目录
一、背景
二、整体架构
三、组件详解
3.1 yarn
3.2 hdfs
四、计算流程
4.1 上传资源到 HDFS
4.2 向 RM 提交作业请求
4.3 RM 调度资源启动 AM
4.4 AM运行用户代码
4.5 NodeManager运行用户代码
4.6 资源释放
五、设计不足
一、背景
有人可能会好奇,为什么要学一个十年前的东西呢?
Hadoop 2.x虽然是十年前的,但hadoop生态系统中的一些组件如今还在广泛使用,如hdfs和yarn,当今流行spark和flink都依赖这些组件
通过学习它们的历史设计,首先可以让我们对它们的了解更加深刻,通过了解软件的演变的过程也能对我们改进自有的系统做启发
之前我们分析了Hadoop 1.x Hadoop 1.x设计理念解析-CSDN博客,说明了其中的一些问题,现在来看2.x
二、整体架构
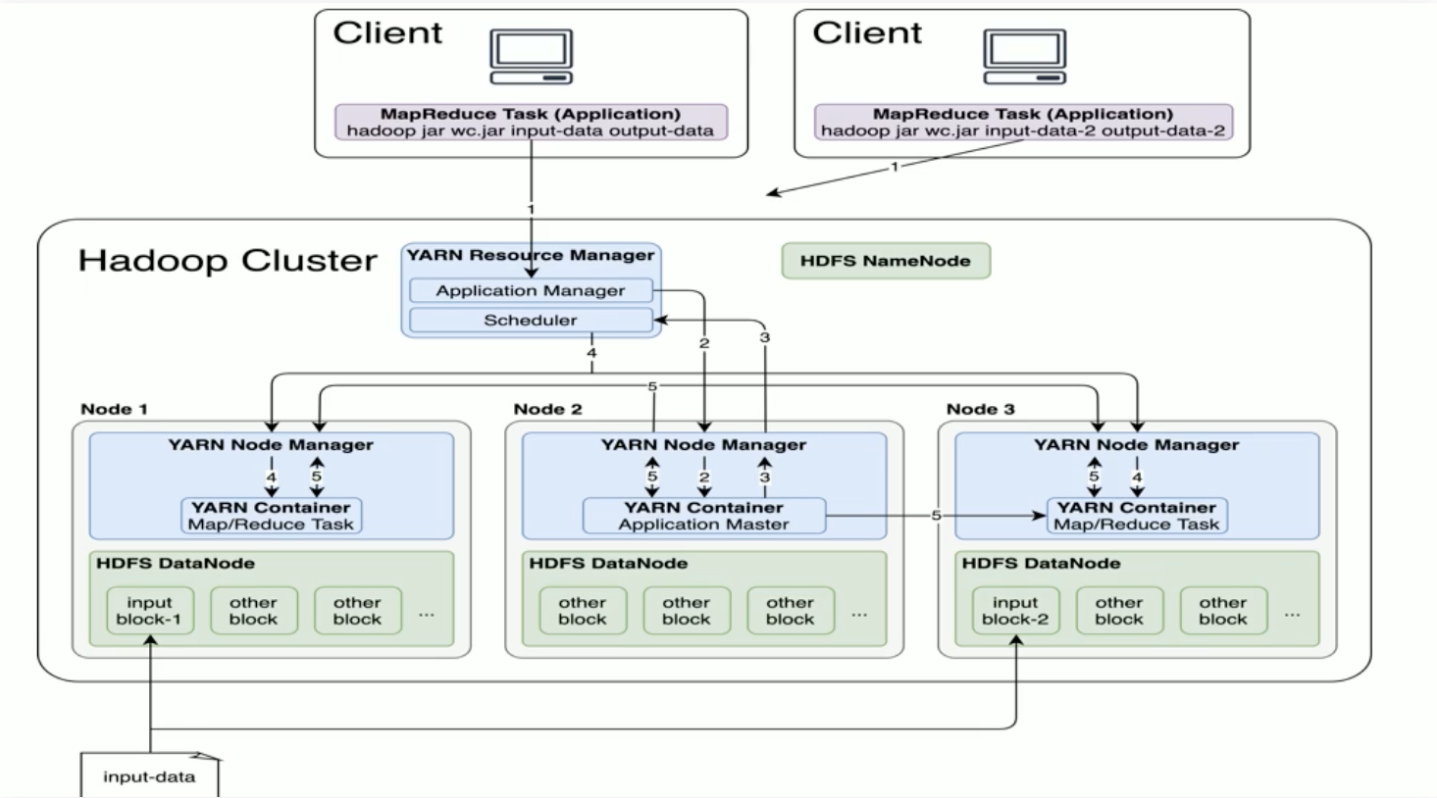
从网上找了一张图:
yarn统计集群资源情况,分配资源Container给hadoop使用
hdfs作为数据中转,负责jar包、中间数据的中转
图中没体现yarn和hdfs高可用的实现,具体高可用实现会在下面的组件详解中提及
三、组件详解
强烈建议:刚了解这块的看组件详解可能没那么好理解,建议直接看下面的第四章计算流程,看完计算流程后,有一个大概的了解了,再来学习组件详解
3.1 yarn
1. ResourceManager(RM)
核心职责
-
全局资源管理:管理整个集群的资源(CPU、内存等),负责资源分配和调度。
-
应用生命周期管理:接收客户端提交的应用请求,启动 ApplicationMaster(AM),监控应用状态。
-
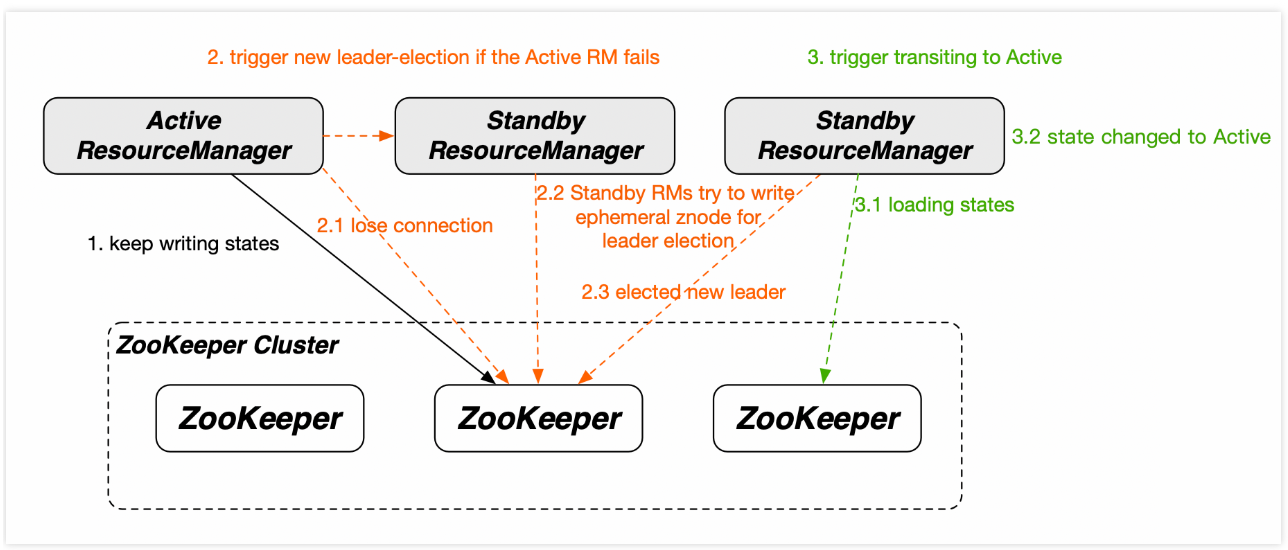
高可用支持:通过主备(Active/Standby)架构避免单点故障,依赖 ZooKeeper 实现自动故障转移。
子模块
-
Scheduler(调度器):
-
纯调度器,仅负责资源分配(不跟踪应用状态)。
-
支持多种调度策略:容量调度(Capacity Scheduler)、公平调度(Fair Scheduler)。
-
-
ApplicationsManager:
-
管理应用提交、启动 AM、记录应用元数据(如用户、队列信息)。
-
高可用机制
-
主备 RM:通过 ZooKeeper 选举 Active RM,状态持久化到 HDFS 或 ZooKeeper。
-
快速故障切换:Standby RM 在 Active RM 宕机后秒级接管。
2. NodeManager(NM)
核心职责
-
单节点资源管理:管理单个物理节点上的资源(如 CPU、内存、磁盘),向 RM 汇报资源状态。
-
容器(Container)生命周期管理:
-
启动、监控、销毁容器(Container)。
-
执行来自 AM 的任务指令(如启动 Map/Reduce 任务)。
-
-
本地化服务:缓存应用依赖的 JAR 包、配置文件等,加速任务启动。
关键机制
-
心跳机制:定期向 RM 发送心跳,汇报节点资源使用情况和容器状态。
-
资源隔离:通过 Linux Cgroups 或 Docker 实现 CPU、内存隔离,避免任务间资源争抢。
-
健康检查:监控节点硬件(如磁盘损坏、内存不足),异常时主动报告 RM。
3. Container(容器)
核心概念
-
资源封装单元:代表集群中可分配的资源(如 2 CPU 核心 + 4GB 内存)。
-
任务执行环境:在 NM 上启动的进程,运行具体任务(如 MapTask、ReduceTask)。
4. ApplicationMaster(AM是Container的一种)
核心职责
-
应用级资源协商:向 RM 申请资源(Container),并协调任务的执行。
-
任务容错:监控任务状态,失败时重新申请资源并重试。
-
应用进度汇报:向 RM 报告应用进度(如 MapReduce 的 Map 完成百分比)。
特点
-
应用专属:每个应用(如 MapReduce 作业、Spark 作业)有独立的 AM。
-
灵活性:AM 由用户程序实现(如 MapReduce 的
MRAppMaster),支持自定义资源请求策略。
容错机制
-
RM 托管状态:AM 定期向 RM 发送心跳,RM 故障切换后重启 AM 并恢复状态。
-
检查点(Checkpoint):部分框架(如 Flink)支持将状态持久化到 HDFS,故障后从检查点恢复。
3.2 hdfs
在Hadoop 1.x 架构中,hdfs的NameNode(NM)只有一个,当NameNode挂了之后,容易造成数据丢失,所以在Hadoop 2.x架构中,NameNode变成了多个,通过zk进行选主,架构如下:
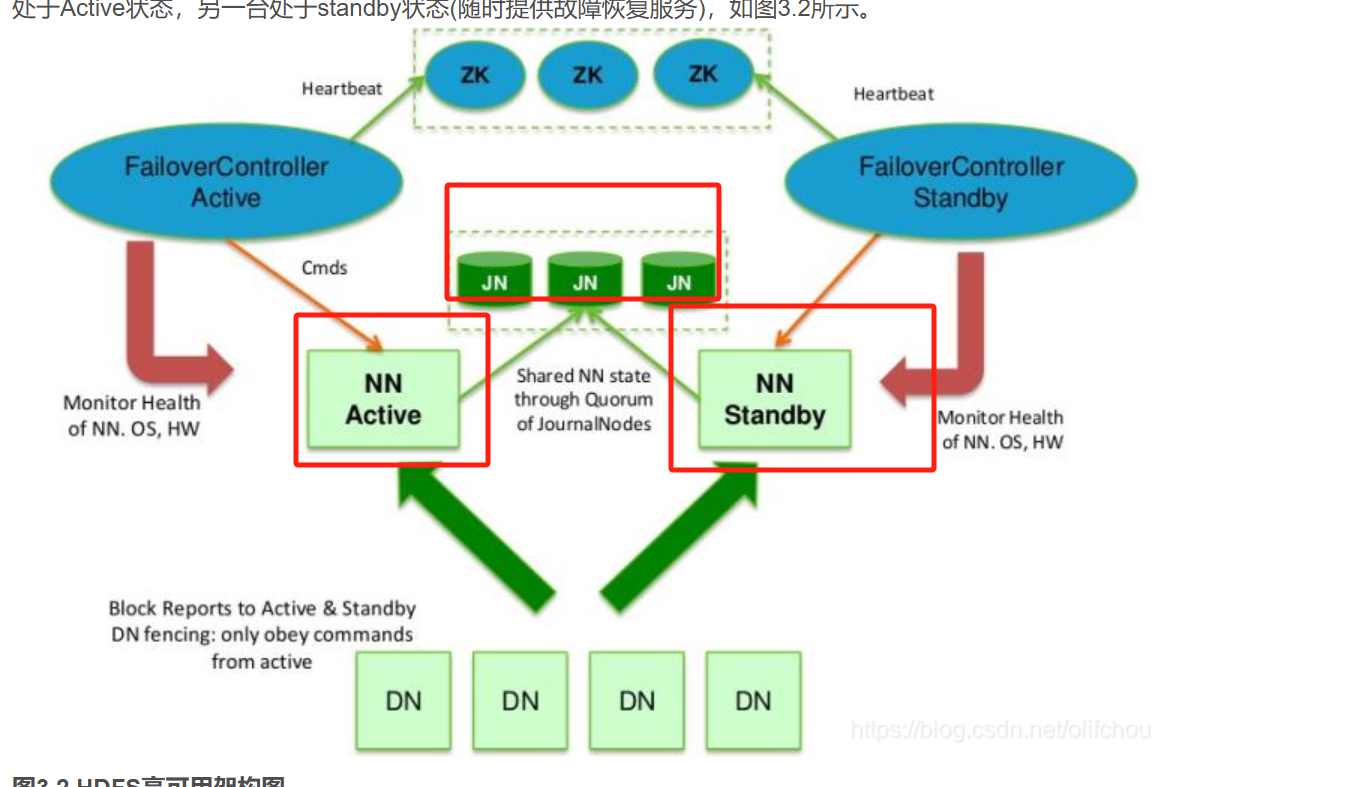
可以看到上图中除了NameNode,还有JournalNodes(JN)
JournalNodes集群用于存储NameNode的EditLog(记录文件系统元数据变更的日志)
JN的作用是保证NM的master和stand by 之间的数据一致性,因为NameNode多了之后,主备之间需要数据同步,一条NameNode EditLog变更内容,需要被需确保大多数节点(Quorum)成功写入,才算变更成功,Standby NameNode定期从JournalNodes读取EditLog,并应用到自身内存中的元数据(FsImage)
这样当主NM挂了之后,不会因为数据变更没及时同步给stand by节点,导致数据丢失
四、计算流程
4.1 上传资源到 HDFS
-
客户端将作业的 JAR 包、配置文件(如
mapred-site.xml)和输入数据分片(InputSplit)上传到 HDFS。 -
例如,JAR 包会被上传到 HDFS 路径
/user/hadoop/jobs/myjob.jar。
4.2 向 RM 提交作业请求
-
客户端通过 YARN RPC 协议 向 RM 提交作业请求,包含以下信息:
-
ApplicationMaster(AM)的入口类(如
org.apache.hadoop.mapreduce.v2.app.MRAppMaster)。 -
HDFS 上的资源路径(JAR、配置文件等)。
-
作业配置参数(如 Map/Reduce Task 的内存、CPU 需求)。
-
4.3 RM 调度资源启动 AM
-
RM 根据集群资源状态,选择一个 NodeManager(NM)节点,分配一个 Container(初始资源,如 1GB 内存、1 核 CPU)。
-
向该 NM 发送指令,启动 AM 进程。
Q:Container的本质是什么?
在hadoop、spark、flink情况下,Container是一个JVM进程
Q:Container 什么时候被创建?

Q:NM如何启动的Container?
通过类似如下代码:
java \
-Djava.net.preferIPv4Stack=true \
-Xmx1024m \
-Djava.io.tmpdir=/tmp/hadoop-tmp \
-Dlog4j.configuration=container-log4j.properties \
-Dyarn.app.container.log.dir=<日志目录路径> \
-classpath <Hadoop类路径>:<用户Jar路径> \
org.apache.hadoop.mapred.YarnChild \
<作业ID> <任务ID> <用户类名>根据如上代码可以看到,实际入口是Hadoop的YarnChild,而非用户类,通过反射机制实例化用户编写的Mapper/Reducer,每个Task在独立JVM中运行,避免相互影响
Q:NM如何限制jvm进程的内存和cpu核数?
内存通过xmx限制,cpu核数通过linux指令限制
Q:NodeManager 怎么来的,用户在机器上启动的应用么?
-
集群管理工具:如 Apache Ambari、Cloudera Manager 等工具统一部署和启动。
-
手动脚本:在传统 Hadoop 部署中,通过
yarn-daemon.sh start nodemanager命令手动启动
4.4 AM运行用户代码
-
初始化与注册:
-
AM 启动后,向 RM 注册自身,并申请运行 Map/Reduce Task 所需的资源(Container)。
-
-
从 HDFS 加载用户代码:
-
AM 从 HDFS 下载作业的 JAR 包和配置文件到本地。
-
使用 分布式缓存(Distributed Cache) 机制,将依赖文件(如 JAR、配置文件)分发到所有任务节点。
-
-
申请资源并启动任务:
-
AM 向 RM 发送资源请求(如申请 10 个 Container 运行 Map Task)。
-
RM 分配 Container 后,AM 与目标 NodeManager 通信,触发 Container 的启动
-
am请求分配Container代码示例:
// 伪代码示例(类似YARN API)
ResourceRequest request = ResourceRequest.newInstance(Priority.HIGH, // 优先级"node_hostname", // 目标节点(或*表示任意)Resource.newInstance(1024, 4), // 1GB内存 + 4个vCore5 // 需要5个这样的Container
);
amClient.addResourceRequest(request);如果资源足够,RM会:
-
根据集群的当前资源使用情况(由NodeManager定期上报)和调度策略(如Capacity Scheduler、Fair Scheduler),决定是否满足AM的请求。
-
若资源足够,调度器将分配Container,生成
Container对象,包含:-
Container ID。
-
分配的节点(NodeManager地址)。
-
资源规格(如内存、CPU)。
-
然后通过心跳机制(AM定期轮询或事件驱动)将分配的Container信息返回给AM
AM收到ResourceManager分配的Container列表后,会向对应的NodeManager发送启动Container的指令
4.5 NodeManager运行用户代码
-
创建 Container 进程:
-
NodeManager 收到 AM 的启动指令后,在本地创建一个 独立的 JVM 进程(如 Map Task)。
-
该进程的入口类是用户编写的
Mapper或Reducer实现类。
-
-
加载用户代码:
-
Container 进程从 HDFS 或本地缓存(通过 Distributed Cache)加载 JAR 包和依赖。
-
使用
URLClassLoader动态加载用户类(如MyMapper.class)。
-
-
执行任务逻辑:
-
调用用户实现的
map()或reduce()方法处理数据。 -
输出结果写入 HDFS 或中间存储。
-
Q:AM收到ResourceManager分配的Container列表后,会向对应的NodeManager发送启动Container的指令。 NodeManager如何确认收到的命令是否合法?
在安全集群(启用Kerberos)中,所有组件(包括AM、RM、NM)必须通过Kerberos认证才能通信:
-
初始化认证:AM在向RM注册时,需提供有效的Kerberos票据(Ticket)以证明身份。
-
服务票据:AM与NM通信时,会使用Kerberos获取NM的服务票据,确保通信双方身份合法。
即使通过Kerberos认证,YARN还需进一步限制AM的操作权限。为此,RM在分配Container时会生成容器令牌,作为AM向NM启动Container的“临时授权凭证”。
容器令牌的生成与传递
-
RM生成容器令牌:
-
当RM的调度器为AM分配Container时,会为该Container生成一个唯一的容器令牌。
-
令牌包含以下信息:
-
Container ID。
-
资源分配详情(如内存、CPU)。
-
有效时间窗口(如过期时间)。
-
NM的地址(确保令牌仅能被目标NM使用)。
-
数字签名(由RM的密钥签名,防篡改)。
-
-
-
AM获取令牌:
-
RM将分配的Container列表及对应的容器令牌返回给AM(通过心跳响应)。
-
AM需在启动Container时将此令牌提交给NM。
-
NodeManager验证容器令牌
当NM收到AM的StartContainerRequest时,会执行以下验证:
-
验证令牌签名:
-
使用RM的公钥验证令牌的签名,确保令牌未被篡改。
-
-
检查令牌有效期:
-
确保令牌未过期(如过期则拒绝请求)。
-
-
匹配目标NM:
-
确认令牌中的NM地址与当前NM的地址一致,防止令牌被转发到其他节点。
-
-
核对Container ID和资源规格:
-
检查请求的Container ID和资源是否与令牌中的分配一致。
-
-
权限校验:
-
确保AM有权操作该Container(例如,令牌中的用户与AM的身份一致)。
-
Q:任务进程(如MapTask)会定期向AM发送心跳,报告进度(如完成50%)。 MapTask 和 AM在两个不同的container中,它们如何知道对方地址并交互的?
步骤1:AM启动并注册
-
MRAppMaster(AM)启动后,绑定到一个可用端口(如
0.0.0.0:0由系统自动分配)。 -
向ResourceManager注册,提交自身的RPC地址(如
am-host:4321)。
步骤2:启动MapTask
-
AM向ResourceManager申请Container资源。
-
在Container启动参数中,设置环境变量
MAPREDUCE_JOB_APPLICATION_MASTER_ADDR=am-host:4321。
步骤3:MapTask向AM发送心跳
-
MapTask进程启动后,读取环境变量获取AM的地址。
-
通过Hadoop RPC客户端,连接到
am-host:4321。 -
调用AM的RPC接口(如
AMProtocol#statusUpdate),发送心跳信息:
4.6 资源释放
子任务的释放:
-
AM的核心职责:
-
管理应用程序的整个生命周期(如Map阶段和Reduce阶段的协调)。
-
主动申请和释放资源:AM根据任务进度动态管理Container,当MapTask完成后,AM会主动释放这些Container的资源,以便进入Reduce阶段。
-
-
具体流程:
-
监控任务状态:AM持续监控所有MapTask的进度,当所有MapTask均完成后,AM标记Map阶段结束。
-
释放Container:
-
AM向对应的NodeManager发送
StopContainerRequest,要求停止MapTask占用的Container。 -
AM通过心跳机制通知ResourceManager的调度器(Scheduler),这些Container已释放,资源可重新分配。
-
-
进入Reduce阶段:AM开始申请新的Container资源以启动ReduceTask。
-
AM的释放:
正常释放流程
-
AM完成工作:当ApplicationMaster完成其分配的任务后,它会主动向ResourceManager(RM)发送完成通知。
-
注销AM:
-
AM调用
AMRMClient.unregisterApplicationMaster()方法 -
该方法向RM发送
FinishApplicationMasterRequest请求
-
-
RM处理请求:
-
RM接收到请求后,将AM状态标记为已完成
-
RM通知NodeManager(NM)释放AM容器
-
-
容器清理:
-
NM接收到释放指令后,停止AM进程
-
清理容器的工作目录
-
释放分配给该容器的资源
-
-
状态更新:
-
RM更新应用程序状态为FINISHED
-
资源调度器回收分配给该AM的所有资源
-
异常释放流程
如果AM异常终止,释放流程会有所不同:
-
心跳超时:
-
RM通过心跳机制检测AM是否存活
-
如果超过
yarn.am.liveness-monitor.expiry-interval-ms(默认60000ms)未收到心跳,RM认为AM失效
-
-
标记失败:
-
RM将AM状态标记为FAILED
-
触发失败处理机制
-
-
容器清理:
-
RM通知NM强制终止AM容器
-
NM执行kill操作并清理资源
-
-
重试机制:
-
根据
yarn.resourcemanager.am.max-attempts配置决定是否重试 -
如果允许重试,RM会启动新的AM容器
-
五、设计不足
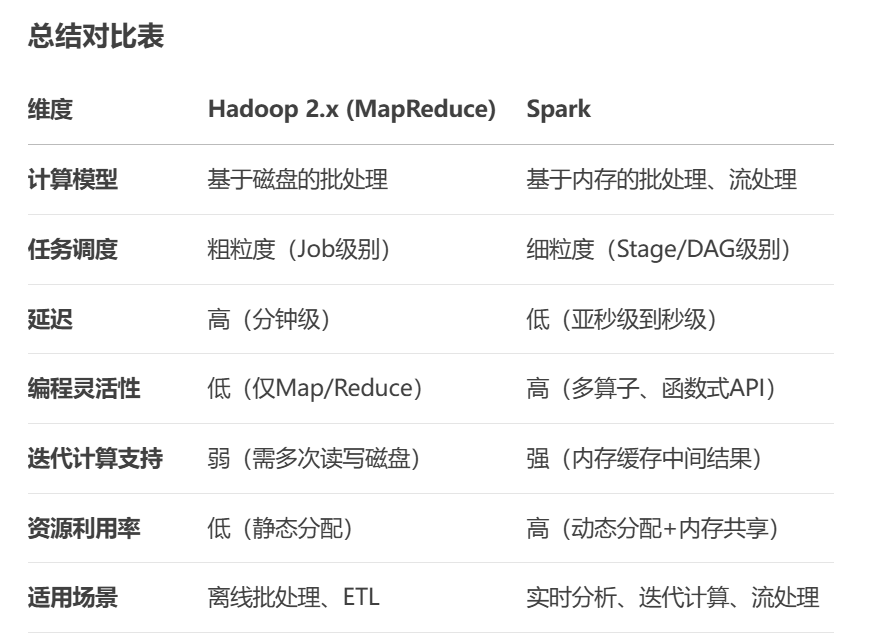
Hadoop 2.x 计算理念,相对于spark计算理念的不足,这里直接上deepseek的回答了:
1. 基于磁盘的计算模型导致性能瓶颈
-
Hadoop:MapReduce的每个中间阶段(Map和Reduce)都需要将数据写入磁盘(HDFS),导致频繁的I/O操作。在迭代计算(如机器学习算法)或需要多阶段处理的任务中,反复读写磁盘的开销极大,性能显著下降。
-
Spark:通过内存计算(In-Memory Processing)和弹性分布式数据集(RDD)的缓存机制,减少磁盘I/O。中间结果优先保留在内存中,适合迭代和交互式任务,性能通常比Hadoop快10-100倍。
2. 任务调度的延迟较高
-
Hadoop:每个MapReduce作业(Job)启动时都需要重新申请资源,且单个Job内分为Map和Reduce两个阶段,任务调度(Task Scheduling)粒度较粗。对于多阶段任务(如多个Job串联的场景),需要重复调度和资源分配,增加了整体延迟。
-
Spark:采用DAG(有向无环图)调度器,将整个计算流程分解为多个Stage,并在一个作业(Job)内自动优化执行顺序,避免多次任务调度。此外,通过细粒度的任务划分,减少资源浪费。
3. 编程模型不够灵活
-
Hadoop:MapReduce的编程模型强制开发者将逻辑拆分为
Map和Reduce两个阶段,对复杂计算(如多表关联、图算法)的支持较差,代码冗长且难以复用。 -
Spark:提供更丰富的API(如
map、filter、join、reduceByKey等)和高级抽象(RDD、DataFrame、Dataset),支持函数式编程和复杂流水线操作。开发者可以更灵活地表达计算逻辑,代码量显著减少。
4. 对实时和流式处理支持有限
-
Hadoop:原生设计面向批处理,延迟通常在分钟到小时级别。虽然可以通过附加框架(如Storm)实现流处理,但需要额外的系统集成。
-
Spark:通过Spark Streaming(微批处理)和Structured Streaming(准实时流处理)直接支持流式计算,并与批处理API保持统一,简化开发流程。
5. 资源利用效率较低
-
Hadoop:MapReduce在任务执行期间资源分配较为静态,任务结束后资源立即释放,难以共享复用。在YARN的调度下,资源分配粒度较粗。
-
Spark:通过动态资源分配和内存缓存机制,允许不同任务共享数据缓存,资源利用率更高。同时支持在内存中缓存中间数据,减少重复计算。
6. 对复杂计算场景的支持不足
-
Hadoop:对机器学习、图计算等需要多次迭代的场景支持较弱(需多次启动作业),需要依赖其他生态工具(如Mahout)。
-
Spark:通过内置库(如MLlib、GraphX)直接支持机器学习、图计算等复杂场景,利用内存计算加速迭代过程












)

)



)
