文章目录
- 1. 前言
- 2. 创建 DefaultMessageStore
- 3. DefaultMessageStore#load
- 3.1 CommitLog#load
- 3.2 loadConsumeQueue 加载 ConsumeQueue 文件
- 3.3 创建 StoreCheckpoint
- 3.4 indexService.load 加载 IndexFile 文件
- 3.5 recover 文件恢复
- 3.6 延时消息服务加载
- 4. registerProcessor 注册 code 处理器
- 5. ConfigManager.persist
- 6. protectBroker 保护 broker
- 7. fetchNameServerAddr 定时任务定时拉取 NameServer 地址
- 8. 小结
本文章基于 RocketMQ 4.9.3
1. 前言
- 【RocketMQ】- 源码系列目录
- 【RocketMQ Broker 相关源码】- broker 启动源码(1)
在前面【RocketMQ Broker 相关源码】- broker 启动源码(1)这篇文章中,我们对 broker 启动的源码进行了简要梳理,着重介绍了 broker 启动过程中所涉及的各项服务,以及启动流程中具体执行的操作。至于这些服务的具体功能,以及其背后源码的详细实现,还有上一篇文章中遗留下来的一些方法和比较重要的类,我们在这篇文章中去介绍。
2. 创建 DefaultMessageStore
DefaultMessageStore 是 RocketMQ 中默认的消息存储核心类,broker 对消息的操作都需要经过这个类,比如消息查询、消息添加、消息拉取 … 所以在调用 BrokerController#initialize 的时候第二步就是创建 DefaultMessageStore,那么我们就来看下这个类的构造方法。
public DefaultMessageStore(final MessageStoreConfig messageStoreConfig, final BrokerStatsManager brokerStatsManager,final MessageArrivingListener messageArrivingListener, final BrokerConfig brokerConfig) throws IOException {// 消息到达监听器, 消息重放之后会通知 pullRequestHoldService 服务消息到达, 接着就可以处理消费者的消息拉取请求this.messageArrivingListener = messageArrivingListener;// broker 配置this.brokerConfig = brokerConfig;// 消息存储配置this.messageStoreConfig = messageStoreConfig;// broker 数据统计管理类this.brokerStatsManager = brokerStatsManager;// MappedFile 分配服务this.allocateMappedFileService = new AllocateMappedFileService(this);// 实例化 CommitLog, 默认是不支持 Dleger 高可用模式的if (messageStoreConfig.isEnableDLegerCommitLog()) {this.commitLog = new DLedgerCommitLog(this);} else {this.commitLog = new CommitLog(this);}// 创建 ConsumeQueue 集合, 存储了 topic -> (queueId, ConsumeQueue) 的关系this.consumeQueueTable = new ConcurrentHashMap<>(32);// 初始化 ConsumeQueue 刷盘服务this.flushConsumeQueueService = new FlushConsumeQueueService();// 初始化过期 CommitLog 文件清除服务this.cleanCommitLogService = new CleanCommitLogService();// 初始化过期 ConsumeQueue 文件清除服务this.cleanConsumeQueueService = new CleanConsumeQueueService();// 初始化消息存储统计服务this.storeStatsService = new StoreStatsService();// 初始化 Index 索引服务this.indexService = new IndexService(this);// 判断是否初始化 HAService 主从同步服务if (!messageStoreConfig.isEnableDLegerCommitLog()) {this.haService = new HAService(this);} else {this.haService = null;}// 初始化消息重放服务this.reputMessageService = new ReputMessageService();// 初始化延时消息服务this.scheduleMessageService = new ScheduleMessageService(this);// 初始化堆外缓存this.transientStorePool = new TransientStorePool(messageStoreConfig);// 初始化堆外缓存的 ByteBuffer, 默认大小是 5if (messageStoreConfig.isTransientStorePoolEnable()) {this.transientStorePool.init();}// 启动 MappedFile 分配线程this.allocateMappedFileService.start();// 启动 Index 文件服务线程this.indexService.start();// 创建消息重放列表, 用于构建 ConsumeQueue、Index 索引, 默认顺序是 ConsumeQueue -> Indexthis.dispatcherList = new LinkedList<>();this.dispatcherList.addLast(new CommitLogDispatcherBuildConsumeQueue());this.dispatcherList.addLast(new CommitLogDispatcherBuildIndex());// 创建 DefaultMessageStore 的根目录文件File file = new File(StorePathConfigHelper.getLockFile(messageStoreConfig.getStorePathRootDir()));// 确保根文件父目录, 也就是 ${user.home}/store(又或者 broker.conf 里面设置的 storePathRootDir) 被创建MappedFile.ensureDirOK(file.getParent());// 确保 CommitLog 文件父目录, 也就是 ${user.home}/store/commitlog(又或者 broker.conf 里面设置的 storePathCommitLog) 被创建MappedFile.ensureDirOK(getStorePathPhysic());// 确保 ConsumeQueue 文件父目录, 也就是 ${user.home}/store/consumequeue(又或者 broker.conf 里面设置的 storePathConsumeQueue) 被创建MappedFile.ensureDirOK(getStorePathLogic());// 设置文件权限是可读写, 在 DefaultMessageStore 启动的时候会加锁, 确保只有一个 broker 对这个根目录下的文件操作lockFile = new RandomAccessFile(file, "rw");
}
可以看到在这个构造器里面就是初始化了一堆服务,按照顺序一个一个往下说:
messageArrivingListener:消息到达监听器, 消息重放之后会通知 pullRequestHoldService 服务消息到达, 接着就可以处理消费者的消息拉取请求,这个监听器是跟消费者消息拉取有关的,后面讲到消费者拉取消息的时候会重点说下。brokerConfig:broker 配置。messageStoreConfig:消息存储配置,里面记录了消息存储服务的一些参数。brokerStatsManager:broker 数据统计管理类,比如 broker 里面添加了多少次消息,添加的消息的总大小 …allocateMappedFileService:MappedFile 分配服务,用来创建 MappedFile 的,这个服务在文章 【RocketMQ 存储】- RocketMQ 如何高效创建 MappedFile 有详细介绍。CommitLog:就是存储消息的 CommitLog,一个 broker 中有一个 CommitLog,但是 CommitLog 中包含了多个 MappedFile。consumeQueueTable:存储了 topic -> <queueId, ConsumeQueue> 的关系,一个 topic 下面有多个队列,而这些队列可以分配到不同的 broker,所以这个集合保存了当前这个 broker 下面存储的 topic -> (id, queue) 的映射,也就是说通过 topic 可以找到所有的 ConsumeQueue。flushConsumeQueueService:ConsumeQueue 刷盘服务,这个服务在文章 【RocketMQ 存储】ConsumeQueue 刷盘服务 FlushConsumeQueueService 有详细介绍。cleanCommitLogService:CommitLog 文件清除服务,清除 CommitLog 的过期文件,这个服务在文章 【RocketMQ 存储】- CommitLog 过期清除服务 CleanCommitLogService 有详细介绍。cleanConsumeQueueService:ConsumeQueue 文件清除服务,清除 ConsumeQueue 的过期文件,这个服务在文章 【RocketMQ 存储】- ConsumeQueue 过期清除服务 CleanConsumeQueueService 中有详细介绍。storeStatsService:消息存储统计服务。indexService:消息存储统计服务。storeStatsService:Index 索引服务,用于管理 Index 索引,构建、删除 … 逻辑都是在里面进行。haService:主从同步服务,在【RocketMQ 高可用】这几篇文章中有详细介绍这个类。reputMessageService:消息重放服务,用于构建 ConsumeQueue 索引、Index 索引、SQL92 的 bitMap 过滤处理,在 【RocketMQ 存储】消息重放服务-ReputMessageService
中有详细介绍。scheduleMessageService:延时消息服务,处理延时消息的。transientStorePool:堆外缓存,实现读写分离,虽然通过 MappedByteBuffer 的 mmap 进行文件映射到了 page cache,同时通过 mlock 锁定了这篇内存进行 swap 交换。但是当 page cache 脏页数据越来越多的时候,内核的 pdflush 线程就会将 page cache 中的脏页回写到磁盘中,这里是我们不能控制的。所以当脏页写入磁盘之后,我们通过 MappedByteBuffer 写入数据还是会触发缺页中断,这样就会导致写入数据延迟,性能产生毛刺现象。为了解决这个问题,RocketMQ 引入了堆外缓存提供读写分离,当数据要写入的时候,先写入 writeBuffer,这段 writeBuffer 只是普通堆外缓存,不涉及脏页回写,所以写入的时候不会阻塞,而后台线程就会不断将这部分数据 commit 到 page cache 中。lockFile:${user.home}/store/lock(storePathRootDir),当 DefaultMessageStore 启动的时候会往里面写入 lock,这是为了确保只有一个 broker 对这个根目录下的文件操作,根目录默认是 ${user.home}/store,但是也可以在 broker.conf 中设置 storePathRootDir 为根目录。
3. DefaultMessageStore#load
在 BrokerController#initialize 方法中,通过 DefaultMessageStore#load 去加载各个目录下面的文件到内存中,如 CommitLog、ConsumeQueue、StoreCheckPoint 等文件,下面就来看下这个方法的源码。
/*** 加载 MessageStore 下面的消息存储文件* @throws IOException*/
public boolean load() {boolean result = true;try {// 判断下上次 RocketMQ 关闭是不是正常关闭boolean lastExitOK = !this.isTempFileExist();log.info("last shutdown {}", lastExitOK ? "normally" : "abnormally");// 1.加载 CommitLog 文件result = result && this.commitLog.load();// 2.加载 ConsumeQueue 文件result = result && this.loadConsumeQueue();if (result) {// 3.加载 checkpoint 检查点文件,文件位置是 ${home}/store/checkpointthis.storeCheckpoint =new StoreCheckpoint(StorePathConfigHelper.getStoreCheckpoint(this.messageStoreConfig.getStorePathRootDir()));// 4.加载 IndexFile 文件this.indexService.load(lastExitOK);// 5.恢复 ConsumeQueue 和 CommitLog 文件,也就是将这些数据恢复到内存中this.recover(lastExitOK);log.info("load over, and the max phy offset = {}", this.getMaxPhyOffset());if (null != scheduleMessageService) {// 6.加载延时消息服务result = this.scheduleMessageService.load();}}} catch (Exception e) {log.error("load exception", e);result = false;}if (!result) {// 如果上面的操作有异常,这里就停止创建 MappedFile 的服务this.allocateMappedFileService.shutdown();}return result;
}
3.1 CommitLog#load
这个方法就是用于加载 CommitLog 文件,其实就是加载 Commit 存储文件夹下面的文件到内存中,下面是源码。
/*** 加载 CommitLog 文件* @return*/
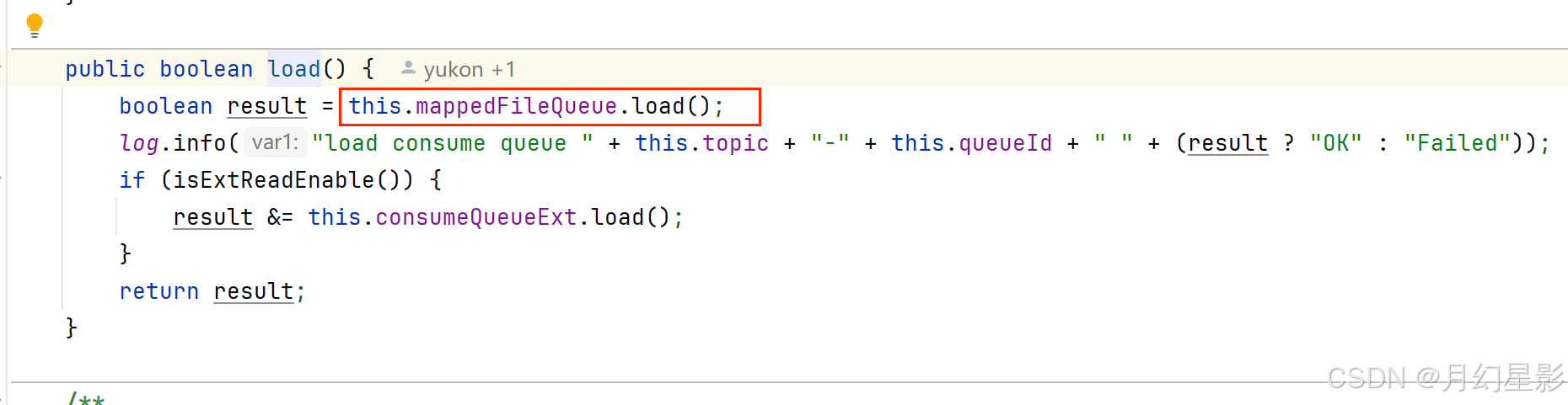
public boolean load() {// 加载 CommitLog 文件boolean result = this.mappedFileQueue.load();log.info("load commit log " + (result ? "OK" : "Failed"));return result;
}/*** 加载文件* @return*/
public boolean load() {// 文件存放目录// ${home}/store/commitlogFile dir = new File(this.storePath);// 获取内部的文件集合File[] ls = dir.listFiles();if (ls != null) {// 如果文件夹下存在文件,那么进行加载return doLoad(Arrays.asList(ls));}return true;
}
因为 CommitLog 一个文件大小是 1GB,所以这个文件夹下面可能有多个文件,需要用到 doLoad 方法,传入一个集合。
/*** 加载文件* @param files* @return*/
public boolean doLoad(List<File> files) {// 将文件按照文件名排序,这里的文件名就是文件的起始偏移量files.sort(Comparator.comparing(File::getName));// 遍历所有文件for (File file : files) {if (file.length() != this.mappedFileSize) {// 到这里就是文件实际大小如果不等于设定的文件大小,就直接返回,不加载其他文件,这里 length 就是创建文件的时候设定的文件大小log.warn(file + "\t" + file.length()+ " length not matched message store config value, please check it manually");return false;}try {// 每一个 CommitLog 或者 ConsumeQueue 文件都需要创建一个MappedFile mappedFile = new MappedFile(file.getPath(), mappedFileSize);// 将下面三个指针位置设置成文件大小// MappedByteBuffer 或者 writeBuffer 中 position 的位置mappedFile.setWrotePosition(this.mappedFileSize);// MappedByteBuffer 或者 writeBuffer 中 flush 刷盘的位置mappedFile.setFlushedPosition(this.mappedFileSize);// writeBuffer 中 commit 提交数据到 page cache 中的位置mappedFile.setCommittedPosition(this.mappedFileSize);// 将 MappedByteBuffer 添加到集合 mappedFiles 中this.mappedFiles.add(mappedFile);log.info("load " + file.getPath() + " OK");} catch (IOException e) {log.error("load file " + file + " error", e);return false;}}return true;
}
可以看到就是在加载文件的时候,会把三个指针 wrotePosition、flushedPosition、committedPosition 设置成 mappedFileSize,这个 mappedFileSize 在 CommitLog 文件下就是 1GB,因为默认从磁盘读取出来的数据肯定就已经是刷盘成功的了,所以这里直接设置为 mappedFileSize,但是有一个问题就是如果你的 RocketMQ 是突然崩溃了,就比如我这里直接 windows 启动,在这之前我只往 CommitLog 里面写入了几条消息,但是这里的设置会导致这三个指针的值都是 1G,就跟实际不符合。

但是这里设置了 1G 之后,在 DefaultMessageStore#load 的第 5 步 this.recover(lastExitOK) 会恢复 ConsumeQueue 和 CommitLog 文件,也就是将这些数据恢复到内存中,同时纠正偏移量,所以是没问题的。
3.2 loadConsumeQueue 加载 ConsumeQueue 文件
上面加载完 CommitLog 之后,这里就要加载 ConsumeQueue 文件了。
/*** 加载 ConsumeQueue 文件* @return*/
private boolean loadConsumeQueue() {// 文件路径是 ${user.home}/store/consumequeue, 当然这个 ${user.home}/store 也可以在 broker.conf 里面通过 storePathRootDir 配置根目录File dirLogic = new File(StorePathConfigHelper.getStorePathConsumeQueue(this.messageStoreConfig.getStorePathRootDir()));// 获取这个目录下面的所有文件File[] fileTopicList = dirLogic.listFiles();if (fileTopicList != null) {// 遍历文件for (File fileTopic : fileTopicList) {// 获取文件名, ConsumeQueue 文件和 CommitLog 不一样, CommitLog 是所有 topic 都存到一起, ConsumeQueue 是 topic 分// 开存储, 文件名就是 topicString topic = fileTopic.getName();// 获取 ${storePathRootDir}/consumequeue/${topic} 下面的文件列表File[] fileQueueIdList = fileTopic.listFiles();if (fileQueueIdList != null) {// 遍历, 因为 ConsumeQueue 默认就是 4 个队列, 所以需要遍历这些队列for (File fileQueueId : fileQueueIdList) {int queueId;try {// 队列 IDqueueId = Integer.parseInt(fileQueueId.getName());} catch (NumberFormatException e) {continue;}// 创建 ConsumeQueue, 这里传了 topic 和 queueId 进去构造器, 因为文件路径就是 ${storePathRootDir}/consumequeue/${topic}/${queueId}ConsumeQueue logic = new ConsumeQueue(topic,queueId,StorePathConfigHelper.getStorePathConsumeQueue(this.messageStoreConfig.getStorePathRootDir()),this.getMessageStoreConfig().getMappedFileSizeConsumeQueue(),this);// 将创建出来的 ConsumeQueue 添加到 consumeQueueTable 中this.putConsumeQueue(topic, queueId, logic);// ConsumeQueue#load 方法if (!logic.load()) {return false;}}}}}log.info("load logics queue all over, OK");return true;
}
这里的文件加载和前面 CommitLog 的差不多,只是获取文件名的时候 ConsumeQueue 文件和 CommitLog 不一样,CommitLog 是所有 topic 都存到一起,ConsumeQueue 是 topic 分开存储,所以 ConsumeQueue 的文件路径就是 ${storePathRootDir}/consumequeue/${topic}/${queueId},最后创建出 ConsumeQueue 之后需要添加到 consumeQueueTable 中,添加的逻辑如下。
/*** 添加 ConsumeQueue 映射关系* @param topic* @param queueId* @param consumeQueue*/
private void putConsumeQueue(final String topic, final int queueId, final ConsumeQueue consumeQueue) {// 获取 topic 下面的 ConsumeQueue 集合ConcurrentMap<Integer/* queueId */, ConsumeQueue> map = this.consumeQueueTable.get(topic);if (null == map) {// 初始化map = new ConcurrentHashMap<Integer/* queueId */, ConsumeQueue>();// 添加map.put(queueId, consumeQueue);this.consumeQueueTable.put(topic, map);if (MixAll.isLmq(topic)) {this.lmqConsumeQueueNum.getAndIncrement();}} else {// 直接添加, 会覆盖map.put(queueId, consumeQueue);}
}
添加完之后调用 ConsumeQueue 的 load 方法去加载 ConsumeQueue 文件,但是其实加载的逻辑跟 CommitLog 是一样的,只是加载的文件不同,因为都是走的 mappedFileQueue.load() 的逻辑,这个逻辑上面 3.1 小结也说过了,这里不再赘述。
3.3 创建 StoreCheckpoint
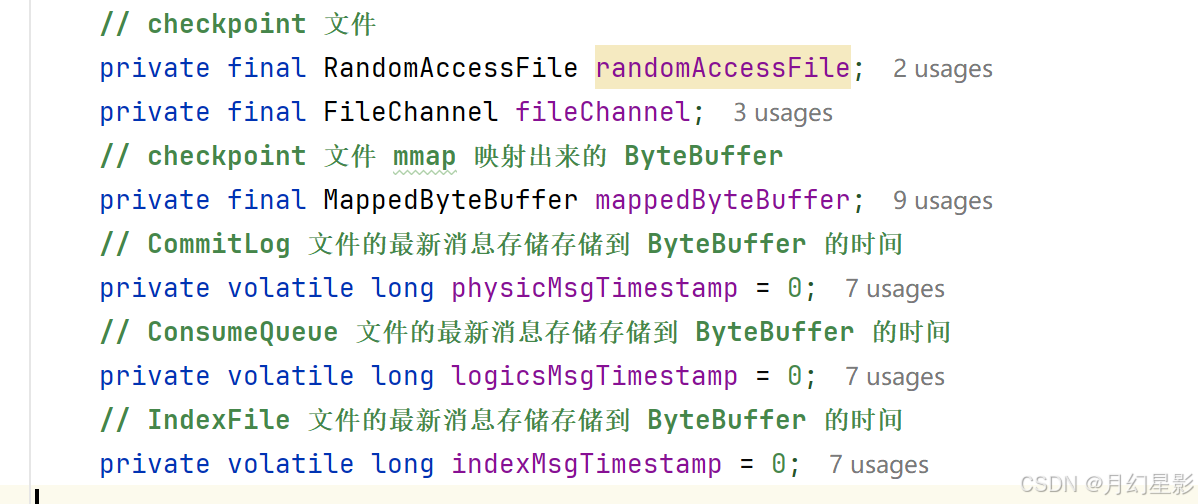
加载 checkpoint 检查点文件,文件位置是 ${storePathRootDir}/checkpoint,这个 checkpoint 就是检查点文件,CommitLog、ConsumeQueue、IndexFile 这三个文件的最新消息的存储时间点会被记录,如果 broker 异常重启了,这时候就会根据这三个时间点来恢复文件。
当然这里就是来看一下创建的构造器逻辑,关于这三个值的使用在 recover 方法有用到,之前的文件也讲过,所以如果有需要可以去看下之前的文章,就是正常异常退出恢复那两篇。
public StoreCheckpoint(final String scpPath) throws IOException {// 判断是否存在当前文件// D:\\javaCode\\rocketmq-source\\config\\store\\checkpointFile file = new File(scpPath);MappedFile.ensureDirOK(file.getParent());// 文件是否存在boolean fileExists = file.exists();// mmap 映射this.randomAccessFile = new RandomAccessFile(file, "rw");this.fileChannel = this.randomAccessFile.getChannel();this.mappedByteBuffer = fileChannel.map(MapMode.READ_WRITE, 0, MappedFile.OS_PAGE_SIZE);if (fileExists) {log.info("store checkpoint file exists, " + scpPath);// 记录最新 CommitLog 文件的最新添加到 ByteBuffer 的时间戳this.physicMsgTimestamp = this.mappedByteBuffer.getLong(0);// 最新 ConsumeQueue 文件的最新添加到 ByteBuffer 的时间戳this.logicsMsgTimestamp = this.mappedByteBuffer.getLong(8);// 最新 IndexFile 文件的最新添加到 ByteBuffer 的时间戳this.indexMsgTimestamp = this.mappedByteBuffer.getLong(16);log.info("store checkpoint file physicMsgTimestamp " + this.physicMsgTimestamp + ", "+ UtilAll.timeMillisToHumanString(this.physicMsgTimestamp));log.info("store checkpoint file logicsMsgTimestamp " + this.logicsMsgTimestamp + ", "+ UtilAll.timeMillisToHumanString(this.logicsMsgTimestamp));log.info("store checkpoint file indexMsgTimestamp " + this.indexMsgTimestamp + ", "+ UtilAll.timeMillisToHumanString(this.indexMsgTimestamp));} else {// 文件不存在log.info("store checkpoint file not exists, " + scpPath);}
}
3.4 indexService.load 加载 IndexFile 文件
/*** 加载 IndexFile 文件, 路径是 ${storePathRootDir}/index* @param lastExitOK 上一次 RocketMQ 是否正常退出* @return*/
public boolean load(final boolean lastExitOK) {// 首先获取这个文件夹路径下面的所有文件File dir = new File(this.storePath);File[] files = dir.listFiles();if (files != null) {// 文件目录名称排序Arrays.sort(files);for (File file : files) {try {// 构建 IndexFileIndexFile f = new IndexFile(file.getPath(), this.hashSlotNum, this.indexNum, 0, 0);// 加载 IndexFilef.load();// 如果上一次不是正常退出if (!lastExitOK) {// 如果说 IndexFile 最后一条消息的 storeTimeStamp 比 StoreCheckPoint 中记录的要大if (f.getEndTimestamp() > this.defaultMessageStore.getStoreCheckpoint().getIndexMsgTimestamp()) {// 说明这个 IndexFile 有一部分数据是脏数据, 删掉这个文件f.destroy(0);continue;}}log.info("load index file OK, " + f.getFileName());// 加到 indexFileList 里面this.indexFileList.add(f);} catch (IOException e) {log.error("load file {} error", file, e);return false;} catch (NumberFormatException e) {log.error("load file {} error", file, e);}}}return true;
}
这个方法就用到了我们提到的 StoreCheckPoint 文件里面的数据,如果 IndexFile 记录的最新的索引的消息在 CommitLog 的存储时间比 StoreCheckPoint 文件里面记录的 indexMsgTimestamp 要大,说明这个 IndexFile 文件就是一个不合法的文件,至少是数据不合法的,因为 indexMsgTimestamp 这个变量就是在 IndexFile 满了刷盘的时候才会记录,比如将一个写满了的 IndexFile 文件刷盘就记录一下这个 indexMsgTimestamp 变量。
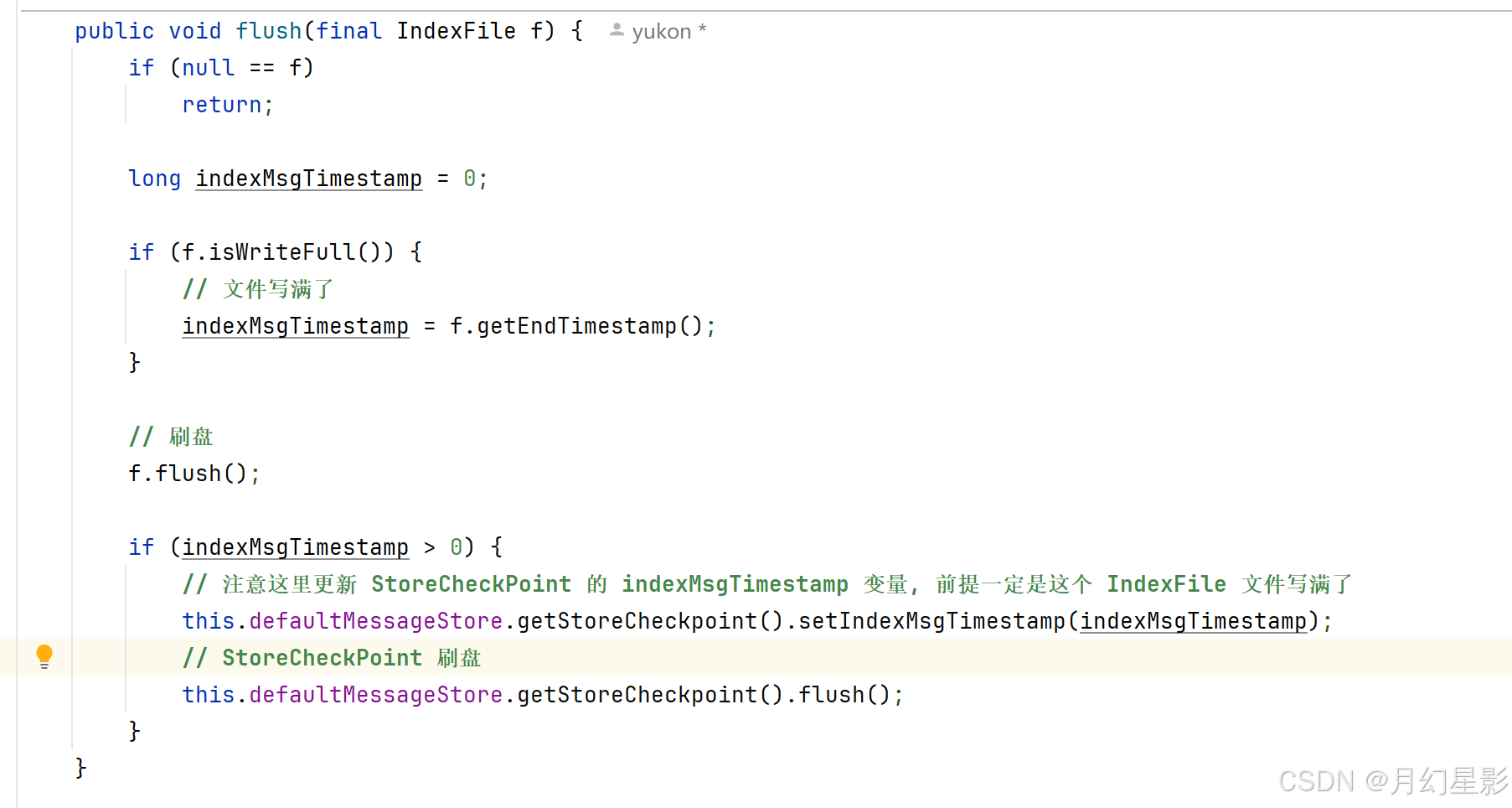
所以看上面图也能看出来,刷盘的时候必须要文件写满了才会去更新 indexMsgTimestamp,这就意味者这个变量就是记录完整的 IndexFile 刷盘的时间,而不是刷盘一次就记录一次,因此如果说 IndexFile 最后一条消息的 storeTimeStamp 比 StoreCheckPoint 中记录的要大,就说明这个 IndexFile 肯定是有问题的。
至于为什么可以这么记录,因为 IndexFile 不像 CommitLog 和 ConsumeQueue 那样,一个 IndexFile 就是一个 MappedFile 来存储所有数据,像 CommitLog 和 ConsumeQueue 都是用 MappedFileQueue 存储 MappedFile 集合的,所以这里还是有点不同的。
3.5 recover 文件恢复
这里的文件恢复代码如下:
/*** 恢复 CommitLog 和 ConsumeQueue 中的数据到内存中* @param lastExitOK*/
private void recover(final boolean lastExitOK) {// 恢复所有 ConsumeQueue 文件,返回的是 ConsumeQueue 中存储的最大有效 CommitLog 偏移量long maxPhyOffsetOfConsumeQueue = this.recoverConsumeQueue();// 上一次 Broker 退出是正常退出还是异常退出if (lastExitOK) {// 这里就是正常退出,所以正常恢复 CommitLogthis.commitLog.recoverNormally(maxPhyOffsetOfConsumeQueue);} else {// 这里就是异常退出,所以异常恢复 CommitLogthis.commitLog.recoverAbnormally(maxPhyOffsetOfConsumeQueue);}// 最后恢复 topicQueueTablethis.recoverTopicQueueTable();
}
正常异常恢复的逻辑在前面讲 RocketMQ 存储部分的时候已经讲过了,所以这里就不再多说。
- 【RocketMQ 存储】- 异常退出恢复逻辑 recoverAbnormally
- 【RocketMQ 存储】- 正常退出恢复逻辑 recoverNormally
3.6 延时消息服务加载
延时消息属于消息消费的一种,这里后面讲到消费者的时候也会详细讲解,这里先不多说。
4. registerProcessor 注册 code 处理器
/*** 注册 Code 处理器*/
public void registerProcessor() {/*** SendMessageProcessor*/SendMessageProcessor sendProcessor = new SendMessageProcessor(this);sendProcessor.registerSendMessageHook(sendMessageHookList);sendProcessor.registerConsumeMessageHook(consumeMessageHookList);// 消息发送的处理器this.remotingServer.registerProcessor(RequestCode.SEND_MESSAGE, sendProcessor, this.sendMessageExecutor);this.remotingServer.registerProcessor(RequestCode.SEND_MESSAGE_V2, sendProcessor, this.sendMessageExecutor);this.remotingServer.registerProcessor(RequestCode.SEND_BATCH_MESSAGE, sendProcessor, this.sendMessageExecutor);this.remotingServer.registerProcessor(RequestCode.CONSUMER_SEND_MSG_BACK, sendProcessor, this.sendMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.SEND_MESSAGE, sendProcessor, this.sendMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.SEND_MESSAGE_V2, sendProcessor, this.sendMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.SEND_BATCH_MESSAGE, sendProcessor, this.sendMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.CONSUMER_SEND_MSG_BACK, sendProcessor, this.sendMessageExecutor);/*** PullMessageProcessor, 专门用于处理 PULL_MESSAGE 这个请求 CODE, 也就是消息拉取请求*/this.remotingServer.registerProcessor(RequestCode.PULL_MESSAGE, this.pullMessageProcessor, this.pullMessageExecutor);this.pullMessageProcessor.registerConsumeMessageHook(consumeMessageHookList);/*** ReplyMessageProcessor*/ReplyMessageProcessor replyMessageProcessor = new ReplyMessageProcessor(this);replyMessageProcessor.registerSendMessageHook(sendMessageHookList);this.remotingServer.registerProcessor(RequestCode.SEND_REPLY_MESSAGE, replyMessageProcessor, replyMessageExecutor);this.remotingServer.registerProcessor(RequestCode.SEND_REPLY_MESSAGE_V2, replyMessageProcessor, replyMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.SEND_REPLY_MESSAGE, replyMessageProcessor, replyMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.SEND_REPLY_MESSAGE_V2, replyMessageProcessor, replyMessageExecutor);/*** QueryMessageProcessor*/NettyRequestProcessor queryProcessor = new QueryMessageProcessor(this);this.remotingServer.registerProcessor(RequestCode.QUERY_MESSAGE, queryProcessor, this.queryMessageExecutor);this.remotingServer.registerProcessor(RequestCode.VIEW_MESSAGE_BY_ID, queryProcessor, this.queryMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.QUERY_MESSAGE, queryProcessor, this.queryMessageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.VIEW_MESSAGE_BY_ID, queryProcessor, this.queryMessageExecutor);/*** ClientManageProcessor*/ClientManageProcessor clientProcessor = new ClientManageProcessor(this);this.remotingServer.registerProcessor(RequestCode.HEART_BEAT, clientProcessor, this.heartbeatExecutor);this.remotingServer.registerProcessor(RequestCode.UNREGISTER_CLIENT, clientProcessor, this.clientManageExecutor);this.remotingServer.registerProcessor(RequestCode.CHECK_CLIENT_CONFIG, clientProcessor, this.clientManageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.HEART_BEAT, clientProcessor, this.heartbeatExecutor);this.fastRemotingServer.registerProcessor(RequestCode.UNREGISTER_CLIENT, clientProcessor, this.clientManageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.CHECK_CLIENT_CONFIG, clientProcessor, this.clientManageExecutor);/*** ConsumerManageProcessor*/ConsumerManageProcessor consumerManageProcessor = new ConsumerManageProcessor(this);this.remotingServer.registerProcessor(RequestCode.GET_CONSUMER_LIST_BY_GROUP, consumerManageProcessor, this.consumerManageExecutor);this.remotingServer.registerProcessor(RequestCode.UPDATE_CONSUMER_OFFSET, consumerManageProcessor, this.consumerManageExecutor);this.remotingServer.registerProcessor(RequestCode.QUERY_CONSUMER_OFFSET, consumerManageProcessor, this.consumerManageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.GET_CONSUMER_LIST_BY_GROUP, consumerManageProcessor, this.consumerManageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.UPDATE_CONSUMER_OFFSET, consumerManageProcessor, this.consumerManageExecutor);this.fastRemotingServer.registerProcessor(RequestCode.QUERY_CONSUMER_OFFSET, consumerManageProcessor, this.consumerManageExecutor);/*** EndTransactionProcessor*/this.remotingServer.registerProcessor(RequestCode.END_TRANSACTION, new EndTransactionProcessor(this), this.endTransactionExecutor);this.fastRemotingServer.registerProcessor(RequestCode.END_TRANSACTION, new EndTransactionProcessor(this), this.endTransactionExecutor);/*** Default*/AdminBrokerProcessor adminProcessor = new AdminBrokerProcessor(this);this.remotingServer.registerDefaultProcessor(adminProcessor, this.adminBrokerExecutor);this.fastRemotingServer.registerDefaultProcessor(adminProcessor, this.adminBrokerExecutor);
}
这里就是注册处理器的逻辑,上一篇文章我们说过,RocketMQ 发送请求的时候会在请求头设置 code 表示这个请求是什么类型的请求,这个请求需要使用什么处理器来处理就是在这里注册的,同时 broker 处理请求的时候不可能是单线程处理的,肯定是封装成一个 runnable 线程任务去处理,所以需要传入一个线程池来并发执行。
5. ConfigManager.persist
在 BrokerController#initialize 中启动了多个定时任务来定时持久化,下面来看下这个持久化的源码。
/*** 持久化到文件中, 持久化 json 和 json.bak 文件*/
public synchronized void persist() {// 需要持久化的数据String jsonString = this.encode(true);if (jsonString != null) {// 需要持久化的文件路径String fileName = this.configFilePath();try {// 持久化逻辑MixAll.string2File(jsonString, fileName);} catch (IOException e) {log.error("persist file " + fileName + " exception", e);}}
}
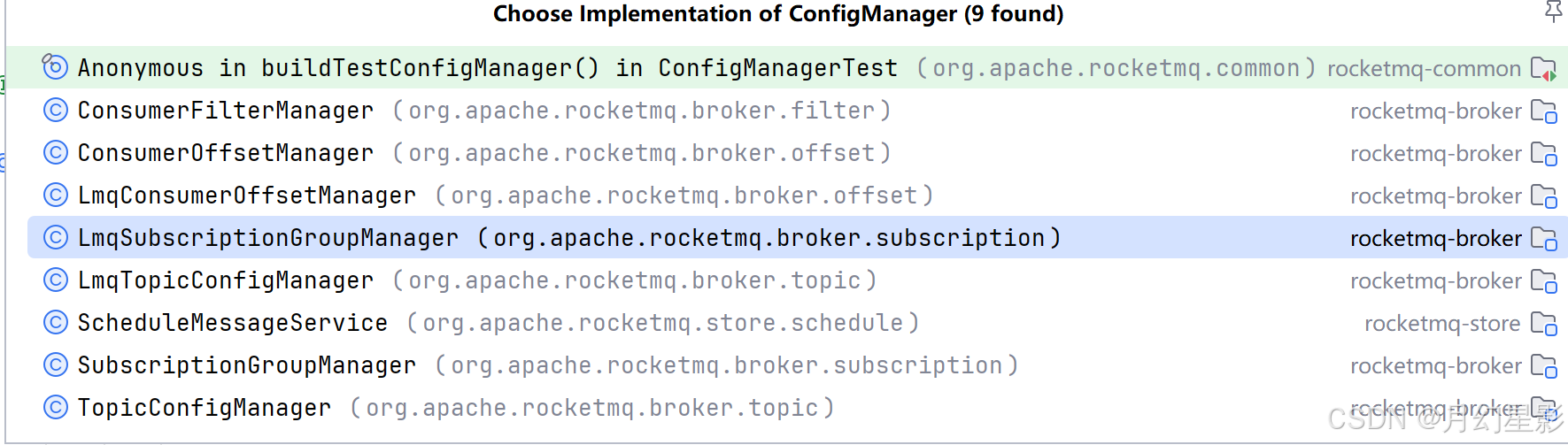
这里面就是用了模板方法的设计模式,ConfigManager 是一个抽象类,需要持久化的数据 encode、需要持久化的文件路径 configFilePath 都是子类实现的,下面是 ConfigManager 的子类。
6. protectBroker 保护 broker
RocketMQ 作为消息队列,肯定会存在消息堆积的情况,如果是堆积量比较少那还行,可以新启动多几个消费者来加速消费,但是如果堆积量比较大,这就不得不怀疑是不是消费者出什么问题了,比如代码出 bug 导致消费进度一致不变。
我们知道消费者消费之前都会先去 broker 拉取消息到本地,然后再在本地消费,所以如果消费者拉取消息的进度一直不变,而生产者又在不断新增消息,就会导致消息堆积量越来越多。
这个 protectBroker 方法就是去检测如果这个消费者组的消息拉取进度落后最新消息超过 16G, 说明有可能这个消费者组里面的消费者出问题了, 不能正常消费消息, 所以这时候就会将消费者组的订阅配置设置为禁止消费, 需要人为介入去修复。
public void protectBroker() {// 如果禁止消费者缓慢读取if (this.brokerConfig.isDisableConsumeIfConsumerReadSlowly()) {final Iterator<Map.Entry<String, MomentStatsItem>> it = this.brokerStatsManager.getMomentStatsItemSetFallSize().getStatsItemTable().entrySet().iterator();while (it.hasNext()) {final Map.Entry<String, MomentStatsItem> next = it.next();// fallBehindBytes 记录的是消费者组剩余可以拉取的消息大小final long fallBehindBytes = next.getValue().getValue().get();// 如果超过了 16Gif (fallBehindBytes > this.brokerConfig.getConsumerFallbehindThreshold()) {final String[] split = next.getValue().getStatsKey().split("@");final String group = split[2];LOG_PROTECTION.info("[PROTECT_BROKER] the consumer[{}] consume slowly, {} bytes, disable it", group, fallBehindBytes);// 设置这个消费者组的 consumeEnable 为 false, 禁止这个消费者组里面的消费者对这个 topic 消费this.subscriptionGroupManager.disableConsume(group);}}}}
7. fetchNameServerAddr 定时任务定时拉取 NameServer 地址
broker 启动的时候在 start 方法会启动一个定时任务去定期拉取 NameServer 地址,当然这里的定期拉取 NameServer 地址的前提是用户没有在 broker.conf 文件中设置 namesrvAddr 配置。
public String fetchNameServerAddr() {try {// 从地址服务器拉取 nameserver 的地址String addrs = this.topAddressing.fetchNSAddr();if (addrs != null) {if (!addrs.equals(this.nameSrvAddr)) {log.info("name server address changed, old: {} new: {}", this.nameSrvAddr, addrs);this.updateNameServerAddressList(addrs);// 更新 nameSrvAddr 属性this.nameSrvAddr = addrs;return nameSrvAddr;}}} catch (Exception e) {log.error("fetchNameServerAddr Exception", e);}return nameSrvAddr;
}
核心源码是下面的 fetchNSAddr,来看下代码。
/*** 拉取 nameserver 的地址* @return*/
public final String fetchNSAddr() {return fetchNSAddr(true, 3000);
}/*** 拉取 nameserver 的地址* @param verbose* @param timeoutMills* @return*/
public final String fetchNSAddr(boolean verbose, long timeoutMills) {String url = this.wsAddr;try {// 向 wsAddr 地址发送查询 NameServer 的请求if (!UtilAll.isBlank(this.unitName)) {url = url + "-" + this.unitName + "?nofix=1";}HttpTinyClient.HttpResult result = HttpTinyClient.httpGet(url, null, null, "UTF-8", timeoutMills);if (200 == result.code) {String responseStr = result.content;if (responseStr != null) {// 处理返回结果return clearNewLine(responseStr);} else {log.error("fetch nameserver address is null");}} else {log.error("fetch nameserver address failed. statusCode=" + result.code);}} catch (IOException e) {if (verbose) {log.error("fetch name server address exception", e);}}if (verbose) {String errorMsg ="connect to " + url + " failed, maybe the domain name " + MixAll.getWSAddr() + " not bind in /etc/hosts";errorMsg += FAQUrl.suggestTodo(FAQUrl.NAME_SERVER_ADDR_NOT_EXIST_URL);log.warn(errorMsg);}return null;
}private static String clearNewLine(final String str) {// 去除前后的空格String newString = str.trim();int index = newString.indexOf("\r");if (index != -1) {// 截取 \r 前面的字符串return newString.substring(0, index);}index = newString.indexOf("\n");if (index != -1) {// 截取 \n 前面的字符串return newString.substring(0, index);}// 没有 \r 和 \n 字符, 直接返回原来的字符串return newString;
}
拉取的逻辑就是往 url 发送 get 请求来获取地址,所以这里的核心就是如何找到这个 url,也就是代码中的 wsAddr。由于这个属性是 TopAddressing 的,我们就看下这个属性是怎么设置的。
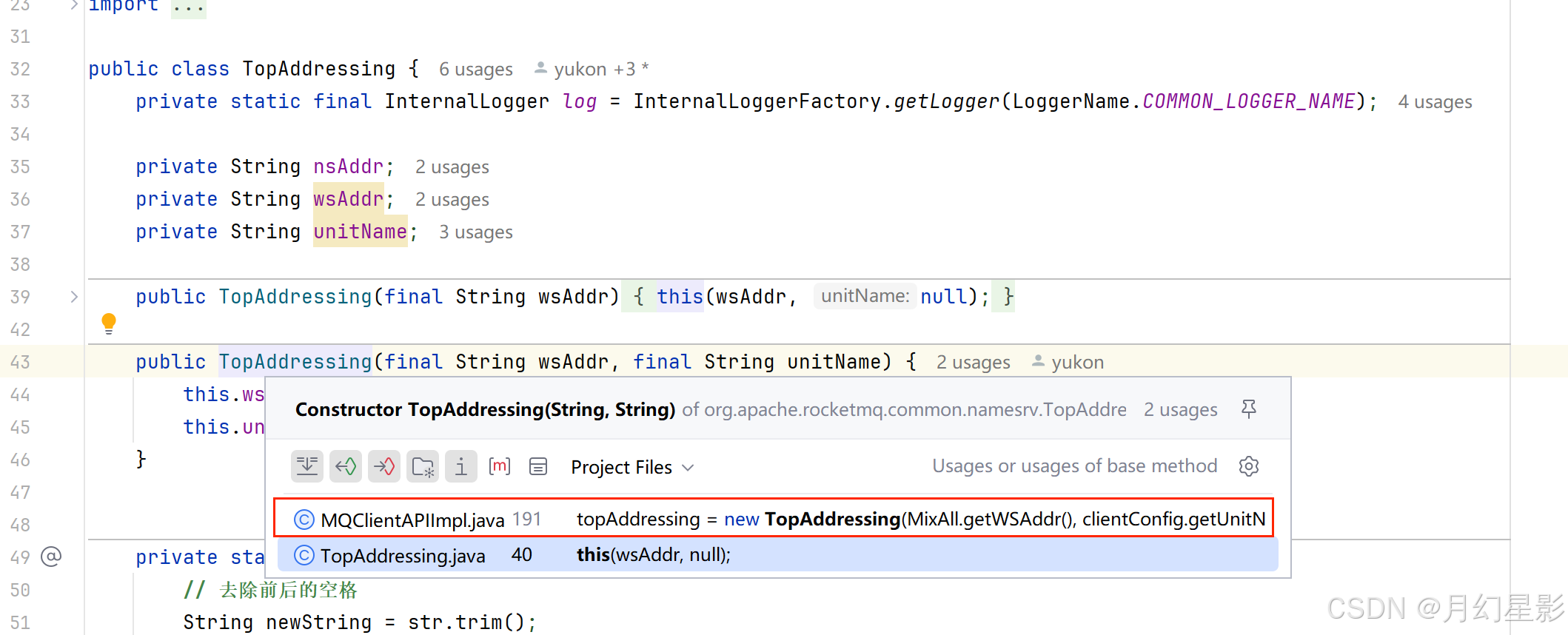
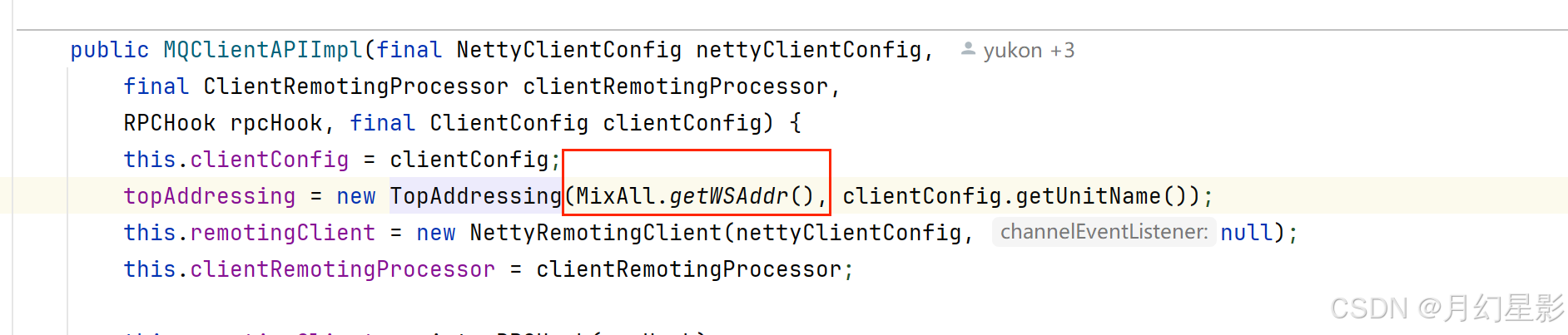
可以看到这个属性就是从 MixAll.getWSAddr 这个方法获取到的,这个方法就是用于获取地址服务器的请求地址。
/*** 获取 WS 地址* @return*/
public static String getWSAddr() {// 属性 rocketmq.namesrv.domain,默认值 jmenv.tbsite.netString wsDomainName = System.getProperty("rocketmq.namesrv.domain", DEFAULT_NAMESRV_ADDR_LOOKUP);// 属性 rocketmq.namesrv.domain.subgroup,默认值 nsaddrString wsDomainSubgroup = System.getProperty("rocketmq.namesrv.domain.subgroup", "nsaddr");// wsAddr 的默认值是 http://jmenv.tbsite.net:8080/rocketmq/nsaddrString wsAddr = "http://" + wsDomainName + ":8080/rocketmq/" + wsDomainSubgroup;// 如果存在 ':', 比如说 127.0.0.1:9876if (wsDomainName.indexOf(":") > 0) {// wsAddr 的会被设置成 http://127.0.0.1:9876/rocketmq/nsaddrwsAddr = "http://" + wsDomainName + "/rocketmq/" + wsDomainSubgroup;}// 返回 ws 地址return wsAddr;
}
如果在没有配置系统变量的情况下,默认就是 http://jmenv.tbsite.net:8080/rocketmq/nsaddr,这个一般也用不到吧,除非是用一个服务来统一管理 NameServer 地址,这里就看下注释即可。
8. 小结
承接上一篇文章,本篇对其中一些关键方法进行了补充说明。将这两篇文章结合起来,我们就梳理出了 broker 启动的大致逻辑。
在 broker 启动过程中,涉及众多方法,本文已着重对部分重要方法进行了补充介绍。不过,还有一些同样关键的操作尚未展开,比如将 broker 信息注册到 NameServer 这一操作。考虑到其重要性和复杂性,我会专门撰写一篇文章深入剖析。
至此,关于 broker 启动的大致逻辑就讲解到这里了。后续文章,我们再一同深入探讨其他关键环节。
如有错误,欢迎指出!!!!

)

)


包中关于SMTP协议支持的属性参数配置)






:关于angular里面的响应式数据入门使用)

详解)



