Job那块的断点代码截图省略,直接进入切片逻辑
参考:Hadoop3:MapReduce源码解读之Map阶段的Job任务提交流程(1)
6、CombineFileInputFormat原理解析
类的继承关系
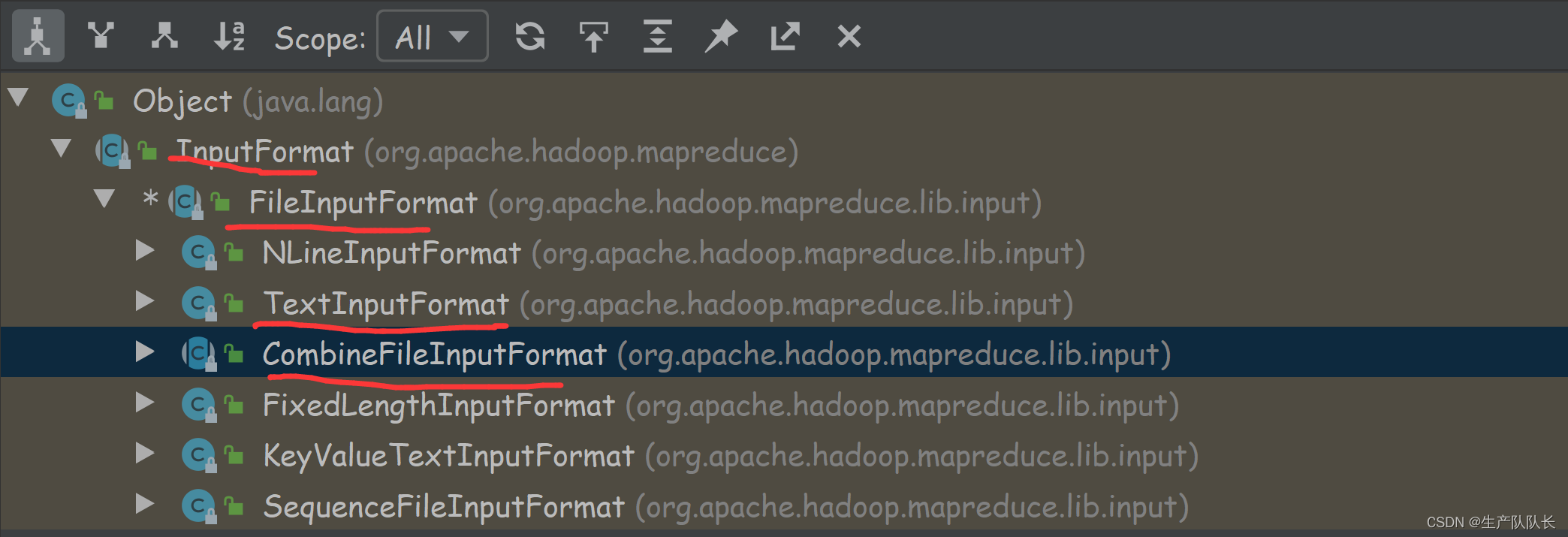
与TextInputFormat切片机制的区别
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
所以,这个切片机制是针对处理大量小文件的,效率比TextInputFormat更高。
切片过程说明
生成切片过程包括:虚拟存储过程和切片过程二部分。

注意
当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
案例
准备4个文件
依然用wordcount案例进行演练
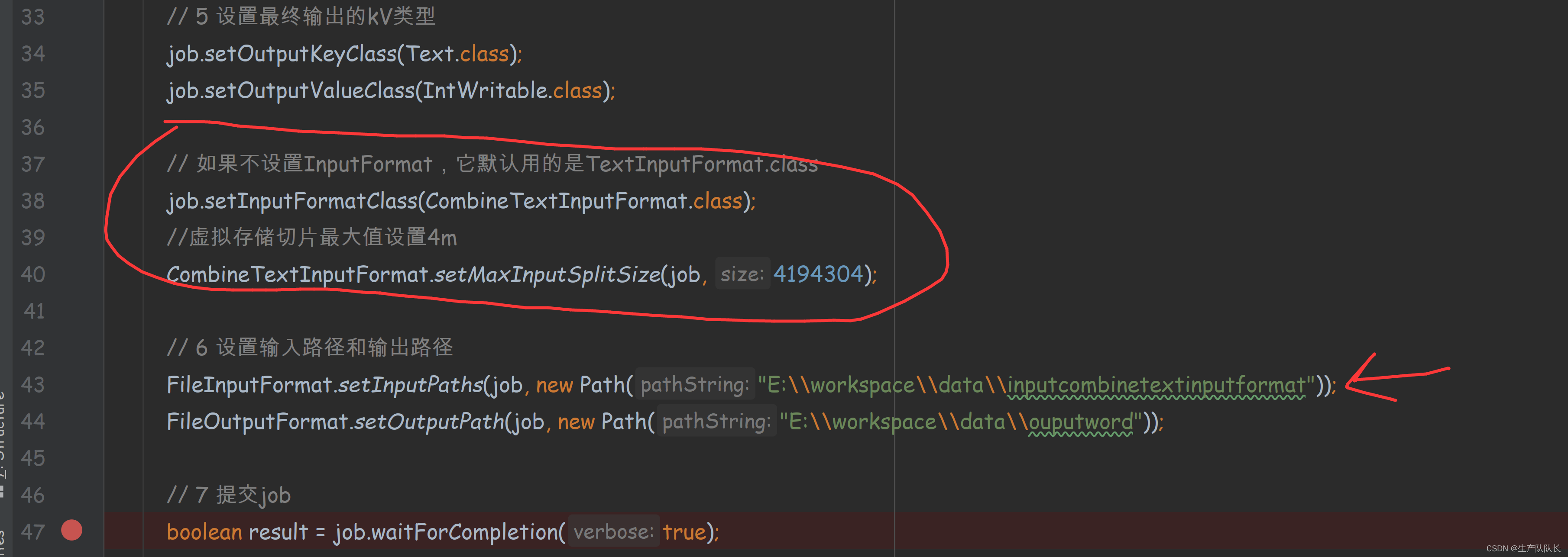
指定文件路径和切片类CombineFileInputFormat
// 如果不设置InputFormat,它默认用的是TextInputFormat.classjob.setInputFormatClass(CombineTextInputFormat.class);//虚拟存储切片最大值设置4mCombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
查看执行日志:
number of splits:3
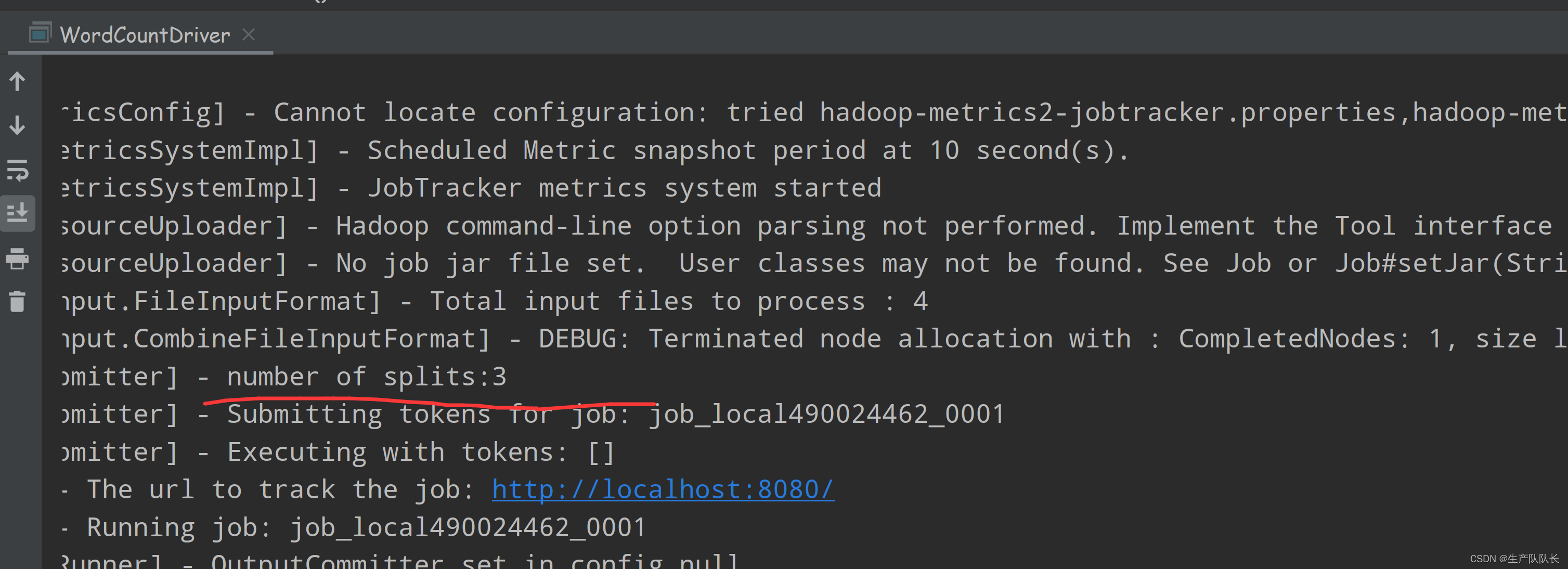
所以,对应的MapTask线程数量就是3个,Reducer线程数是1个。
)

虚拟机性能测试)
![[消息队列 Kafka] Kafka 架构组件及其特性(一)](http://pic.xiahunao.cn/[消息队列 Kafka] Kafka 架构组件及其特性(一))







的意思)




训练与使用自己的模型_识别字母)


