目录
1、PK_WITH_CLUSTER取值为0
2、PK_WITH_CLUSTER取值为1
达梦数据库的参数PK_WITH_CLUSTER在最近使用过程中发现与前期使用的版本存在差异,特此测试分析一下。具体哪个版本改动的暂未得知。
PK_WITH_CLUSTER,默认值为0,动态会话级参数。
参数含义:在建表语句或增加约束语句中指定主关键字时,是否缺省指定为CLUSTER,0:不指定;1:指定
注:该参数对水平分区表、列存储表和堆表无效
测试版本:
1-3-26-2024.08.21-240039-20046-ENT
--03134284058-20240821-240039-20046 Pack37接下来创建表,做一些验证测试。本文使用创建聚集主键的方式来做测试,创建聚集索引的效果与之相同。
1、PK_WITH_CLUSTER取值为0
(1)使用SQL语句创建普通表,表中存在主键,建表正常无报错
--创建一张普通测试表
DROP TABLE IF EXISTS T1;
CREATE TABLE T1(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
PRIMARY KEY(ID)
);
--插入测试数据
INSERT INTO T1 VALUES (7,'A',15,1);
INSERT INTO T1 VALUES (1,'A',20,2);
INSERT INTO T1 VALUES (3,'A',53,3);
INSERT INTO T1 VALUES (5,'A',35,4);
INSERT INTO T1 VALUES (10,'A',62,5);
INSERT INTO T1 VALUES (6,'A',18,6);
INSERT INTO T1 VALUES (2,'A',35,7);
INSERT INTO T1 VALUES (4,'A',66,8);
INSERT INTO T1 VALUES (9,'A',24,9);
INSERT INTO T1 VALUES (8,'A',41,10);
COMMIT;创建表后查看其表定义,由于PK_WITH_CLUSTER为0,所以建表后主键自动加了not cluster,建表结果与期望效果一致。
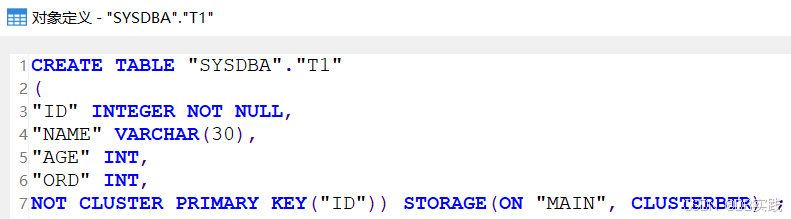
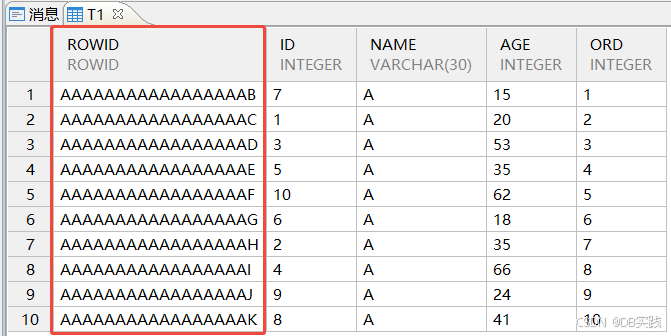
表数据默认以ROWID有序聚集。
(2)创建一张带有大字段的普通表,表中存在主键,主键字段非大字段类型,建表正常无报错
--创建一张普通测试表
DROP TABLE IF EXISTS T2;
CREATE TABLE T2(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
DINFO CLOB,
PRIMARY KEY(ID)
);
--插入测试数据
INSERT INTO T2 VALUES (7,'A',15,1,'test');
INSERT INTO T2 VALUES (1,'A',20,2,'test');
INSERT INTO T2 VALUES (3,'A',53,3,'test');
INSERT INTO T2 VALUES (5,'A',35,4,'test');
INSERT INTO T2 VALUES (10,'A',62,5,'test');
INSERT INTO T2 VALUES (6,'A',18,6,'test');
INSERT INTO T2 VALUES (2,'A',35,7,'test');
INSERT INTO T2 VALUES (4,'A',66,8,'test');
INSERT INTO T2 VALUES (9,'A',24,9,'test');
INSERT INTO T2 VALUES (8,'A',41,10,'test');
COMMIT;创建表后查看其表定义,由于PK_WITH_CLUSTER为0,所以建表后主键自动加了not cluster,建表结果与期望效果一致。
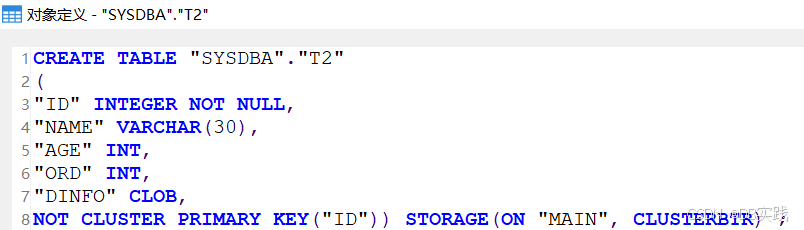
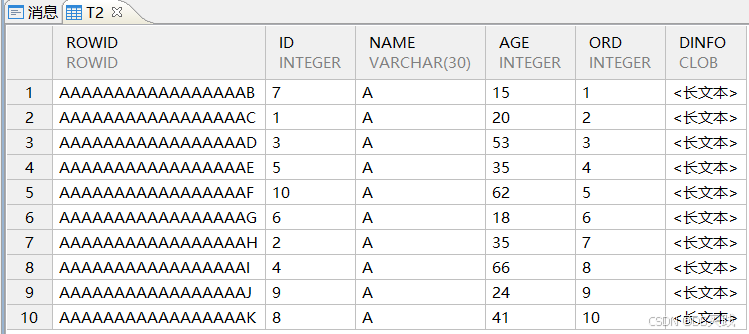
表数据默认以ROWID有序聚集。
(3)创建一张带有大字段的普通表,表中存在主键,主键字段为大字段类型,建表报错
--创建一张普通测试表
DROP TABLE IF EXISTS T3;
CREATE TABLE T3(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
DINFO CLOB,
PRIMARY KEY(DINFO)
);报错信息:“字段[DINFO]不可比较”。

这里可能会联想到一个参数ENABLE_BLOB_CMP_FLAG(是否支持大字段类型的比较)。但实际将参数ENABLE_BLOB_CMP_FLAG改为1后也是会继续报错的,因为此参数的作用主要是解决SQL语句中大字段与字符类型的比较这种情况的。
报错原因:大字段本身是不支持比较的,在大字段上创建主键,其实就相当于对大字段创建唯一素索引,为了确保数据的唯一,会涉及到比较的过程,所以报错。
(4) 创建一张带有大字段的普通表,建表时使用cluster显式创建聚集主键,主键字段为大字段类型,建表报错
--创建一张普通测试表
DROP TABLE IF EXISTS T4;
CREATE TABLE T4(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
DINFO CLOB,
CLUSTER PRIMARY KEY(DINFO)
);报错信息:“字段[DINFO]不可比较”。

报错原因:与上述(3)的原因相同。
(5)创建一张普通表,建表时使用cluster显式创建聚集主键,建表正常无报错
--创建一张普通测试表
DROP TABLE IF EXISTS T5;
CREATE TABLE T5(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
CLUSTER PRIMARY KEY(ID)
);
--插入测试数据
INSERT INTO T5 VALUES (7,'A',15,1);
INSERT INTO T5 VALUES (1,'A',20,2);
INSERT INTO T5 VALUES (3,'A',53,3);
INSERT INTO T5 VALUES (5,'A',35,4);
INSERT INTO T5 VALUES (10,'A',62,5);
INSERT INTO T5 VALUES (6,'A',18,6);
INSERT INTO T5 VALUES (2,'A',35,7);
INSERT INTO T5 VALUES (4,'A',66,8);
INSERT INTO T5 VALUES (9,'A',24,9);
INSERT INTO T5 VALUES (8,'A',41,10);
COMMIT;创建表后查看其表定义,由于显式指定了cluster,所以实际创建的聚集主键,建表结果与期望效果一致。
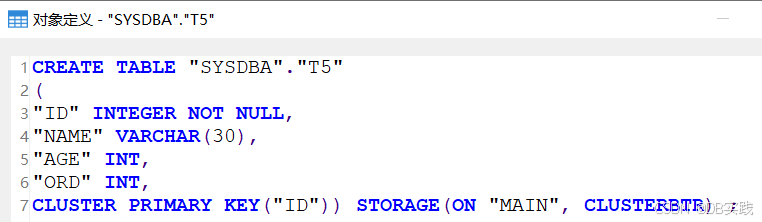
表数据以主键字段“ID”有序聚集。
(6)创建一张带有大字段的普通表,建表时使用cluster显式创建聚集主键,主键字段非大字段类型,建表正常无报错
--创建一张普通测试表
DROP TABLE IF EXISTS T6;
CREATE TABLE T6(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
DINFO CLOB,
CLUSTER PRIMARY KEY(ID)
);
--插入测试数据
INSERT INTO T6 VALUES (7,'A',15,1,'test');
INSERT INTO T6 VALUES (1,'A',20,2,'test');
INSERT INTO T6 VALUES (3,'A',53,3,'test');
INSERT INTO T6 VALUES (5,'A',35,4,'test');
INSERT INTO T6 VALUES (10,'A',62,5,'test');
INSERT INTO T6 VALUES (6,'A',18,6,'test');
INSERT INTO T6 VALUES (2,'A',35,7,'test');
INSERT INTO T6 VALUES (4,'A',66,8,'test');
INSERT INTO T6 VALUES (9,'A',24,9,'test');
INSERT INTO T6 VALUES (8,'A',41,10,'test');
COMMIT;创建表后查看其表定义,因为显式指定了cluster,理论上这里应该是聚集主键,但实际创建的非聚集主键,建表结果与期望效果并不一致,在比较老的版本上这里应该是cluster primary。
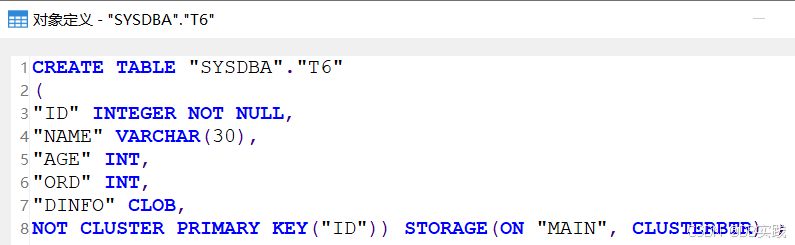
原因分析:在达梦数据库中,有大字段的表是不建议创建聚集索引的,因为可能存在数据文件快速膨胀的风险。所以这里应该是基于这一点,内部自动进行了转换,创建为了非聚集主键。
因此,表数据仍然以默认的ROWID有序聚集。
(7)创建一张分区表,表中存在主键,建表正常无报错
--创建一张普通测试表
DROP TABLE IF EXISTS T7;
CREATE TABLE T7(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
PRIMARY KEY(ID)
)
PARTITION BY RANGE(AGE) INTERVAL(10)(
PARTITION P1 VALUES EQU OR LESS THAN (18),
PARTITION P2 VALUES EQU OR LESS THAN (35),
PARTITION P3 VALUES EQU OR LESS THAN (60),
PARTITION P4 VALUES EQU OR LESS THAN (100));
--插入测试数据
INSERT INTO T7 VALUES (7,'A',15,1);
INSERT INTO T7 VALUES (1,'A',20,2);
INSERT INTO T7 VALUES (3,'A',53,3);
INSERT INTO T7 VALUES (5,'A',35,4);
INSERT INTO T7 VALUES (10,'A',62,5);
INSERT INTO T7 VALUES (6,'A',18,6);
INSERT INTO T7 VALUES (2,'A',35,7);
INSERT INTO T7 VALUES (4,'A',66,8);
INSERT INTO T7 VALUES (9,'A',24,9);
INSERT INTO T7 VALUES (8,'A',41,10);
COMMIT;创建表后查看其表定义,由于PK_WITH_CLUSTER为0,所以建表后主键自动加了not cluster,建表结果与期望效果一致。
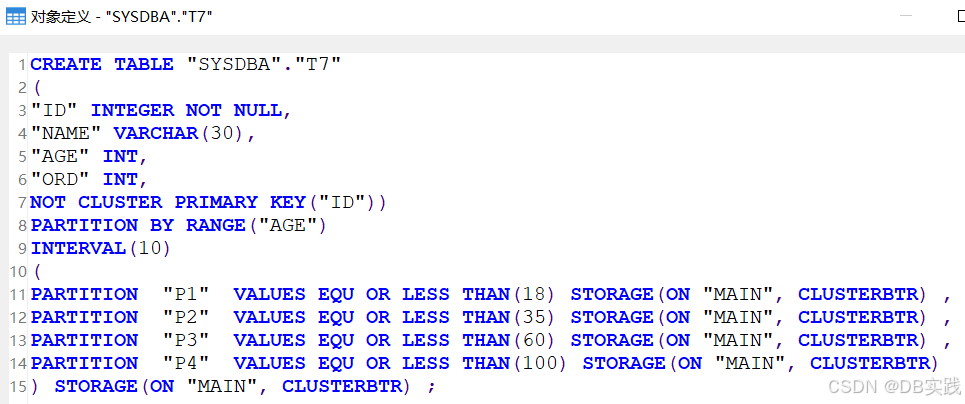
各子分区表中,表数据默认以ROWID有序聚集。
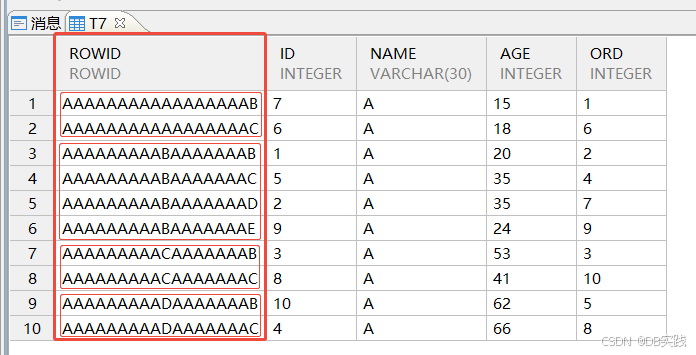
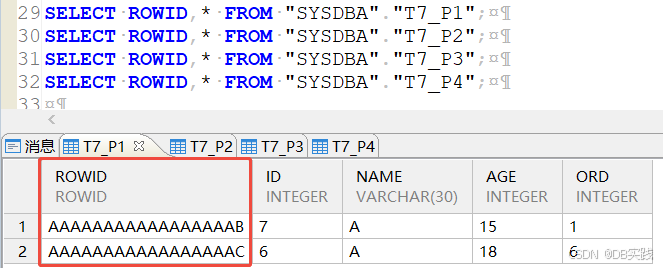
(8)创建一张分区表,建表时使用cluster显式创建聚集主键,建表报错
--创建一张普通测试表
DROP TABLE IF EXISTS T8;
CREATE TABLE T8(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
CLUSTER PRIMARY KEY(ID)
)
PARTITION BY RANGE(AGE) INTERVAL(10)(
PARTITION P1 VALUES EQU OR LESS THAN (18),
PARTITION P2 VALUES EQU OR LESS THAN (35),
PARTITION P3 VALUES EQU OR LESS THAN (60),
PARTITION P4 VALUES EQU OR LESS THAN (100));报错信息:“聚集主键必须包含全部分区列”
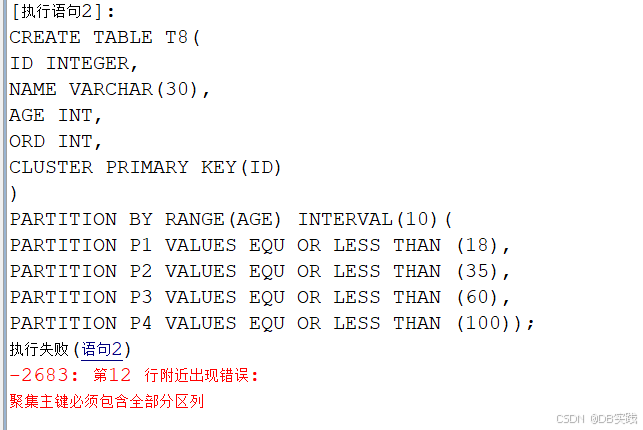
报错原因:创建聚集主键时,主键中需要把分区字段也加上
(9)创建一张分区表,建表时使用cluster显式创建聚集主键,聚集主键包含分区字段,建表正常无报错
--创建一张普通测试表
DROP TABLE IF EXISTS T8;
CREATE TABLE T8(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
CLUSTER PRIMARY KEY(ID,AGE)
)
PARTITION BY RANGE(AGE) INTERVAL(10)(
PARTITION P1 VALUES EQU OR LESS THAN (18),
PARTITION P2 VALUES EQU OR LESS THAN (35),
PARTITION P3 VALUES EQU OR LESS THAN (60),
PARTITION P4 VALUES EQU OR LESS THAN (100));
--插入测试数据
INSERT INTO T8 VALUES (7,'A',15,1);
INSERT INTO T8 VALUES (1,'A',20,2);
INSERT INTO T8 VALUES (3,'A',53,3);
INSERT INTO T8 VALUES (5,'A',35,4);
INSERT INTO T8 VALUES (10,'A',62,5);
INSERT INTO T8 VALUES (6,'A',18,6);
INSERT INTO T8 VALUES (2,'A',35,7);
INSERT INTO T8 VALUES (4,'A',66,8);
INSERT INTO T8 VALUES (9,'A',24,9);
INSERT INTO T8 VALUES (8,'A',41,10);
COMMIT;创建表后查看其表定义,由于显式指定了cluster,所以实际创建的聚集主键,建表结果与期望效果一致。
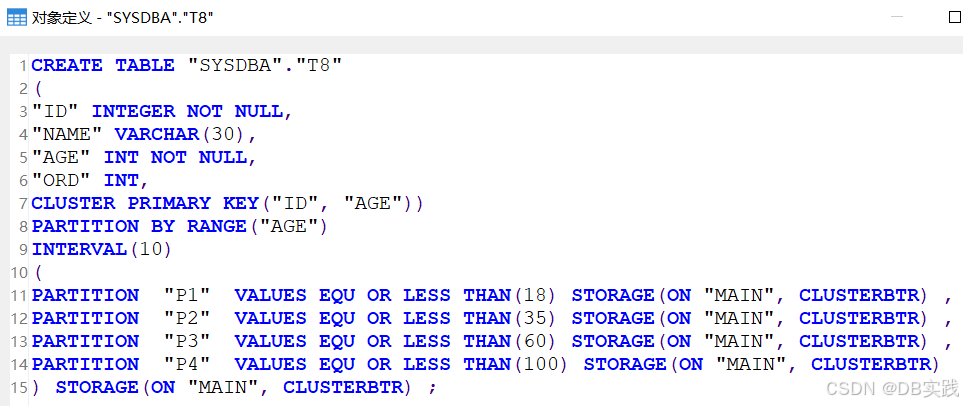
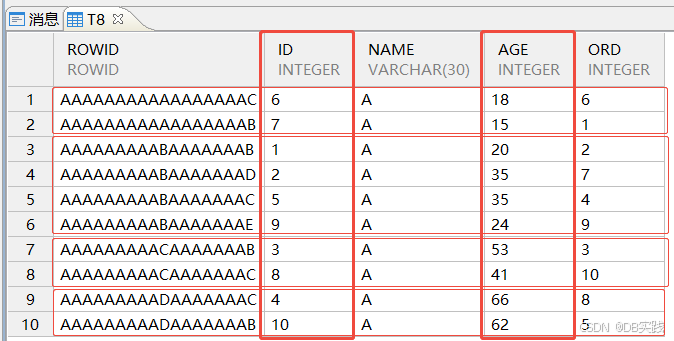
各子分区表中,表数据以主键字段“ID”,“AGE”有序聚集。数据会先以ID排序,当ID相同时按照AGE排序。
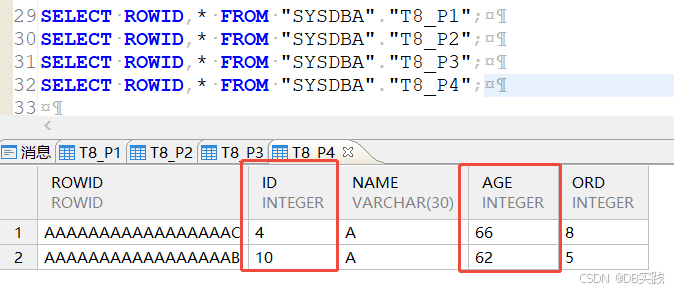
(10)创建一张带有大字段的分区表,表中存在主键,建表正常无报错
--创建一张普通测试表
DROP TABLE IF EXISTS T10;
CREATE TABLE T10(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
DINFO CLOB,
CLUSTER PRIMARY KEY(ID)
)
PARTITION BY RANGE(AGE) INTERVAL(10)(
PARTITION P1 VALUES EQU OR LESS THAN (18),
PARTITION P2 VALUES EQU OR LESS THAN (35),
PARTITION P3 VALUES EQU OR LESS THAN (60),
PARTITION P4 VALUES EQU OR LESS THAN (100));
--插入测试数据
INSERT INTO T10 VALUES (7,'A',15,1,'test');
INSERT INTO T10 VALUES (1,'A',20,2,'test');
INSERT INTO T10 VALUES (3,'A',53,3,'test');
INSERT INTO T10 VALUES (5,'A',35,4,'test');
INSERT INTO T10 VALUES (10,'A',62,5,'test');
INSERT INTO T10 VALUES (6,'A',18,6,'test');
INSERT INTO T10 VALUES (2,'A',35,7,'test');
INSERT INTO T10 VALUES (4,'A',66,8,'test');
INSERT INTO T10 VALUES (9,'A',24,9,'test');
INSERT INTO T10 VALUES (8,'A',41,10,'test');
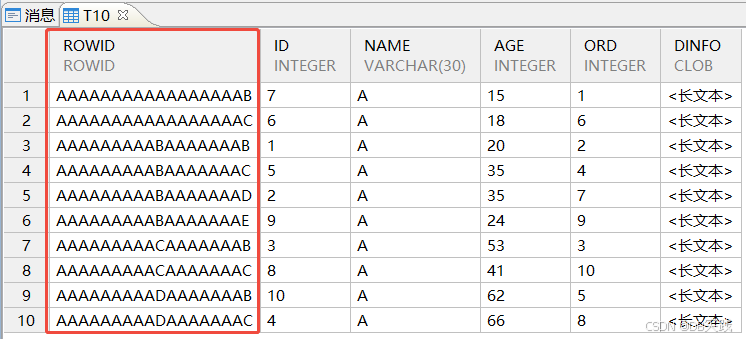
COMMIT;这里问题就出现了,建表的语句中聚集主键没有加分区字段,但是为什么创建没有报错呢?以往的老版本上,这里应该也会报错“聚集主键必须包含全部分区列”才对。
查看表定义,发现这里并没有创建成聚集主键,数据库自动加了not cluster,建表结果与期望效果不一致。
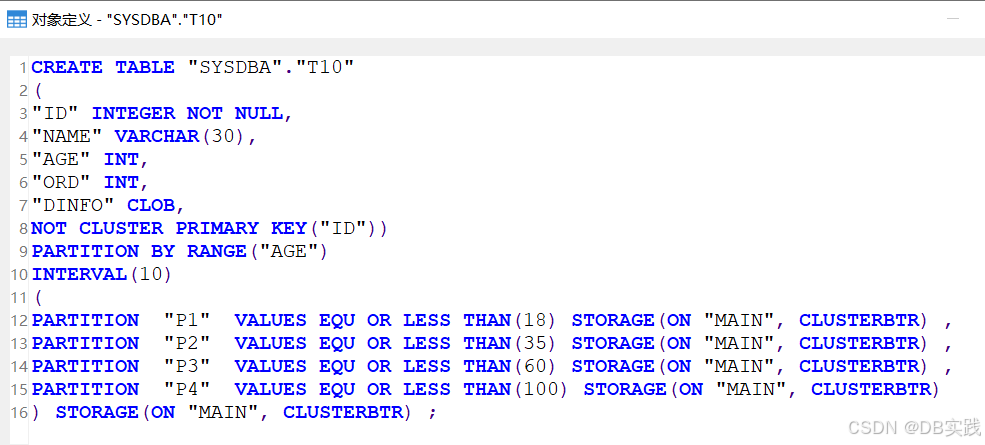
原因分析:这里应该是与(6)的测试情况是一样的原因,表中因为含有了大字段,所以系统内部自动创建成了非聚集主键。
由于最终创建的还是非聚集主键,数据还是默认以rowid排序聚集的。
(11)创建一张带有大字段的分区表,建表时使用cluster显式创建聚集主键,聚集主键包含分区字段,建表正常无报错
--创建一张普通测试表
DROP TABLE IF EXISTS T11;
CREATE TABLE T11(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
DINFO CLOB,
CLUSTER PRIMARY KEY(ID,AGE)
)
PARTITION BY RANGE(AGE) INTERVAL(10)(
PARTITION P1 VALUES EQU OR LESS THAN (18),
PARTITION P2 VALUES EQU OR LESS THAN (35),
PARTITION P3 VALUES EQU OR LESS THAN (60),
PARTITION P4 VALUES EQU OR LESS THAN (100));
--插入测试数据
INSERT INTO T11 VALUES (7,'A',15,1,'test');
INSERT INTO T11 VALUES (1,'A',20,2,'test');
INSERT INTO T11 VALUES (3,'A',53,3,'test');
INSERT INTO T11 VALUES (5,'A',35,4,'test');
INSERT INTO T11 VALUES (10,'A',62,5,'test');
INSERT INTO T11 VALUES (6,'A',18,6,'test');
INSERT INTO T11 VALUES (2,'A',35,7,'test');
INSERT INTO T11 VALUES (4,'A',66,8,'test');
INSERT INTO T11 VALUES (9,'A',24,9,'test');
INSERT INTO T11 VALUES (8,'A',41,10,'test');
COMMIT;查看表定义,这里一样没有创建成聚集主键,尽管满足了“聚集主键必须包含全部分区列”的限制,但大字段数据类型带来的风险更严重,因此还是优先保证规避风险,所以数据库还是自动加了not cluster,建表结果与期望效果不一致。
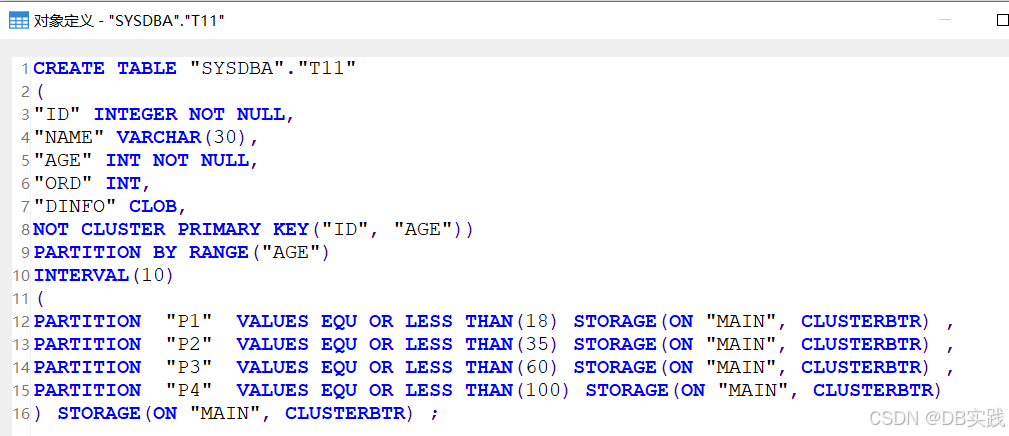
同样是由于创建的非聚集主键,数据还是默认以rowid排序聚集的。

(12)创建一张带有大字段的分区表, 表中存在主键或聚集主键,且主键或聚集主键是大字段,或者主键或聚集主键包含大字段的情况,均会报错。
--报错,分区表,主键为大字段
--创建一张普通测试表
DROP TABLE IF EXISTS T12;
CREATE TABLE T12(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
DINFO CLOB,
PRIMARY KEY(DINFO)
)
PARTITION BY RANGE(AGE) INTERVAL(10)(
PARTITION P1 VALUES EQU OR LESS THAN (18),
PARTITION P2 VALUES EQU OR LESS THAN (35),
PARTITION P3 VALUES EQU OR LESS THAN (60),
PARTITION P4 VALUES EQU OR LESS THAN (100));--报错,分区表,聚集主键为大字段
--创建一张普通测试表
DROP TABLE IF EXISTS T12;
CREATE TABLE T12(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
DINFO CLOB,
CLUSTER PRIMARY KEY(DINFO)
)
PARTITION BY RANGE(AGE) INTERVAL(10)(
PARTITION P1 VALUES EQU OR LESS THAN (18),
PARTITION P2 VALUES EQU OR LESS THAN (35),
PARTITION P3 VALUES EQU OR LESS THAN (60),
PARTITION P4 VALUES EQU OR LESS THAN (100));--报错,分区表,主键含大字段
--创建一张普通测试表
DROP TABLE IF EXISTS T12;
CREATE TABLE T12(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
DINFO CLOB,
PRIMARY KEY(ID,DINFO)
)
PARTITION BY RANGE(AGE) INTERVAL(10)(
PARTITION P1 VALUES EQU OR LESS THAN (18),
PARTITION P2 VALUES EQU OR LESS THAN (35),
PARTITION P3 VALUES EQU OR LESS THAN (60),
PARTITION P4 VALUES EQU OR LESS THAN (100));--报错,分区表,聚集主键含大字段
--创建一张普通测试表
DROP TABLE IF EXISTS T12;
CREATE TABLE T12(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
DINFO CLOB,
CLUSTER PRIMARY KEY(ID,DINFO)
)
PARTITION BY RANGE(AGE) INTERVAL(10)(
PARTITION P1 VALUES EQU OR LESS THAN (18),
PARTITION P2 VALUES EQU OR LESS THAN (35),
PARTITION P3 VALUES EQU OR LESS THAN (60),
PARTITION P4 VALUES EQU OR LESS THAN (100));--报错,分区表,聚集主键包含全部分区列,且含大字段
--创建一张普通测试表
DROP TABLE IF EXISTS T12;
CREATE TABLE T12(
ID INTEGER,
NAME VARCHAR(30),
AGE INT,
ORD INT,
DINFO CLOB,
CLUSTER PRIMARY KEY(ID,AGE,DINFO)
)
PARTITION BY RANGE(AGE) INTERVAL(10)(
PARTITION P1 VALUES EQU OR LESS THAN (18),
PARTITION P2 VALUES EQU OR LESS THAN (35),
PARTITION P3 VALUES EQU OR LESS THAN (60),
PARTITION P4 VALUES EQU OR LESS THAN (100));报错原因与(3)测试的原因相同。
2、PK_WITH_CLUSTER取值为1
当PK_WITH_CLUSTER=1时,其实就是免去了显式指定CLUSTER的方法,自动创建为了聚集主键或聚集索引,根据前文PK_WITH_CLUSTER取值为0时的测试结果及原因,其实可以猜到PK_WITH_CLUSTER取值为1时不同情况下的测试结果,因此这里直接写实际测试结果,不再过多赘述各测试结果出现的原因。
(1)使用SQL语句创建普通表,表中存在主键,建表正常无报错,创建的是聚集主键
(2)创建一张带有大字段的普通表,表中存在主键,主键字段非大字段类型,建表正常无报错,创建的是非聚集主键
(3)创建一张带有大字段的普通表,表中存在主键,主键字段为大字段类型,建表报错。报错信息:“字段[DINFO]不可比较”
(4)创建一张带有大字段的普通表,建表时使用cluster显式创建聚集主键,主键字段为大字段类型,建表报错。报错信息:“字段[DINFO]不可比较”
(5)创建一张普通表,建表时使用cluster显式创建聚集主键,建表正常无报错,创建的是聚集主键
(6)创建一张带有大字段的普通表,建表时使用cluster显式创建聚集主键,主键字段非大字段类型,建表正常无报错,创建的是非聚集主键
(7)创建一张分区表,表中存在主键,建表正常无报错,创建的是非聚集主键
(8)创建一张分区表,建表时使用cluster显式创建聚集主键,建表报错。报错信息:“聚集主键必须包含全部分区列”
(9)创建一张分区表,建表时使用cluster显式创建聚集主键,聚集主键包含分区字段,建表正常无报错,创建的是聚集主键
(10)创建一张带有大字段的分区表,表中存在主键,建表正常无报错,创建的是非聚集主键
(11)创建一张带有大字段的分区表,建表时使用cluster显式创建聚集主键,聚集主键包含分区字段,建表正常无报错,创建的是非聚集主键
(12)创建一张带有大字段的分区表, 表中存在主键或聚集主键,且主键或聚集主键是大字段,或者主键或聚集主键包含大字段的情况,均会报错。报错信息:“字段[DINFO]不可比较”
总结:达梦数据库底层修改策略,使得无论参数PK_WITH_CLUSTER是否为1,无论是否指定CLUSTER关键字显式创建聚集索引或聚集主键,目前均会自动避免出现聚簇表中有大字段的现象。此外,当参数PK_WITH_CLUSTER为1时,如果没有显式指定CLUSTER关键字,创建的分区表主键不满足“包含全部分区列”的条件,会自动创建成非聚集主键。





)

与替换进行结合使用)

)









