这里写目录标题
- 一、视图表 create view
- 1.1 视图表概述
- 1.2 视图表能否修改?(面试题)
- 1.3 基本语法
- 1.3.1 创建
- 1.3.2 查看
- 1.3.3 删除
- 1.4 通过视图表求无交集值
- 二、case语句
- 三、空值(null) 和 无值(' ') 的区别
- 四、正则表达式
- 4.1 基本语法和匹配模式
- 4.2 举个例子
- 五、存储过程
- 5.1 简介
- 5.2 存储过程的优点
- 5.3 建立存储过程的步骤
- 5.4 相关命令
- 5.4.1 创建
- 5.4.2 调用
- 5.4.3 查看
- 5.4.4 删除
- 5.5 存储过程的参数
- 5.6 存储过程的控制语句
- 5.6.1 条件语句`if-then-else ···· end if`
- 5.6.2 循环语句`while ···· end while`
一、视图表 create view
1.1 视图表概述
视图,可以被当作是虚拟表或存储查询。
视图跟表格的不同是,表格中有实际储存数据记录,而视图是建立在表格之上的一个架构,它本身并不实际储存数据记录。
临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。
视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。
比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写sql语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便。
1.2 视图表能否修改?(面试题)
视图表保存的是select语句的定义,视图表的表数据能否修改,视情况而定。
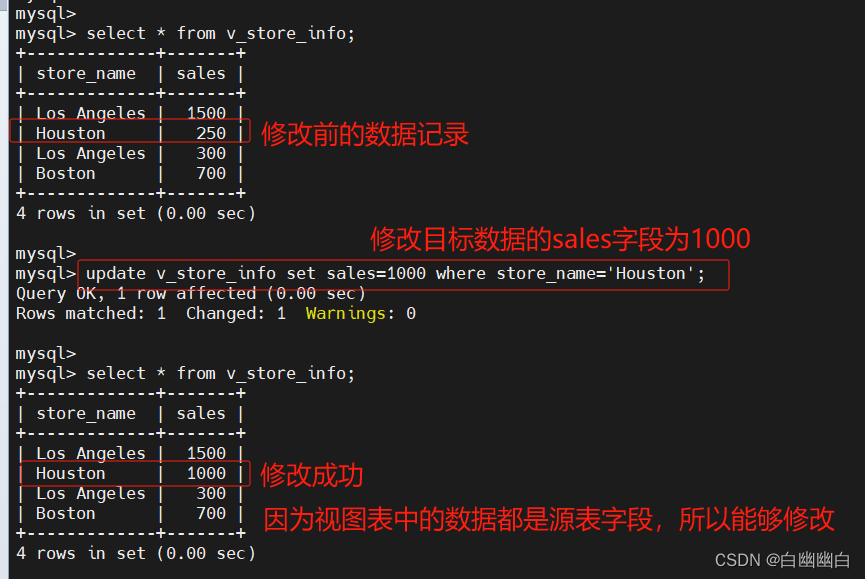
如果 select 语句查询的字段是没有被处理过的源表字段,则可以通过视图表修改源表数据;
如果select 语句查询的字段是被 group by语句或 函数 处理过的字段,则不可以直接修改视图表的数据。
举个例子
create view v_store_info as select store_name,sales from store_info;update v_store_info set sales=1000 where store_name='Houston';
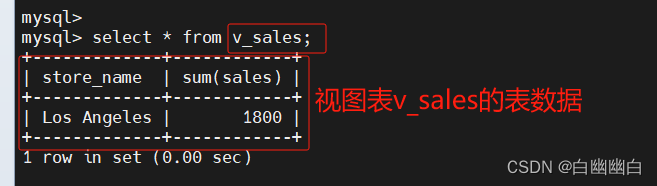
create view v_sales as select store_name,sum(sales) from store_info group by store_name having sum(sales)>1000;update v_sales set store_name='xxxx' where store_name='Los Angeles';

1.3 基本语法
1.3.1 创建
语法
create view "视图表名" as "select 语句";
举个例子
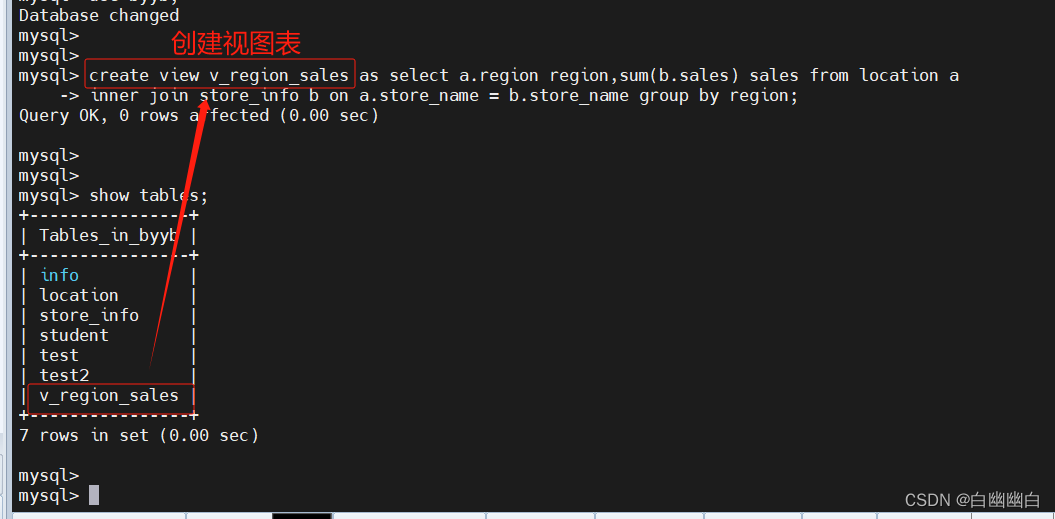
create view v_region_sales as select a.region region,sum(b.sales) sales from location a
inner join store_info b on a.store_name = b.store_name group by region;
1.3.2 查看
语法
select * from 视图表名;
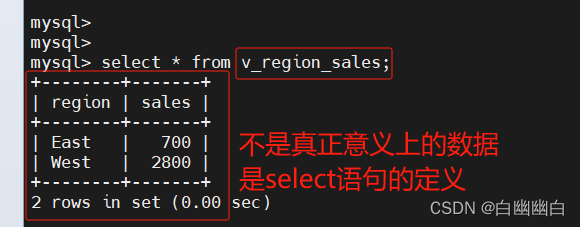
select * from v_region_sales;
1.3.3 删除
语法
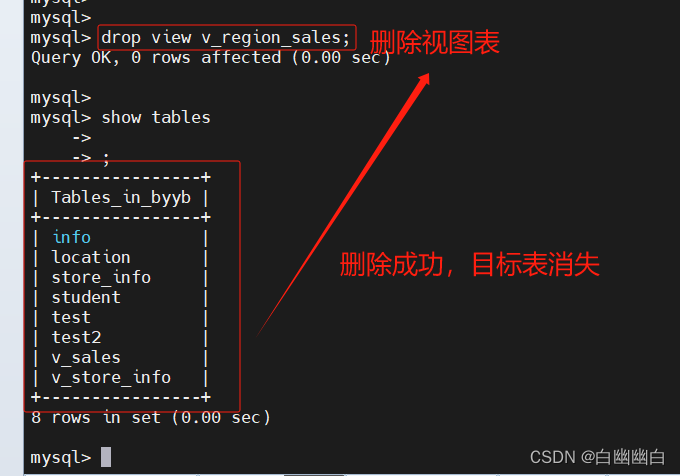
drop view 视图表名;
drop view v_region_sales;
1.4 通过视图表求无交集值
将两个表中某个字段的不重复值进行合并
只出现一次(count =1 ) ,即无交集
通过
create view 视图表名 as select distinct 字段 from 左表 union all select distinct 字段 from 右表;select 字段 from 视图表名 group by 字段 having count(字段)=1;
#先建立视图表
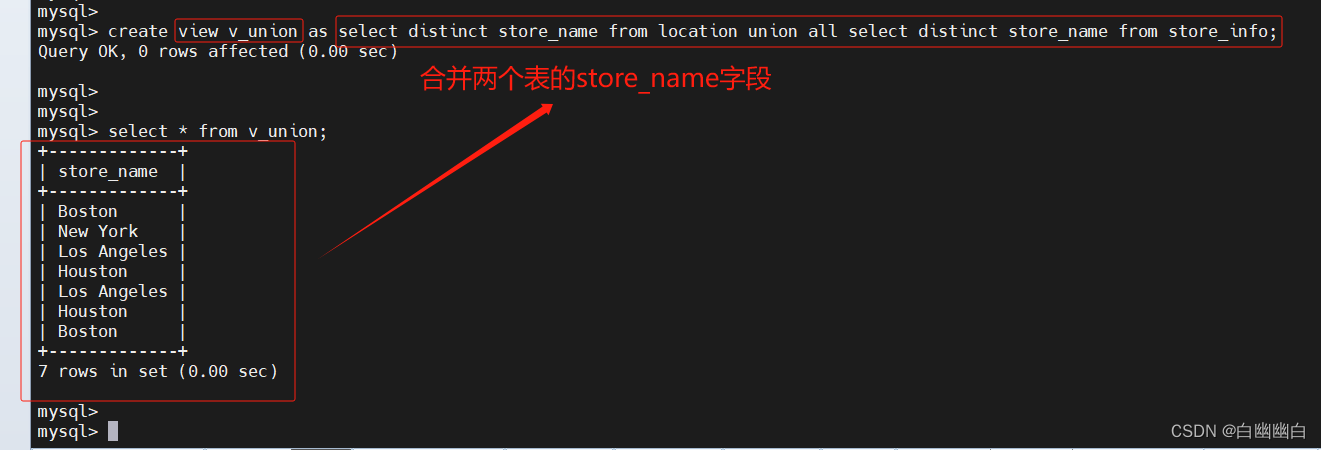
create viem v_union as select distinct store_name from location union all select distinct store_name from store_info;
#再通过视图表求无交集
select store_name from v_union group by store_name having count(*)=1;

二、case语句
在MySQL中,CASE语句用于根据给定条件对数据进行条件判断和分支选择。
它可以在SELECT、UPDATE、DELETE语句中使用,也可以用于表达式中。
语法
select case ("字段名")when "条件1" then "结果1"when "条件2" then "结果2"...[else "结果n"]end
from "表名";# "条件" 可以是一个数值或是公式。 else 子句则并不是必须的。
#举个例子
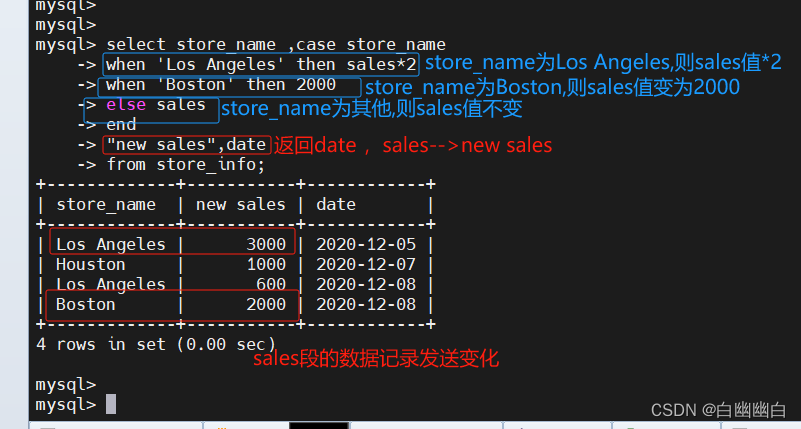
select store_name, case store_name when 'los angeles' then sales * 2 when 'boston' then 2000else sales end
'new sales',date
from store_info;#将'sales的值作为new sales的值返回
三、空值(null) 和 无值(’ ') 的区别
1)无值的长度为 0,不占用空间的;而 null 值的长度是 null,是占用空间的;
2)is null 或者 is not null,是用来判断字段是不是为 null 或者不是 null,不能查出是不是无值的;
3)无值的判断使用=' '或者<>' '来处理,<> 和 !=代表不等于;
4)在通过 count( )指定字段统计有多少行数时,如果遇到 NULL 值会自动忽略掉,遇到无值会加入到记录中进行计算。
四、正则表达式
4.1 基本语法和匹配模式
语法
select "字段" from "表名" where "字段" regexp {匹配模式};
匹配模式不区分大小写
| 匹配模式 | 描述 | 实例 |
|---|---|---|
| ^ | 匹配文本的开始字符 | ‘^bd’ 匹配以 bd 开头的字符串 |
| $ | 匹配文本的结束字符 | ‘qn$’ 匹配以 qn 结尾的字符串 |
| . | 匹配任何单个字符 | ‘s.t’ 匹配任何 s 和 t 之间有一个字符的字符串 |
| * | 匹配零个或多个在它前面的字符 | ‘fo*t’ 匹配 t 前面有任意个 o |
| + | 匹配前面的字符 1 次或多次 | ‘hom+’ 匹配以 ho 开头,后面至少一个m 的字符串 |
| 字符串 | 匹配包含指定的字符串 | ‘clo’ 匹配含有 clo 的字符串 |
| p1|p2 | 匹配 p1 或 p2 | ‘bg|fg’ 匹配 bg 或者 fg |
| […] | 匹配字符集合中的任意一个字符 | ‘[abc]’ 匹配 a 或者 b 或者 c |
| [^…] | 匹配不在括号中的任何字符 | [^ a b] 匹配不包含 a 或者 b 的字符串 |
| {n} | 匹配前面的字符串 n 次 | ‘g{2}’ 匹配含有 2 个 g 的字符串 |
| {n,m} | 匹配前面的字符串至少 n 次,至多m 次 | ‘f{1,3}’ 匹配 f 最少 1 次,最多 3 次 |
4.2 举个例子
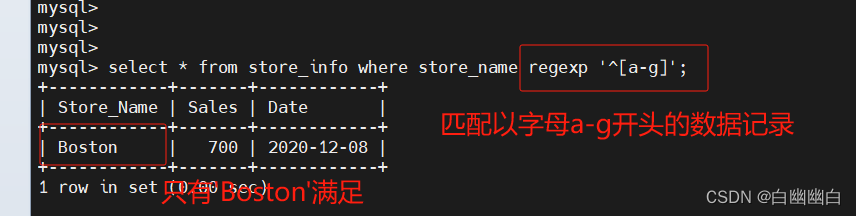
select * from store_info where store_name regexp '^[a-g]';
select * from store_info where store_name regexp 'Hou+';
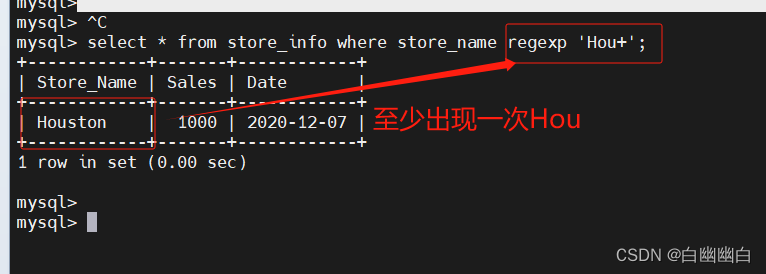
select * from store_info where store_name regexp 'os';
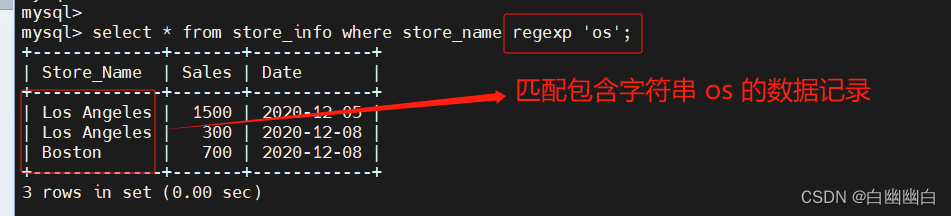
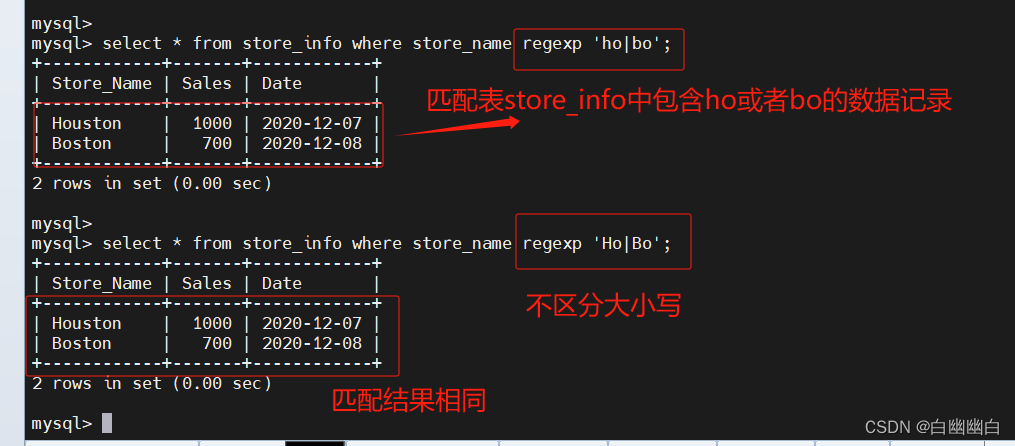
select * from store_info where store_name regexp 'ho|bo';select * from store_info where store_name regexp 'Ho|Bo';
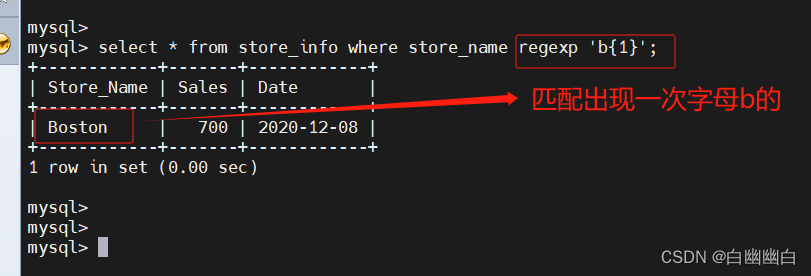
select * from store_info where store_name regexp 'b{1}';
五、存储过程
存储过程也叫做数据库脚本(MySQL脚本,SQL脚本)
5.1 简介
存储过程是一组为了完成特定功能的sql语句集合。
存储过程在使用过程中是将常用或者复杂的工作预先使用sql语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可。存储过程在执行上比传统sql速度更快、执行效率更高。
5.2 存储过程的优点
1、执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
2、sql语句加上控制语句的集合,灵活性高
3、在服务器端存储,客户端调用时,降低网络负载
4、可多次重复被调用,可随时修改,不影响客户端调用
5、可完成所有的数据库操作,也可控制数据库的信息访问权限
5.3 建立存储过程的步骤
1)临时修改SQL语句的结束符(;——>自定义符号,比如$$ ,##,...);
2)创建存储过程;
3)将SQL语句结束符改回;;
4)调用存储过程。
5.4 相关命令
5.4.1 创建
delimiter $$
#将语句的结束符号从分号;临时改为两个$$(可以是自定义)
create procedure proc()
#创建存储过程,过程名为proc,不带参数
-> begin
#过程体以关键字 begin 开始
-> select * from store_info;
#过程体语句
-> end $$
#过程体以关键字 end 结束
delimiter ;
#将语句的结束符号恢复为分号delimiter $$
create procedure proc()
-> begin
->.....(要执行的命令)
-> select * from store_info;
-> end $$
delimiter ;
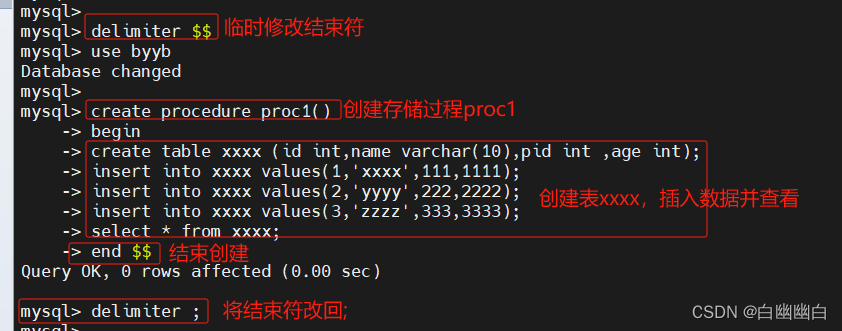
#举个例子delimiter $$
use byyb
create procedure proc1()
begin
create table xxxx (id int,name varchar(10),pid int,,age int);
insert into xxxx values (1,'xx',11,111);
insert into yyyy values (2,'yy',22,222);
insert into zzzz values (3,'zz',33,333);
select * from xxxx;
end $$
delimiter ;
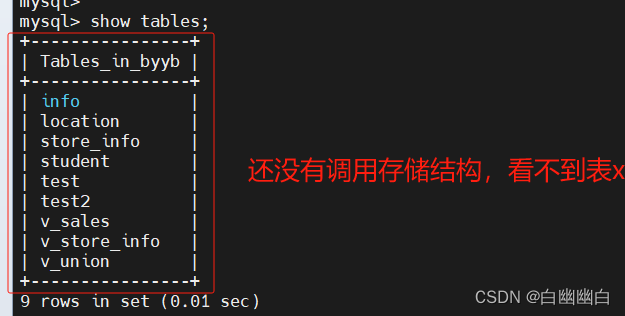
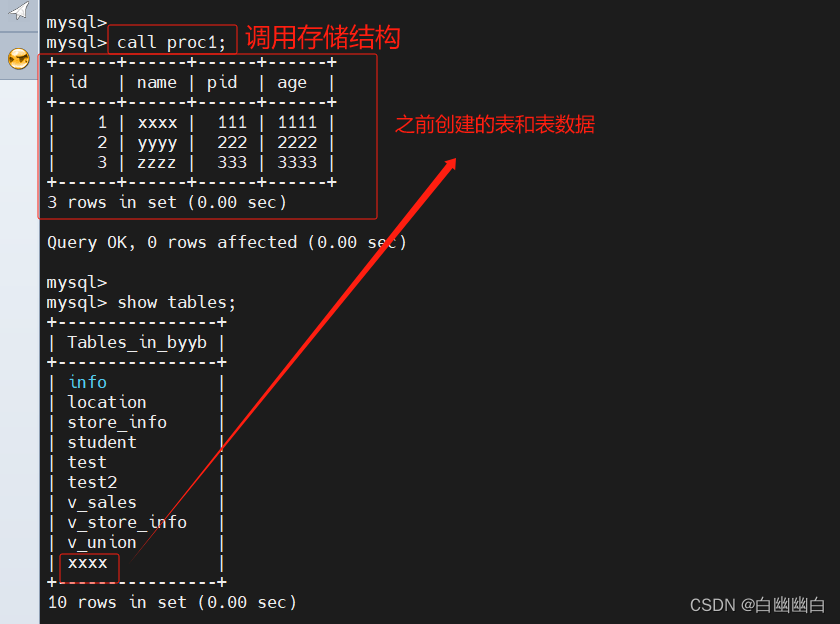
5.4.2 调用
call 存储过程名;
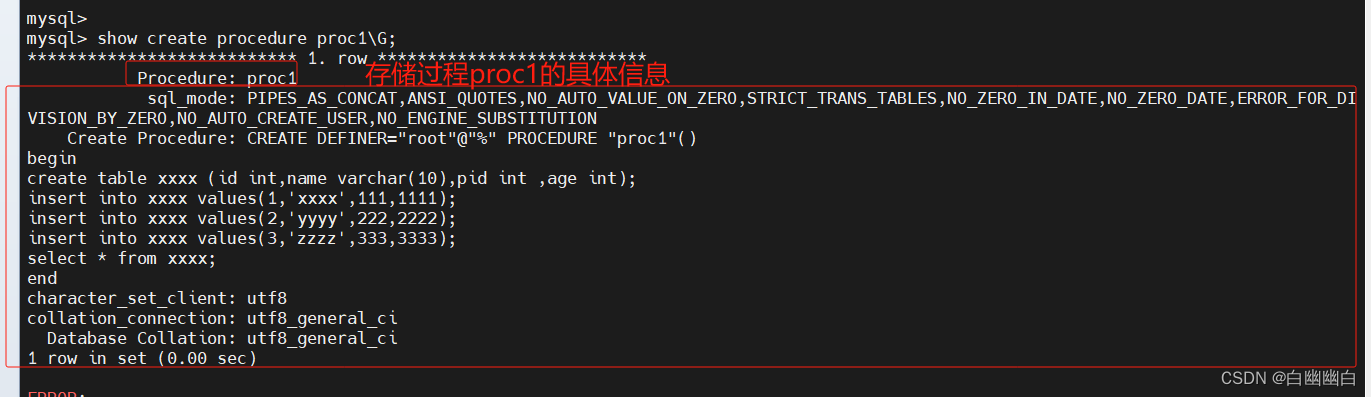
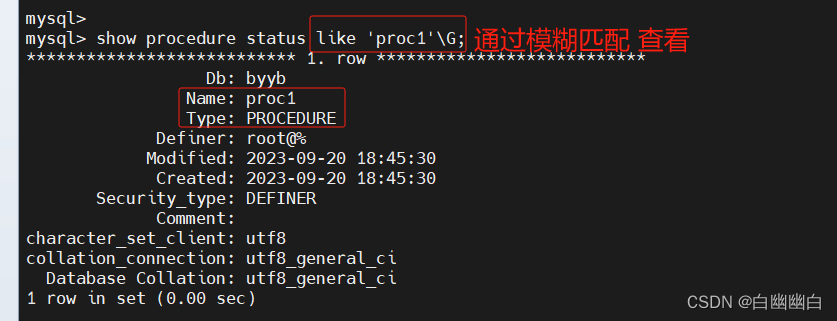
5.4.3 查看
show create procedure [数据库.]存储过程名;
#查看某个存储过程的具体信息show create procedure 存储过程名\G;show procedure status [like '%存储过程名%'] \G;
5.4.4 删除
存储过程内容的修改方法是通过删除原有存储过程,之后再以相同的名称创建新的存储过程。
如果要修改存储过程的名称,可以先删除原存储过程,再以不同的命名创建新的存储过程。
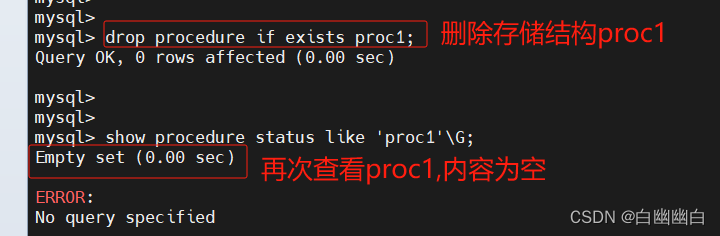
基本语法
drop procedure if exists 存储过程名;
#仅当存在时删除
#不添加 if exists 时,如果指定的过程不存在,则报错
5.5 存储过程的参数
| 参数 | 功能 |
|---|---|
| in 输入参数 | 表示调用者向过程传入值(传入值可以是字面量或变量) |
| out 输出参数 | 表示过程向调用者传出值(可以返回多个值)(传出值只能是变量) |
| inout 输入输出参数 | 既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量,传入传出值必须是同一数据类型) |
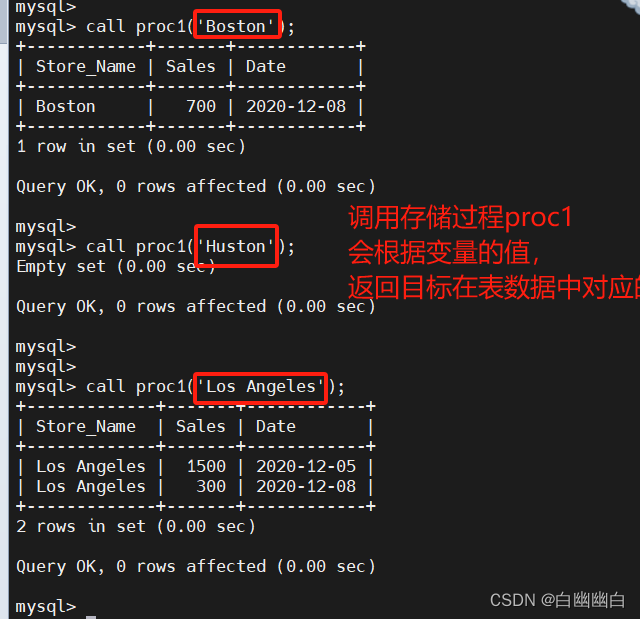
in
delimiter $$
create procedure proc1(in inname char(16))
-> begin
-> select * from store_info where store_name = inname;
-> end $$
delimiter ; call proc1('boston');#inname为自定义变量名
out
基本格式delimiter $$
create procedure 存储过程名(in 传入参数名 传入参数数据类型,out 传出参数名 传出参数数据类型)
begin
select 字段 into 传出参数名 from 表名 where 字段=传入参数名;
end $$
delimiter ;call 存储过程名(参数值,@变量名)
#传出参数的值只能用变量获取
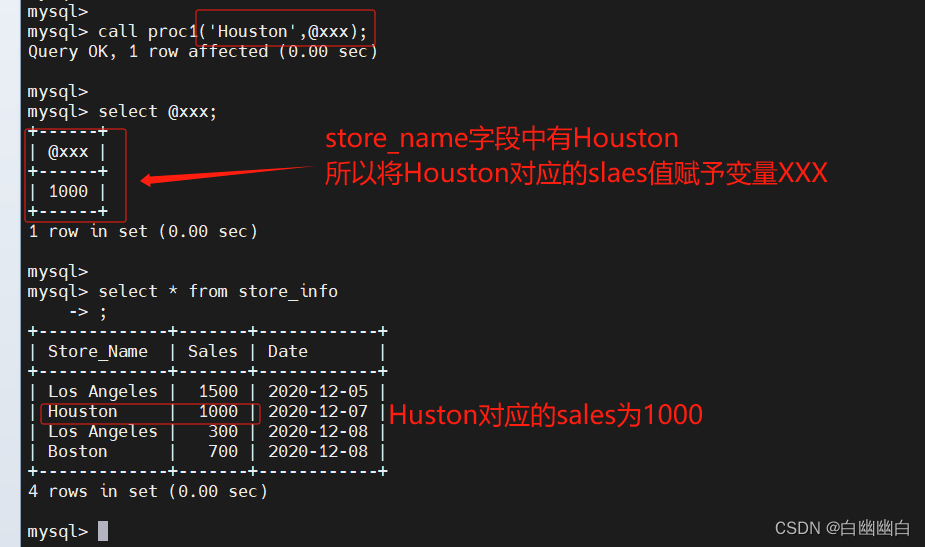
#举个例子delimiter $$
mysql> create procedure proc1(in myname char(10), out outname int)-> begin-> select sales into outname from store_info where store_name = myname-> end $$
delimiter ;
#建一个名为 proc1 的存储过程
#存储过程接收一个字符参数 myname,并将与其匹配的 store_info 表中的 sales 值存储到一个整数参数 outname 中call proc1('Houston', @xxx);
select @xxx;
inout
基本格式delimiter $$
create procedure 存储过程名(into 参数名 参数数据类型)
begin
select 字段 into 传出参数名 from 表名 where 字段=参数名;
end $$
delimiter ;set @变量名 传入值
#变量赋值,传入值
call 存储过程名(@变量名)
#传入传出参数的值只能用变量
select @变量名
#此时变量内容应该为传出值
delimiter $$
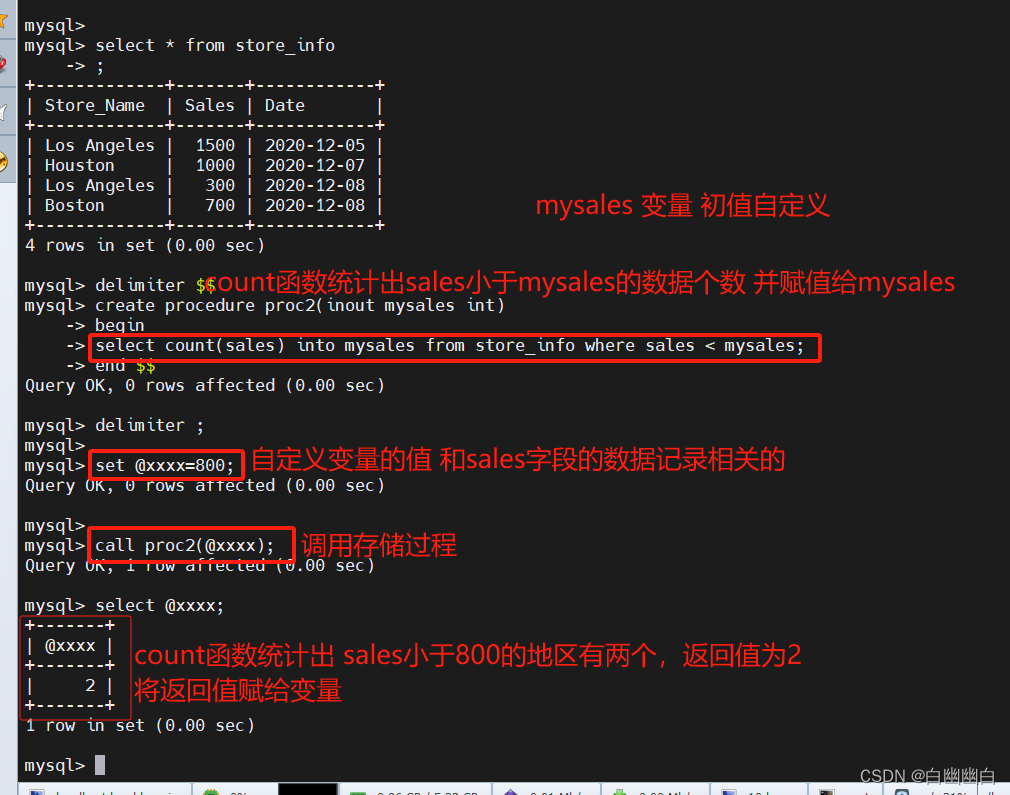
create procedure proc4(inout insales int)
-> begin
-> select count(sales) into insales from store_info where sales < insales;
-> end $$
delimiter ;
set @inout_sales=1000;
call proc4(@inout_sales);
select @inout_sales;#创建了一个名为 proc4 的存储过程
#存储过程接受一个输入输出参数 insales,并通过查询 store_info 表获取 sales 值小于 insales 的记录数量,并将结果存储到参数 insales 中。
#通过 call 语句调用该存储过程,并使用 select 语句查看存储在变量 @inout_sales 中的值。
5.6 存储过程的控制语句
create table t (id int(10));
insert into t values(10);
5.6.1 条件语句if-then-else ···· end if
if 条件表达式 thenSQL语句序列1
elseSQL语句序列2
end if;
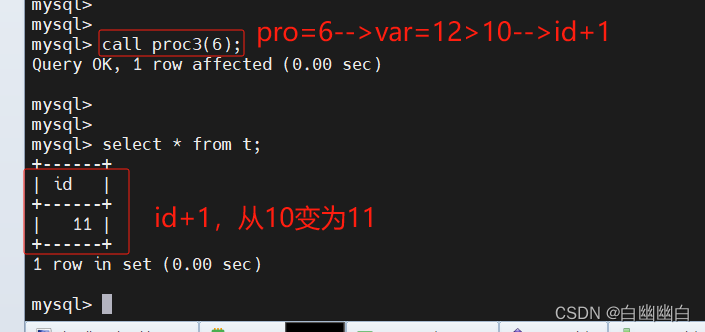
delimiter $$
create procedure proc3(in pro int)
-> begin
-> declare var int;
-> set var=pro*2;
-> if var>=10 then
-> update t set id=id+1;
-> else
-> update t set id=id-1;
-> end if;
-> end $$delimiter ;call proc3(6);
#pro=6
5.6.2 循环语句while ···· end while
while 条件表达式
doSQL语句序列set 条件迭代表达式;
end while;
delimiter $$
create procedure proc3()
-> begin
-> declare var int(10);
-> set var=0;
-> while var<6 do
-> insert into t values(var);
-> set var=var+1;
-> end while;
-> end $$ delimiter ;call proc3;
举个例子
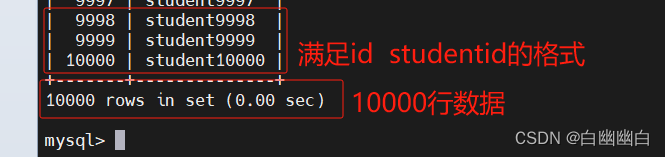
创建一张表
id name
1 student1
…
一万行数据
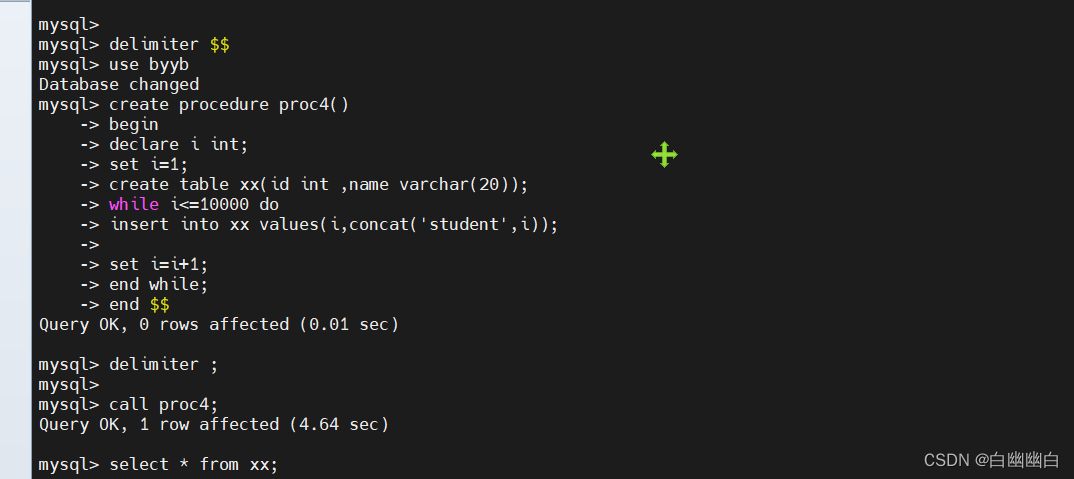
delimiter $$
create procedure proc4()
begin
declare i int;
set i=1;
create table xx(id int ,name varchar(20))
while i<=10000 do
insert into xx values(i,concat('student',i));
set i=i+1;
end while;
end $$ delimiter ;call proc4;


)
)






ngx.balance和balance_by_lua灰度发布)








