
大家好,今天我们分享一篇来自于ECCV 2020的论文《AiR: Attention with Reasoning Capability》。这篇论文主要研究的是在视觉推理过程中,人和机器的注意力在时域上的渐进变化。
论文代码github.com一. 论文的动机
现有的工作在视觉任务中,例如图片描述生成(Image captioning)和视觉问答(Visual question answering),广泛应用了注意力机制(Attention),通过关注重要的视觉区域,来增加决策过程的可解释性,提升模型的表现。
本文作者认为,在视觉推理中,人需要一边看一边进行推理,在捕捉视觉线索的同时进行推理、然后继续看继续推理,直到最后得到答案。从人身上得到启发,对于模型来说,关注不同的视觉区域和推理也应该是一个互相交织的过程。

如图,在视觉问答任务中,给出一个问题“Is there a bag to the left of the girl that is wearing jeans?”,我们解题时关注的焦点(Regions of interest,ROIs)会随着推理过程的推进不断变化:先找图中的牛仔裤,再关联到穿牛仔裤的小女孩,然后看向她的左边,寻找背包,找到背包时就能知道答案是“yes”。
基于上述想法,作者将推理过程细分成一系列推理步骤,在每个步骤显式地监督机器去关注对应的的焦点区域,使其以一种循序渐进的方式完成整个推理,最后得到答案。
二. 论文的贡献
本文主要贡献是将推理过程打散成一系列原子操作,提出了一个将attention和reasoning整合在一起的框架,具体内容分为以下四个方面:
- 提出了一个可以定量评估推理过程中模型attention准确率的指标(AiR-E),而之前的工作一般都只能定性衡量attention;
- 提出了一个显式约束模型attention的方法,能在整个推理过程中逐步优化attention(AiR-M);
- 收集了一个VQA任务上的眼动数据集(AiR-D),以便定量的去建模人的注意力,进一步用于机器attention的比较和诊断
值得注意的是,本文的题目具有一定的混淆性,这篇论文的重心并不是介绍一个精妙的带推理能力的attention结构,而是做了大量丰富的实验和分析,探究了在推理过程中,人和机器attention的差异、在时空域上的变化、以及和任务表现之间的关系。接下来,我们就具体来看这四部分内容。
三. 准备工作
为了更好地理解后面作者设计的指标和模型,我们先简单地介绍一下本文使用的数据集和前期数据处理工作。
这篇论文主要是在研究VQA任务中的视觉推理过程,使用了GQA数据集[1]。GQA数据集中图片对应的问题是由模板自动生成的。
其中,每张图片都对应于一个Dense Scene Graph(如下图),这部分的标记数据主要来自Visual Genome数据集。
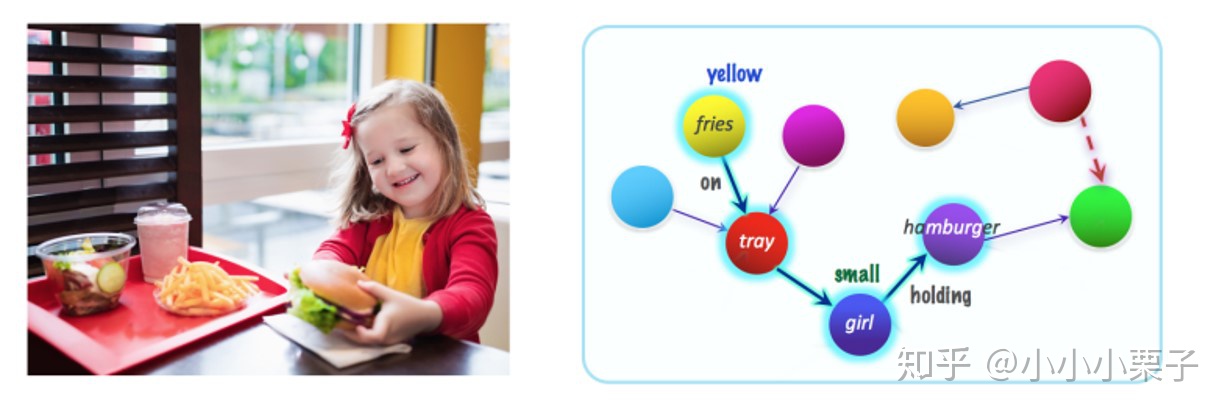
同时每个问题都对应一个functional program,它罗列了得出答案需要经过的一系列推理步骤,如下所示。

因为本文想研究的是推理过程中attention循序渐进的变化,所以首先要拆分推理过程为一系列原子操作(atomic operations)。作者将GQA数据集中涉及的127种操作根据语义相似性映射到7种,并构建了一个单词表,如下图所示。这些原子操作强调了在这一步中attention的作用。

视觉问答中的一个问题,对应了一个原子操作的序列,每个原子操作带有标注的ROIs(Region of Interest),即为每个推理步骤需要关注的ground truth区域。
四. 方法
1. 指标AiR-E
将一个推理过程分解成原子操作的序列后,作者提出了衡量每一步attention质量的指标AiR-E。设计的主要思路是:在每一个推理操作中,可以根据attention map(人或者机器的)和标注的ROIs的对齐程度,来衡量attention的质量。
指标AiR具体的计算方法如下:
1) standardize the attention map。Attention可以用一个二维的概率矩阵来表示,其中每个值反映了图像上对应像素的重要程度。先对整个attention map A(x) 用均值和方差进行标准化:A*(x) = (A(x) - µ) =σ;
2) 对每个标注的ROI,将它的bounding box B 范围内对应的attention map数值取平均,记为它的AiR-E score:
3) 对每个推理操作:
- 如果这个操作只对应了一类ROIs集合(比如操作select,query, filter等),就取这个ROIs集合中最大的AiR-E score作为最终的aggregated AiR-E score
- 如果这个操作对应了多个ROIs集合(比如relate, compare, and),那么就先计算每一类ROIs的aggregated AiR-E,最后再对所有类取平均
如下图所示,高质量的attention能帮助推理得到正确的答案,对应更高的AiR-E分数;反之,不准确的attention关注到了无关区域,对应的AiR-E分数也更低。

2. 模型AiR-M
在推理过程中,为了让模型学习每个推理操作应该关注哪些区域,循序渐进地推理得到答案,本文提出了一种简单的显式attention监督方法,联合训练三个子问题:预测一系列推理操作是什么、每个操作中应该关注什么区域、最后得到的问题答案是什么。
在一个推理过程中(即回答一个VQA的问题时),在第t个推理步骤,模型需要预测这个步骤的推理操作rt,并生成这个步骤的attention map αt。联合训练的损失函数如下面公式(1)所示:
其中θ和Φ是超参数。作者使用了标准的交叉熵损失函数来有监督地训练答案预测和推理操作预测,同时使用了一个KL散度函数(KullbackLeibler divergence loss)
这种简单的监督方法可以整合到很多已有的使用了attention机制的的VQA模型上。
3. 眼动数据集AiR-D
以前的工作没有显式地验证过推理过程中人类注意力的准确性。为了定量地建模人的注意力,本文收集了第一个关于VQA的眼动数据集。
下面,简要介绍一下眼动数据集的收集过程:
1) 用于测试的图片和问题来源于 the balanced validation set of GQA [1];
2) 自动+手工筛选原始数据、保证质量,最终得到 987 张图片和和对应的1,422 个问题;
3) 设计Eye-tracking experiment,让20个被测者回答这些VQA问题,记录被测者回答问题、进行视觉推理时的Eye fixations;
4) 对于每个问题,整合所有被测者的Fixation map为一个,对Fixation map进行平滑处理和标准化,最后它的大小为256*256像素,map中每个值介于[0,1];
5) 测试者回答问题时有对也有错(如下图),将所有问题的fixation map根据回答是否正确分为两类(正确/错误)。
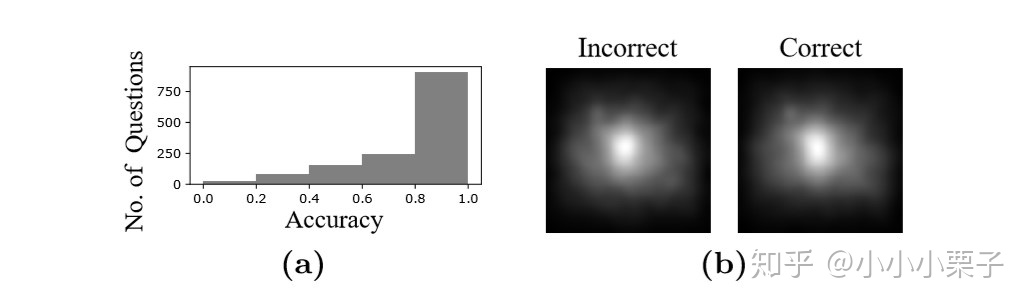
人在进行视觉推理时,目光停留的地方就是重点关注的区域,所以人的Fixation map相当于attention map。回答正确/错误的问题对应的两类fixation maps被作者视为两个human attention baseline,用于后续与机器的attention map作对比。
这里收集眼动数据集来定量建模人的attention,是因为本文使用的数据集GQA是机器自动生成问题和答案的,每个问题的推理步骤序列也是程序自动生成的,需要做一些人的attention实验,用来和模型的attention做比较,同时也能验证AiR-E指标和AiR-M模型的有效性。
五. 实验与分析
本文围绕人和机器的attention做了大量的实验和分析,主要想回答三个方面的问题,下面进行详细介绍。
1. Do machines or humans look at places relevant to the reasoning process? How does the attention process influence task performances?
这部分实验,作者没有分解推理过程,单纯从空间域上分析人和机器的attention。
具体地,作者测评了在VQA任务中模型常用的四种注意力机制:spatial soft attention (S-Soft), spatial Transformer attention (S-Trans), object-based soft attention (O-Soft), 以及object-based Transformer attention (O-Trans)。使用UpDown [2] 这个VQA模型为骨架,将上述四种attention分别代替UpDown论文中原来的attention模块,训练得到实验结果。
同时,为了研究人的注意力机制,作者将回答正确的那些问题所对应的fixation map记做H-Cor,不正确的记做H-Inc,所有问题(忽略正确/错误)的fixation map记做H-Tot。

图4中展示了一些attention可视化的例子,每一行代表一个问题,前四列表示不同推理操作的标注ROIs,后六列分别是机器和人在回答问题时的attention map。
接下来,作者又分三个维度来做实验:
1) 探究了人和机器的注意力准确度和在任务上的表现。
表2定量地展示了在不同的推理操作下、不同类型的attention下,人和机器得到的AiR-E分数和问题回答准确率。看表格前三行,可以得到人正确回答问题时(H-Cor)的AiR-E分数要比错误回答问题时(H-Inc)高很多。对比人和机器的表现,无论在AiR-E分数还是问题回答准确率,人能达到的各项指标都显著高于机器。在机器的四种attention类型之间比较,则发现Object-based attentions要比spatial attentions关注地更准确。
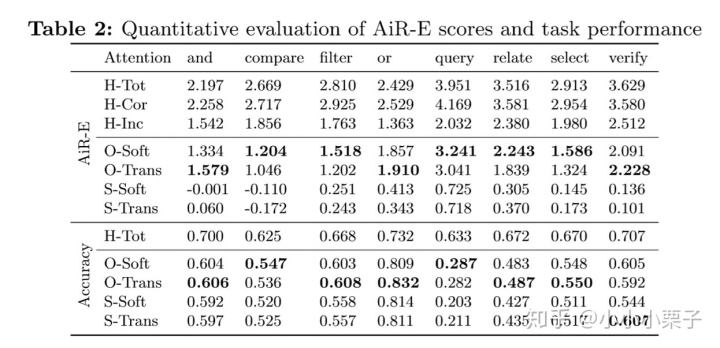
此外,表2 的实验结果整体和我们的直觉一致,也验证了AiR-E指标的有效性。
2) 不同推理操作下的注意力准确度和任务表现
表2中每一列都表示了一个推理操作。比较不同的推理操作,我们可以发现query操作对模型来说是最难的:此时模型的注意力准确度是最高的,问题回答准确率却是最低的。作者分析模型在识别能力上劣于人类,即使关注到了正确的区域,它也可能无法准确识别出区域中的物体。对人来说,compare操作是最有挑战性的,这是因为给出一些很复杂的问题时,人需要同时关注对比多个区域,在有限的时间内难以完成,但模型却可以并行地处理多区域多物体。
3) 注意力准确度和任务表现之间的关系
作者进一步计算了注意力准确度和任务表现之间的Pearson系数,来探究两者的相关性,如表3所示。
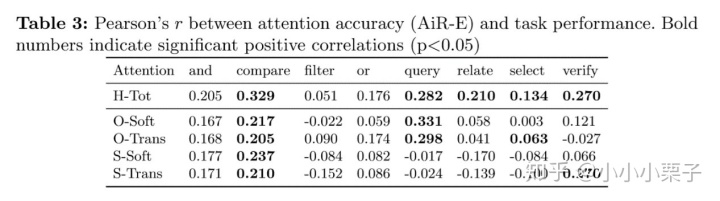
表3显示在大多数推理操作下,人的注意力准确度和任务表现是正相关的,Pearson系数明显高于机器的attention。反之,虽然我们通常认为spatial attention的准确度和模型的表现是相关的、能增加模型的可解释性,但是表3的实验结果否定了这一点,观察最后两行,大多数推理操作对应的Pearson系数是很小的、甚至为负。比较而言,object-based attentions反映了注意力准确度-任务表现之间更高的相关度。
总结第一部分的实验,作者发现在推理过程中,人关注的相关区域会比机器准确很多。此外,attention准确率和任务表现不是直接正相关的,而是要取决于进行的推理操作。
2. How does attention accuracy evolve over time, and what about its correlation with the reasoning process?
第二部分实验和本文的研究的内容相关,作者分解了推理过程,额外从时域上来分析attention,探究了人和机器attention在推理过程中是否有渐进的变化。
具体地,作者使用了multi-glimpse machine attention,对比人类attention随时间的变化,以揭示两者的差异。
1) 人类的注意力是随推理过程变化的吗?
作者将人的fixation map根据时间划分为三类(0-1s,1-2s和2-3s),计算每个时间段fixation map和推理步骤ROIs之间的AiR-E分数,如下图所示。这两个热力图中颜色越亮表示AiR-E分数越高,横轴表示每个推理步骤应关注的ground truth区域,纵轴表示人随时间变化的关注区域,如果两者有高度一致性,可以看到对角线“”是高亮的。
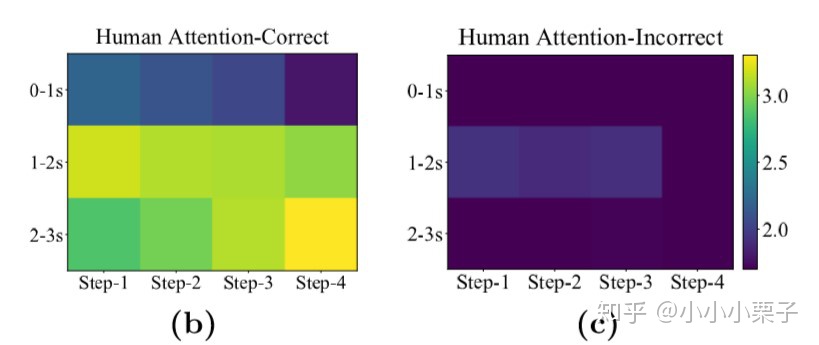
观察图(b)发现人能正确回答问题时,在0-1s的AiR-E分数比较低,说明还在最初的探索阶段;经过了这个探索阶段,注意力准确度就开始提升,并且在1-2s主要关注early-step ROIs(第二行左边最亮);到了2-3s的最后推理阶段,热力图第三行右边高亮,说明推理快结束时人关注late-step ROIs。而当人回答问题错误时,如图(c),AiR-E分数一直都比较低,说明整个推理过程都没有看对地方。这个实验说明了人的attention和推理步骤序列是有时空上的高度对齐性的。
2) 模型的注意力是随推理过程变化的吗?
类似地,作者研究了三种multi-glimpse machine attentions的表现: stacked attention from SAN [41], compositional attention from MAC [18]和multi-head attention [12, 44]。其中Multi-glimpse attention模型一般在解答问题时输出多个attention map,可以观察不同时刻输出的attention map来研究它随时间的变化。
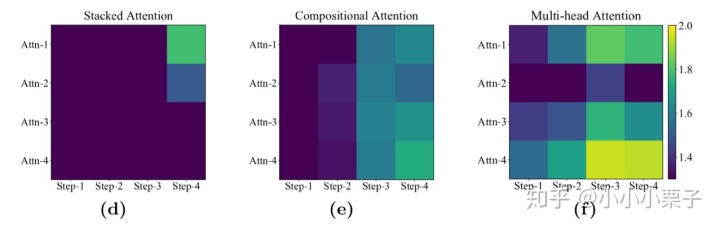
上图展示了三种不同的Multi-glimpse attention在推理中随时间的变化。(d)中模型在第一次看的时候就已经看到了推理结束时刻应关注的区域;(e)和(d)中的两种attention也是主要关注Step-3或者Step-4对应的ROIs,直接忽略了early steps中的ROIs。这说明传统的几种multi-glimpse machine attentions都不是随着推理过程循序渐进变化的,而倾向于“一眼看到底”。
3. Does guiding models to look at places progressively following the reasoning process help?
第三部分实验主要在验证本文提出的attention监督方法AiR-M是否有效。
这里作者将AiR-M和其他三种SOTA的attention监督方法(human-like attention (HAN) [31], attention supervision mining (ASM) [46] and adversarial learning (PAAN) [30]),整合到三个VQA模型中(UpDown [2], MUTAN [4], and BAN [25]),来进行多维的比较。
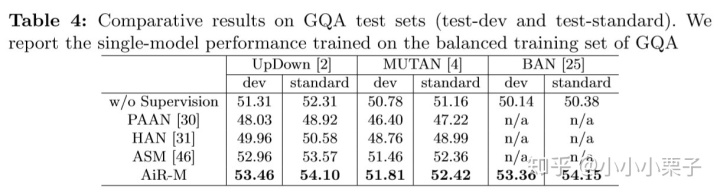
从表4中,可以观察得到相比于其他三种监督方式,AiR-M能使得三个VQA模型达到最好的效果。
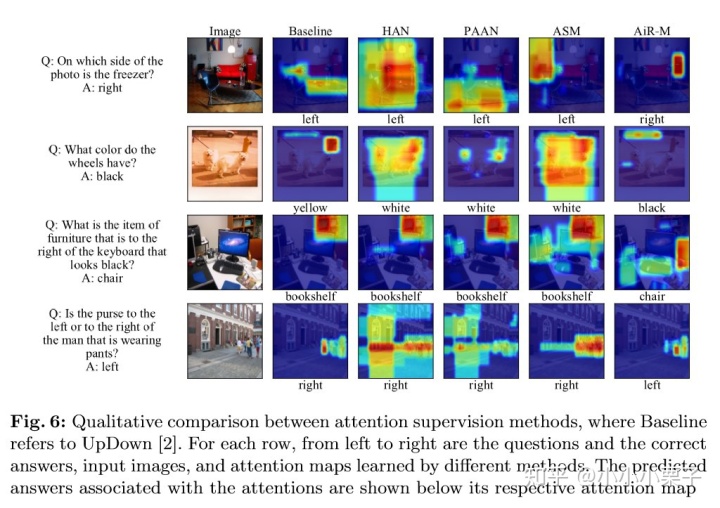
图6是一些attention的可视化例子,本文提出的AiR-M监督方式可以使模型不仅关注到和答案最相关的ROIs(例如Q4中的purse),还能关注到问题中提及的其他重要ROIs(Q4中的man),它们往往是在推理过程中涉及到的。
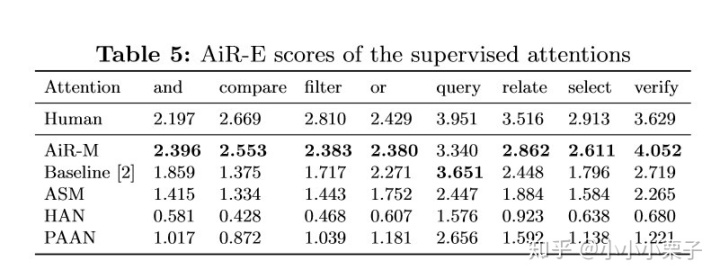
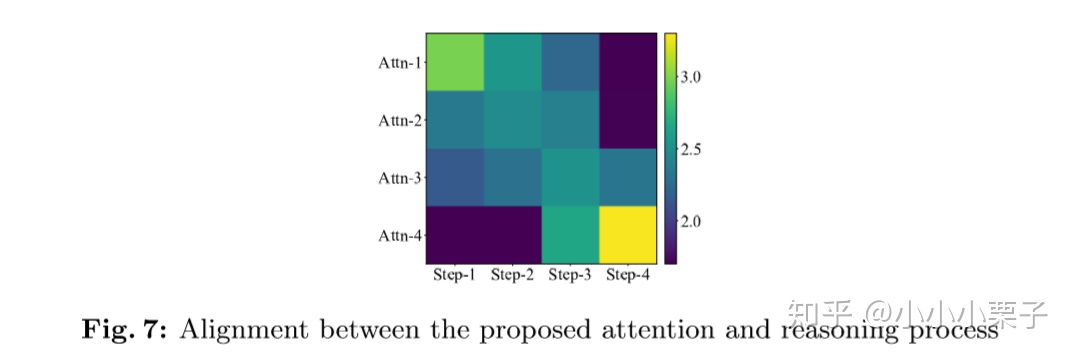
表5展示了不同推理操作下人和机器的attention,说明AiR-M监督方式可以显著提升attention准确度。图7中,热力图大致呈对角线“”型高亮,说明用AiR-M训练的multi-glimpse attentions能够在时域上和推理步骤更好地对齐。
最后这个demo视频可视化了随着推理过程循序渐进变化的模型attention。

六. 总结与分析
之前的工作在VQA中广泛使用attention来捕捉和问题相关的区域,但是没有在时域上考虑过attention渐进的变化。由本文的实验部分可得,现有的Multi-glimpse attentions也是“一眼看到底”。这篇论文基于GQA这样高质量、监督信息比较多的数据集,将推理过程细分成一系列原子操作,想法新颖,同时做了大量详实的实验和分析,为后面的工作提供了思路。
我们认为这篇论文思路的缺陷在于,完成一个推理过程,并不一定需要按照ground truth中的“推理路径”来推理,我们可以通过不同的“推理路径”来得到正确答案,例如找一个穿牛仔裤的小女孩,可以先找“牛仔裤”再找“小女孩”,也可以先寻找图中的“小女孩”再判断她是否穿着牛仔裤,而本文的AiR-M强制模型根据标注的一个ROIs序列去进行观察和推理。此外,本文提出的这种AiR-M监督attention,对数据集的要求比较高,其中必须要带有每个推理过程的操作标注和相应ROIs标注。
参考文献
[1] Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: CVPR (2019)
[2] Anderson, P., He, X., Buehler, C., Teney, D., Johnson, M., Gould, S., Zhang,L.: Bottom-up and top-down attention for image captioning and visual question answering. In: cvpr (2018)
[4] Ben-Younes, H., Cad`ene, R., Thome, N., Cord, M.: Mutan: Multimodal tucker fusion for visual question answering. ICCV (2017)
[12] Fukui, A., Park, D.H., Yang, D., Rohrbach, A., Darrell, T., Rohrbach, M.: Multimodal compact bilinear pooling for visual question answering and visual grounding. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. pp. 457{468 (2016)
[18] Hudson, D.A., Manning, C.D.: Compositional attention networks for machine reasoning (2018)
[25] Kim, J.H., Jun, J., Zhang, B.T.: Bilinear Attention Networks. In: NeurIPS. pp. 1571{1581 (2018)
[30] Patro, B.N., Anupriy, Namboodiri, V.P.: Explanation vs attention: A two-player game to obtain attention for vqa. In: AAAI (2020)
[31] Qiao, T., Dong, J., Xu, D.: Exploring human-like attention supervision in visual question answering. In: AAAI (2018)
[41] Yang, Z., He, X., Gao, J., Deng, L., Smola, A.: Stacked attention networks for image question answering. In: CVPR (2016)
[44] Yu, Z., Yu, J., Fan, J., Tao, D.: Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. In: ICCV (2017)
[46] Zhang, Y., Niebles, J.C., Soto, A.: Interpretable visual question answering by visual grounding from attention supervision mining. In: WACV. pp. 349{357 (2019)


)



)




)



)


)
