基本概念
概述
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习中常用于处理具有网格结构数据的神经网络模型。它在计算机视觉领域广泛应用于图像分类、目标检测、图像生成等任务。
核心思想
CNN 的核心思想是通过利用局部感知和参数共享来捕捉输入数据的空间结构信息。相比于传统的全连接神经网络,CNN 在网络结构中引入了卷积层和池化层,从而减少了参数量,并且能够更好地处理高维输入数据。
其他概念
输入层:接收原始图像或其他形式的输入数据。
卷积层(Convolutional Layer):使用卷积操作提取输入特征,通过设置滤波器(卷积核)在输入数据上滑动并执行卷积运算。这样可以学习到局部的特征,如边缘、纹理等。
激活函数(Activation Function):在每个卷积层后面通常紧跟一个非线性的激活函数,如ReLU(Rectified Linear Unit),以增加网络的非线性表达能力。
池化层(Pooling Layer):通过减少特征图的尺寸来降低模型复杂性。常用的池化操作是最大池化(Max Pooling),它选取每个池化窗口内的最大特征值作为输出。
全连接层(Fully Connected Layer):将卷积层和池化层的输出连接到全连接层,使用传统的神经网络模式进行分类、回归等任务。
Dropout 层:在训练过程中以一定概率随机将部分神经元的输出置为0,以减少模型的过拟合。
Softmax 层:多分类问题中常用的输出层,在最后一层进行 softmax 操作将输出转化为类别上的概率分布。
代码与详细注释
import os# third-party library
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt# torch.manual_seed(1) # reproducible# Hyper Parameters
# 轮次
EPOCH = 1 # train the training data n times, to save time, we just train 1 epoch
# 批大小为50
BATCH_SIZE = 50
# 学习率
LR = 0.001
# 是否下载mnist数据集
DOWNLOAD_MNIST = False# 下载minist数据集
if not(os.path.exists('./mnist/')) or not os.listdir('./mnist/'):# not mnist dir or mnist is empyt dirDOWNLOAD_MNIST = True# torchvision本身就是一个数据库
train_data = torchvision.datasets.MNIST(root='./mnist/',train=True, # this is training datatransform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]download=DOWNLOAD_MNIST,
)# 输出训练数据尺寸
print(train_data.train_data.size()) # (60000, 28, 28)
# 输出标签数据尺寸
print(train_data.train_labels.size()) # (60000)
# 展示训练数据集中的第0个图片
plt.imshow(train_data.train_data[0].numpy(), cmap='gray')
# 图片的标题是标签
plt.title('%i' % train_data.train_labels[0])
plt.show()# Data Loader for easy mini-batch return in training, the image batch shape will be (50, 1, 28, 28)
# 批大小为50,shuffle为True意思是设置为随机
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)# pick 2000 samples to speed up testing
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
# 使用unsqueeze增加一个维度
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
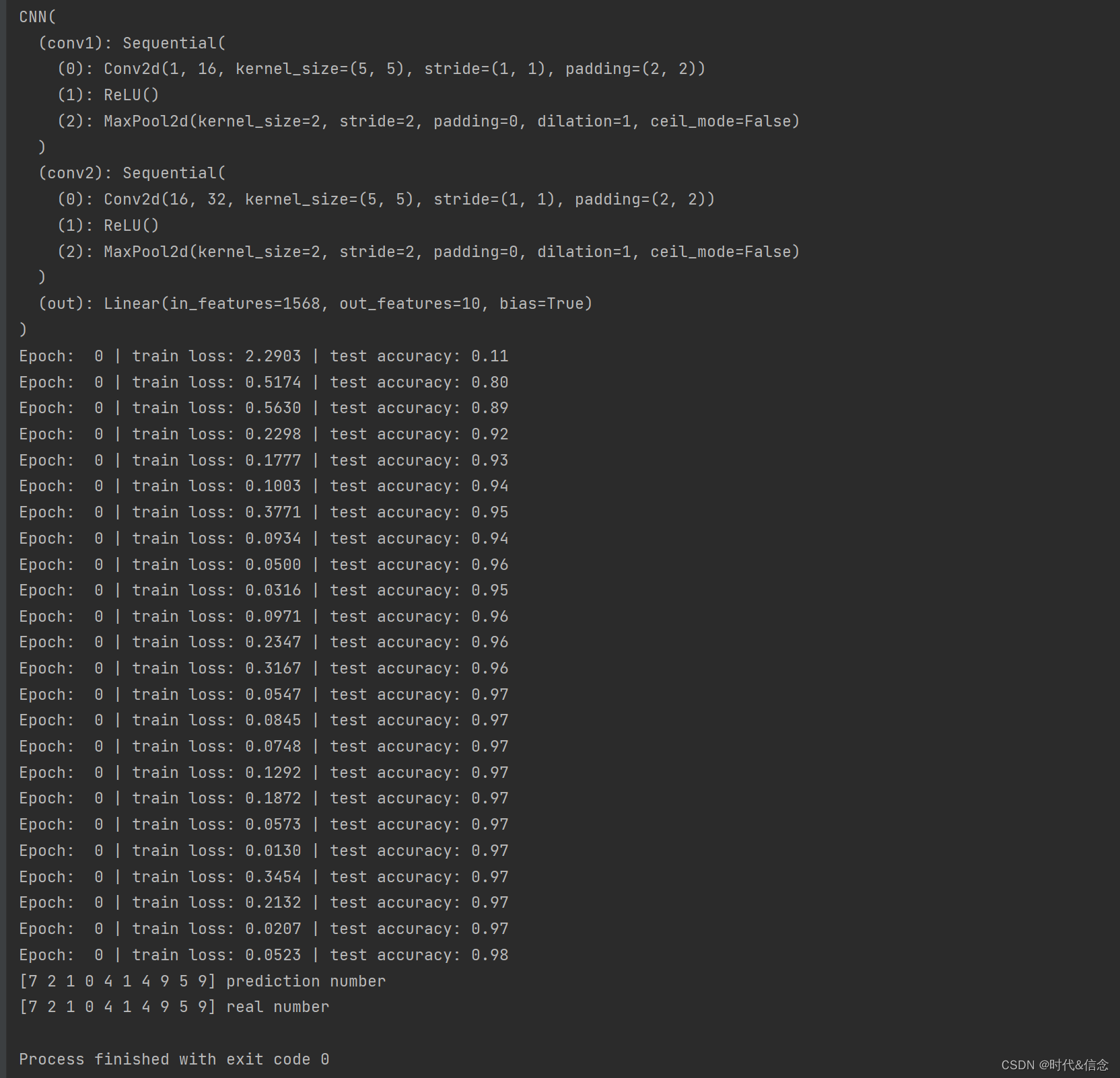
test_y = test_data.test_labels[:2000]class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()# 快速搭建神经网络self.conv1 = nn.Sequential( # input shape (1, 28, 28)nn.Conv2d(in_channels=1, # input heightout_channels=16, # n_filterskernel_size=5, # filter sizestride=1, # filter movement/steppadding=2, # if want same width and length of this image after Conv2d, padding=(kernel_size-1)/2 if stride=1), # output shape (16, 28, 28)nn.ReLU(), # activationnn.MaxPool2d(kernel_size=2), # choose max value in 2x2 area, output shape (16, 14, 14))self.conv2 = nn.Sequential( # input shape (16, 14, 14)nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)nn.ReLU(), # activationnn.MaxPool2d(2), # output shape (32, 7, 7))self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes# 前向传播def forward(self, x):# 第一层卷积x = self.conv1(x)# 第二层卷积x = self.conv2(x)x = x.view(x.size(0), -1) # flatten the output of conv2 to (batch_size, 32 * 7 * 7)output = self.out(x)return output, x # return x for visualizationcnn = CNN()
print(cnn) # net architecture# 选择优化器
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
# 选择损失函数
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted# following function (plot_with_labels) is for visualization, can be ignored if not interested
from matplotlib import cm
try: from sklearn.manifold import TSNE; HAS_SK = True
except: HAS_SK = False; print('Please install sklearn for layer visualization')
def plot_with_labels(lowDWeights, labels):plt.cla()X, Y = lowDWeights[:, 0], lowDWeights[:, 1]for x, y, s in zip(X, Y, labels):c = cm.rainbow(int(255 * s / 9)); plt.text(x, y, s, backgroundcolor=c, fontsize=9)plt.xlim(X.min(), X.max()); plt.ylim(Y.min(), Y.max()); plt.title('Visualize last layer'); plt.show(); plt.pause(0.01)plt.ion()# training and testing
for epoch in range(EPOCH):for step, (b_x, b_y) in enumerate(train_loader): # gives batch data, normalize x when iterate train_loaderoutput = cnn(b_x)[0] # cnn outputloss = loss_func(output, b_y) # cross entropy lossoptimizer.zero_grad() # clear gradients for this training steploss.backward() # backpropagation, compute gradientsoptimizer.step() # apply gradientsif step % 50 == 0:test_output, last_layer = cnn(test_x)pred_y = torch.max(test_output, 1)[1].data.numpy()accuracy = float((pred_y == test_y.data.numpy()).astype(int).sum()) / float(test_y.size(0))print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.numpy(), '| test accuracy: %.2f' % accuracy)if HAS_SK:# Visualization of trained flatten layer (T-SNE)tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)plot_only = 500low_dim_embs = tsne.fit_transform(last_layer.data.numpy()[:plot_only, :])labels = test_y.numpy()[:plot_only]plot_with_labels(low_dim_embs, labels)
plt.ioff()# print 10 predictions from test data
test_output, _ = cnn(test_x[:10])
pred_y = torch.max(test_output, 1)[1].data.numpy()
print(pred_y, 'prediction number')
print(test_y[:10].numpy(), 'real number')运行结果





)





 剑指 Offer 09. 用两个栈实现队列 ——【Leetcode每日一题】)
-利用银行取钱和存钱两个任务举例)
)



)


