selenium+Xpath
在与该ipynb文件同文件下新增一个111.xlsx,第一列放一堆需要爬虫的同样式网页
然后使用selenium+Xpath爬虫
from selenium import webdriver
from selenium.webdriver.common.by import By
import openpyxl
import timedef crawl_data(driver, url):driver.get(url)time.sleep(5) # 等待页面加载# 爬取指定的XPath内容xpath1 = '//*[@id="main"]/div/div/div[2]/div[1]/div/div[1]/div'xpath2 = '//*[@id="main"]/div/div/div[2]/div[1]/div/div[1]/p/span'xpath3 = '//*[@id="descriptionDiv"]/p'xpath4 = '//*[@id="introductionDiv"]/p'content1 = driver.find_element(By.XPATH, xpath1).textcontent2 = driver.find_element(By.XPATH, xpath2).textcontent3 = driver.find_element(By.XPATH, xpath3).textcontent4 = driver.find_element(By.XPATH, xpath4).textreturn content1, content2, content3, content4# 启动Chrome浏览器
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)# 打开Excel文件
file_path = "111.xlsx"
wb = openpyxl.load_workbook(file_path)
ws = wb.active# 获取第一列的网址
urls = [cell.value for cell in ws["A"]]# 逐个处理每个网址
for i, url in enumerate(urls, start=1):print(f"处理第{i}个网址: {url}")url_str = str(url) if url is not None else ""# 爬取数据data1, data2, data3, data4 = crawl_data(driver, url_str)# 写回Excel文件ws.cell(row=i, column=2, value=data1)ws.cell(row=i, column=3, value=data2)ws.cell(row=i, column=4, value=data3)ws.cell(row=i, column=5, value=data4)# 保存Excel文件
wb.save(file_path)# 关闭浏览器
driver.quit()
使用Xpath方法相比css定位的好处:如果页面的层级结构非常复杂,XPath提供了更复杂的选择和过滤方式,可以更灵活地定位元素
相比id、class定位的好处:XPath可以根据元素的属性值进行定位,这在某些情况下很有用,尤其是在没有独特标识符(如ID)的情况下
同样使用selenium其它定位的方法
按ID、类名
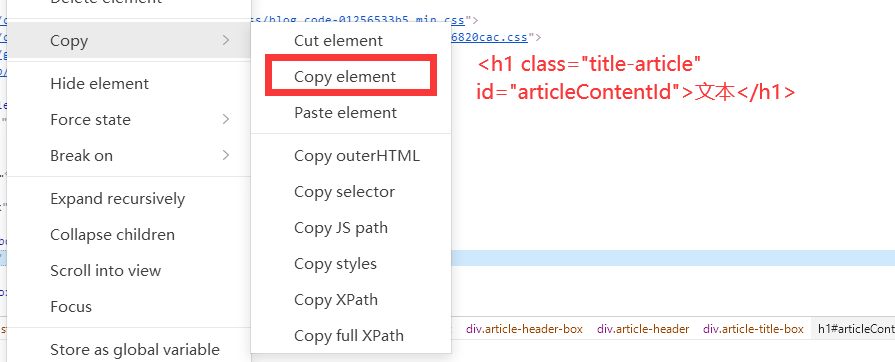
# 以ID定位元素
element_by_id = driver.find_element(By.ID, 'articleContentId')
print("Element by ID:", element_by_id.text)# 以类名定位元素
element_by_class = driver.find_element(By.CLASS_NAME, 'title-article')
print("Element by Class Name:", element_by_class.text)按css选择器
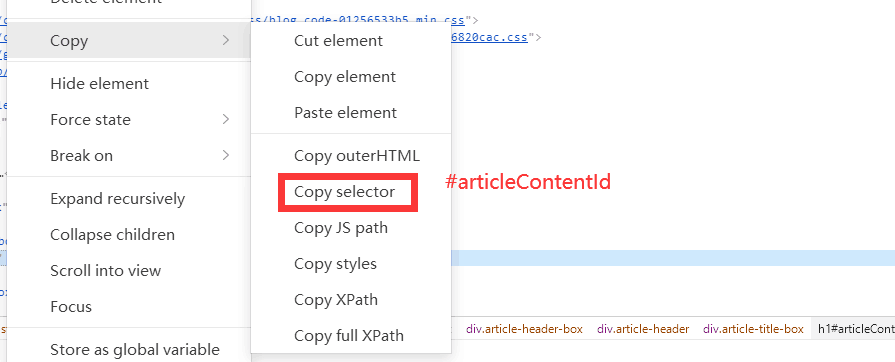
# 以CSS选择器定位元素
element_by_css = driver.find_element(By.CSS_SELECTOR, '#articleContentId')
print("Element by CSS Selector:", element_by_css.text)
不用selenium
Requests + BeautifulSoup
使用BeautifulSoup时,通常通过选择器(CSS选择器)而不是XPath来提取元素
import requests
from bs4 import BeautifulSoupurl = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')# 使用CSS选择器
title_element = soup.select_one('#articleContentId')
title = title_element.text if title_element else "Title not found"paragraphs = soup.select('#articleContentId + div.content p')# 输出结果
print(f"Title: {title}")
for paragraph in paragraphs:print(paragraph.text)
Scrapy
在Scrapy中,可以使用XPath或CSS选择器,具体取决于你的喜好或页面的结构。
XPath
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['https://example.com']def parse(self, response):# 使用XPathtitle = response.xpath('//*[@id="articleContentId"]/text()').get()paragraphs = response.xpath('//*[@id="articleContentId"]/following-sibling::div[@class="content"]/p/text()').getall()# 输出结果print(f"Title: {title}")for paragraph in paragraphs:print(paragraph)
css
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['https://example.com']def parse(self, response):# 使用CSS选择器title = response.css('#articleContentId::text').get()paragraphs = response.css('#articleContentId + div.content p::text').getall()# 输出结果print(f"Title: {title}")for paragraph in paragraphs:print(paragraph)
Pyppeteer / Playwright
使用Pyppeteer或Playwright时,你可以通过JavaScript在页面上执行脚本来获取数据,而不是直接使用XPath
XPath
from pyppeteer import launchasync def crawl_data(url):browser = await launch()page = await browser.newPage()await page.goto(url)# 使用JavaScript执行脚本获取内容title = await page.evaluate('document.evaluate("//*[@id=\"articleContentId\"]", document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue.textContent')paragraphs = await page.evaluate('Array.from(document.evaluate("//*[@id=\"articleContentId\"]//p", document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null)).map(p => p.textContent)')# 输出结果print(f"Title: {title}")for paragraph in paragraphs:print(paragraph)await browser.close()# 使用asyncio来运行异步代码
import asyncio
asyncio.get_event_loop().run_until_complete(crawl_data('https://example.com'))
element选择器
Element选择器实际上是通过HTML元素的标签名来选择元素,而不是通过ID或类名。
HTML元素的标签名就是元素的名称,通常是由尖括号括起来的部分。下述h1、p、a就是HTML元素的标签名
<h1>这是一个标题</h1>
<p>这是一个段落</p>
<a href="https://www.example.com">这是一个链接</a>
所以,如果你想使用element选择器,你可以这样修改代码:
from pyppeteer import launchasync def crawl_data(url):browser = await launch()page = await browser.newPage()await page.goto(url)# 使用JavaScript执行脚本获取内容title = await page.evaluate('document.querySelector("h1#articleContentId").textContent')paragraphs = await page.evaluate('Array.from(document.querySelector("h1#articleContentId + div.content").querySelectorAll("p")).map(p => p.textContent)')# 输出结果print(f"Title: {title}")for paragraph in paragraphs:print(paragraph)await browser.close()# 使用asyncio来运行异步代码
import asyncio
asyncio.get_event_loop().run_until_complete(crawl_data('https://example.com'))
在这个例子中,我们使用了document.querySelector("h1#articleContentId")来选择ID为articleContentId的h1元素,以及document.querySelector("h1#articleContentId + div.content").querySelectorAll("p")来选择与该h1元素相邻的div元素内的所有p元素。
css
from pyppeteer import launchasync def crawl_data(url):browser = await launch()page = await browser.newPage()await page.goto(url)# 使用JavaScript执行脚本获取内容title = await page.evaluate('document.querySelector("#articleContentId").textContent')paragraphs = await page.evaluate('Array.from(document.querySelectorAll("#articleContentId p")).map(p => p.textContent)')# 输出结果print(f"Title: {title}")for paragraph in paragraphs:print(paragraph)await browser.close()# 使用asyncio来运行异步代码
import asyncio
asyncio.get_event_loop().run_until_complete(crawl_data('https://example.com'))






)



)
)

)





