在本次 KubeCon 上,阿里云将为全球用户分享阿里巴巴超大规模云原生落地实践、云原生前沿技术与应用包括OpenKruise 开源项目、开放云原生应用中心(Cloud Native App Hub),同时将重磅发布边缘容器、云原生应用管理与交付体系等产品和服务。

“云原生应用自动化引擎”加持下的阿里“云原生”
随着云原生概念的兴起,越来越多的应用开始尝试在云原生的土壤上耕耘。那么什么是云原生,简而言之,云原生就是一套能够充分利用“云”的能力,高效构建与交付应用的方法论集合,使得应用容器化的用户可以充分的利用云的弹性、“不可变基础设施”等优势专注于自身核心业务价值。
当前,阿里巴巴基础设施的云原生演进与升级也正在如火如荼的进行。而在阿里巴巴上云的过程中,阿里内部在超大规模的互联网场景中,已经开始进行大量的云原生的理念落地实践,比如轻量级容器化,阿里巴巴经济体正在大规模推进应用的轻量级容器化,从而达成利用容器的敏捷、一致等特性快速构建符合云原生理念的电商站点交付的能力,适应类似“双十一”大促的严苛技术需求;再比如说云原生应用管理, 阿里巴巴经济体正在将 Kubernetes 等项目的应用编排与自动化能力,穿透到上层运维框架当中,驱动电商应用按照云原生的技术理念进行编排、交付和运行。
在阿里巴巴经济体的整体云原生化过程当中,阿里的技术团队逐渐沉淀出了一套紧贴上游社区标准、适应互联网规模化场景的技术理念与最佳实践。这其中,最重要的无疑是如何对应用进行自动化的发布、运行和管理。
OpenKruise:来自阿里经济体云原生化历程的宝贵经验与最佳实践
在 KubeCon 上海,阿里云容器平台团队正式宣布了重量级项目 - OpenKruise(以下简称Kruise)的开源。
Kruise 是 cruise的谐音,'k' for Kubernetes. 字面意义巡航,豪华游艇。寓意Kubernetes上应用的自动巡航,满载阿里巴巴多年应用部署管理经验。
Kruise 的目标是automate everything on Kubernetes ! Kruise 项目源自于阿里巴巴经济体应用过去多年的大规模应用部署、发布与管理的最佳实践,源于容器平台团队对集团应用规模化运维,规模化建站的能力,源于阿里云Kubernetes服务数千客户的需求沉淀。Kruise 借力于云原生社区,集成阿里巴巴云原生实践之精华,反哺社区,指引业界云原生化最佳实践,少走弯路。
Kruise 核心在于自动化,我们将从不同维度解决 Kubernetes之上应用的自动化,包括,部署,升级,弹性扩缩容,Qos调节,健康检查,迁移修复等等。此次Kruise开源的内容主要在应用部署,升级方面,即一套增强版controller组件用于应用的部署和级和运维。后续,Kruise会依次开源智能化的弹性扩缩容组件,以及应用Qos自调节能力的组件等。
Kruise Controllers:将 Kubernetes 的“控制器模式”进行到底
以下内容主要介绍 Kruise Controllers - 一套用于 Kubernetes 之上应用自动化部署管理的 controller 组件。众所周知,Kubernetes 项目的核心原理,就是“控制器模式”。目前,Kubernetes 项目默认已经提供了一套 Controller 组件,例如 Deployment, Statefulset, DaemonSet 等,这些 Controller 提供了比较丰富的应用部署和管理功能。但是,随着 Kubernetes 的使用范围越来越广,真实的企业与规模性场景中的业务诉求与上游 Controller 功能不匹配的情况也越来越常见。以阿里巴巴为例:阿里巴巴内部的 Kubernetes 集群需要服务涵盖50几个 BU,上万种应用。这个体量非常庞大,对规模性和高可用性带来了巨大的挑战。与此同时,阿里云上的 Kubernetes 服务也接入了上千家企业客户,收集并支撑了各种各样的客户需求。这些诉求与最后阿里经济体的实践经验,最终促成了 Kruise 开源项目的诞生。
Kruise 第一期开源主要包含以下 Controller,后续会加入更多。
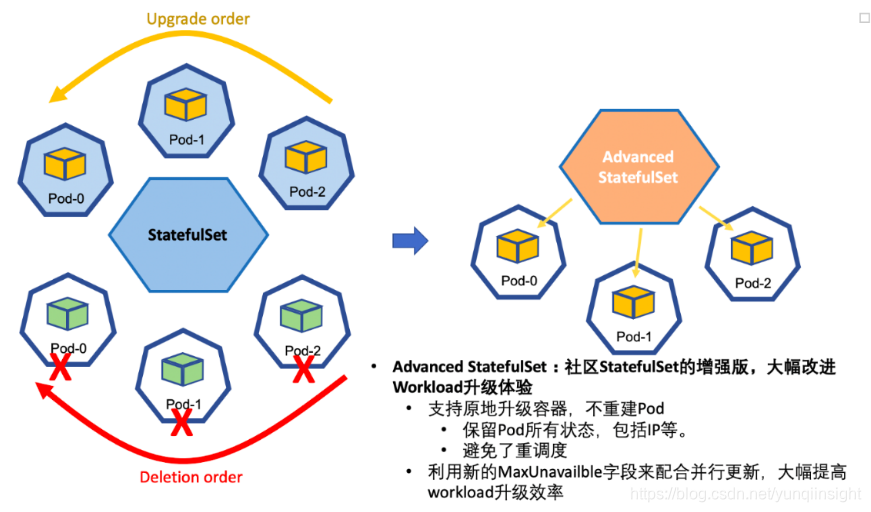
Advanced StatefulSet - 具备丰富发布策略、支持原地升级的 StatefulSet
Advanced StatefulSet 扩展了原生的 StatefulSet,加入了两个新的特性。
1)原地升级 (In-place update strategy)原生的 StatefulSet 在做 rolling update 的时候会销毁并且重建 pods. 这在阿里巴巴规模体量的场景下,代价巨大。
a) 首先,所有被删除的应用的Pods需要被重新调度一遍,由于pod数量大,这对调度带来了不必要的开销,更糟的是,重新调度的pod无法正常被调度,由于资源被占用,亲和特性等其他原因。Pod被重新调度到新的node上,损失了原来的本地 state, 虽然通常可以被重建,但是还是带来额外开销。
b) 重调度后的 pods 很有可能分布在不同的机器上,由于网络拓扑结构的改变,需要重新申请IP, 有些依赖IP保持的应用无法正常工作,此外,对网络流量的传输带来了不确定性。
c) 针对多容器的 Pod, 升级 sidecar 容器而导致主容器重建,通常是不可接受的。
Advanced StatefulSet 引入了原地升级功能,允许在不销毁pod的情况下,更新容器 image。这样带来的好处是,效率和稳定性。效率很明显,pod 不需要被重新调度了,还是跑在原来的node,一些本地存储state还是可以保留。稳定性体现在 IP 保持,网络拓扑以及流量结构基本不变,稳定性在阿里巴巴及阿里云经济体中一直以来是一个极其重要的指标。
2)允许最大不可用实例的配置(Max Unavailable)
社区原生的 StatefulSet 在升级的过程中是不允许同时升级多个实例的,这主要是为了某些有状态应用需要依次按序升级的需求。但是,从阿里巴巴场景,以及阿里云容器平台之上的客户了解到,许多应用不需要依次按序升级的语义,这样带来的问题是效率太低。特别是像阿里巴巴一些应用实例数巨大的场景,问题尤其显著。MaxUnavailable 的功能正式为了解决这个问题,它允许应用实例被并行升级,且保持始终保持最大不可用的实例数不超过 MaxUnavailable 的限制数。
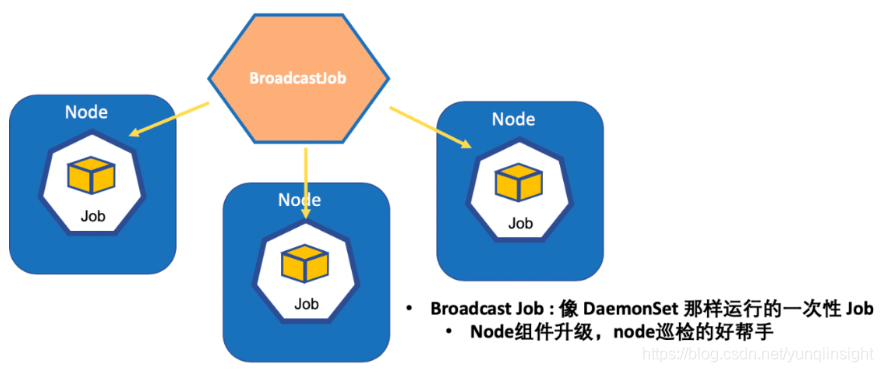
Broadcast Job - 像 DaemonSet 那样运行的一次性 Job
Broadcast Job 会在集群中每个node上面跑一个pod直至结束。类似于社区的DaemonSet, 区别在于DaemonSet始终保持一个pod长服务在每个node上跑,而BroadcastJob中最终这个pod会结束。相比DaemonSet,Broadcast结束后不再占用资源,这在某些场景中特别适用,比如升级node中某些组件,检测node上一些配置是否正确等。
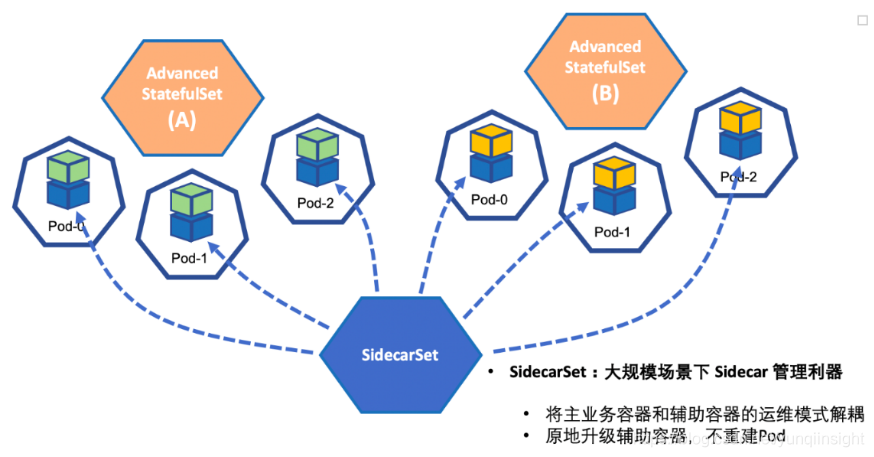
SidecarSet - 大规模场景下 Sidecar 管理利器
Sidecar 在Kubernetes中是一个辅助容器的概念,和主容器跑在同一个pod中。Sidecar容器一般是一些基础服务组件如monitoring容器,log collection容器等。在一个公司中,主业务容器,和基础组件容器通常由不同的团队开发和维护,多个团队同时操作和修改同一份yaml文件,同一个API资源对象,时常会产生一些冲突,且不便于管理。SidecarSet的理念在于将主业务容器和辅助容器的运维模式解耦。当业务用户提交应用时,不需要显示指定sidecar容器,由sidecar容器相应的团队编写规则负责自动注入。并且在容器运维和升级时候,利用Advanced Statefulset 原地升级的功能,业务团队,和基础架构团队分别按照自己定义的策略升级各自相应的容器,而不需要耦合在一起升级,产生不必要的影响。Istio 其实采用类似的思想自动给业务容器注入sidecar容器的功能,但是其缺乏sidecar容器后续升级运维的能力。SidecarSet有效地把Sidecar容器的部署和管理抽象出来。
OpenKruise 正在面向开源社区招募合作伙伴与子项目!
Kruise 社区的准则,是基于Kubernetes 的核心技术理念来构建更强大的自动化能力。目前,Kruise 正在计划发布更多的Controller来覆盖更多的场景和功能比如丰富的发布策略,金丝雀发布,蓝绿发布,分批发布等等。
更为重要的是,OpenKruise 是一个 Umbrella 项目,OpenKruise 的维护者们,正以最开放的姿态面向全球招募合作伙伴和贡献者。没错,我们非常期待您能够为 OpenKruise 贡献和共建新的自动化能力,或者一起来共同推 Kubernetes 云原生应用编排能力的演进与发展。
原文链接
本文为云栖社区原创内容,未经允许不得转载。



















