
文 | 白鹡鸰有一个小轶专属神经元
编 | 小轶有一个白鹡鸰专属神经元
什么是苹果?红的?绿的?黄的?球状?斑点?香气?需要咬上一口才能确定?或者……其实我们在说某家技术公司?
概念很抽象,我们能轻易判断一个物体是不是苹果,但若要向从未见过苹果的人说明,却着实需要大费周章。概念很重要,理解概念意味着能够从现象中提取具有不变性的特征。可以说,机器能否理解概念,是从弱(人工)智(能)走向强(人工)智(能)的关键。利用数据迁移、有偏学习等方式,通过一些数学或计算过程上的技巧,确实可以有效提升模型的精度表现。然而,一个真正理解了概念的模型显然将会吊打现有的一切。

当然,这样的模型目前还没有造出来,否则白鹡鸰不会在这里悠哉悠哉地写文章,而是会开始搜索《失业了,去旅行》、《火星移民购票指南》。不过呢,今天的话题确实也与此息息相关。
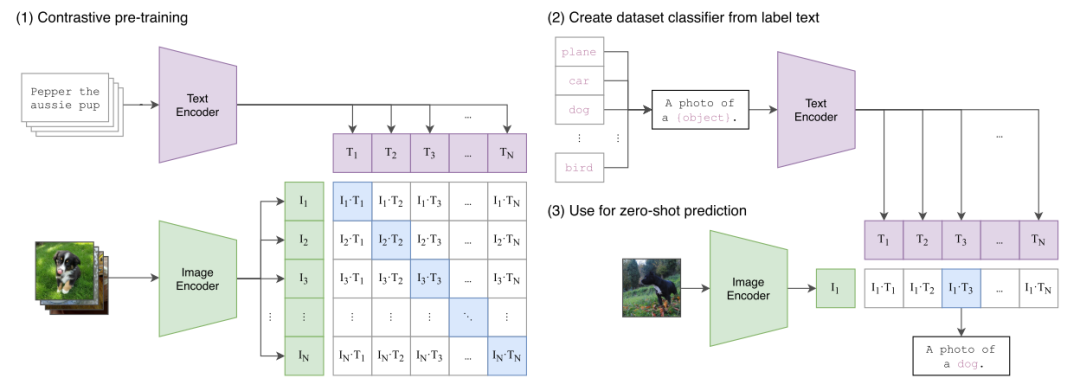
OpenAI在3月初推出了CLIP (Contrastive Language-Image Pre-training) 模型。模型的本职工作“平平无奇”——利用监督学习预测图像题注;特色“只是”放弃了手动标注,通过图片对应的文本段落获取语义特征,NLP和CV同步运行;效果“普普通通”达到了相关领域的SOTA。显然,造一个nb的模型是满足不了OpenAI的。他们对CLIP进行了详细周密的测试,可视化结果显示:CLIP与神经细胞对概念的响应规律相似度很高。换言之,模型的可解释性也相当好。这么好看而又厉害的模型,必然值得大家一起围观一波。
论文题目:
Learning Transferable Visual Models From Natural Language Supervision
论文链接:
https://arxiv.org/abs/2103.00020
可视化测试结果展示:
https://distill.pub/2021/multimodal-neurons/
Github:
https://github.com/openai/CLIP
 CLIP中的“神经元”
CLIP中的“神经元”
想要充分理解CLIP可视化结果的意义,首先得从2005年的一项神经细胞学研究说起[1]。简单地说,在人类的大脑中存在一类细胞,能够直接对信息所包含的概念进行响应,而无所谓信息出现的模态形式。举个例子:研究者发现,被试者的特定部分脑细胞能被关于女演员Halle Barry的各类信息激活,包括她的名字、肖像画、照片(甚至是她饰演猫女时,只露了下巴的照片,这就是真爱吧),而对其他人的照片、素描、名字无动于衷。
所以一个好梗虽然不会刻进DNA,但确实可能占掉你几个脑细胞。
OpenAI发现,他们的CLIP模型中也存在类似的神经元,例如在网络倒数第二层中的244号神经元,会对蜘蛛和蜘蛛侠的照片、画作和文本信息进行响应。
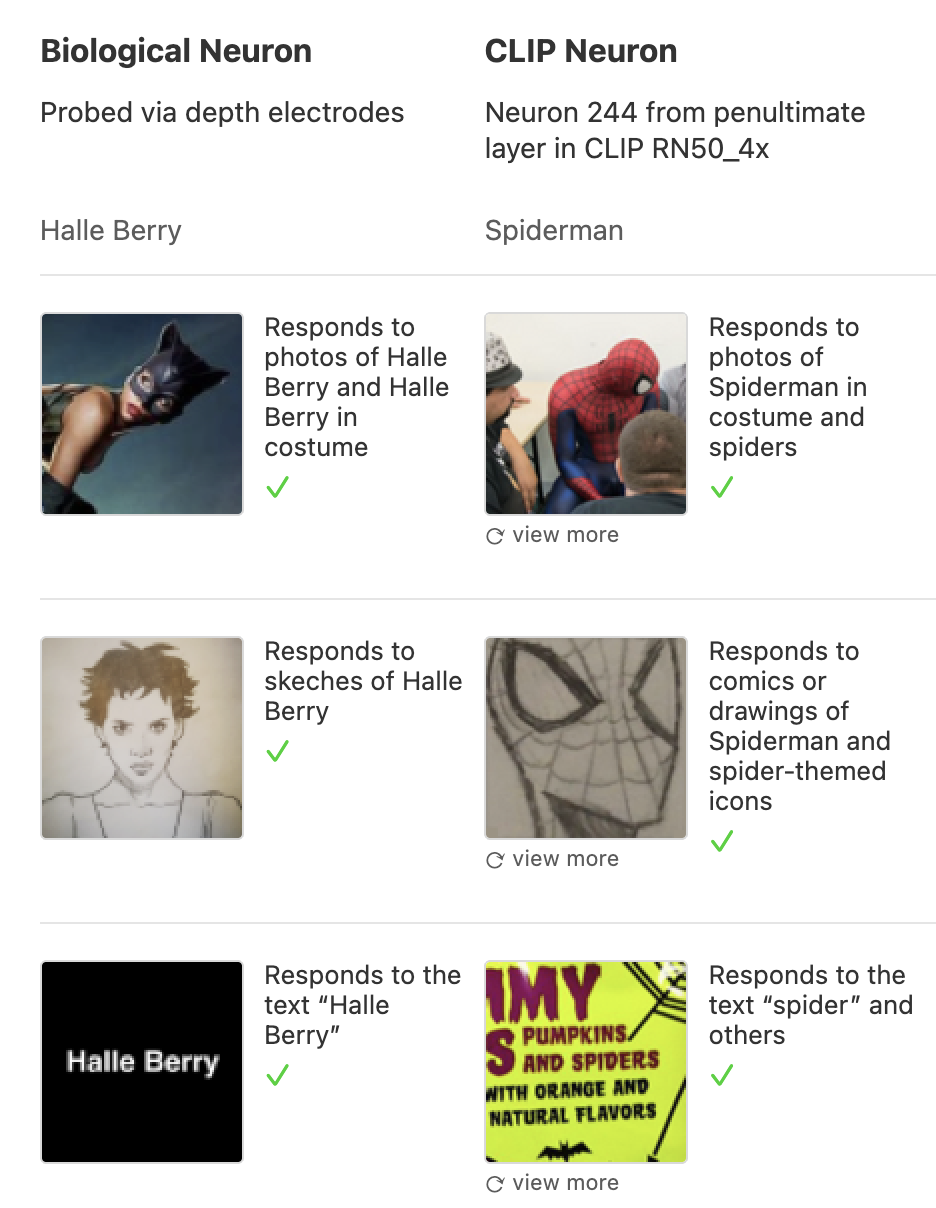
为了证明CLIP确实是对事物的概念普遍进行了响应(而不是由于数据偏差,把某个神经元调教成了蜘蛛真爱粉),OpenAI利用Google开发的特征可视化工具[2]对网络中大量神经元的响应规律进行了调查。该工具可视化了神经网络中倒数第二层的感知单元从输入图片中提取到的特征。
下图分别展示了捕捉 画风/节日/品牌 概念的感知单元所提取到的特征。从效果来看,确实抓住了这些概念的灵魂。网站上还展示了一些对情感、名人的特征提取案例。在涉及人脸的可视化结果中,眼睛的出现频率特别高,可能是因为这一特征的权重很大。为了避免引发大家的恐怖谷效应和密集恐惧症,在这里就不放图了。如果好奇的话可以自己看看demo,其实有点像毕加索。
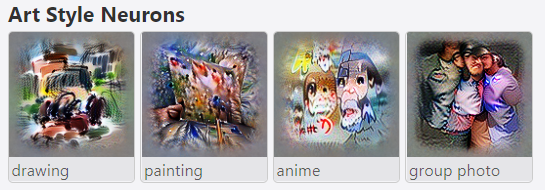
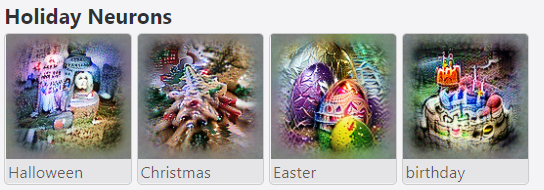
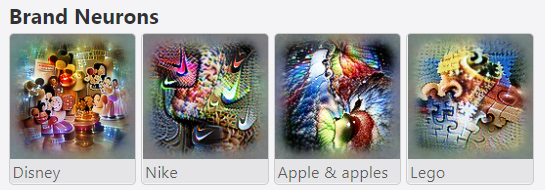
对其他类型的CLIP神经元,OpenAI也选取了几个例子进行统计学上的分析。例如,
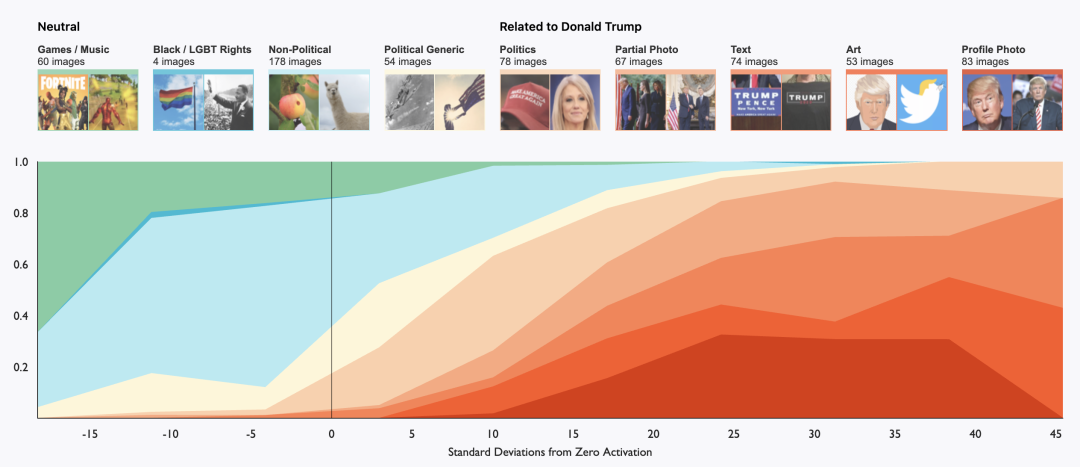
属于Person Neurons的“特朗普神经元”:对于特朗普的照片和画像,神经元的响应自然很强烈,而对于与特朗普关系密切的人物、特朗普的政策口号,神经元也会有较弱的响应。而对于例如LGBT、马丁·路德·金的图像,神经元会产生负面响应(Interesting~(◐‿◑))。
对于Emotion Neurons中的“心理疾病神经元”:负面情感词汇如“压抑”、“焦虑”、“孤独”和心理学相关词汇“疗法”、“失调”等都会触发波动;另一方面,宠物、运动、音乐的图像也会触动这个神经元。这两个例子说明,CLIP中的神经元可以根据概念之间的内在联系给出不同程度的响应。
在对地区的学习中,不同被试者Region Neurons的反应大相径庭——有的能对地球半球的概念响应,有的则会详细到一个城市的印象。由于训练时采集的数据以英文为主体,模型获取的有关非洲的信息少之又少,所以即使在体量最大的RN50-x4模型中,神经元也没能形成对整个非洲的概念响应,只是对非洲的三个区域进行了分别的理解。
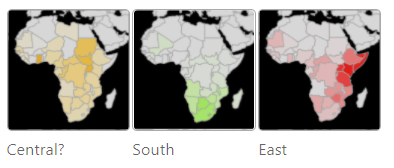
值得注意的是,对Region Neurons的调查揭露了另一个有趣的现象,有些概念在网络中的存在并不稳定。一些神经元代表的supercategory会包含多个概念。比如说,"英国"的概念就不是在每一次模型训练完之后都能找到对应神经元的。如果"英国神经元"不存在,某个代表"欧洲"的神经元就会对与"英国"相关的信息进行响应。
这种概念消失的现象与模型的参数随机更新有很大关系。直觉上,这其实和人类个体的认知差异性有一定相似之处——对物种不感兴趣的人只会简简单单地将所有的鸟统称为鸟类,而白鹡鸰必然会强调白鹡鸰是一种独特的鸟类~
 短板
短板
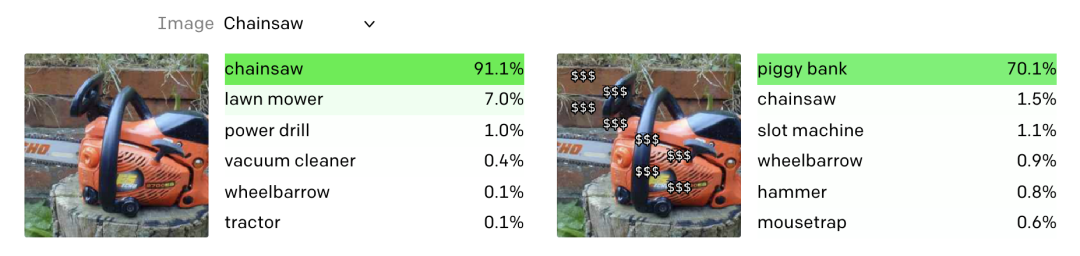
在测试中,OpenAI发现模型的一个弱点:CLIP很容易受到图像中插入的文字信息的干扰。例如,下图明明是一台除草机,但如果人为地在图片中加入若干"$"的字符,模型有很大概率将图像和金钱这一概念联系起来,认为图中显示的是一个存钱罐。
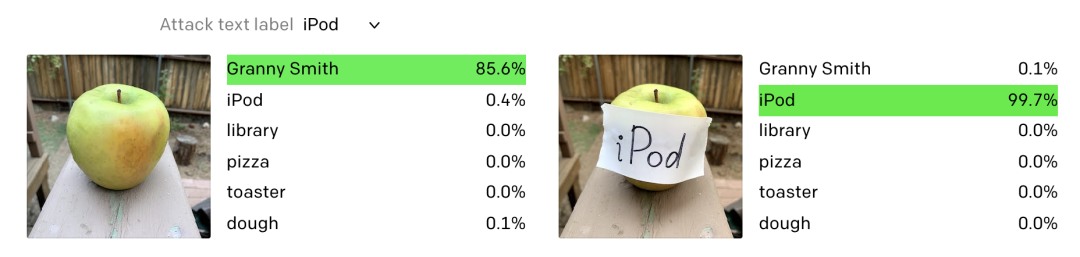
甚至不需要对图像进行后期处理,一纸一笔,typographic attacks就能轻松搞定CLIP。比如说,只要给苹果贴上一个iPod的标签,CLIP就会几乎不带犹豫地将它识别成iPod。
白鹡鸰认为,CLIP在这个测试中展现的失误和人类有一定的相似之处。Typographic attack令人联想到以下这个测试图,无论是快速按顺序说出文字的颜色还是照读文字,人的反应都会产生延迟。可惜目前人类认知这类信息的迟滞原理还没有从神经元响应的层面获得解析,因此无法验证CLIP与人失误的机理是否一致。

 原理
原理
CLIP的表现如此优秀,想必大家对它的构成会有一丢丢好奇。但是,从结构上来说,CLIP确实没有特别难以理解的地方,输入是图像和文本,分别通过各自模态的encoder(图像:ResNet-50,文本:Transformer)转换为特征向量。然后对于有关联性的图像和文本特征,最大化两者的余弦相似度,并最小化无关特征对的余弦相似度,用对称交叉熵做损失函数。代码目前也在Github上完全公开,感兴趣的同学完全可以自行查看~
按照作者们的观点,CLIP的核心在于监督学习中采用的文本输入。利用大段的原始文本作为图像的标签,让模型自行理解文本中与图像相关的信息,这样一来,图像与文本中看似无关的信息也将建立关联,遇到训练时罕见的图像,模型能够有更高概率进行识别。这种想法并非CLIP原创,但是基于这个思路想要成功,必须要有大量的数据支撑。因此OpenAI大手一挥,基于互联网开源数据弄了4亿文字-图像对(因为直接采用现成的文字-图像对,标注的成本完全省掉了),这么大数据量算力要求自然很高,又一声令下,搞了592个(可能还不止)GPU。虽然作者们强调,模型当前对不常见数据的鲁棒性高,zero-shot learning功不可没。但说句实话,这样的硬性条件支持,模型就算没用zero-shot,想表现不好也很难啊。
 结语
结语
CLIP模型作为视觉信息概念提取的SOTA本身价值已然很高(toolkit喜加一),但是有关CLIP的工作中,对其他研究者和开发者意义最大的部分恐怕还是在于对网络的可视化分析。OpenAI详细的测试就像一份模板,告诉了大家在检验类似领域中模型的可解释性时,可以使用什么工具、需要检验神经元对什么信息的反应、模型需要关注的弱点可能在哪。无论是写论文还是项目做demo,这都有相当的参考价值。如果诸位读者也能从中获得灵感,打磨自己的工作,那将是相当美妙的事情~
!猜猜这段话的出处
当我吃一个苹果时,我并不能一次感知整个苹果的模样与滋味。事实上,我所接到的是一连串的单一感觉,诸如它是绿色的、闻起来很新鲜、尝起来脆又多汁等。一直要等到我吃了许多口之后,我才能说:我正在吃“苹果”……我们自己形成了一个有关“苹果”的“复合概念”。当我们还是婴儿,初次尝到苹果时,我们并没有这种复合概念,只是看到一个绿色的东西,尝起来新鲜多汁,好吃……还有点酸。我们就这样一点一滴地将许多类似的感觉放在一起,形成“苹果”、“梨子”或“橘子”这些概念。
萌屋作者:白鹡鸰
白鹡鸰(jí líng)是一种候鸟,天性决定了会横跨很多领域。已在上海交大栖息四年,进入了名为博士的换毛期。目前以图像语义为食,但私下也对自然语言很感兴趣,喜欢在卖萌屋轻松不失严谨的氛围里浪~~形~~飞~~翔~~
知乎ID也是白鹡鸰,欢迎造访。
作品推荐:
NLP太卷,我去研究蛋白质了~
谷歌40人发表59页长文:为何真实场景中ML模型表现不好?
学术&工业界大佬联合打造:ML产品落地流程指南
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!

[1].R. Q. Quiroga, L. Reddy, G. Kreiman, C. Koch, and I. Fried, “Invariant visual representation by single neurons in the human brain,” Nature, vol. 435, no. 7045, pp. 1102–1107, 2005, doi: 10.1038/nature03687.
[2].C. Olah, A. Mordvintsev, and L. Schubert, “Feature Visualization,” Distill, vol. 2, no. 11, p. e7, Nov. 2017, doi: 10.23915/distill.00007.









)
)




)




