写在前面
大家好,我是青玉白露。
在这个充斥着精英主义色彩的社会里,"双一流"大学和耀眼奖项似乎成了走向职业成功、大厂的不二法门及必备之物。
然而,今天我要分享的,是一个打破常规的故事,是一个关于普通二本学生如何成功逆袭进入互联网巨头腾讯和字节跳动的励志故事。这不仅是一段个人奋斗史,更是一份给所有怀揣梦想、欲穿越重重困难上岸大厂的人的指南。
先说一下背景,他是一位普通的二本学生,主修计算机编程,凭借着自己的努力和坚持,成功地拿下了腾讯、字节跳动以及其他知名互联网公司的offer。他的故事不仅激励着每一位梦想进入大厂的求职者,也向我们展示了秋招前期的准备、岗位选择以及校招时间线的重要性。**努力和毅力!一定要用对方向!**见下。
经验感悟
我的实习之路是从一系列艰辛的尝试和不懈的努力开始的。
我逐一投递简历,经历了无数次的面试练习。最终,我收到了包括腾讯、字节跳动、滴滴、网易雷火和图森未来在内的多个实习offer。
在权衡之后,我选择了字节跳动,一个充满活力且快速成长的互联网企业。实习期间,我全身心投入工作,积极学习,最终赢得了公司的认可,并顺利转正。
而在随后的秋季招聘季节中,我的努力再次得到了回报。我成功拿下了腾讯、字节跳动、百度、美团、网易互娱、虾皮和米哈游等超过十家知名互联网公司的工作offer。
这些岗位覆盖了cpp、golang、java、大数据和游戏研发等多个领域,几乎每一次给我面试机会的公司,我都能从容通过。
我分享这些,并不是为了炫耀个人成就,而是想告诉所有有志于进入大厂工作的朋友们:即使你是双非本科生,只要你有能力,有毅力,大厂的门槛并不像你想象的那么高不可攀。
但是要注意!努力和毅力!一定要用对方向!
秋招前期准备事项:
- 投递渠道:
- 官网投递
- 可靠的招聘软件,例如boss直聘和牛客
- 内推,包括直系学长、牛客、脉脉、v2ex、leetcode求职区
- 内推策略:
- 选择能够联系到且负责的内推人
- 内推人能够查看最新面试状态和帮助解决简历锁定问题
- 对内推人的帮助心怀感激,但不需有心理负担
- 内推类型:
- 部门、组内直推可以快速得到反馈
- 寻找特殊内推机会,例如免笔试、免筛选、直通面试的机会
岗位选择事项:
- 部门考量:
- 选择事少钱多或氛围好的部门
- 投递正在快速扩张或紧急缺人的部门,通常面试难度较低
- 了解部门信息来源:
- 脉脉职言区
- Workinfo微信小程序
- 直接询问部门员工
- 岗位适应性:
- 校招时更关注学习能力和基础,而非专业技能
- 转语言或方向是常见现象,面试官更看重学习能力
校招重要时间线:
- 实习的重要性:
- 实习经历可提升简历含金量
- 实习有助于降低面试难度
- 实习转正可提前获得offer,增强面试时的信心
- 实习策略:
- 如果学校不允许实习,考虑远程实习或其他途径
- 权衡实习与提前批面试的时间安排
- 提前批招聘:
- 提前批通常有更多HC,SP offer获得概率高
- 提前批面试不影响正式批次,增加了试错机会
- 注意提前批和实习转正的时间冲突,合理规划时间
**总而言之,**努力和正确的策略是进入大厂的关键。无论背景如何,只要有信心和坚持,就有可能实现自己的职业梦想。
面经分享
下面我们来看一次他面试字节的过程吧,大家主要关心知识背景以及回答技巧。
一共分为项目介绍、八股文和三道算法题。
注意划线!注意划线!注意划线!好记性比不过烂笔头!
项目介绍
面试官: 你好!感谢你参加抖音电商供应链在上海的面试。今天我们首先来聊一聊你的项目经历。能否简要介绍一下你的项目1和项目2呢?
求职者: 当然可以。在项目1中,我主要负责了……(此处省略具体项目介绍)。而在项目2中,我则是……(此处省略具体项目介绍)。
八股文
面试官: 我们将重点讨论一些理论知识。首先,请你解释一下脏读和幻读是什么?
求职者: 脏读是指一个事务读取了另一个未提交事务的数据。而幻读则是指在一个事务内读取了几次表中的某个范围的记录,但每次读取的数据都不同。
面试官: 很好。那么你能解释一下ACID是什么吗?
求职者: 当然。ACID代表原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。它们是事务处理中必须满足的四个条件,用来确保数据库事务是可靠的。
面试官: 接下来,请你告诉我网络的五层与七层模型的区别吗?
求职者: 网络的五层模型包括应用层、传输层、网络层、数据链路层和物理层。而七层模型则额外包括表示层和会话层。七层模型比五层模型更详细地描述了网络通信过程中的各个环节。
面试官: 非常好。那么,HTTP状态码能否举几个例子说明它们的含义?
求职者: 当然。200 OK 表示请求成功;404 Not Found 表示资源未找到;500 Internal Server Error 表示服务器内部错误。
面试官: 好的,那forward和redirect的区别是什么?
求职者: forward是服务器内部的转发,客户端不知道;而redirect是一种客户端重定向,浏览器会收到新的URL并发起新请求。
面试官: 那么,你能解释一下Socket编程吗?
求职者: Socket编程主要是用于实现两台机器间的通信。通过创建socket,一台机器可以监听特定端口,另一台机器可以通过这个端口与之建立连接,实现数据的发送和接收。
面试官: 接下来,你怎么设计一个服务注册中心呢?
求职者: 设计服务注册中心,首先需要有一个中央存储来记录服务信息。服务启动时,会向注册中心注册自己的信息,包括服务地址、端口等。客户端则可以从注册中心查询服务信息,实现服务发现。我们还需要考虑服务健康检查和负载均衡等功能。
面试官: 最后一个问题,Spring Bean的生命周期是怎样的?
求职者: Spring Bean的生命周期大致可以分为几个阶段:实例化、属性填充、初始化前后的处理、以及销毁前的处理。在这个过程中,可以通过实现特定的接口或使用注解来自定义初始化和销毁的逻辑。
面试官: 嗯,你的解法很有逻辑性。你的技术背景和问题解答都非常出色。现在我们来谈谈一些更深入的问题。在数据库事务中,隔离级别有哪些,它们分别解决了什么问题?
求职者: 数据库事务的隔离级别主要有四种:读未提交(Read Uncommitted),读已提交(Read Committed),可重复读(Repeatable Read)和串行化(Serializable)。
读未提交级别可以防止事务中出现更新丢失,但是会导致脏读。
读已提交级别解决了脏读问题,但不能防止不可重复读和幻读。
可重复读级别能够防止不可重复读,但是仍然可能出现幻读。
最后,串行化是最高的隔离级别,它通过锁定事务相关的数据库表来避免脏读、不可重复读和幻读,但性能开销也最大。
面试官: 说得好。现在我们来聊聊网络,你能详细解释一下TCP和UDP的区别吗?
求职者: 当然可以。TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)都是传输层协议。TCP是一种面向连接的、可靠的、基于字节流的传输层通信协议,它提供了数据包顺序传输、数据完整性以及拥塞控制机制。而UDP则是一种无连接的协议,它不保证数据包的顺序、完整性或可靠性,但是它的传输速度更快,适用于对实时性要求高的应用,如视频流或在线游戏。
面试官: 我还有几个问题想问你。在设计大型系统时,如何确保系统的高可用性(High Availability)?
求职者: 为了确保系统的高可用性,我们可以采取几个策略。
首先,冗余是关键,我们可以通过多副本的数据和服务来避免单点故障。
此外,负载均衡能够分散流量,防止过载。
还有,故障切换和灾难恢复策略能够在系统出现故障时迅速恢复服务。
最后,定期的压力测试和监控系统能够帮助我们提前发现和解决潜在问题。
面试官: 很好。既然你提到了故障切换,那么你能解释一下蓝绿部署和滚动更新吗?
求职者: 当然。蓝绿部署是一种减少系统停机时间和风险的部署模式,它通过同时运行两个生产环境(蓝环境和绿环境)来实现。任何时间点,只有一个环境处理真实流量。更新时,会在闲置环境中部署新版本,然后通过切换流量来激活新环境。而滚动更新是逐步替换旧版本的实例,新旧版本会短暂共存,直到所有实例都更新为止,这样可以不中断服务地进行更新。
面试官: 那么,如何处理和避免数据库的膨胀问题?
求职者: 数据库膨胀通常是由于数据不断增长而未进行有效管理造成的。
处理这个问题,首先可以通过定期清理无用数据或旧数据来减小数据库大小。
其次,使用分区表技术可以将数据分布到不同的表中,这样可以提高查询效率并降低单个表的大小。
另外,归档策略可以将不常访问的数据转移到更低成本的存储上。
最后,适当的索引也能优化查询性能,减少不必要的数据扫描。
面试官: 接下来的问题是关于安全性的。你如何理解SQL注入攻击,以及如何防止它发生?
求职者: SQL注入攻击是攻击者利用应用程序中处理输入数据不当的漏洞,向后端数据库注入恶意SQL语句的一种攻击。为了防止SQL注入,我们应当始终使用参数化查询,这样可以确保输入数据不会被解释为SQL代码。此外,对输入数据进行严格的验证和转义,以及使用最小权限原则来限制数据库账户的权限,也是预防SQL注入的有效方法。
面试官: 很详细。最后一个技术问题,什么是内存泄漏,你如何诊断和解决这个问题?
求职者: 内存泄漏是指程序中已分配的内存由于某种原因未能释放,导致可用内存逐渐减少,最终可能导致程序运行缓慢或崩溃。为了诊断内存泄漏,我们可以使用诸如Valgrind、LeakSanitizer等工具来检测。解决内存泄漏的问题通常涉及对代码进行审查,找到并修复没有正确释放内存的部分。
算法题
面试官: 很好,现在,我想给你一个算法题,请你完成奇偶排序。可以吗?
求职者: 没问题,当然可以。奇偶排序(Odd-Even Sort)是一种简单的排序算法,类似于冒泡排序的变体。该算法通过比较相邻的奇偶索引对来工作,迭代直到数组完全排序。在每次迭代中,算法分两个阶段进行:第一阶段比较所有奇数索引和其下一个偶数索引的元素(即比较 a[i] 和 a[i+1],其中 i 为奇数),第二阶段比较所有偶数索引和其下一个奇数索引的元素(即比较 a[i] 和 a[i+1],其中 i 为偶数)。这两个阶段交替进行直到没有更多的交换为止。
下面是实现代码:
public class OddEvenSort {public static void oddEvenSort(int[] arr) {boolean isSorted = false; // Initially array is unsortedwhile (!isSorted) {isSorted = true;// Perform bubble sort on odd indexed elementfor (int i = 1; i <= arr.length - 2; i = i + 2) {if (arr[i] > arr[i + 1]) {swap(arr, i, i + 1);isSorted = false;}}// Perform bubble sort on even indexed elementfor (int i = 0; i <= arr.length - 2; i = i + 2) {if (arr[i] > arr[i + 1]) {swap(arr, i, i + 1);isSorted = false;}}}}// Utility function to swap two elements in an arraypublic static void swap(int[] arr, int i, int j) {int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}// Driver code to test abovepublic static void main(String[] args) {int[] arr = {3, 8, 5, 4, 1, 9, -2};oddEvenSort(arr);for (int i = 0; i < arr.length; i++)System.out.print(arr[i] + " ");System.out.println();}
}
面试官: 很不错的解法。接下来,我有一个新的算法题目给你,找出二叉搜索树中两个节点的最近公共祖先。你能尝试解答一下吗?
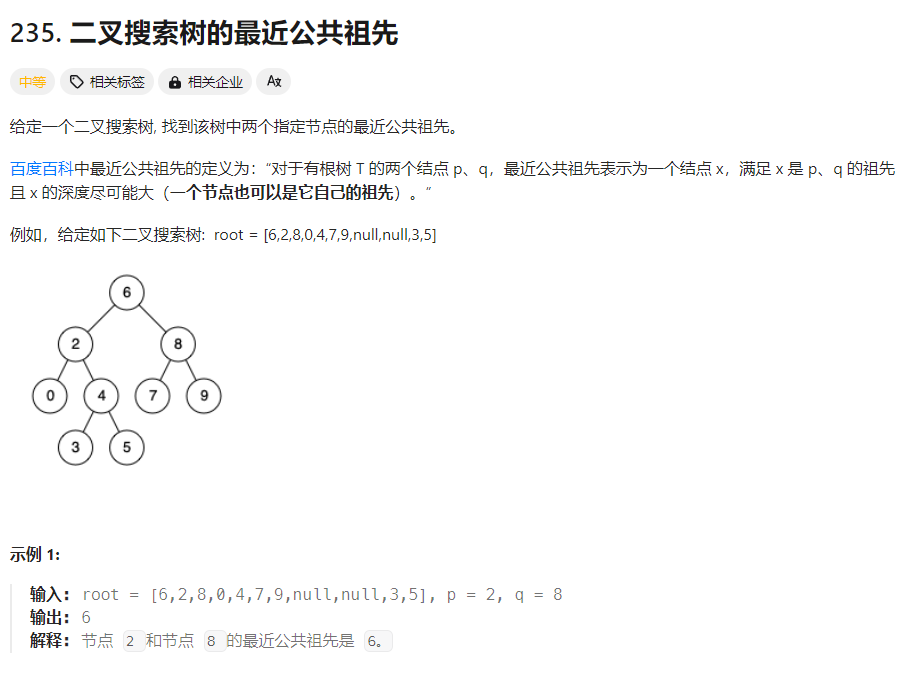
求职者: 当然,在二叉搜索树(BST)中,公共祖先指的是同时拥有两个节点作为后代(这里的后代包括节点本身)的最深的节点。在BST中,所有节点的左子树包含的值都小于当前节点的值,右子树包含的值都大于当前节点的值。
假设我们有两个节点 p 和 q,我们要找到它们的最近公共祖先 LCA。由于BST的性质,我们可以利用以下规则来找到它:
- 如果 p 和 q 的值都小于当前节点的值,那么 LCA 位于当前节点的左子树中。
- 如果 p 和 q 的值都大于当前节点的值,那么 LCA 位于当前节点的右子树中。
- 如果 p 的值小于当前节点的值而 q 的值大于当前节点的值,或者相反,那么当前节点就是 LCA。
定义二叉树节点类 TreeNode**:**
public class TreeNode {int val;TreeNode left;TreeNode right;TreeNode(int x) {val = x;}
}
实现寻找最近公共祖先的方法:
public class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {// 从根节点开始TreeNode current = root;while (current != null) {// 如果两个节点的值都小于当前节点的值,向左子树搜索if (p.val < current.val && q.val < current.val) {current = current.left;}// 如果两个节点的值都大于当前节点的值,向右子树搜索else if (p.val > current.val && q.val > current.val) {current = current.right;}// 发现分岔点,当前节点是最近公共祖先else {return current;}}return null; // 如果找不到,返回 null}
}
这个递归方法会在最坏情况下的时间复杂度是 O(h),其中 h 是树的高度,因为它每次都深入到树的下一层直到找到分岔点。对于平衡的二叉搜索树,时间复杂度是 O(log n),其中 n 是树中的节点数。对于非平衡树,时间复杂度可能更接近 O(n)。
面试官: 非常详细。那么,来到另外一个算法题部分,你能告诉我如何判断B是不是A的子树吗?
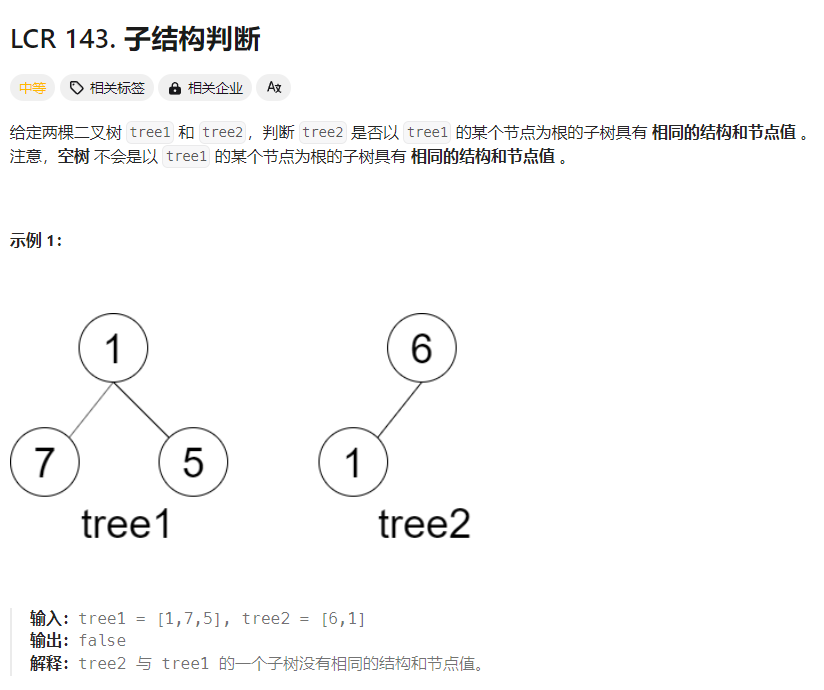
求职者: 要解决这个问题,我们可以按照以下步骤来思考:
- 遍历树 tree1:我们需要遍历 tree1 的每一个节点,将每个节点作为一个潜在的根节点,与 tree2 进行比较。
- 比较树:对于 tree1 中的每个节点,我们需要判断以该节点为根的子树是否与 tree2 完全相同。这需要一个递归函数来实现深度优先搜索,比较当前节点及其所有子节点的值。
- 递归比较节点:比较两个节点时,我们需要确认以下三个条件都满足:
-
当前两个节点的值相等。
-
当前节点的左子树与另一棵树的左子树相同。
-
当前节点的右子树与另一棵树的右子树相同。
首先,定义二叉树的节点类 TreeNode**:**
public class TreeNode {int val;TreeNode left;TreeNode right;TreeNode(int x) {val = x;}
}
然后,实现检查 tree2 是否是 tree1 的子树的方法:
public class Solution {public boolean isSubtree(TreeNode tree1, TreeNode tree2) {// 空树不是任何树的子树if (tree2 == null) {return false;}// 空树的子树为空树if (tree1 == null) {return false;}// 如果找到相同的根节点,检查子树是否相同if (isSameTree(tree1, tree2)) {return true;}// 在 tree1 的左子树和右子树中继续寻找 tree2return isSubtree(tree1.left, tree2) || isSubtree(tree1.right, tree2);}// 检查两棵树是否完全相同public boolean isSameTree(TreeNode p, TreeNode q) {// 如果两棵树都为空,那么它们相同if (p == null && q == null) {return true;}// 如果其中一棵树为空,另一棵不为空,它们不相同if (p == null || q == null) {return false;}// 如果当前节点的值不同,它们不相同if (p.val != q.val) {return false;}// 递归检查左子树和右子树return isSameTree(p.left, q.left) && isSameTree(p.right, q.right);}
}
这段代码定义了两个主要的方法:isSubtree 检查 tree2 是否是 tree1 的子树,而 isSameTree 用于比较两棵树是否完全相同。
通过递归地遍历 tree1 并对每个节点调用 isSameTree,我们可以判断 tree2 是否为 tree1 的子树。
这个解决方案的时间复杂度是 O(m*n),其中 m 和 n 分别是两棵树的节点数,因为我们需要在 tree1 中的每个节点上运行 isSameTree。
面试官: 好的,你的表现真的很棒。这次面试到此为止。如果有后续面试或者其他通知,我们会通过邮件或电话与你联系。再次感谢你的参与和分享。
![[华为OD] C卷 货运 老李是货运公司承运人,老李的货车额定载货重量为Wt 100](http://pic.xiahunao.cn/[华为OD] C卷 货运 老李是货运公司承运人,老李的货车额定载货重量为Wt 100)
,供大家学习研究参考~)
(免费下载))
)







)
)






教学解决方案)