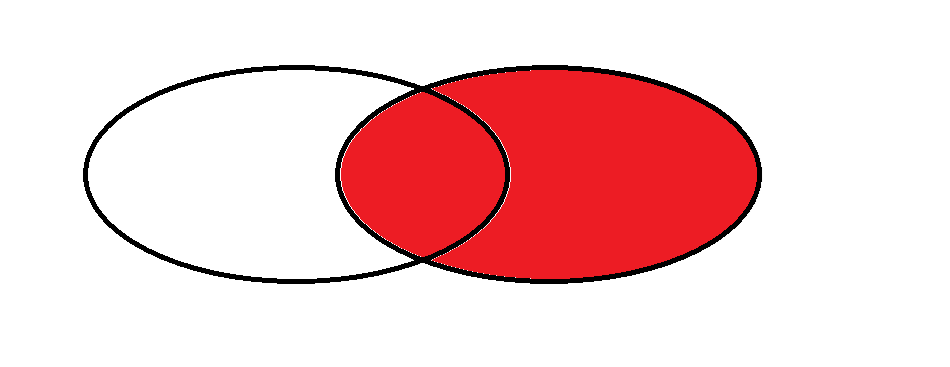
一.联合查询/多表查询
联合查询关键在于笛卡尔积的过程
笛卡尔坐标积的排列组合
首先它会将两个表用排列组合的方式进行排列组合。
表一
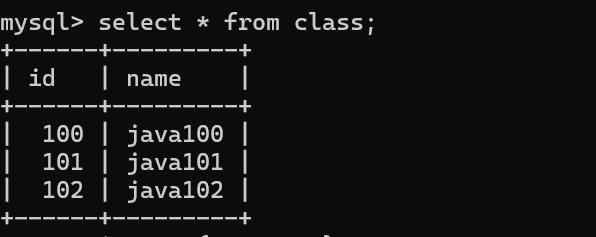
表二
进行排列组合
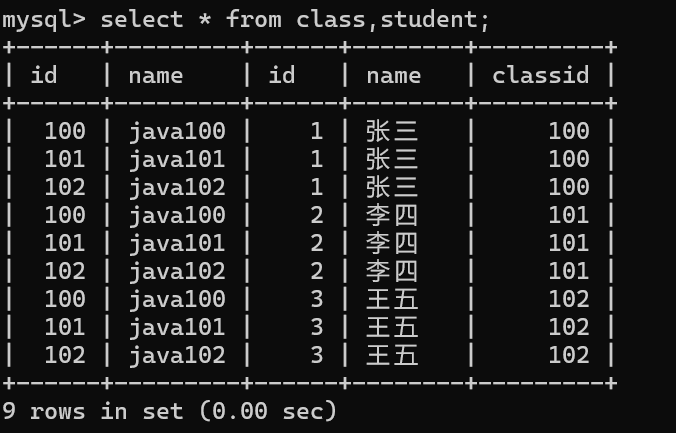
我们发现它的行是 两个表的行相乘,列是两表的列相加。
我们所看到的数据有合理的也有不合理的我们接下来要做的就是将这些不合法的数据剔除,另外这种方法十分不安全,因为数据量太过庞大了,就行相乘来说就足以让服务器崩溃。
筛选
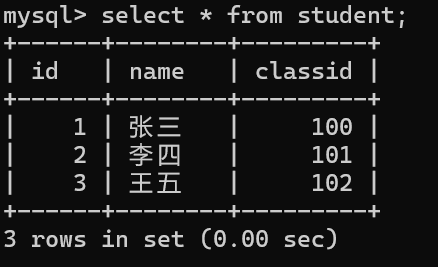
我们得找两个表的相同项比如id这一项
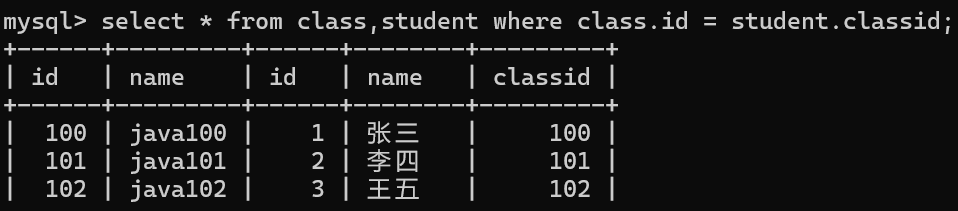
这下数据就是有效的了,都是有效信息。美化一下
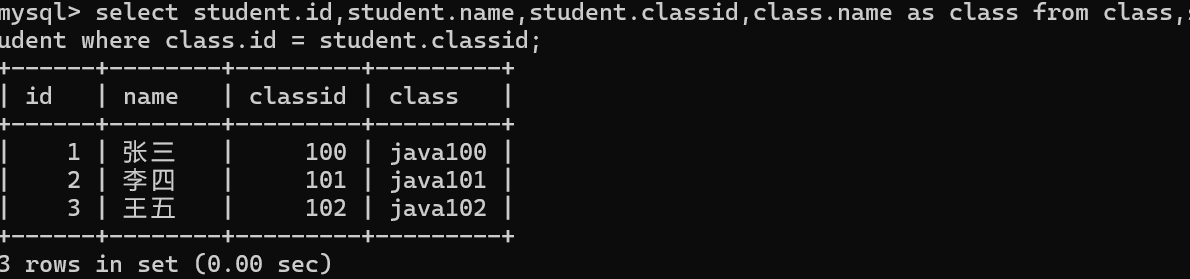
这种方法虽然方便但可读性差,还不安全。
在两个表之间有关联的情况下合成的表为内连接反之为外连接
内连接

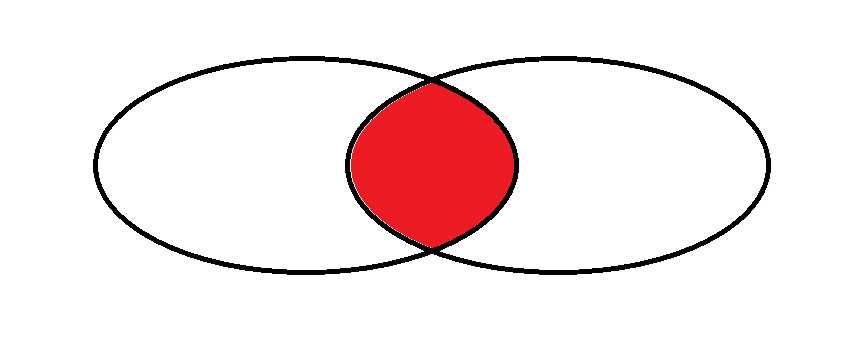
外连接
左连接

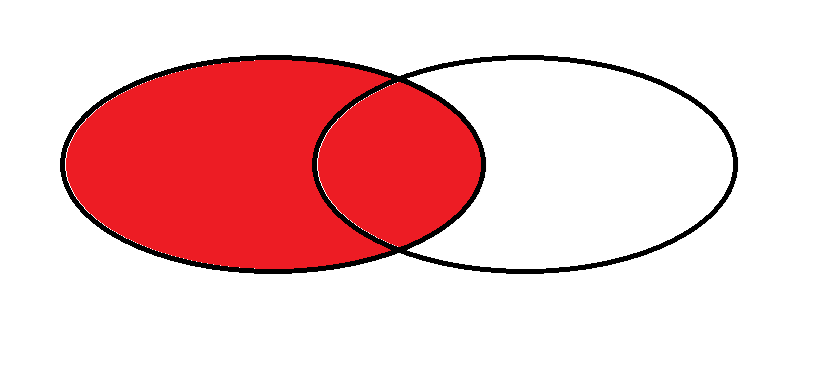
右连接
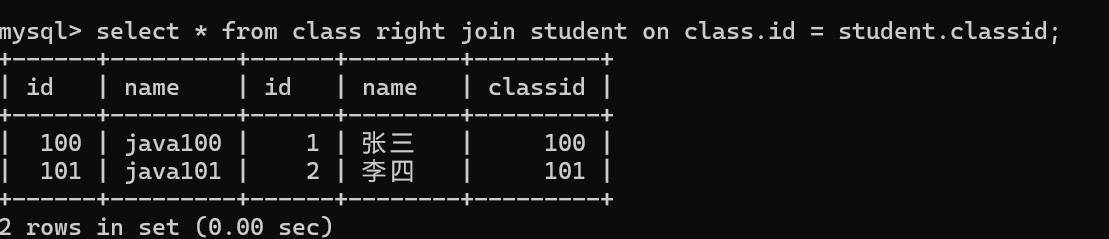
自连接
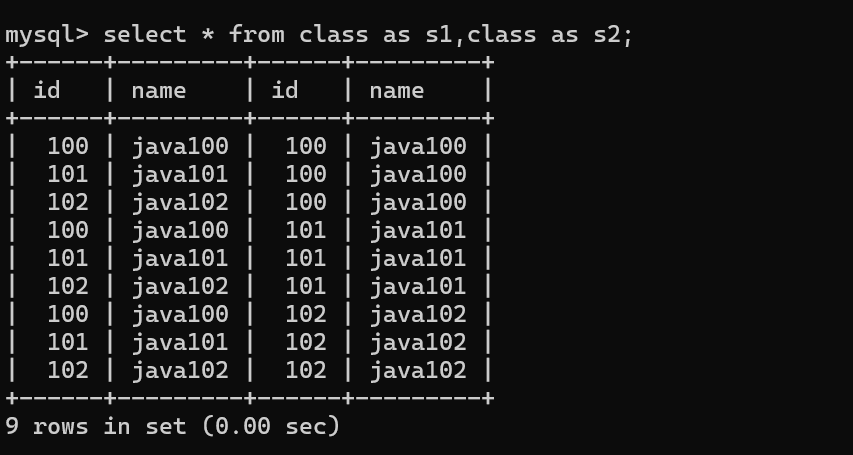 二.联合查询
二.联合查询

这个方法可以将两个完全不同的表合并在一起,会自动去重,如果不想去重则须在union后加上all
三.索引
索引能够提高查询速度,但是会占用更多的空间来生成索引,但是可能会降低插入修改删除的速度,
1.查看索引 show index from 表名
2.创建索引 create index 索引名字 on 表名(列名)
3.删除索引 drop index 索引名 on 表名
另外主键和外键会自动生成索引,而删除索引这个操作对于自动生成的无效。
在创建索引时是一个危险操作,因为它会对现有的数据进行一次大规模的整理,如果表很大的胡,会导致服务器收到的请求量剧增。
所以我们会再搞另一个机器来部署mysql服务器,创建同样的表,并加上索引,然后将需要的表的数据导入这个表中。
索引背后的一些事情
索引是一个改进的树形结构,B+树(N叉搜索树)
B树
1.每个结点的度都是不一样的
2.一个结点保存N个key就划分N+1个区间
3.虽然一个节点可以保存N个key,但是达到一定的规模会触发节点的分裂,删除元素达到一定规模则会触发节点的合并
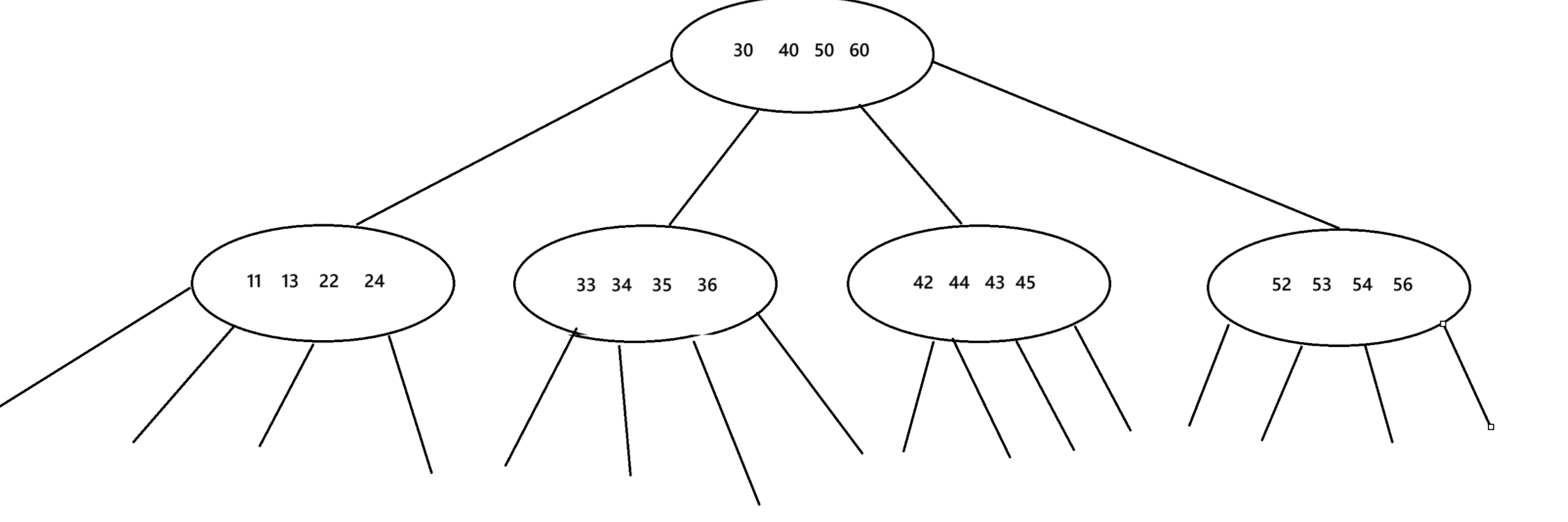
如果用B树来查询一个树可能就会很麻烦,因为会涉及到这颗树找不到就要返回到上一棵树来找,可能还不能找到,十分麻烦。
B+树
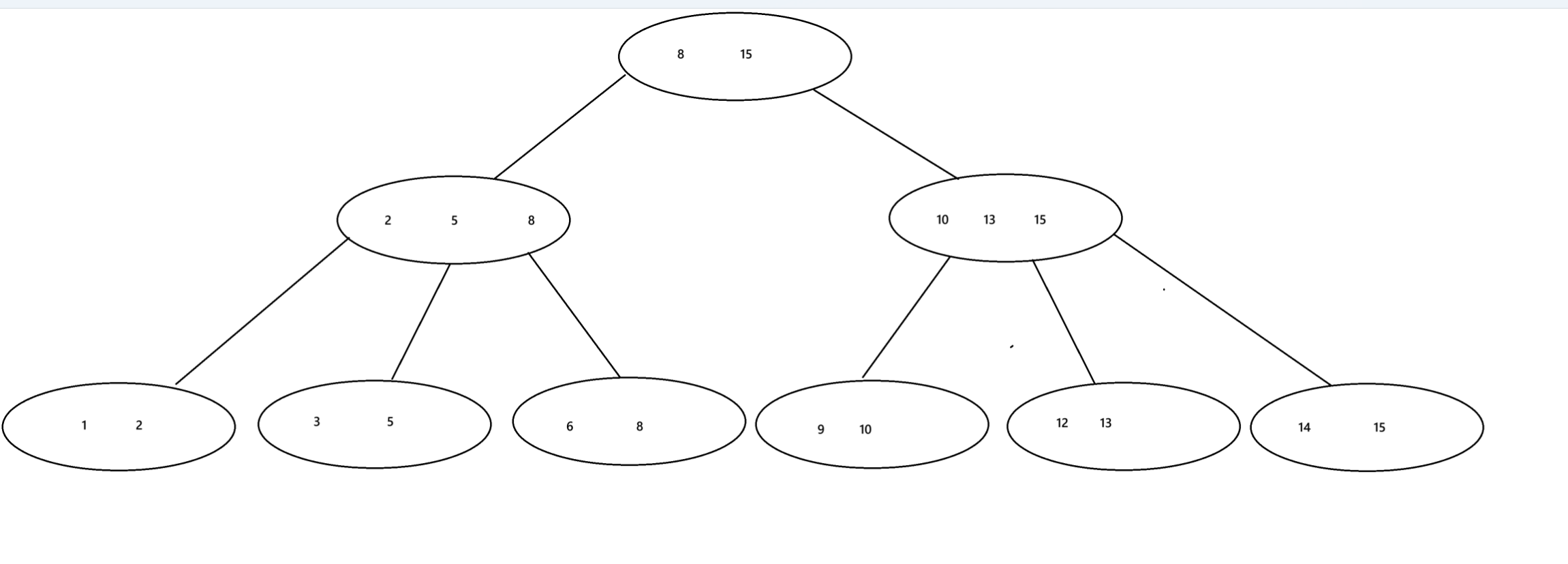
1.B+树也是一个N叉搜索树,一个节点上存在N个Key,划分N个区间
2.每个节点上N个key中,最后一个就是子树的最大值
3.父节点上的每个key都会以最大值的身份再子节点的对应区间中存在
所以我们看到在叶子节点上包含着树的所有元素
4.B+树会使用链表这样的结构,把叶子节点串起来
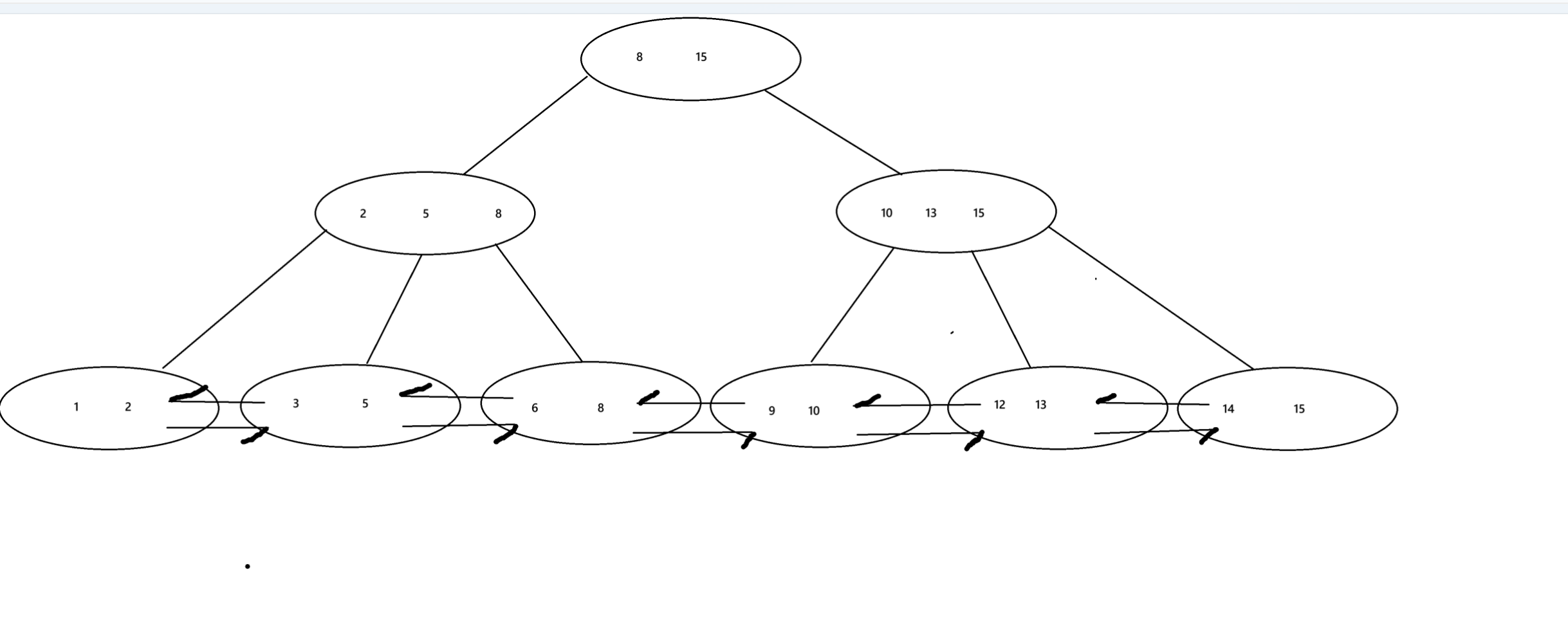 B树与B+树的比较
B树与B+树的比较
对于B树来说查询速度往往是不稳定的,因为如果查询的元素层数高的话就很快,反之,对于B+树来说最终都会在叶子节点来进行查询整体时间差距不大,是稳定的。
B+树的优点
1.N叉搜索树,树的高度受限,降低IO次数
2.非常擅长范围查询
3.所有查询最终都是要落到叶子节点上,查询与查询之间的花销都是稳定的。
4.由于叶子节点是全集,会把数据只存储在叶子节点上,非叶子节点只是存储一个用来排序的key,这样使得非叶子节点并不会占用多少空间,叶子节点会非常占用空间,将非叶子节点缓存在内存中,整体的查询速度又减少了。
四.事务
在转账过程中如果A转账给B而A的余额减少了,但发生了一些不可避免的意外,使得A的钱扣了,但B的钱却没有增加,这就是个很严重的错误。
而事务可以避免上面问题,且听我说
1.事务就可以把多个sql打包成一个整体
2.可以保证这些sql要么全部执行,要么一个都没执行成功。
我们将把多个sql打包在一起作为一个整体来执行,成为“原子性”。
有这么一个过程就是
开启事务
执行sql
结束事务
主动触发回滚
回滚
它通过日志的方式,记录事务中的关键操作,这样记录的数据就是回滚的依据(一旦发生重启等操作,就会发现回滚日志有一些需要进行回滚的操作,于是就可以完成这里的回滚)。
事务的一些其他特性
1.原子性
回滚的方式,保证这一系列操作,都能执行正确,或者恢复如初
2.一致性
事务执行之前和之后数据都不能太离谱
3.持久性
事务做出的修改都是在硬盘上持久保存的,重启服务器,数据仍然存在,事务执行的修改依旧是有效的
4.隔离性
数据库并发执行多个事务的时候,涉及到的问题
数据库并发执行
mysql是一个客户端服务器结构的程序
一个服务器可以为多个客户端提供服务
多个客户端都会让数据库执行事务。
我们希望数据库服务器执行效率高,就希望提高并发程度,但是提高了并发程度后一些问题就会显现出来。
隔离级别就是在“数据正确”和“效率”之间做权衡
往往提升了效率,就会牺牲正确性,提升了正确性就会牺牲效率
问题的展现
1.脏读问题
假设A是一个写数据的事务,B是一个读数据的事务,当A出现的修改数据的情况机会使得B读取的数据有误,这些数据是无效数据(脏数据)。
这俩事务一个接一个串的执行,没事,但并发执行就容易出现脏读。
我们可以加一个约定或者说是锁,A写数据的时候,B不能读,但是这种方法使得并发性降低了,隔离性提高了,效率降低了,数据准确性提高了。
2.不可重复读
还是那个假设,这次A写完了,轮到B来读了,但在B读的过程中,A又觉得可以优化,就进行了修改,这使得B又读到东西又突然变了,这又是无效数据,这次涨记性了,我们又加一个约束,A写了之后就不能改了,加上前面的约束,使得并发性又进一步降低了,隔离性提高了,效率降低了,数据的准确性提高了。
如果两个事务之间的影响越大,隔离性就越低,反之。
3.幻读
还是那个假设,这次A在写,B闲下来了,B想着总得做点啥吧,所以它也开始写了,在最后读的时候把结果集一对发现问题了,这称为幻读。
这些问题因为并发而存在,所以我们要想去避免这些问题最好的办法就是不去并发,即使串行化,这与我们的初衷相违背了,虽然数据是最为准确的,但并发程度最低,隔离性最高,效率最低。
读未提交并发程度最高, 速度最快, 隔离性最低,准确性最低
脏读
读已提交引入了写加锁,只能读写完之后提交的版本并发程度降低了,速度降低了:隔离性提高了,准确性提高了
不可重复读
可重复读引入了写加锁和读加锁. 写的时候不能读,读的时候也不能写并发程度又进一步降低了,速度降低了;隔离性提高了,准确性提高了
幻读
串行化严格的按照 串行 的方式,一个一个的执行事务.并发程度最低(没有并发),速度最低:隔离性最高,准确性最高。
五.数据库编程(java)(JDBC)
数据库编程,需要数据库服务器,提供一些API(Application Programming Interface)应用程序编程接口,提供给一组类/函数进行调用来完成一些功能。
在导入了jar之后我们就可以开始操作了。
1.先创建DataSoure


URL是网络上资源的位置,给jdbc操作mysql用的,我们在这里进行了向下调整,mysqldatabase这个类名不去扩散到其他地方,降低耦合性。
需要注意的是127.0.0.1是一个环回IP,一般是jdbc和mysql在同一个主机上使用环回IP就可以。

在设置了用户名与密码之后我们就要建立于服务器之间的连接
2.建立数据库于服务器之间的连接

我们得提前抛出一个异常才不会爆红

3.构造一个sql


我们构造了sql语句后会进行解析检查,减轻服务器的负担。
4.把sql发送给服务器,返回值是一个整数表示影响到的整数
只针对于增删改,查有另一套
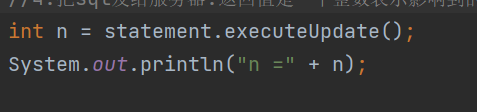
5.释放资源,关闭连接
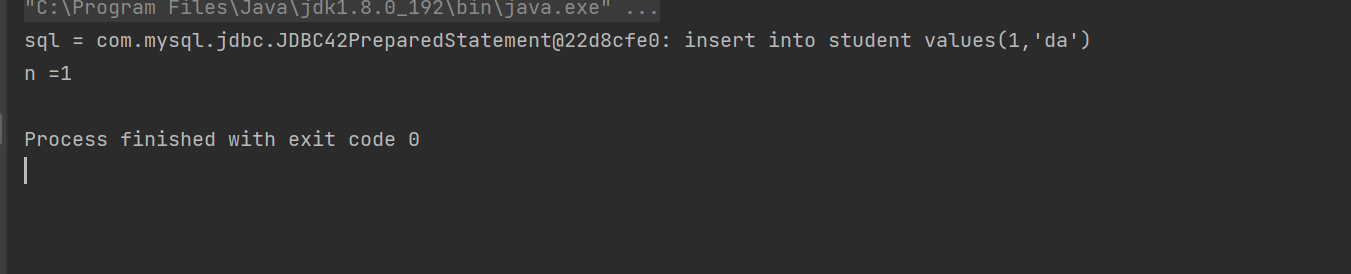
我们用jdbc操作服务器成功了
当然还可以执行其他语句

或者自己输入

 我们来看看查询这方面
我们来看看查询这方面
public static void main(String[] args) throws SQLException {//1.创建DataSoureDataSource dataSource = new MysqlDataSource();((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/java109?characterEncoding=utf8&useSSL=false");((MysqlDataSource) dataSource).setUser("root");((MysqlDataSource) dataSource).setPassword("1793334060qq.");//2.建立连接Connection connection = dataSource.getConnection();//3.构造sqlString sql = "select * from student where id = ?";PreparedStatement statement = connection.prepareStatement(sql);statement.setInt(1,100);//4.执行 sql// ResultSet 表示查询的结果集合ResultSet resultSet = statement.executeQuery();//5.遍历结果集合//通过next方法就可以获得临时表中的每一行数据,如果获取到最后一行之后,再执行next 返回false,循环结束while(resultSet.next()){//针对这一行进行处理//取出列的数据int id = resultSet.getInt("id");String name = resultSet.getString("name");System.out.println("id = " + id + ",name = " + name);}//6.释放资源resultSet.close();statement.close();connection.close();}最大的不同在于ResuSet,resultset光标的指向不是有效数据所以要看next()。
自增id
B+树
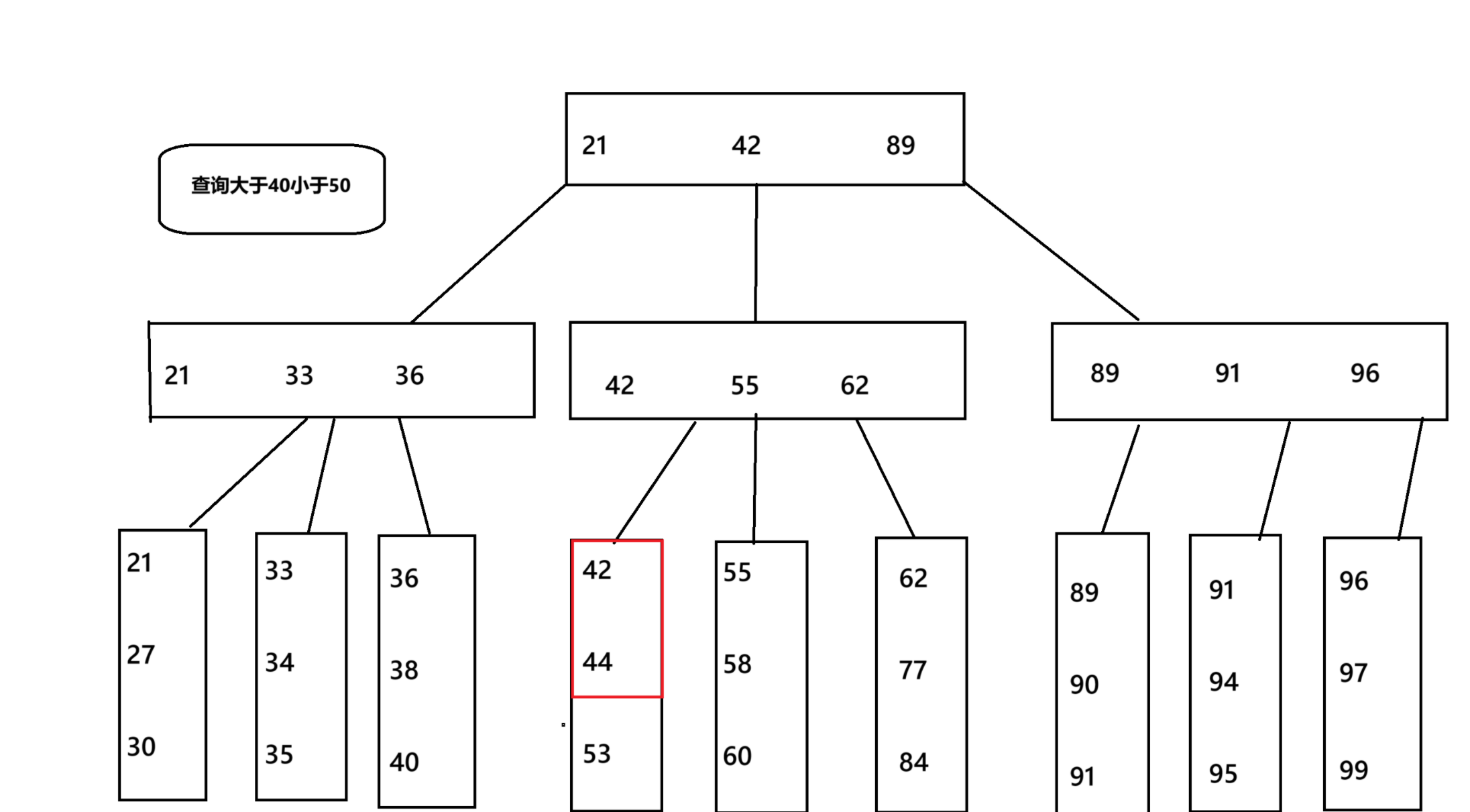
对于B+树来说,我们在查找到大于40小于50的数,我们就会来到42和55这两列,把这两列加载到内存中,然后按照顺序应该是找到了42,44,当我们想插入43,也是一样,我们会找找到我们要插入的位置,但当我们接下来要插入45时,如果说是id自增,则会在当前的列查找并插入,但如果不是自增,跑到了89这一列,我们就要先将原来的缓存置换出去,在缓存中加载89这一列,然后加载到磁盘,没找到位置就又去缓存置换找到42这一列,这一列显然这是浪费时间的。
全表遍历
比如对于1000条数据进行遍历,默认按照id自增遍历的话,我们就可以进行分条遍历,因为id时自增,则只需要考虑边界条件即可,以100个数据为一条进行遍历。
缺点
可预测性,id自增以为这别人可以轻易知道你的数据总数。
可能用尽,id时整形总有用完的一天。
分库分表困难,如果两个库都用自增id,id就重复了。


![[C++] 小游戏 决战苍穹](http://pic.xiahunao.cn/[C++] 小游戏 决战苍穹)










(第2版)学习笔记 02.OpenGL图像管线)



)

