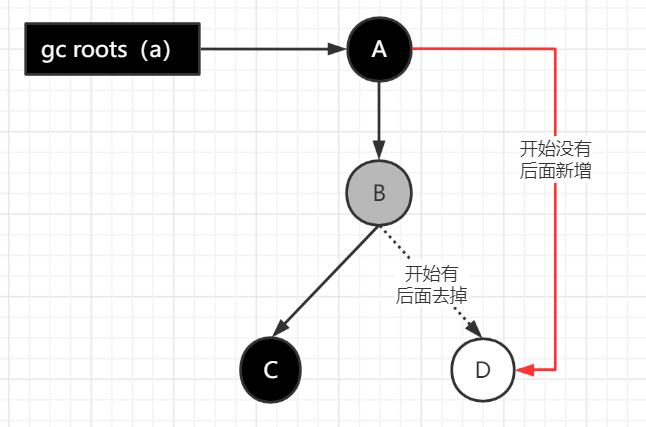
1. 三色标记算法:解决并发标记的 “多标” 与 “漏标”
- 颜色定义:
- 黑色:对象已扫描,且所有引用已遍历,安全存活(不可直接指向白色对象)。
- 灰色:对象已扫描,但部分引用未遍历。
- 白色:对象未扫描,分析结束后仍为白色则可回收。
- 核心问题:
- 多标(浮动垃圾):并发标记中,GC Roots(如局部变量)销毁,但其引用的对象已标记为非垃圾,本轮无法回收,需下一轮处理(不影响正确性)。
- 漏标(严重 bug):并发标记中,对象引用变化导致本应存活的白色对象未被标记,需通过读写屏障解决。
2. 漏标解决方案:增量更新与 SATB
| 方案名称 | 核心逻辑 | 适用收集器 | 实现方式 |
|---|---|---|---|
| 增量更新 | 黑色对象新增指向白色对象的引用时,记录该引用;重新标记阶段以黑色对象为根重新扫描 | CMS | 写屏障(post_write_barrier) |
| SATB(原始快照) | 灰色对象删除指向白色对象的引用时,记录该引用;重新标记阶段以灰色对象为根重新扫描 | G1/Shenandoah | 写屏障(pre_write_barrier) |
原始快照:重新标记阶段,没有新的对象引用之前记录的白色对象时,白色对象作为浮动垃圾,下一轮垃圾回收时再处理
- 读写屏障:类似 AOP,在对象引用赋值 / 读取前后插入处理逻辑:
- 写屏障:
pre_write_barrier(赋值前记录旧引用)、post_write_barrier(赋值后记录新引用)。 - 读屏障:
pre_load_barrier(读取前记录引用),ZGC 使用。
- 写屏障:
这是C++代码级别的屏障,不同于内存屏障
3. 记忆集与卡表:优化跨代引用扫描
- 问题背景:新生代 GC 时,若扫描老年代的跨代引用,效率极低。
- 记忆集:记录 “非收集区(如老年代)指向收集区(如新生代)的引用”,避免全区域扫描。
- 卡表:记忆集的实现方式(类似 HashMap 与 Map 的关系):
- 结构:字节数组
CARD_TABLE[],每个元素对应1 个卡页(HotSpot 中 1 卡页 = 512 字节)。 - 逻辑:卡页内有跨代引用时,对应卡表元素设为 1(脏标记);GC 时仅扫描 “脏卡页” 对应的引用。
- 维护:通过写屏障,在对象引用赋值时更新卡表的脏标记。
- 结构:字节数组
四、实战:亿级流量电商订单系统的 JVM 参数优化(ParNew+CMS)
1. 系统场景
- 规模:日活 500 万,日均 50 万单,大促峰值 300 单 / 秒,每秒产生 60MB 对象(放大后)。
- 目标:减少 FullGC,降低停顿时间。
2. 核心参数配置
| 参数类别 | 参数名称 | 取值 | 作用 |
|---|---|---|---|
| 内存基础 | -Xms/-Xmx | 3072M | 堆内存固定,避免扩容开销 |
| 内存基础 | -Xmn | 2048M | 新生代占比 2/3,减少对象进入老年代 |
| 内存基础 | -Xss | 1M | 线程栈大小,避免栈溢出 |
| 元空间 | -XX:MetaspaceSize/-XX:MaxMetaspaceSize | 256M | 元空间固定,避免频繁 GC |
| 新生代优化 | -XX:SurvivorRatio | 8 | Eden:Survivor=8:1:1,符合默认比例 |
| 新生代优化 | -XX:MaxTenuringThreshold | 5 | 对象 5 次 MinorGC 后进入老年代(默认 15) |
| 新生代优化 | -XX:PretenureSizeThreshold | 1M | >1M 的大对象直接进入老年代 |
| CMS 优化 | -XX:+UseParNewGC/-XX:+UseConcMarkSweepGC | - | 启用 ParNew+CMS 组合 |
| CMS 优化 | -XX:CMSInitiatingOccupancyFraction | 92 | 老年代使用率 92% 触发 FullGC |
| CMS 优化 | -XX:+UseCMSCompactAtFullCollection | - | FullGC 后执行碎片整理 |
| CMS 优化 | -XX:CMSFullGCsBeforeCompaction | 3 | 每 3 次 FullGC 后整理一次(减少整理频率) |
关键问题
问题 1:CMS 收集器以 “低停顿” 为核心优势,但其并发标记阶段可能出现 “漏标” 问题,导致本应存活的对象被误回收,JVM 是如何通过技术手段解决这一问题的?
答案:CMS 通过 “增量更新”+“写屏障” 解决漏标问题,具体逻辑如下:
- 漏标场景:并发标记中,黑色对象(已完成扫描)新增指向白色对象(未扫描)的引用,若不处理,白色对象会被误判为垃圾。
- 核心方案(增量更新):
- 当黑色对象插入新的指向白色对象的引用时,通过写屏障的 post_write_barrier操作,将该新引用记录到 “重新标记集合(remark_set)” 中。
- 并发标记结束后,进入 “重新标记” 阶段(短暂 STW),以记录集中的黑色对象为根,重新扫描其引用的白色对象,将这些白色对象标记为灰色 / 黑色,避免漏标。
- 写屏障的作用:类似 AOP 切面,在对象引用赋值(如
a.d = d)的 “赋值后” 插入记录逻辑,确保所有新增的跨颜色引用都被捕获,为重新标记提供依据。
问题 2:新生代 GC(如 ParNew)时,为何需要 “卡表” 这一数据结构?它的工作原理是什么?
答案:卡表的核心作用是优化跨代引用的扫描效率,避免新生代 GC 时全量扫描老年代;其工作原理基于 “记忆集” 思想,具体如下:
- 必要性:新生代 GC 的收集范围是新生代,但老年代中可能存在指向新生代的引用(跨代引用),若全量扫描老年代,会导致 GC 效率极低。卡表通过记录 “老年代→新生代” 的引用位置,仅扫描这些位置,减少扫描范围。
- 工作原理:
- 结构:卡表是字节数组
CARD_TABLE[],每个元素对应 1 个 “卡页”(HotSpot 中 1 卡页 = 512 字节),卡页覆盖老年代的内存区域。 - 脏标记:当老年代某卡页内的对象新增指向新生代的引用时,通过写屏障将卡表中对应元素设为 1(脏标记)。
- GC 扫描:新生代 GC 时,仅筛选卡表中 “脏标记(1)” 对应的卡页,扫描其中的跨代引用,将这些引用作为 GC Roots 的补充,无需扫描整个老年代。
- 结构:卡表是字节数组
问题 3:在亿级流量电商订单系统中,为何选择 “ParNew+CMS” 的收集器组合?并说明核心参数(如 - Xmn、-XX:MaxTenuringThreshold)的优化逻辑是什么?
答案:选择 “ParNew+CMS” 及参数优化的核心逻辑是匹配系统 “低停顿、高并发” 的需求,具体如下:
- 收集器组合选择原因:
- 系统特性:电商订单系统对响应时间敏感(如大促峰值 300 单 / 秒),需避免长时间 STW;ParNew 是新生代多线程收集器,可配合 CMS(老年代并发收集器),实现 “新生代快速 MinorGC + 老年代低停顿 FullGC”,符合低停顿需求。
- 对比其他组合:Parallel Scavenge+Parallel Old 关注吞吐量,STW 时间较长,不适合用户交互场景;Serial+Serial Old 单线程,无法应对高并发,故排除。
- 核心参数优化逻辑:
- -Xmn=2048M:新生代内存设为 2GB(堆总 3GB 的 2/3),增大 Eden 区容量,减少 MinorGC 频率(每秒 60MB 对象需 30 秒才占满 Eden)。
- -XX:MaxTenuringThreshold=5:对象需经历 5 次 MinorGC 才进入老年代(默认 15 次)。系统中多数对象(如订单对象)几秒内变为垃圾,5 次 MinorGC(约 150 秒)可筛选出真正长期存活的对象(如 Spring Bean),避免短期对象频繁进入老年代导致 FullGC。
- -XX:PretenureSizeThreshold=1M:>1M 的大对象(如大缓存 Map)直接进入老年代,避免大对象在新生代频繁复制(复制算法对大对象成本高),减少 MinorGC 开销。













 - 详解)

时的一些问题)



